






近年来,因果推断与机器学习的结合取得了显著进展。从因果效应的识别与估计到异质性分析,再到中介效应和时空干扰的研究,这一领域不断拓展。这种结合不仅提升了因果推断的精度,还为社会科学研究提供了更强大的工具,有助于深入理解复杂社会现象背后的因果机制。
提出因果效应识别的最优实验设计算法,解决干预成本最小化问题,显著提升因果推断效率。
推动了社会科学的实证研究,为政策制定提供了更科学的依据,有助于优化资源分配并提升社会干预的效果。
我整理了10种【机器学习+因果推断】的相关论文,全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “因果ML”领取~
1.Locally Private Causal Inference for Randomized Experiments
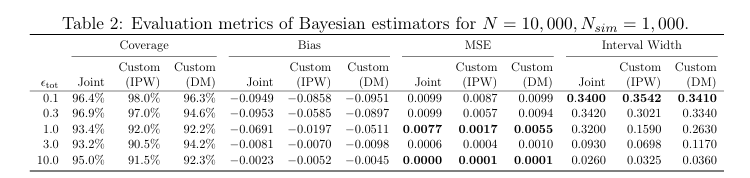
文章聚焦随机实验中的局部隐私因果推断,提出不同隐私场景下的推断方法,包括频率主义估计和贝叶斯方法,并通过模拟研究和真实数据分析验证其性能,为处理隐私数据的因果推断提供了有效方案。
-
创新点
1.提出针对不同局部隐私场景的频率主义估计方法,定制隐私机制以达到极小极大最优推断,提升估计效果。
2.开发贝叶斯非参数方法及相应的抽样算法,能有效整合先验知识,在隐私预算紧张时表现出色。
3.在多种隐私场景下进行研究,涵盖联合私有化、定制私有化且已知或未知处理分配概率的情况,拓展了研究边界。
-
研究结论
1.定制隐私机制的估计方法可达到极小极大最优,在不同隐私场景下表现良好,优于简单的联合私有化估计。
2.贝叶斯方法能有效利用先验信息,在隐私预算紧张时,相比频率主义方法具有更小的均方误差和更优的区间估计。
3.模拟研究和真实数据分析验证了所提方法的有效性,但在隐私保护和结果准确性之间存在权衡,未来可进一步优化。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “因果ML”领取~
2.Optimal Experiment Design for Causal E ect Identification
文章围绕因果效应识别的最小成本干预设计问题展开,证明该问题 NP 完全,提出精确算法和启发式算法,通过理论分析和实验评估,为解决此问题提供了有效途径。
-
创新点
1.证明最小成本干预问题的 NP 完全性,并表明近似求解该问题的难度,为研究该问题的复杂性提供理论依据。
2.提出基于最小命中集问题的精确算法,能找到最优解或对数因子近似解,同时给出特殊情况下的多项式时间算法。
3.设计多种多项式时间启发式算法,通过实验验证其在随机图上能获得低遗憾解,并给出平均情况下的遗憾上界。
-
研究结论
1.最小成本干预设计问题在一般情况下是 NP 完全的,难以找到多项式时间的精确算法。
2.提出的算法在解决单 c - 组件和一般子集的因果效应识别的最小成本干预问题上有效,精确算法可求解或近似求解,启发式算法在实际应用中有良好表现。
3.算法性能受图结构、边密度、干预成本等因素影响,在不同情况下应选择合适算法以平衡运行时间和结果的最优性。

全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “因果ML”领取~
3.Riemannian Bilevel Optimization
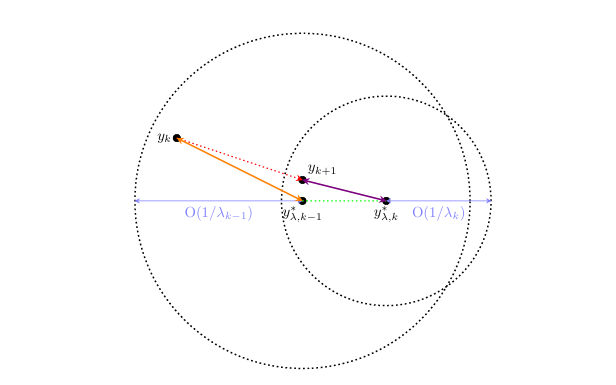
文章针对黎曼双级优化问题,提出并分析了 RF²SA 算法,通过将问题转化为单级约束问题,避免使用二阶信息,给出了算法在不同情况下的收敛速率,为相关领域优化提供新方法。
-
创新点
1.提出 RF²SA 算法,利用一阶梯度信息解决黎曼双级优化问题,避免复杂的二阶信息计算,简化了算法实现过程。
2.推导了拉格朗日乘子 λ 的最优增长速率,确保算法在不依赖二阶导数的情况下非渐近收敛到 ε- 平稳点。
3.给出了算法在随机场景下的收敛速率保证,且该速率与欧几里得优化中的预期速率一致,适应了黎曼流形的复杂性 。
-
研究结论
1.RF²SA 算法是一种有效的黎曼双级优化算法,能在避免二阶信息的情况下,收敛到 ε- 平稳点,且在不同噪声条件下均有收敛速率保证。
2.算法的收敛速率在不同噪声场景下有所不同,噪声影响越少收敛越快,在完全确定性场景下收敛速率可达O(k−2/3) 。
3.该算法为解决涉及流形约束的复杂优化挑战提供了几何感知框架,但仍存在迭代复杂度较高等局限性,未来可拓展其应用范围 。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “因果ML”领取~
顶会投稿交流群来啦!
欢迎大家加入顶会投稿交流群一起交流~这里会实时更新AI领域最新资讯、顶会最新动态等信息~

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









