






最近文生图领域最重要的消息,就是Stable Diffusion 3的推出。
目前,有两种使用Stable Diffusion 3的方法,一种是通过API调用,这需要在Stability AI开发者平台申请API Keys:
Stability AI开发者平台
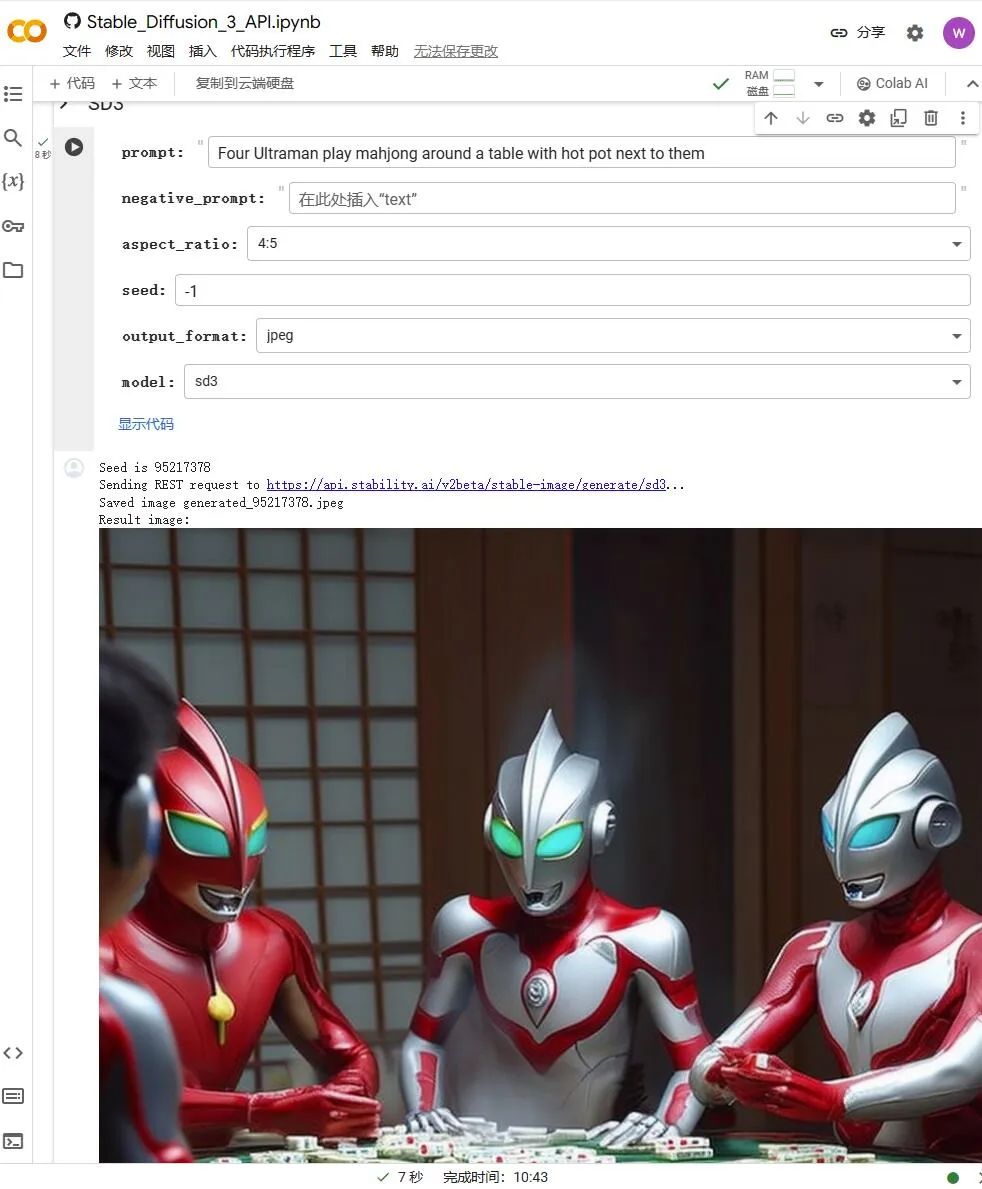
在Google Colab上调用API进行绘图
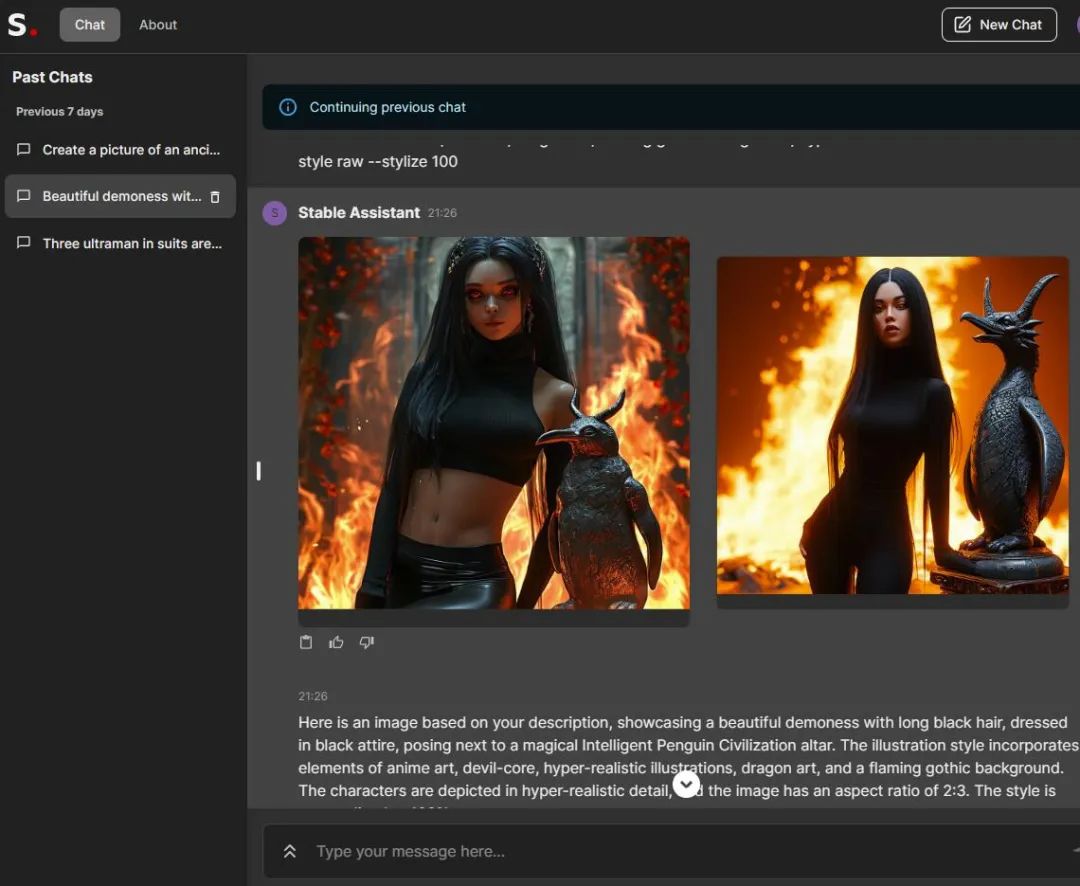
另一种方法,是使用Stable Assistant聊天机器人(需申请),类似在ChatGPT里使用DALLE3:
通过Stable Assistant使用SD3
总之,目前两种方式都需要付费,10美元1000点数,只能画不到200张图,并不便宜。
那到底效果如何,今天就和Midjourney(V6)作一番详细对比:
**
1.**
美丽的魔女,黑色长发,穿着黑色高领套头衫和黑色瑜伽裤,在一个神奇的智能企鹅文明祭坛旁摆姿势,雕像,动画艺术风格,魔鬼核心,超现实插画,32k uhd,龙的艺术,燃烧的哥特式背景,超现实的人物。
Beautiful demoness with long black hair, dressed in a black turtleneck jumper and black yoga pants, posing next to a magic Intelligent Penguin Civilization altar, a statue, in the style of anime art, devil-core, hyper-realistic illustrations, 32k uhd, dragon art, flaming gothic background, hyper-realistic characters.
Stable Diffusion 3

