






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
这篇论文提出对当前大型语言模型(LLM)剪枝的做法进行重新思考。作者通过分而治之的策略,将模型分解为子模型,依次剪枝,然后在小规模的校准数据上逐个重建密集对应物的预测;最终通过组合这些结果得到的稀疏子模型来获得最终模型。尽管这种方法能够在内存限制下进行剪枝,但它会产生高的重建误差。作者首先提出了一系列可以显著减少这种误差的重建技术,这些技术可以将误差降低超过90%。然而,作者无意中发现,最小化重建误差并不总是理想的,因为它可能会过拟合给定的校准数据,导致语言困惑度增加和下游任务性能下降。作者发现,生成校准数据的自我策略可以缓解重建和泛化之间的这种权衡,为剪枝LLM的存在提供了新的方向。
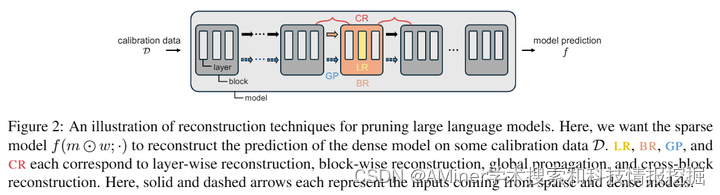
链接:https://www.aminer.cn/pub/667a250f01d2a3fbfc7069f8/?f=cs
2.Building on Efficient Foundations: Effectively Training LLMs with Structured Feedforward Layers
这篇论文探讨了如何有效地训练大规模语言模型(LLM),特别是针对transformer架构中计算密集型的前馈网络(FFN)。作者考虑了在FFN中通过结合有效的低秩和块对角矩阵来近似三个线性层候选方案。与之前的研究不同,本研究从零开始训练这些结构,并将参数扩展到13亿,同时针对最近的基于transformer的LLM,而不是卷积架构。研究首先证明了这些近似可以在各种场景下带来实际的计算收益,包括在使用预合并技术时在线解码。此外,作者提出了一种新的训练方法,称为自我引导训练,旨在改善这些近似在初始化时表现出的较差训练动态。在大型RefinedWeb数据集上的实验表明,我们的方法在训练和推理中都是高效且有效的。有趣的是,这些结构化的FFN显示出比原始模型更陡的缩放曲线。进一步将自我引导训练应用于具有32% FFN参数和2.5倍加速的结构化矩阵,在相同的训练FLOPs下,仅增加了0.4的困惑度。最后,我们开发的宽和结构化网络在困惑度和吞吐量性能上超过了当前的中型和大型transformer。
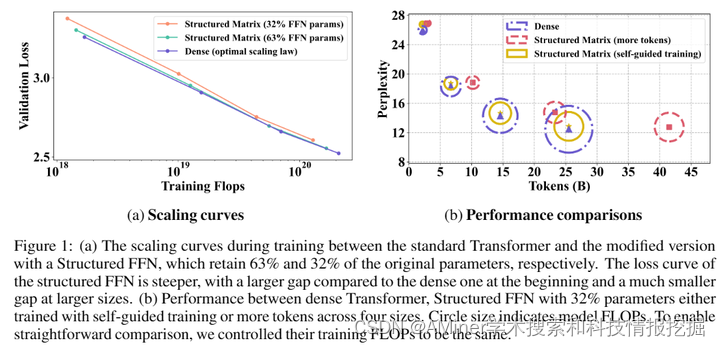
链接:https://www.aminer.cn/pub/667a253f01d2a3fbfc715456/?f=cs
3.EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
EAGLE-2是一种更快的语言模型推理方法,它采用了动态草稿树的技术。与传统的EAGLE方法相比,EAGLE-2考虑了草稿令牌的接受率不仅与其位置有关,还与其上下文有关。这一改进利用了EAGLE草稿模型校准良好的特性,即草稿模型的置信度分数与接受率接近,误差较小。在三个系列的大型语言模型和六个任务上进行了大量评估,EAGLE-2实现了3.05x-4.26x的加速比例。同时,EAGLE-2确保了生成文本的分布保持不变,因此它是一种无损加速算法。
