







〔探索AI的无限可能,微信关注“AIGCmagic”公众号,让AIGC科技点亮生活〕
论文地址: https://arxiv.org/abs/2411.10640
一. 研究背景
- 研究问题:这篇文章要解决的问题是如何在移动设备上高效地部署多模态大型语言模型(MLLMs)。移动设备由于其内存和计算能力的限制,难以实现流畅且实时的处理,因此需要针对移动平台进行优化。
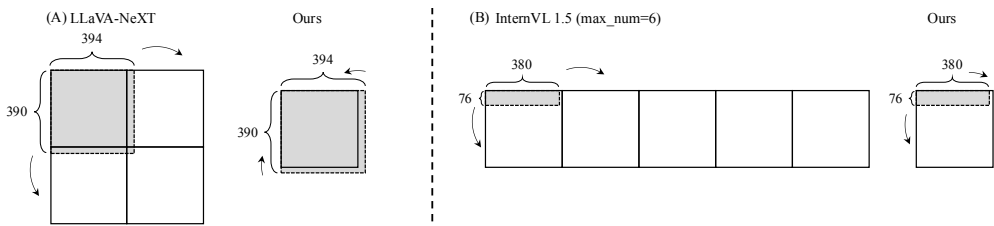
- 研究难点:该问题的研究难点包括:移动设备的内存容量有限,限制了大型参数模型的部署;移动处理器的计算能力有限,影响了推理速度;传统的动态分辨率方案会导致图像处理速度变慢,增加整体延迟。
- 相关工作:该问题的研究相关工作包括:大语言模型(LLMs)在解决各种复杂任务中的潜力;多模态大型语言模型(MLLMs)通过处理和整合文本、图像和音频数据,增强了用户体验;现有研究探讨了在云服务平台、桌面PC和边缘设备上部署LLMs的可行性。
二. 研究方法
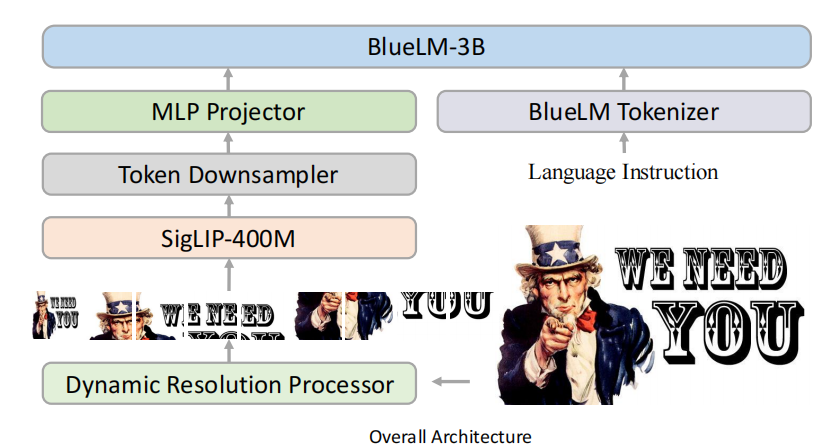
这篇论文提出了BlueLM-V-3B,一种针对移动平台优化的算法和系统协同设计方法。具体来说,
-
算法设计:首先,重新设计了传统MLLMs采用的动态分辨率方案,提出了一种放松的宽高比匹配方法,以减少图像令牌的数量而不牺牲模型准确性。该方法通过添加参数α来防止总是选择较大分辨率的趋势,公式如下:
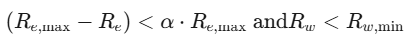
其中,Re表示有效分辨率,Rw表示浪费分辨率。
-
系统设计:其次,进行了详细的系统优化,包括批处理图像编码和流水线并行处理,以提高硬件感知的训练和部署效率。具体来说,批处理图像编码通过将图像分成多个局部块并与缩略图一起输入到ViT中,利用GPU并行性加速处理。流水线并行性方案则对SigLIP模型中的Conv2D层和视觉变换器块进行并行处理。
-
令牌下采样:此外,为了应对动态分辨率策略导致的图像令牌数量过多的问题,采用了令牌下采样方法,将每2x2个令牌合并为一个令牌,并通过线性层融合信息。
-
模型量化和整体框架:最后,应用混合精度量化以进一步减少内存使用和提高推理速度,采用INT8精度用于ViT和MLP投影器的权重,INT4精度用于LLM权重,并保持INT16精度用于LLM激活和FP16用于ViT和投影器激活。

三. 实验设计
- 数据收集:预训练阶段使用了开源数据集,包括LLaVA 558k、ShareGPT4V 1200k和ALLaVA 708k,共250万个图像-字幕对。微调阶段构建了一个包含6.45亿图像-文本对的多样化数据集,涵盖了字幕、VQA、OCR和纯文本等多种下游任务和数据类型。
- 实验设置:在预训练阶段,使用AdamW优化器,峰值学习率为10^-3,训练步数为3.434k,全局批量大小为720。在微调阶段,使用AdamW优化器,峰值学习率为10^-4,训练步数为131k,全局批量大小为5760。