Midjourney V6

两款工具的画风都比较精致,但MJ6没能体现“魔女”,SD3则加入了眼睛异色、头上长角的元素。
2.
狮子肖像,黑白,逼真
lion portrait, black and white, photorealistic
Stable Diffusion 3

Midjourney V6

两款工具表现都很好,好到简直像是以同一只狮子的照片训练的。
3.
贴纸设计的武士宫本武藏,他与樱花树站在一起,平静,安详,极简的线条插图,黑色的灰色和橙色,白色的背景
sticker design of samurai Miyamoto Musashi, he is standing with cherry blossoms tree, he is standing calm, serene, minimalistic line illustration, black gray and orange colors, white background
Stable Diffusion 3

Midjourney V6

相比之下,MJ6更符合“极简”的要求。
4.
一堆垃圾,高得像一座山,活着的人类演员从里面伸出来,人类垃圾超写实,色彩鲜艳,现代,白色背景
pile of garbage, very tall like a mountain, alive human comedians sticking out of it, ala human garbage ultra realistic, colorful, modern, white background
Stable Diffusion 3

Midjourney V6

各有所长,但MJ6在人物的细节上面表现更好。
5.
泰伦斯·马利克拍摄的现代电影,当代在热气球上野餐和西蒙妮·吉尔兹吃糖果的场景
Cinematic film still of modern contemporary picnic in a hot air balloon and a simone giertz eating a candy bar by terrence malik
Stable Diffusion 3

Midjourney V6

提示词包含具体的导演风格和演员形象,两款工具不相伯仲,但对于表现“吃东西”都有点困难。
**6.
**
Stable Diffusion 3

Midjourney V6

个人感觉都差不多,但MJ6的工人是白人,SD3的工人是黑人?
7.
动作科幻电影中女主角的电影广角镜头,控制论增强,运动身体,未来主义,戏剧性的姿势,大胆的灯光,景深,引人注目的视觉效果
cinematic wide shot of a lead heroine in an action packed sci fi movie with cybernetic enhancements, athletic body, futuristic, dramatic pose, bold lighting, depth of field, striking visual effects
Stable Diffusion 3

Midjourney V6
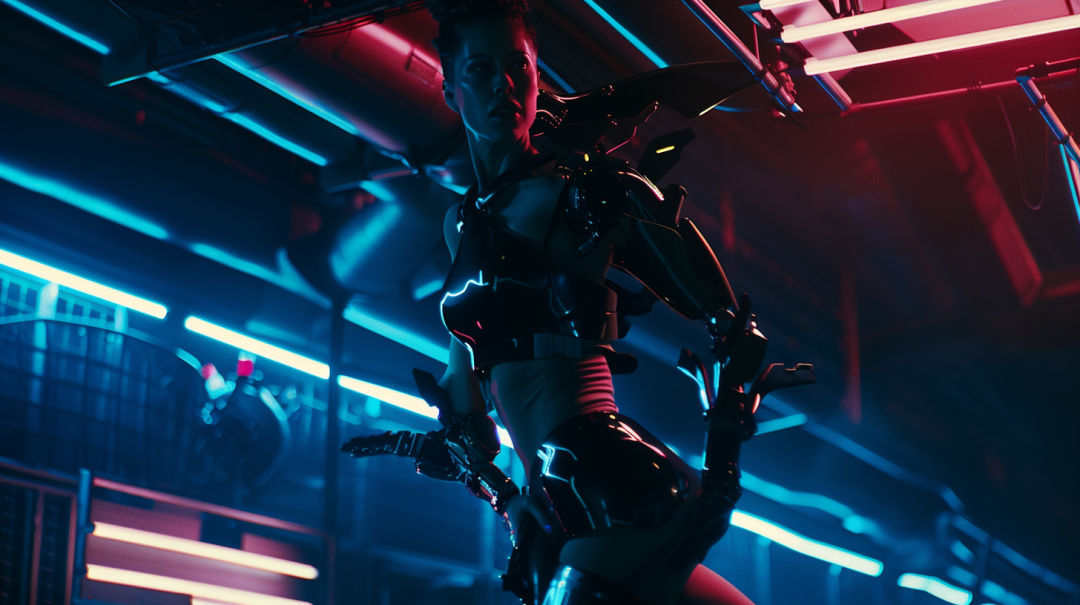
都说MJ6的优势是艺术效果,但这次似乎是SD3的质感更佳。
8.
1961年完全库存道奇动力旅行车展出在道奇经销商船回到1961年的质量照片质量
'61 completely stock Dodge Power Wagon on display at the dodge dealer ship back in the day, 1961 quality photo quality
Stable Diffusion 3

