









论文链接:https://arxiv.org/pdf/2408.02629
项目链接:https://sais-fuxi.github.io/projects/vidgen-1m/
git链接:https://github.com/SAIS-FUXI/VidGen
亮点直击
引入了一个专门用于训练文本到视频模型的高质量视频数据集。
提出了一种多阶段策展方法,在有限计算资源下实现精准且高质量的数据策展。
发布了本文的文本到视频模型,该模型生成的高质量视频在性能上超越了当前最先进的方法。
视频-文本对的质量从根本上决定了文本到视频模型的上限。目前,用于训练这些模型的数据集存在显著缺陷,包括低时间一致性、低质量的字幕、低质量的视频以及数据分布不平衡。现行的视频策展过程依赖于图像模型进行标记和基于规则的人工策展,导致计算负担高且数据不干净。因此,缺乏适合文本到视频模型的训练数据集。为了解决这个问题,本文提出了VidGen-1M,这是一个优质的文本到视频模型训练数据集。通过粗到细的策展策略生成,该数据集保证了高质量的视频和具有优良时间一致性的详细字幕。在用于训练视频生成模型时,该数据集的实验结果超越了使用其他模型所获得的结果。
方法
在构建VidGen的过程中,本文利用了来自HD-VILA数据集的380万高分辨率、长时段视频。随后,这些视频被分割成1.08亿个视频片段。接下来,本文对这些视频片段进行了标注和采样。然后,使用VILA模型进行视频字幕生成。最后,为了纠正前几个步骤中的数据整理错误,本文部署了LLM进行进一步的字幕整理。
粗略策展
为了在有限的计算资源下实现高效的数据整理,本文首先采用粗略的整理方法。这包括场景分割、视频标注、过滤和采样,以减少后续字幕生成和精细整理阶段的计算负担。
场景分割
运动不一致性,例如场景变化和渐变,常常在原始视频中出现。然而,由于运动不一致性直接切断了视频语义,文本到视频模型对其非常敏感并容易混淆,导致训练效率大幅降低。为了减轻这种影响,本文遵循之前的研究,以级联方式利用 PySceneDetect 检测和移除原始视频中的场景转换。
标注
构建适合训练文本到视频模型的数据集需要满足以下标准:高质量视频、类别平衡和视频内的强时间一致性。为了实现这一目标,本文首先需要对每个分割的视频片段进行标注。随后,这些标签将作为策划和采样的基础。
视频质量 视频的视觉质量对于高效训练文本到视频模型至关重要。为了提高文本到视频生成中生成视频的质量,本文采用了一种策略,过滤掉低美学吸引力和高OCR分数的视频。在这种情况下,本文采用LAION美学模型来预测和评估美学分数,从而确保训练数据的高质量。特别是,美学模型还可以过滤掉视觉异常的视频,例如色彩分布不规则或视觉元素奇怪的视频。
时间一致性 视频中的错误场景分割会显著影响模型训练的效果。高时间一致性是训练文本到视频模型所需的关键特征。为确保这一点,本文利用CLIP模型提取视觉特征并评估时间一致性。通过计算视频片段的起始帧和结束帧之间的余弦相似度来实现这一评估,从而提供连续性和一致性的定量衡量。