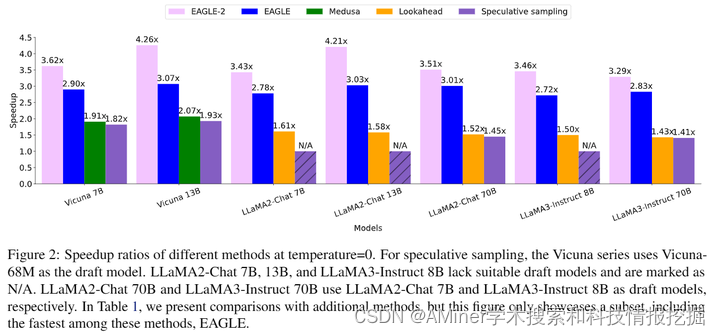
链接:https://www.aminer.cn/pub/667a253f01d2a3fbfc715621/?f=cs
4.Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
这篇论文提出了一种名为语义熵探针(Semantic Entropy Probes,简称SEPs)的方法,用于检测大型语言模型(LLMs)中的虚构内容,即“幻觉”。幻觉是指听起来合理但事实上不正确且任意的模型生成内容,这对LLMs的实际应用构成了重大挑战。尽管Farquhar等人(2024年)提出的语义熵(SE)可以通过估计模型生成内容在语义意义空间中的不确定性来检测幻觉,但其计算成本的5至10倍增加阻碍了其实际应用。为了解决这个问题,本文提出的SEPs方法可以直接从单个生成的隐藏状态来近似语义熵,无需在测试时对多个模型生成进行采样,从而将语义不确定性量化的人力成本降低到几乎为零。研究结果显示,SEPs在检测幻觉和推广到分布外数据方面的表现优于之前直接预测模型准确性的探针方法。在不同模型和任务中的实验结果表明,模型的隐藏状态可以捕获语义熵,而消融研究进一步提供了关于哪些标记位置和模型层适用于这一现象的见解。
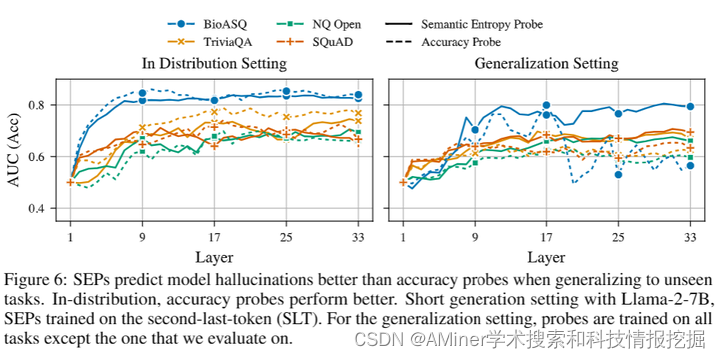
链接:https://www.aminer.cn/pub/667a253e01d2a3fbfc71517c/?f=cs
5.Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
本文探讨了大型语言模型(LLM)在处理长输入上下文时遇到的“中间迷失”问题,即难以捕捉到位于输入中间的相关信息。研究首先分析了导致该问题的因素,并发现LLM内在的注意力偏差是原因之一:LLM表现出U型注意力偏差,即无论相关性如何,其输入开头的和结尾的标记都会获得更高的关注。接着,通过一种名为“found-in-the-middle”的校准机制来减轻这种位置偏差,该机制使得模型能够根据相关性忠实于上下文地分配关注,即使相关信息位于中间。研究还表明,“found-in-the-middle”不仅提高了在长上下文中定位相关信息的表现,而且最终还导致了在不同任务中改进了检索增强生成(RAG)的性能,比现有方法高出最多15个百分点。这些发现为未来在理解LLM注意力偏差及其潜在后果方面提供了方向。

链接:https://www.aminer.cn/pub/667a253e01d2a3fbfc71524b/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