Midjourney V6

SD3在文字的还原上比较强。
9.
一个全副武装的骑士坐在欧洲拥挤的地铁里,逼真的,用iPhone 13拍摄
a knight in full armor sitting in a crowded subway in europe, photorealistic, shot with an iphone 13
Stable Diffusion 3

Midjourney V6

两款工具的效果都令人满意。
10.
一个被锁住的男人,拿着一把鹤嘴锄,在一个建筑工地上工作,他们正在建造未来主义的摩天大楼,这个男人站在那里,对着天空大喊大叫,地上有一片面包,照片,现实主义的照片,肖像
a chained man, holding a pickaxe, working on a construction site where they are building futuristic skyscrapers, the man is standing and shouting to the sky, a piece of bread on the ground, photo, realistic photo, portrait
Stable Diffusion 3

Midjourney V6

MJ6似乎无法很好地理解“被锁住”和“鹤嘴锄”,面包的数量也不对。SD3胜出。
11.
一个黑色的和尚坐在通往无边无际的星星的门口静静地冥想
a black monk in tranquil meditation sitting at the gateway to an infinity of endless stars
Stable Diffusion 3

Midjourney V6

很难说哪个更好,取决于用户的自身审美。
12.
设计师高跟鞋的特写照片,在一个令人难以置信的美丽豪宅和庄园修剪整齐的草坪上,美丽的日落照亮了天空和云彩。
close up photo of designer high heels being worn in the manicured grass lawn of an incredibly beautiful mansion and estate as a gorgeous sunset lights the sky and clouds.
Stable Diffusion 3

Midjourney V6

两款工具都有不错的表现,但需要经过“抽卡”。
13.
一位身着橙青色渐变荷叶裙的中国古代美女,化着华丽的妆容,戴着精致的发饰,站在以荷塘为背景的唐代建筑花园中。她头上戴着荷叶,穿着五颜六色、飘逸的衣袖。全身照片是用那个时代风格的高清摄影拍摄的。她举着一个牌子,上面写着“我是中国人”。
An ancient Chinese beauty wearing an orange and cyan gradient lotus leaf skirt, gorgeous makeup, and exquisite hair accessories stood in the garden of Tang Dynasty architecture with a lotus pond background. Lotus leaves were on her head and she wore colorful, flowing sleeves. The full body photos were taken with high-definition photography in the style of that period. She was holding a sign that said “I am Chinese”.
Stable Diffusion 3

Midjourney V6

妆容表现力差不多,MJ6生成的都是全景,SD3生成的则是近景。文字生成的准确性方面,SD3再次胜出。
14.
一座雕刻在山上的城堡入口的概念艺术,有一座桥与之相连
concept art of an entrance of a castle carved into a mountain, with a bridge connecting to it
Stable Diffusion 3

Midjourney V6

两款工具都较好地达成了创作要求。
15.
一个巨大的种植基地,蓝天,一个巨大的果园,一个小的绿色柑橘,极美的风景照片,风景摄影作品,广角拍摄,逼真的视觉效果,逼真的风景照片,超现实主义,丰富明亮的光源,美丽的光影,柔和的光源,低角度摄影,鸟瞰,高质量,高细节,8k
A 10000 acre planting base, a huge planting base, blue sky and a huge planting base, a huge orchard, small green citrus, extremely beautiful scenery photos, landscape photography works, wide-angle shooting, realistic visual effects, realistic landscape photos, surrealism, rich and bright light sources, beautiful light and shadow, soft light sources, low angle photography, bird’s-eye view, high quality, high detail, 8k
Stable Diffusion 3

