










2025年2月27日,CVPR 2025论文录用结果出炉,共2878篇,录用率为22.1%!目前,上海市计算机学会计算机视觉专委会正在征集上海地区的录用论文成果,拟于2025年5月召开“2025 CVPR上海论文分享学术报告会”。
1,Post-Training Quantization with Adaptive Scale in One-Step Diffusion based Image Super-Resolution
-
作者及单位:朱力博(上海交通大学),李建泽(上海交通大学),秦浩桐(苏黎世联邦理工学院),李文博(香港中文大学),张宇伦(上海交通大学),国雍(马克斯-普朗克信息学研究所),杨小康(上海交通大学)
-
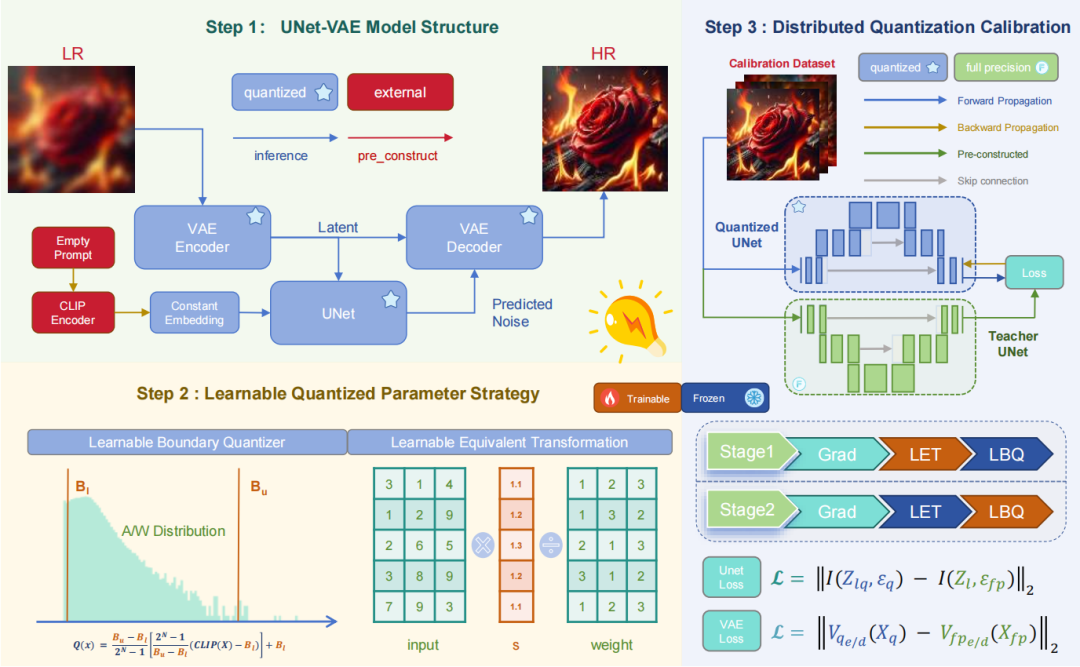
论文简介:基于扩散的图像超分辨率(SR)模型虽表现卓越,但高计算和存储成本限制了其硬件部署。为此,我们在一步扩散(OSD)SR(PassionSR)中提出了一种自适应尺度的后训练量化方法。首先,移除 CLIPEncoder 以简化模型,仅保留 UNet 和 VAE。其次,引入可学习边界量化器(LBQ)和等价变换(LET)优化量化。最后,设计分布式量化校准(DQC)稳定训练。实验表明,8/6 位 PassionSR 在视觉效果上与全精度模型相当,并优于现有低比特量化方法。
-
Paper链接:
-
Code链接:
2,One-for-More: Conditional Diffusion Model for Anomaly Detection
-
