






传统的注意力机制由于时间和空间复杂度的二次方增长,以及在生成过程中键值缓存的内存消耗不断增加,限制了模型处理长文本的能力。相关的解决方案包括减少计算复杂度、改进记忆选择和引入检索增强语言建模。
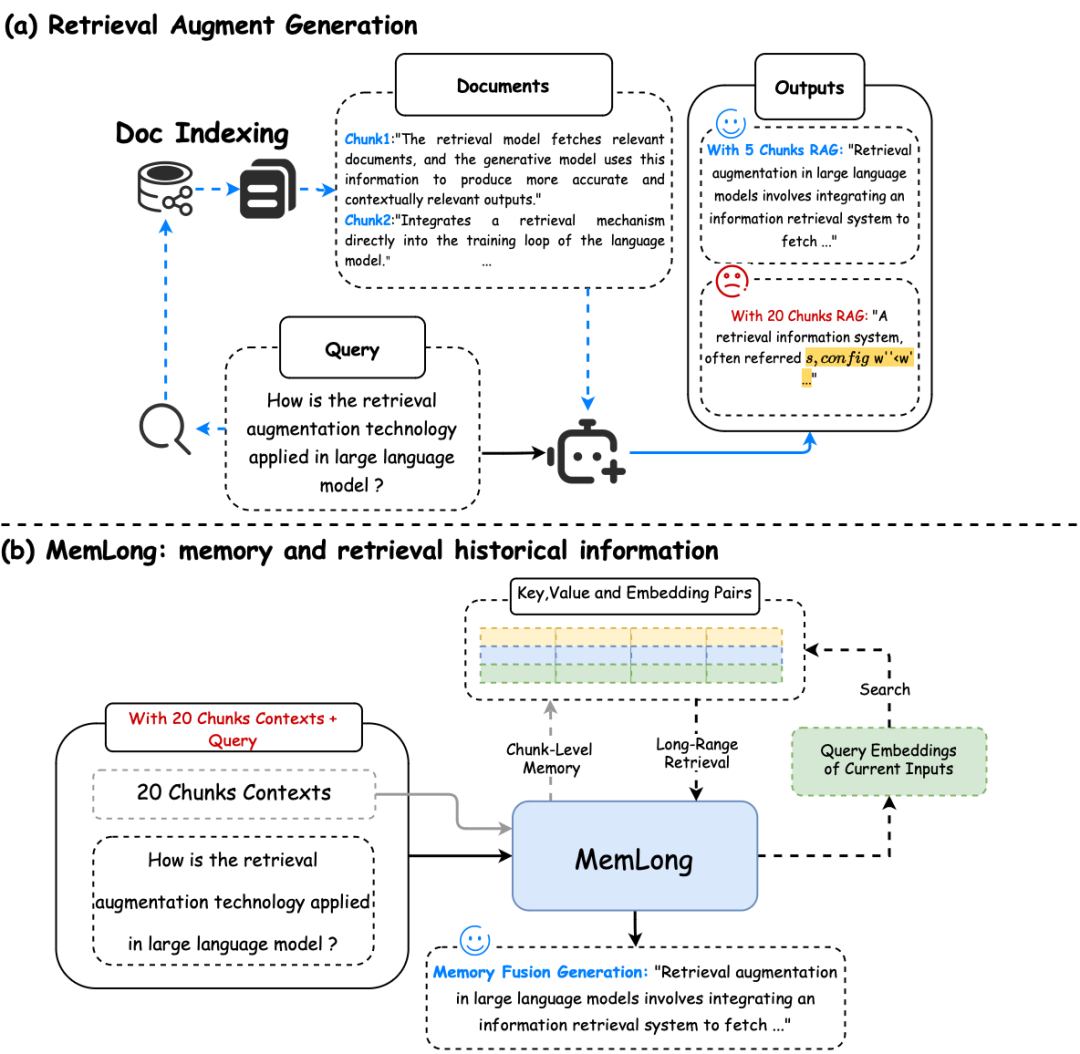
检索增强生成(RAG)和MemLong的记忆检索流程。 (a) 当检索到的信息长度超过模型的处理能力时,RAG甚至可能会降低生成性能(黄色)(b) MemLong利用外部检索器来获取历史信息,然后将这些信息以键值对(K-V)的形式而不是文本形式传递给模型。
提出一种新方案MemLong,结合一个非可微分的检索-记忆模块和一个部分可训练的解码器语言模型,来增强长文本上下文的语言建模能力。
MemLong利用外部检索器来检索历史信息,并通过细粒度、可控的检索注意力机制,将语义级别的相关信息块整合到模型中。这种方法不仅提高了模型处理长文本的能力,还保持了信息分布的一致性,避免了训练过程中的分布偏移问题。
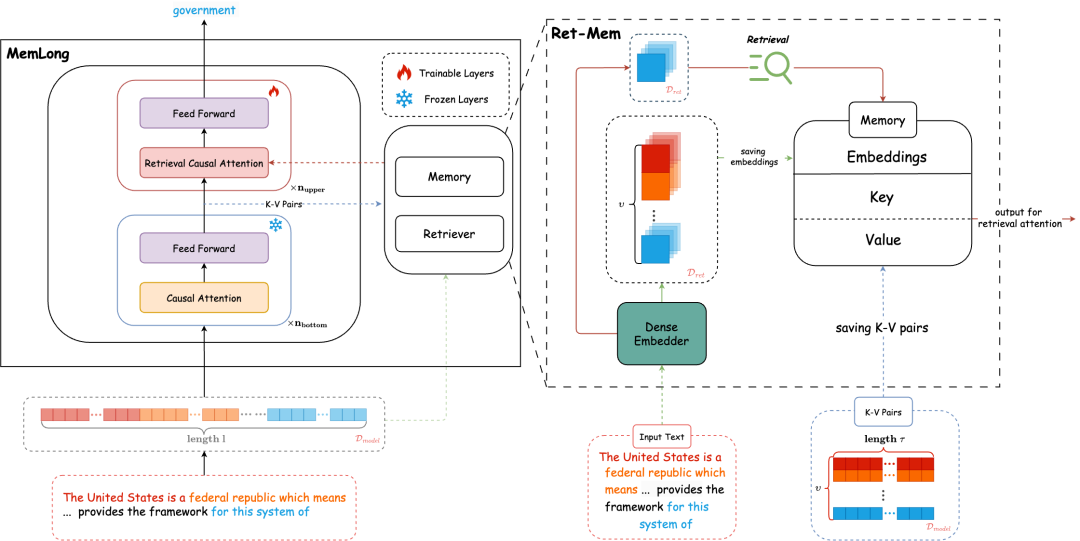
MemLong的一个示例:在底层,模型保持静态,对整个数据块Ci进行因果语言建模,随后,Ci被缓存为嵌入和键值对(K-V)形式。最后,上层进行微调,以协调检索偏好并整合检索到的内容。