类别 HD-VILA-100M视频数据集在其类别上显示出显著的不平衡,导致这些类别的视频生成模型性能不佳。为了解决这个问题,本文使用预定义的类别标签来标注每个视频,并借助CLIP模型。具体来说,本文从每个视频的初始、中间和最终帧中提取CLIP图像特征,计算它们的平均值,然后确定这些平均图像特征与每个标签相关的文本特征之间的相似性。这种方法使本文能够为每个视频分配最合适的标签。
运动 本文采用RAFT模型来预测视频的光流分数。由于静态视频和运动过快的视频都会对训练文本到视频模型产生不利影响,本文根据光流分数过滤掉这些视频。
采样
通过使用与视觉质量、时间一致性、类别和运动相关的标签,本文进行了过滤和采样任务。下图2所展示的数据集中多个维度的数据分布清晰表明,低质量、静态场景、运动速度过快以及文本与视频不匹配且时间一致性差的视频被系统地移除。同时,本文确保了在不同类别中样本的相对均匀分布。
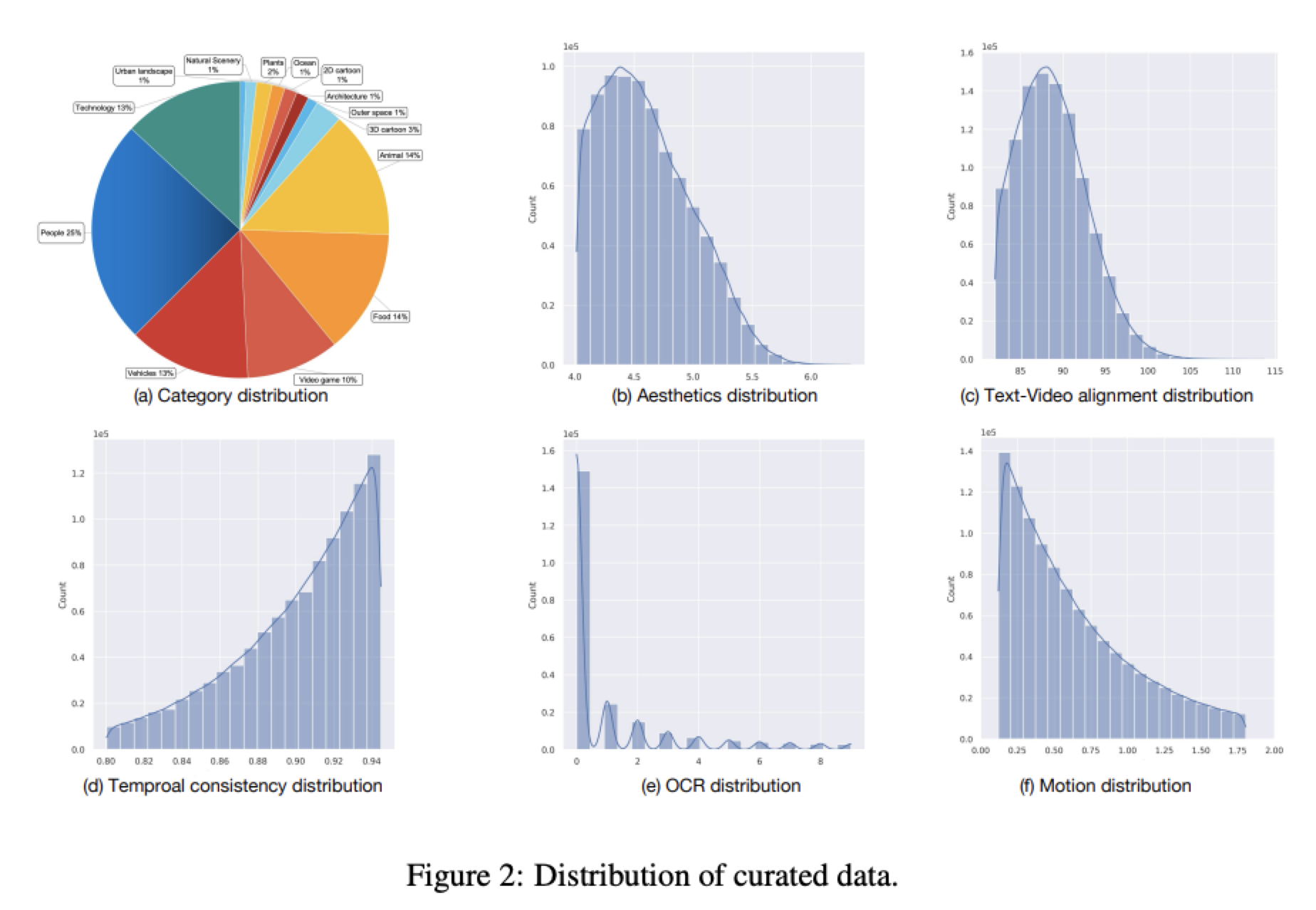
字幕
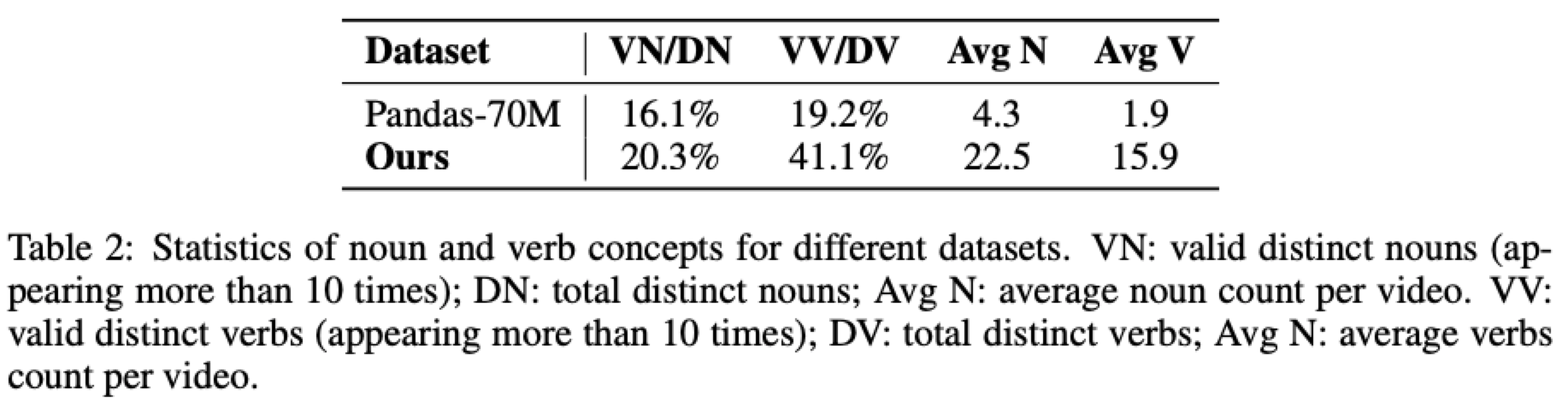
视频字幕的质量对文本到视频模型有着至关重要的影响,而HD-VILA-100M数据集中的字幕存在一些问题,包括文本与视频之间的不匹配、描述不充分以及词汇使用有限。为了提高字幕的信息密度,本文采用了最先进的视觉语言模型VILA。由于VILA在视频字幕生成方面的卓越能力,本文显著提升了字幕的质量。在生成字幕后,本文使用CLIP评分来过滤出文本与视频相似度较低的对。本文在下表2中展示了词汇分析,其中有效的不同名词和有效的不同动词是指在数据集中出现超过10次的词汇。利用VILA模型对HD-VILA-100M数据集进行处理后,本文生成了增强版的HD-VILA-100M数据集。在Panda-70M数据集中,有270K个不同的名词和76K个不同的动词;然而,只有16.1%和19.2%的名词和动词分别符合有效性标准。使用VILA生成的字幕显著提高了有效比例以及每个视频中名词和动词的平均数量,从而增加了概念密度。
精细策展
在粗略策展和字幕生成阶段,使用CLIP评分过滤文本-图像对齐和时间一致性可以去除一些不一致的数据,但并不完全有效。因此,在视频字幕中会出现一些问题,如场景转换,以及两种典型的描述错误:
-
生成eos标记失败,即模型未能正确终止生成过程,导致循环或重复的标记生成
-
帧级生成,即模型缺乏对帧之间动态关系的理解,为每个帧生成孤立的描述,导致字幕缺乏连贯性,无法准确反映视频的整体故事情节和动作序列。
为了解决上述数据策划问题,一种潜在的解决方案是人工注释,但这种方法成本过高。随着大型语言模型的最新进展,这个问题可以得到解决。可以使用语言模型(LLM)分析特定模式,如场景转换、重复内容和帧级描述,来识别多模态语言模型(MLLM)生成的字幕中的错误。像LLAMA3这样的模型在这些任务中表现出色,使其成为人工注释的可行替代方案。