作者及单位:李晓凡(华东师范大学),谭鑫(华东师范大学),陈卓(厦门大学),张志忠(华东师范大学),陈玉珑(上海交通大学),曲延云(厦门大学),马利庄(华东师范大学、上海交通大学),谢源(华东师范大学)
-
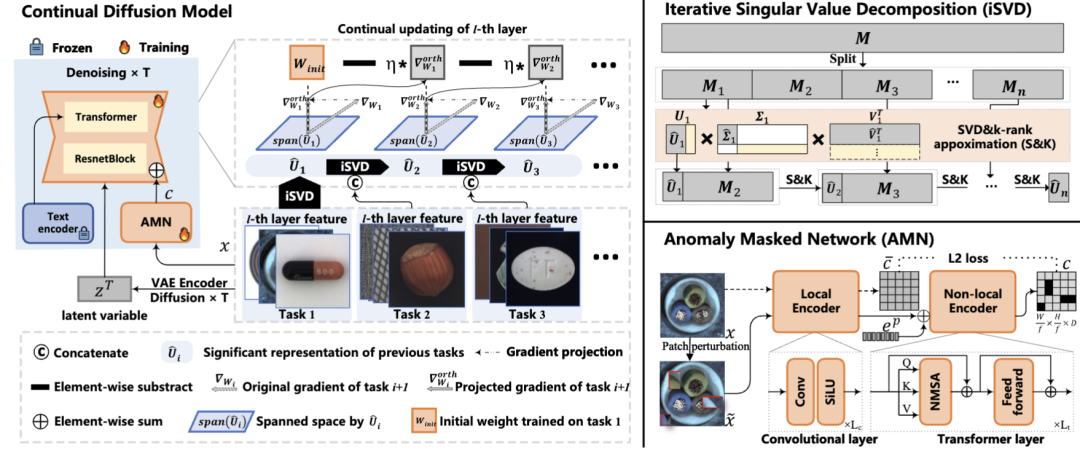
论文简介:本文针对扩散模型在异常检测中存在的“忠实幻觉”和“灾难性遗忘”问题,提出持续扩散模型:1)采用梯度投影正交化实现知识保留;2)设计迭代奇异值分解法降低马尔可夫推理90%内存消耗;3)构建异常掩码网络防止正常样本过拟合。该模型在MVTec和VisA的17/18任务中达到SOTA,验证了持续学习框架的有效性。
-
Paper链接:
[2502.19848] One-for-More: Continual Diffusion Model for Anomaly Detection
-
Code链接:
3,Domain Generalization in CLIP via Learning with Diverse Text Prompts
-
作者:文长崧,彭泽林,黄瑜,杨小康,沈为
-
单位:上海交通大学
-
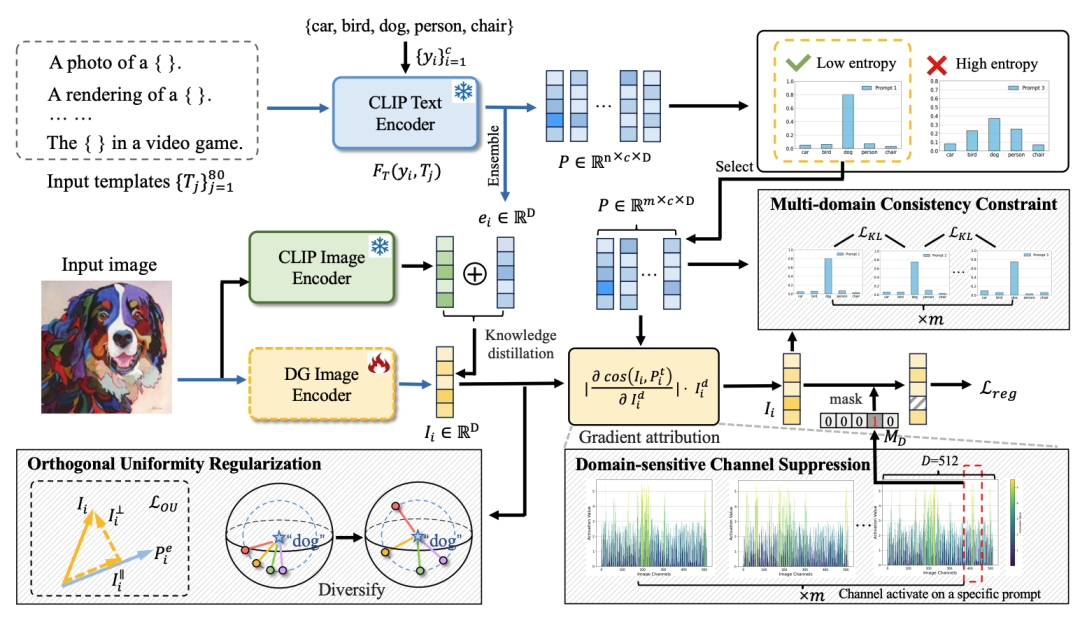
论文简介:领域泛化(Domain Generalization, DG)通过在源领域上训练模型,使其能够泛化到未见过的领域。尽管视觉-语言模型(如CLIP)展现了卓越的泛化能力,但在其预训练过程中对齐图像与细节的文本描述,不可避免地导致图像编码器捕获特定的领域细节,并且在源领域特征多样性有限时引入偏差,从而限制了其跨域泛化能力。本文提出了一种通过多样文本提示学习的新DG方法。这些文本提示模拟不同领域,引导模型学习领域不变特征。本文从特征抑制、特征一致性和特征多样化三个方面进行优化。实验结果表明,该方法在DomainBed基准测试的五个数据集上提升了领域泛化性能,达到了最先进水平。