MemLong的核心原理包括以下几个方面:
-
检索-记忆模块:MemLong通过检索-记忆模块来存储过去的上下文和知识,并利用这些存储的嵌入向量来检索输入模型的块级关键值(K-V)对。
-
检索注意力机制:MemLong引入了一种细粒度、可控的检索注意力机制,允许模型在局部上下文和通过检索获得的块级过去上下文之间进行注意力分配。
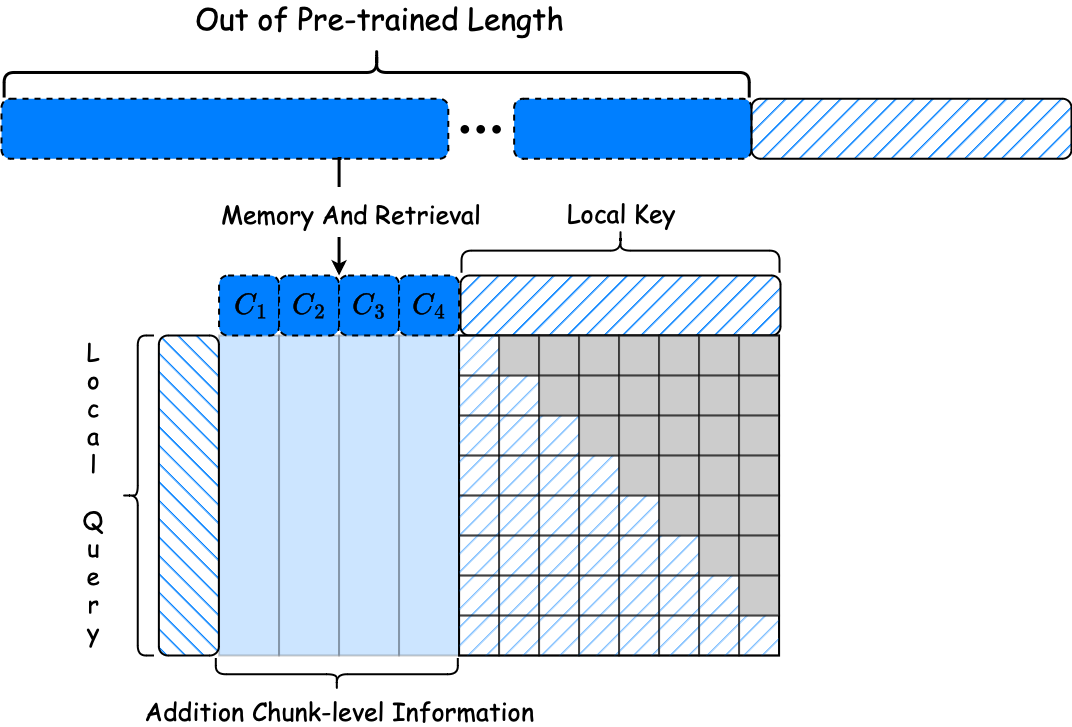
检索因果注意力的说明。局部因果注意力应用于最近的上下文,而通过检索方法获得的块级键值对(K-V)允许双向注意力,由于它们的历史性质,不会导致信息泄露。
-
动态记忆管理:当内存溢出时,MemLong使用计数器机制智能地更新内存,保留最有价值的信息,删除最不相关的数据,以控制内存大小并提高检索效率。
-
推理过程:在处理超出模型最大处理长度的输入时,MemLong将文本存储为记忆库中的上下文信息,并在给定最近生成的文本块时,使用检索器显式检索过去的信息,通过索引对齐获得额外的上下文信息。