- 样本选择:在微调阶段,使用了多种开源数据集,如ALLaVA、ScienceQA、Orca-Math等,并结合了自建数据以增强模型的多语言理解能力。
四. 结果与分析
-
部署效率:在MediaTek Dimensity 9300处理器上,BlueLM-V-3B的图像编码时间为2.53秒,LLM预填充时间为2.7秒,令牌吞吐量为24.4 token/s。相比之下,MiniCPM-V-2.5在CPU上的图像处理延迟为4.0秒,LLM预填充延迟为13.9秒,吞吐量仅为4.9 token/s。
-
基准测试:在OpenCompass基准测试中,BlueLM-V-3B在8个任务中有4个取得了最佳性能,平均排名第二。与参数规模相似的模型相比,BlueLM-V-3B表现出色,例如在TextVQA任务中,BlueLM-V-3B的得分为78.4,而MiniCPM-V-2.6为73.2。
-
文本/OCR能力:在文本为中心的/OCR基准测试中,BlueLM-V-3B的表现与类似参数规模的最先进MLLMs相当,同时显著提高了多语言能力。例如,在MTVQA任务中,BlueLM-V-3B的得分为32.7,而MiniCPM-V-2.6为20.7。

五. 论文总结
这篇论文介绍了BlueLM-V-3B,一种针对移动平台优化的算法和系统协同设计方法。通过重新设计动态分辨率方案、进行系统优化、采用令牌下采样和混合精度量化等方法,BlueLM-V-3B在移动设备上实现了高效的推理。实验结果表明,BlueLM-V-3B在多个基准测试中表现出色,具有较高的模型性能和部署效率。未来的工作将集中在优化BlueLM-V-3B的可扩展性,并探索先进的算法以进一步提高性能和可用性。
六. 论文评价
- 算法和系统联合设计:提出了针对移动平台的多模态大型语言模型(MLLMs)的高效部署算法和系统设计,解决了传统动态分辨率方案中图像放大过度的问题,并实现了一系列硬件感知的系统优化。
- 模型性能优越:BlueLM-V-3B在多个基准测试中表现出色,特别是在OpenCompass基准测试中取得了最高平均分66.1,超过了多个参数更多的模型。
- 高效部署:在MediaTek Dimensity 9300处理器上,BlueLM-V-3B的内存需求仅为2.2GB,能够在约2.1秒内编码分辨率为768x1536的图像,并实现每秒24.4个token的吞吐量。
- 放松的宽高比匹配方法:提出了一种新的放松宽高比匹配方法,有效减少了图像token的数量,同时不牺牲模型的准确性。
- 批处理和流水线并行处理:设计了批处理图像编码和流水线并行处理,显著提高了训练和推理的效率。
- 输入token的分块计算:在推理过程中,实现了输入token的分块计算策略,平衡了并行处理和NPU的计算能力。
- 混合精度部署:应用了混合精度量化,进一步减少了内存使用并提高了推理速度。
七. 论文问题及回答
问题1:BlueLM-V-3B在算法设计方面有哪些具体的改进?