4,Towards Universal Dataset Distillation via Task-Driven Diffusion
-
作者及单位:齐鼎(同济大学),李剑*(腾讯优图),高俊尧(同济大学),窦曙光(同济大学),邰颖(南京大学),胡建龙(腾讯优图),赵波(上海交通大学),王亚彪(腾讯优图),汪铖杰(腾讯优图),赵才荣*(同济大学)
-
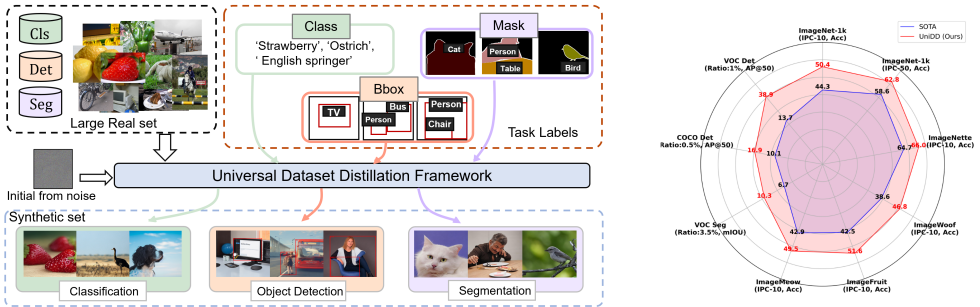
论文简介:数据集蒸馏(DD)通过压缩大规模数据集的关键信息,降低训练开销,但现有方法主要针对图像分类,难以满足检测和分割任务的需求。为此,我们提出UniDD框架,基于任务驱动扩散模型,分为任务知识挖掘和任务驱动扩散两阶段,生成任务相关的合成图像。实验表明,UniDD在ImageNet-1K,Pascal VOC和MS COCO等数据集上性能显著提升,降低部署成本,为多样化任务提供新思路。
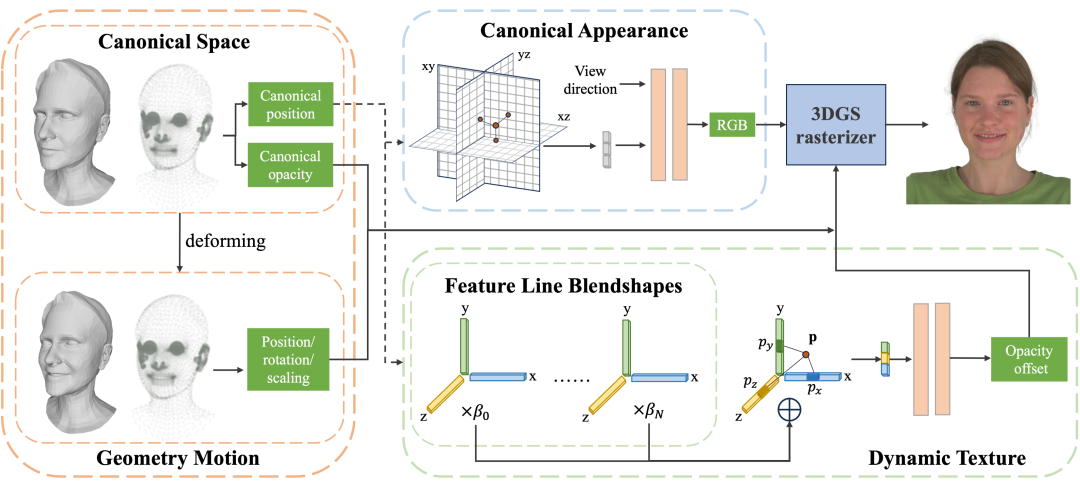
5,3D Gaussian Head Avatars with Expressive Dynamic Appearances by Compact Tensorial Representations
-
作者及单位:王雅婷(上海交通大学),王璇(蚂蚁金服研究院),易冉(上海交通大学),樊艳波(蚂蚁金服研究院),胡基宸(上海交通大学),朱璟程(上海交通大学),马利庄(上海交通大学)
-
