






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
本文介绍了一个名为CS-Bench的大规模语言模型基准测试集,旨在全面评估语言模型在计算机科学领域的表现。目前,大型语言模型主要关注特定基础技能的评估,如数学和代码生成,而忽略了计算机科学全领域的评价。为填补这一空白,研究者提出了CS-Bench,这是首个针对计算机科学领域的双语(中文-英文)基准测试集,包含约5000个精心挑选的测试样例,覆盖了计算机科学四大领域的26个子领域,包含了各种任务形式和知识推理的划分。通过使用CS-Bench,研究者对30多个主流语言模型进行了全面评估,揭示了计算机科学表现与模型规模之间的关系,并定量分析了现有语言模型失败的原因,指出改进方向,包括知识补充和计算机科学特定推理。进一步的跨能力实验表明,语言模型在计算机科学领域的表现与其在数学和编程方面的能力高度相关。此外,擅长数学和编程的专家级语言模型在多个计算机科学子领域也表现出强大的性能。未来,研究者希望CS-Bench能成为语言模型在计算机科学领域应用的基石,为评估语言模型多样化推理能力开辟新途径。
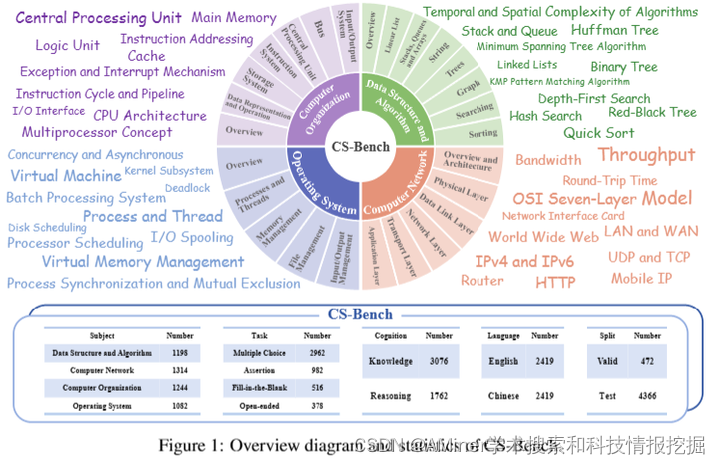
链接:https://www.aminer.cn/pub/666ba41801d2a3fbfc11aa31/?f=cs
2.Towards Lifelong Learning of Large Language Models: A Survey
本文对大型语言模型(LLM)的终身学习进行了综述。随着大型语言模型在各个领域的应用不断扩展,这些模型能够适应数据、任务和用户偏好等方面持续变化的能力变得至关重要。传统的基于静态数据集的训练方法,对于应对现实世界中信息的动态性越来越不够。终身学习,也称为连续或逐步学习,通过使LLM在操作生命周期内持续和适应性地学习,整合新知识的同时保留之前学到的信息,防止灾难性遗忘,解决了这个挑战。本文深入探讨了终身学习的复杂局面,将策略分为两大类:内部知识和外部知识。内部知识包括持续预训练和持续微调,它们分别在各种场景中增强LLM的适应性。外部知识包括基于检索和基于工具的终身学习,利用外部数据源和计算工具扩展模型的能力,而不修改核心参数。本文的主要贡献是:(1)引入了一个新的分类法,将终身学习的广泛文献分为12个场景;(2)识别出所有终身学习场景中共同的技巧,并将现有文献归类为每个场景中不同的技巧组;(3)强调了一些在pre-LLM时代很少探讨的新兴技术,如模型扩展和数据选择。通过详细检查这些组及其各自的类别,本综述旨在提高LLM在现实世界应用中的适应性、可靠性和整体性能。
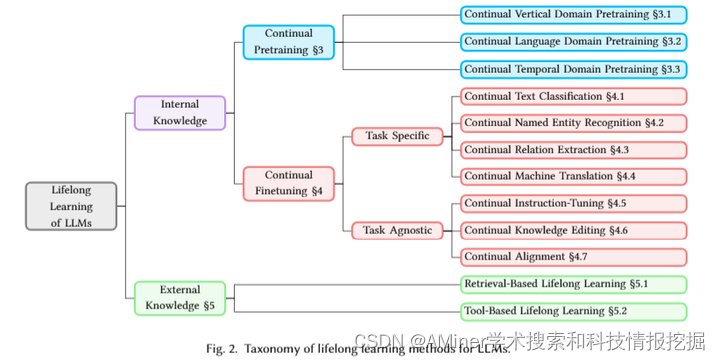
链接:https://www.aminer.cn/pub/6667b02401d2a3fbfc2e3b67/?f=cs
3.NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
本文介绍了一项名为NATURAL PLAN的自然语言规划基准测试,该测试包含三个关键任务:行程规划、会议规划和日历排程。研究重点是评估具有完整任务信息的语言模型(LLMs)的规划能力,通过为模型提供诸如Google Flights、Google Maps和Google Calendar等工具的输出作为上下文,从而消除了评估LLMs规划时使用工具环境的需要。研究发现,NATURAL PLAN对现有最先进模型构成了挑战:例如,在行程规划任务中,GPT-4和Gemini 1.5 Pro只能达到31.1%的准确率,随着问题复杂性的增加,准确率大幅下降,所有模型的表现都低于50%。此外,本文还对NATURAL PLAN进行了大量的消融研究,以进一步揭示自我校正、少样本泛化和长上下文内规划等方法对提高LLM规划效果的有效性。
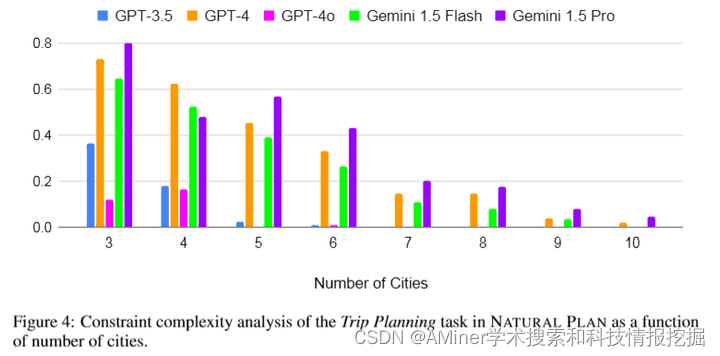
链接:https://www.aminer.cn/pub/66665de401d2a3fbfc324f82/?f=cs
4.LLM Dataset Inference: Did you train on my dataset?