1. 放宽的宽高比匹配方法:传统的动态分辨率方案会导致图像放大,增加图像令牌的数量。BlueLM-V-3B提出了一种放宽的宽高比匹配方法,通过添加参数α来防止总是选择较大分辨率的趋势。具体公式如下:
![]()
其中,Re表示有效分辨率,Rw表示浪费分辨率。这种方法可以在减少图像令牌数量的同时,不牺牲模型的准确性。
2. 批处理图像编码:为了提高训练和推理的效率,BlueLM-V-3B将图像分成多个局部块并与缩略图一起输入到ViT中,利用GPU并行性加速处理。
3. 流水线并行性:在推理过程中,BlueLM-V-3B对SigLIP模型中的Conv2D层和视觉变换器块进行并行处理,进一步提高了图像编码的速度。这些改进使得BlueLM-V-3B在保持高性能的同时,实现了更高效的移动设备部署。
问题2:BlueLM-V-3B在系统优化方面采取了哪些措施?
-
批处理图像编码:将图像分成多个局部块并与缩略图一起输入到ViT中,利用GPU并行性加速处理。
-
流水线并行性:对SigLIP模型中的Conv2D层和视觉变换器块进行并行处理,以提高图像编码的速度。具体来说,对于从单张图像中提取的不同图像块,设计了并行的处理流水线。
-
令牌下采样:为了应对动态分辨率策略导致的图像令牌数量过多的问题,采用了令牌下采样方法,将每2x2个令牌合并为一个令牌,并通过线性层融合信息。
-
混合精度部署:应用混合精度量化以进一步减少内存使用和提高推理速度,采用INT8精度用于ViT和MLP投影器的权重,INT4精度用于LLM权重,并保持INT16精度用于LLM激活和FP16用于ViT和投影器激活。
这些系统优化措施显著提高了BlueLM-V-3B在移动设备上的部署效率和推理速度。
问题3:BlueLM-V-3B在实验结果中表现如何?
-
动态分辨率方法比较:在OpenCompass基准测试中,BlueLM-V-3B在4个任务上取得了最佳性能,平均排名第二。与MiniCPM-V-2.6和InternVL2-8B等参数更多的模型相比,BlueLM-V-3B表现出色,证明了较小参数模型的强大能力。
-
不同基准测试:在Text-centric/OCR基准测试中,BlueLM-V-3B的性能与类似参数大小的SOTA MLLMs相当,同时显著提高了多语言能力。在VLMEvalKit上进行文本VQA和MTVQA评估时,结果同样表明BlueLM-V-3B的多语言和多模态理解能力。
-
部署效率:在vivo X100手机上部署BlueLM-V-3B时,实现了24.4 token/s的生成速度和2.2GB的内存占用。与MiniCPM-V相比,BlueLM-V-3B在图像处理延迟、LLM预填充延迟和吞吐量方面均表现更优。
BlueLM-V-3B 的提出为多模态大型语言模型在移动设备上的高效部署提供了重要的解决方案。通过算法和系统的协同设计,模型在资源受限的硬件平台上实现了高效推理和强大性能,突破了手机端 MLLM 部署的多个瓶颈。这不仅为移动环境中的人工智能应用奠定了技术基础,还为未来的设备端多模态模型优化提供了重要的借鉴意义,有望进一步推动多模态人工智能技术在日常生活中的普及,助力智能手机成为更强大、更便捷的多模态 AI 工具。
推荐阅读
社区简介:
《AIGCmagic星球》,五大AIGC方向正式上线!让我们在AIGC时代携手同行!限量活动中!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之输出映射器:Output Projector
AI多模态模型架构之模态生成器:Modality Generator
AI多模态实战教程:
AI多模态教程:从0到1搭建VisualGLM图文大模型案例


















 2635
2635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