论文简介:近期研究结合了3D高斯和人脸3DMM来构建高质量的3D头部虚拟形象。现有方法或无法捕捉动态纹理,或在运行速度或存储空间上开销过大。为解决了上述问题,我们引入了一种表达力强且紧凑的表示方法,将3D高斯的纹理相关属性编码为张量格式。我们将中性表情的外观存储在静态三平面中,并使用轻量级的1D特征线表示不同表情的动态纹理细节,这些特征线随后解码为相对于中性脸的不透明度偏移。我们还提出了自适应截断透明度惩罚和类别平衡采样,以提高不同表情间的泛化能力。实验表明,该设计能够准确捕捉面部动态细节,同时保持实时渲染并显著降低存储成本,从而拓宽了其应用场景。
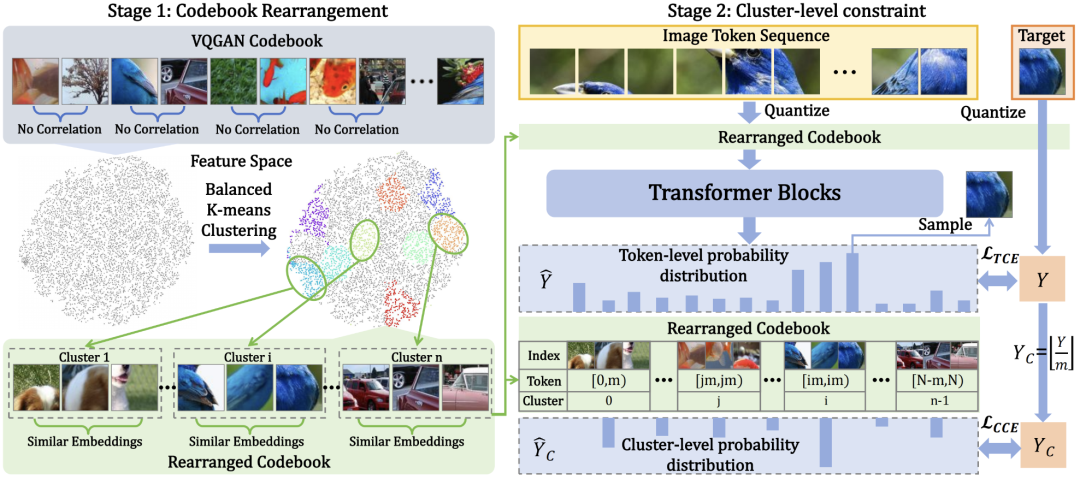
6,Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction
-
作者及单位:胡腾(上海交通大学),张江宁(腾讯优图、浙江大学),易冉(上海交通大学),翁解语(上海交通大学),王亚彪(腾讯优图、浙江大学),曾仙芳(浙江大学),薛竹村(浙江大学),马利庄(上海交通大学)
-
论文简介:本文基于视觉令牌相似度聚类改进自回归模型(IAR),通过分析视觉嵌入空间特性,发现利用视觉特征间的高相关性可提升生成稳定性。基于平衡k-means聚类设计码簿重组策略,将离散视觉特征重构为高内聚性簇结构,确保相似特征在码簿位置的相近。进一步提出簇导向交叉熵损失,引导模型预测目标token所属簇,缓解单步误差累积导致的语义偏移问题。实验表明,IAR在不同规模模型上均表现出色,有效减少训练时间并提高性能。
-
Paper链接:
[2501.00880] Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction
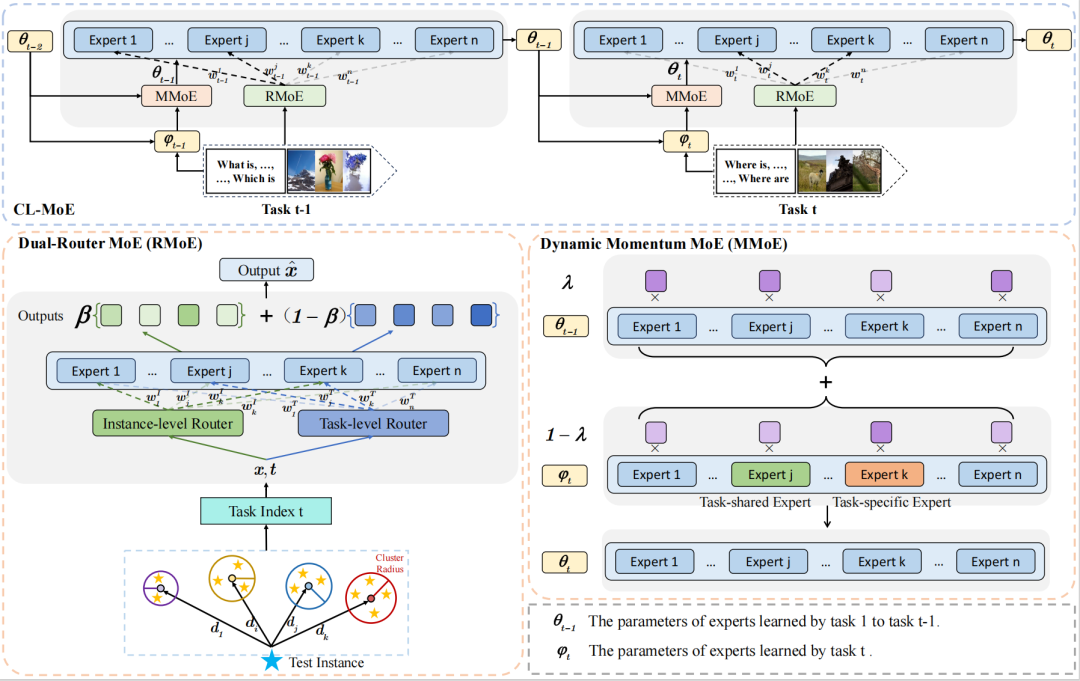