Midjourney V6

MJ6的场景较为自然,SD3的植物排列有点过于整齐
16.
日本女团,年轻的少女,抚摸不同人的头发,直发,快乐的表情,浅色照片,肖像,时尚照片,50mm镜头,4k
Japanese girl group, young teenage women, touching different people’s hair, straight hair, happy expressions, light colour photo, portrait, fashion photo, 50mm lens, 4k
Stable Diffusion 3

Midjourney V6

SD3的图中规中矩,MJ6的“艺术修养”这次体现出来了。
17.
街头移动咖啡厅,木质框架,透明玻璃,现代简约,空间多变,结构简洁,细节精致,建筑艺术
Street mobile cafe, wooden frame, transparent glass, modern simplicity, variable space, simple structure, exquisite details, architectural art
Stable Diffusion 3

Midjourney V6

感觉MJ6的生成效果更自然。
18.
霓虹灯在白色的背景上使用粉红色、白色、浅蓝色、深蓝色
neon lights circle on white background using colours pink, white, light blue, dark blue
Stable Diffusion 3

Midjourney V6

虽然呈现的画面有区别,但都满足了提示词的要求。
**19.
**
炫酷蜘蛛侠的“射网”姿势
Cool Spider-Man’s “web shooter” pose
Stable Diffusion 3

Midjourney V6

SD3的服装质感更好。
20.
可爱的皮克斯《哈利波特》海报,迪士尼logo上有“哈利波特”字样的文字,哈利波特手持魔杖,指向前方,进入战斗位置,大大的眼睛,没有雀斑,背景是霍格沃茨学校的城堡,一些巫师骑着扫帚,皮克斯风格,色彩鲜艳
Cute Pixar poster of Harry Potter, Disney logo with the words “Harry Potter” in the text, Harry Potter holding a magic wand, Point ahead and get into battle position, big eyes, No freckles, In the background are Hogwarts School castle, Some wizards ride broomsticks, Pixar style, bright colors
Stable Diffusion 3

Midjourney V6

两款工具表现都不完美,MJ6的英文有问题,SD3的手指有问题。
21.
可爱的皮克斯马里奥海报,迪士尼logo文字中带有“超级马里奥”字样,马里奥跳跃,击打碎砖,大眼睛,周围有乌龟和蘑菇,皮克斯风格,色彩鲜艳
Cute Pixar poster of Mario, Disney logo with the words “Super Mario” in the text, Mario jumps, punching the broken brick, big eyes, There are turtles and mushrooms around, Pixar style, bright colors
Stable Diffusion 3

Midjourney V6

SD3的人物肢体不对,这轮MJ6胜出。
22.
穿着耐克T恤,在维米尔的“戴珍珠耳环的女孩”上做一个现代的转变
Create a modern twist on Vermeer’s ‘Girl with a Pearl Earring’ wearing a Nike T-shirt
Stable Diffusion 3

Midjourney V6

两款工具生成的是不同风格的图像,对品牌图标的表现,SD3较理想。
23.
马克龙总统滑板的照片,用鱼眼拍摄,刊登在trasher杂志
photo of emanuel macron the president skateboarding, photo taken as in the trasher magazin in fisheye
Stable Diffusion 3

Midjourney V6

尽管MJ6的图更有照片质感,但SD3忠实表现了“鱼眼效果”。
24.
一名亚洲黑头发女模特,身穿白色抹胸上衣和藏青色喇叭裙,右手拿着褶边袖子走在巴黎时装周的T台上,背景是灰色的墙壁和木地板。构图以她的全身照片为中心,展示了整个服装。她穿着白色平底鞋和高跟鞋。她优雅地走在T台上,像走秀模特一样,她的姿势散发着自信。
A photo of an Asian female model with black hair, wearing a white strapless top and navy blue flared skirt, walking on the runway for Paris fashion week, with her right hand holding ruffled sleeves, and a background featuring gray walls and wooden floors. The composition is centered around her full body shot, showcasing the entire outfit. She wears white flat shoes with high heels. Her posture exudes confidence as she walks gracefully along the catwalk in the style of a runway model.
Stable Diffusion 3