通过这些原理,MemLong在多个长文本上下文语言建模基准测试中表现出色,证明了其在处理长文本方面的有效性和优越性。MemLong可以将单个3090 GPU上的上下文长度从4k扩展到80k。
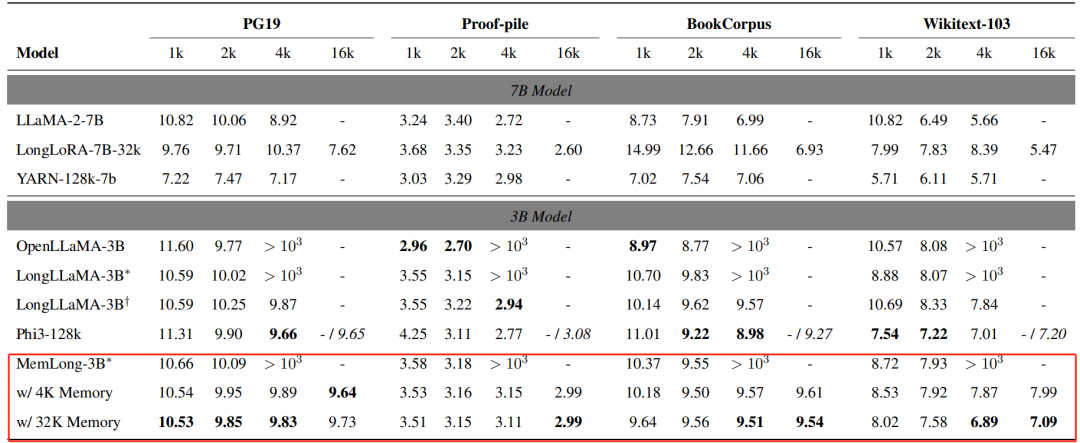
不同上下文窗口扩展模型在PG19、Proof-pile、BookCorpus、Wikitext-103上的滑动窗口困惑度。所有实验均在一块3090 24GB GPU上进行。LongLLaMA-3B和MemLong-3B带有∗标记的表示在没有内存的情况下进行评估,而带有†标记的LongLLaMA-3B表示在无限内存的情况下进行评估。还评估了MemLong在4K/32K内存场景下的表现。"- / 6.95"表示模型在单个GPU上导致内存不足(OOM)错误,而在双GPU上则产生了相应的结果。
https://arxiv.org/pdf/2408.16967https://github.com/Bui1dMySea/MemLongMemLong: Memory-Augmented Retrieval for Long Text Modeling















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