7,CL-MoE: Enhancing Multimodal Large Language Model with Dual Momentum Mixture-of-Experts for Continual Visual Question Answering
-
作者及单位:怀天宇(华东师范大学),周杰(华东师范大学),吴兴蛟(华东师范大学),陈琴(华东师范大学),白庆春(上海开放大学),周泽(竹蜻蜓数据科技(浙江)有限公司)、贺樑(华东师范大学)
-
论文简介:我们提出了一种基于 MLLM 的双动量混合专家框架 CL-MOE,用于持续视觉问答。我们将持续视觉问答 (VQA) 与 MLLM 相结合,充分利用 MLLM 的潜力,MLLM 具有出色的推理能力和丰富的世界知识。在方法上,我们设计了一个双重路由MoE (RMoE),它由任务级和实例级路由组成。通过这种方式,我们的模型通过同时考虑任务和实例,从局部和全局角度捕获合适的专家。同时,我们引入了一个动态动量 MoE (MMoE),使用动量机制根据专家与任务(实例)之间的相关性动态更新专家的参数,吸收新知识,同时减轻灾难遗忘。
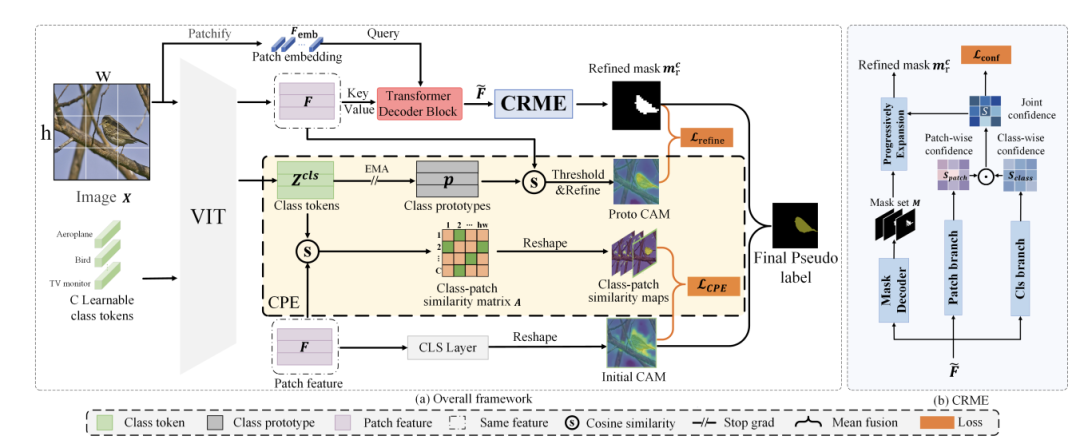
8,Weakly Supervised Semantic Segmentation via Progressive Confidence Region Expansion
-
作者及单位:许翔峰,张品一,黄文轩,陈浩胜,林靖众, 何高奇,谢娇,林绍辉(华东师范大学),沈云航(厦门大学),李卫(华为诺亚实验室)
-