在本文努力隔离和去除在文本-视频对齐和时间一致性方面存在差异的视频-文本配对时,利用了先进的语言模型(LLM)LLAMA3.1来审查各自的字幕。精细策划的应用显著提高了文本-视频对的质量,如下图3所示。研究主要围绕三个关键因素展开:场景转换(ST)、帧级生成(FLG)和重复(Redup)。

实验
实施细节
为了评估本文文本到视频训练数据集的有效性,本文使用基础模型进行了全面评估,该模型由空间和时间注意力块组成。为了加速训练过程,本文最初在大量低分辨率 图像和视频上进行了广泛的预训练。随后,本文使用 像素分辨率的图像和4秒视频在本文的 VidGen-1M 数据集上进行了联合训练。
实验结果
定性评估
如下图4所示,本文模型生成高质量视频的能力证明了高分辨率VidGen-1M数据集的稳健性。该数据集的高质量体现在生成视频的真实感和细节上,进一步证明了其在训练本文模型方面的有效性。本文生成的视频一个显著特点是其强大的“提示跟随”能力,这是训练数据中视频-文本对高度一致性的直接结果。这种一致性确保了模型能够准确解释文本提示,并生成具有高保真度的相应视频内容。第一个例子进一步强调了VidGen-1M数据集的高质量。生成的视频展示了惊人的真实感——从潜水员在水下漂浮的头发到气泡的运动。这些细节展示了显著的时间一致性,并遵循现实世界的物理规律,突显了模型生成可信且视觉上准确的视频内容的能力。

VidGen-1M数据集的质量对计算机视觉领域,特别是文本到视频生成,有着深远的影响。通过提供高分辨率和时间一致性的训练数据,VidGen-1M使模型能够生成更真实和高质量的视频。这可以推动视频生成技术的发展,突破当前的可能性界限。此外,VidGen-1M提供的高质量数据可能会简化模型训练过程。借助更准确和详细的训练数据,模型可以更有效地学习,可能减少对大量计算资源和耗时训练周期的需求。通过这种方式,VidGen-1M不仅改善了文本到视频生成的结果,还促进了更高效和可持续的模型训练实践。
结论
在本文中介绍了一个高质量的视频-文本数据集,该数据集具有高视频质量、高字幕质量、高时间一致性和高视频-文本对齐度,专门用于训练文本到视频生成模型。上述各种高质量特性源于本文精心设计的数据策展过程,该过程以粗到细的方式高效地确保了数据质量。为了验证VidGen-1M的有效性,作者在其上训练了一个文本到视频生成模型。结果令人鼓舞,训练在VidGen-1M上的模型在零样本UCF101上取得了显著更好的FVD分数,与最先进的文本到视频模型相比有明显提升。
参考文献
[1] VidGen-1M: A Large-Scale Dataset for Text-to-video Generation
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术
















 2405
2405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