Midjourney V6

很难说哪个工具表现更好,但如果严格按照提示词,则都没能达到完美。
25.
海蓝色杯子的咖啡,几块饼干,桌上的樱花,近距离拍摄约克郡霍华德城堡前草坪的电影场景,可以看到背后宏伟的建筑,四周有树篱和雕像。阳光灿烂。对称的构图。
a navy cup of coffee, a few cookies, sakura on the table, close up, cinematic still of the front lawn at Castle Howard in Yorkshire, the grand building is visible behind it with hedges and statues on its sides. the sun is shining. symmetrical composition.
Stable Diffusion 3

Midjourney V6

基本元素都没问题,MJ6的图更有美感。
26.
海滩上的蓝色波浪,人们沿着海岸散步,矢量,简单的设计,詹姆斯·吉拉德风格,查尔斯·希勒窗格,马克·布里斯科窗格,莫比乌斯风格,俯视图
Blue waves on the beach, people walking along the coast, vector, simple design,James Gillard style,Charles Sheeler pane,Mark Briscoe pane,Moebius style, top view
Stable Diffusion 3

Midjourney V6
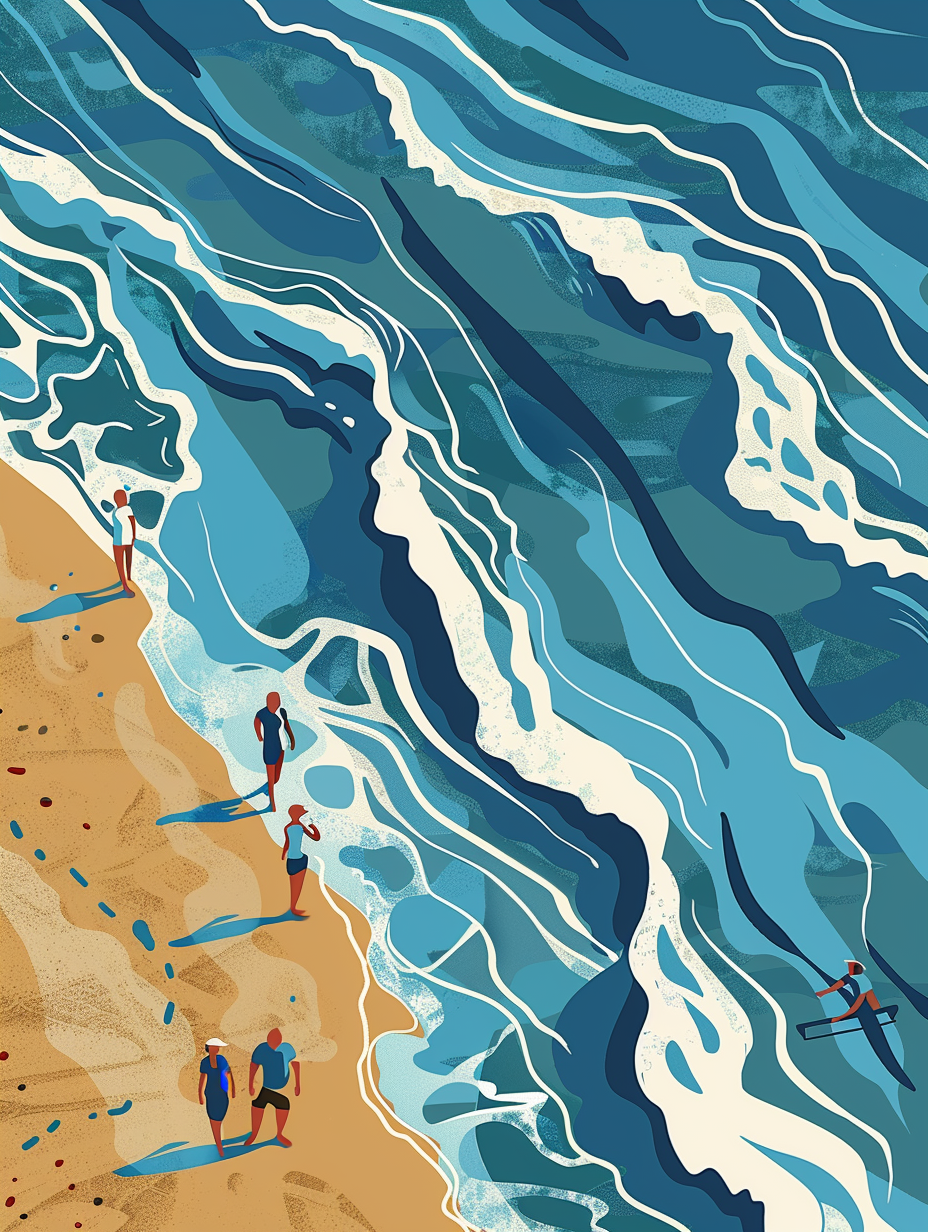
对这些艺术家风格实在不熟,个人觉得表现差不多。
27.
东京超级跑车高达风格驾驶在涩谷的街道
tokyo super cars gundam style driving on the streets of shibuya
Stable Diffusion 3