论文简介:弱监督语义分割(WSSS)通过类激活图(CAM)生成伪标签,但ViT易导致“过度扩展”问题。为此,我们提出渐进置信区域扩展(PCRE)框架,包含可信区域掩码扩展(CRME)和类原型增强(CPE),逐步学习目标区域掩码并纠正CAM混淆。
9,Dynamic Stereotype Theory Induced Micro-expression Recognition with Oriented Deformation
-
作者:张博皓,王雪娇,王长波,何高奇
-
单位:华东师范大学
-
论文简介:本文利用自监督学习方法解决了微表情样本稀缺的问题,并通过定向局部形变技术有效克服了微表情空间特征难以有效表征的挑战。最后,本文基于动力定型理论(DST),提出了一种契合人类情感过程的时序表征方法,首次尝试将心理学情感理论作为微表情识别方法的设计依据,是课题组坚持“心理学+计算机视觉”研究理念的重要成
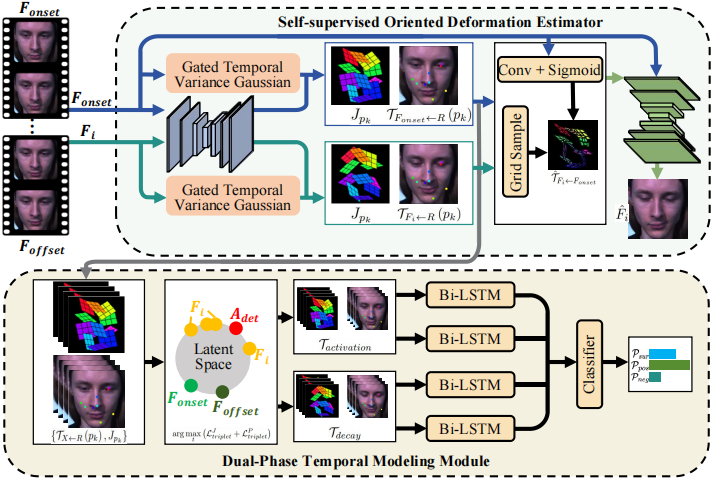
10,Domain Adaptive Diabetic Retinopathy Grading with Model Absence and Flowing Data
-
作者及单位:苏汶芯(上海理工大学),唐宋*(上海理工大学),Liu Xiaofeng(耶鲁大学),尹小静(四川艾尔眼科医院),叶茂(电子科技大学),祖春晓(上海理工大学),李嘉昊(北京协和医学院),Zhu Xiatian(萨里大学)
-
论文简介:本文提出“模型无关的在线领域自适应(OMG-DA)”新问题:如何在所有模型信息不可知、且无监督条件下,仅通过改变数据概率分布,实现跨领域迁移。针对该问题,本文以糖尿病视网膜病变分级为实例,创新地提出了生成式非对抗样本的数据迁移理论(GUES),并给出了基于变分自编码器(VAE)的实现框架。实验表明:不论下游模型是否训练、输入样本规模如何变化,GUES都能显著地鲁棒提升模型的迁移性能。