本文探讨了大型语言模型(LLM)在现实生活中广泛应用所带来的知识产权问题。随着针对公司未经许可使用互联网数据训练模型的版权案件增多,近期研究提出了识别个体文本序列是否为模型训练数据成员的方法,即成员推断攻击(MIAs)。文章指出,这些MIAs看似成功的原因是因为选择了与成员(用于训练的文本)分布不同的非成员(未用于训练的文本)。然而,当MIAs在区分来自相同分布的成员和非成员时,其表现并不比随机猜测好,且即使MIAs有效,它们也只在推断来自不同分布样本的成员资格时成功。为此,文章提出了一种新的数据推断方法,以准确识别用于训练大型语言模型的数据集。该方法在现实版权环境中较为实际,作者声称LLM是通过对他们撰写的多篇文章(如一本书)进行训练,而不是针对某个特定段落。尽管数据推断与成员推断面临许多相同挑战,但通过选择为给定分布提供积极信号的MIAs,并将其汇集以对给定数据集进行统计测试,文章解决了这一问题。实验表明,该方法能在统计学上显著的p值<0.1区分不同子集的Pile的训练集和测试集,而没有假阳性。
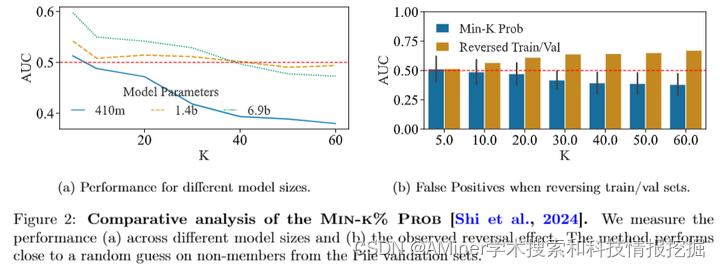
链接:https://www.aminer.cn/pub/6667b02401d2a3fbfc2e3b9e/?f=cs
5.Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
本文介绍了一种评估大型语言模型(LLM)在时间推理任务上性能的新基准。尽管LLM显示出了卓越的推理能力,但在涉及复杂时间逻辑的时间推理任务中,它们仍然容易出错。现有研究通过使用多样化的数据集和基准来探索LLM在时间推理上的表现,但这些研究往往依赖于LLM在预训练过程中可能遇到的真实世界数据,或者采用匿名化技术,这可能会无意中引入事实上的不一致性。本文解决了这些局限,通过引入专门设计的新颖合成数据集来评估LLM在各种场景中的时间推理能力。这些数据集之间问题的多样性使得能够系统地研究问题结构、大小、问题类型、事实顺序等因素对LLM性能的影响。研究发现揭示了当前LLM在时间推理任务上的优势和劣势。
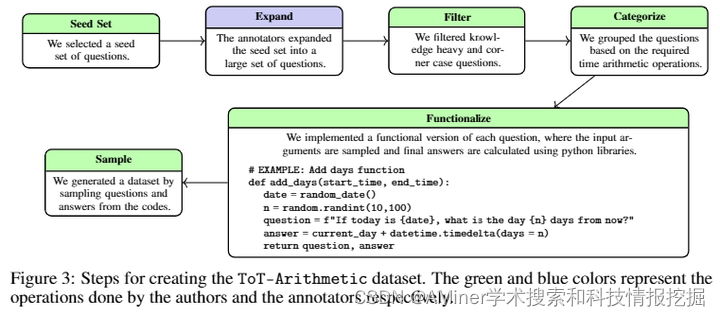
链接:https://www.aminer.cn/pub/666ba41801d2a3fbfc11ac50/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