Midjourney V6

SD3生成的图像像是实拍,MJ6似乎加了摄影滤镜,两者对于日文均无法正常呈现。
28.
科威特大猩猩,穿着白色ghutra和黑色agal,穿着白色dishdasha的行为像一个科威特人,站在超市排队等待科威特的收银员,人类的行为
kuwaiti gorillas, wearing [white ghutra] and [black agal], wearing [white dishdasha] acting like a Kuawiti men, standing in supermarket queue line waiting for the cashier in Kuwait, human act, back to the viewer
Stable Diffusion 3

Midjourney V6

两款工具的效果基本令人满意。
29.
四个奥特曼围着一张桌子打麻将,旁边放着火锅
Four Ultraman play mahjong around a table with hot pot next to them
Stable Diffusion 3

Midjourney V6

SD3绘制的是奥特曼,而MJ6对关键词没有正确理解。
30.
一个3岁的女孩,汉服,可爱,逼真,高品质,功夫,武当山上的一种中国武术风格,背景是云和山,山顶青翠朦胧,营造出一种禅意的氛围。高清摄影捕捉细节
A 3 year old girl, Hanfu, cute, realistic, high quality, kung fu, a style of Chinese martial arts on Wudang Mountain, the background is Yunhe Mountain, the top of the mountain is green and misty, creating a Zen atmosphere. Hd photography captures detail
Stable Diffusion 3

Midjourney V6

两款工具的服饰和容貌表现力都很好,但SD3手指又画错了。
31.
拉尔夫·巴克希执导的电影《1972年龙与地下城》的史诗级战斗剧照
dnd an epic fight still of the movie dungeons and dragons 1972 by Ralph Bakshi
Stable Diffusion 3

Midjourney V6

两种不同的画面风格,个人比较喜欢SD3的结果。
32.
小男孩,皮克斯风格的数字绘画,多种表情和姿势,全身,人物表,蓝色T恤和棕色裤子
very young boy, pixar style digital painting, multiple expressions and poses, full body, character sheet, blue t-shirt and brown pants
Stable Diffusion 3

Midjourney V6

绘制多角度人物还是MJ6更好用,SD3可能需要多次抽卡。
至此,可以对Stable Diffusion 3给出一个初步的结论:
1、对提示词的理解(跟随度)比之前版本有了明显进步,但尚未达到DALLE3的程度。
2、表现文字(英文)的能力,比Midjourney更强。
3、审美能力(美观度)略逊于Midjourney。
4、人体(尤其手指)较容易崩坏,相信开源后可借助插件解决。
5、目前功能较简单,并不支持局部重绘等
综合来看,SD3具有相当大的潜力。尤其Stability AI承诺会坚持开放原则,在不久的将来使得SD3模型可以本地部署。

基于目前的模型,Stable Diffusion如果接入各种插件,成为最强文生图工具,并不是梦。尤其是…本地部署还有更多的“创作自由”!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2621
2621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