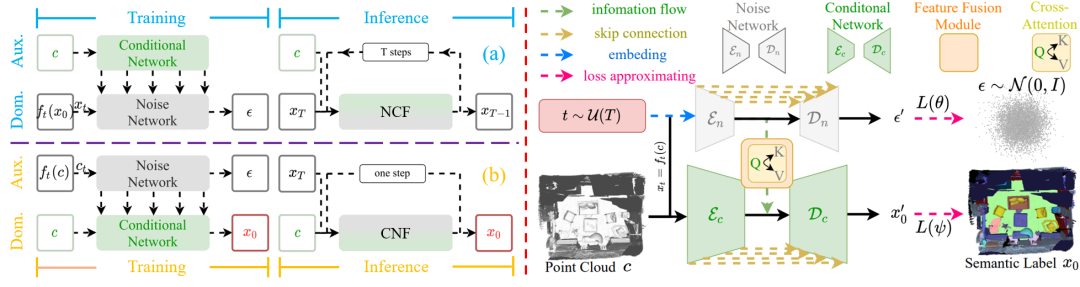
11,An End-to-End Robust Point Cloud Semantic Segmentation Network with Single-Step Conditional Diffusion Models
-
作者及单位:曲文涛(南京理工大学),王晶(清华大学),宫永顺(山东大学),黄小水(上海交通大学),肖亮(南京理工大学)
-
论文简介:分析了 DDPMs 在 3D 感知任务中的优势(噪声和稀疏性鲁棒性)和局限(多步推理),试图剥离两者。因此提出了 CNF,一种新的端到端 DDPMs框架,能避免多步推理的同时保持性能和鲁棒性。希望为 DDPMs 应用于 3D 感知任务引入一种新视角。
-
Paper链接:
-
Code链接:
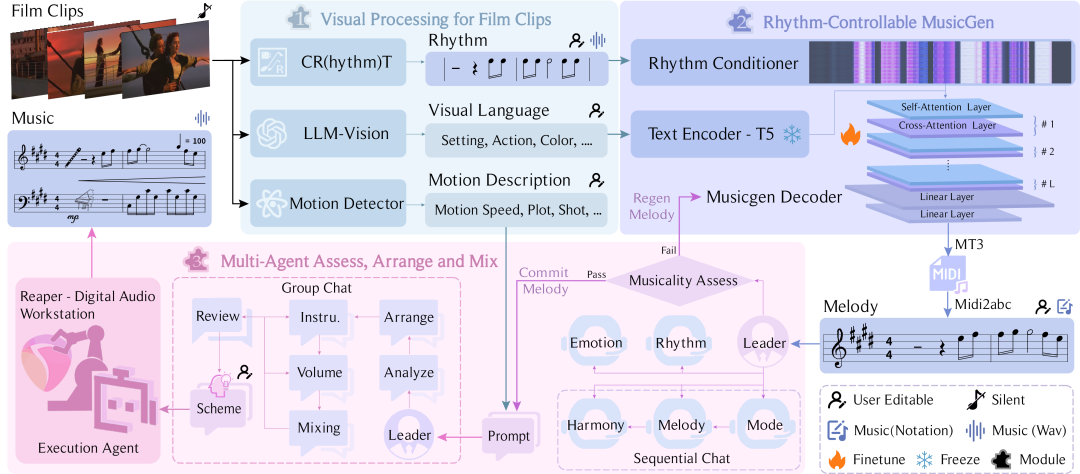
12,FilmComposer: LLM-Driven Music Production for Silent Film Clips
-
作者:谢志峰,何其乐,朱幼佳,何其微,李梦甜
-
单位:上海大学
-
论文简介:本文探索了大模型赋能影视创制,实现了为无声电影片段制作高质量配乐。我们通过大模型驱动与智能体协同,模拟了音乐家真实的配乐过程,可以有效嵌入实际音乐制作管线,初步实现了智能化专业化的电影配乐生成。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









