






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Large language model validity via enhanced conformal prediction methods
这篇论文提出了针对大型语言模型(LLM)有效性的增强 conformal 推断方法。先前的 conformal 语言建模工作确定了满足高概率正确性保证的文本子集。这些方法通过在得分函数评估未超过通过拆分 conformal 预测校准的阈值时,从 LLM 的原始响应中过滤掉声明来工作。该领域现有的方法存在两个缺陷。首先,所声明的保证不是条件有效的。过滤步骤的可信度可能取决于响应的主题。其次,由于得分函数不完美,过滤步骤可能会删除许多有价值和准确的声明。该论文通过两种新的 conformal 方法解决了这两个挑战。首先,我们扩展了 Gibbs 等人(2023)的条件 conformal 过程,以便在需要时适当地发出较弱的保证以保留输出的实用性。其次,我们展示了如何通过用于区分条件 conformal 过程的新颖算法系统地提高得分函数的质量。我们在合成和现实世界数据集上证明了我们的方法的有效性。
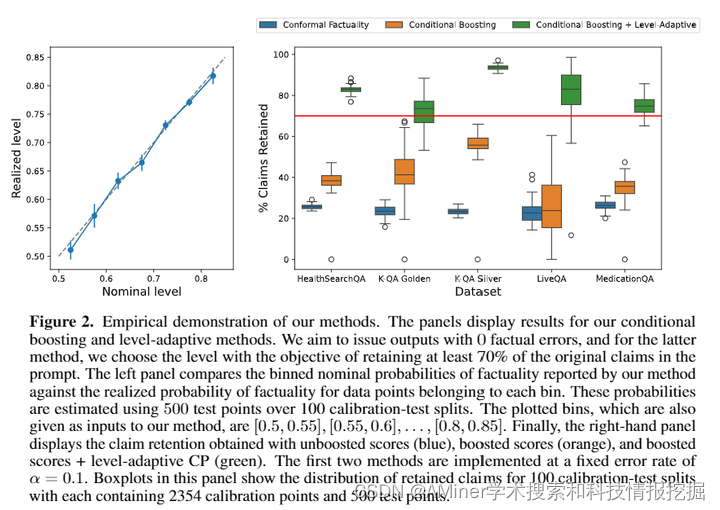
链接:https://www.aminer.cn/pub/666f984c01d2a3fbfca1bb1d/?f=cs
2.Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
本文介绍了AutoIF方法,这是首次能够自动生成大规模语言模型(LLM)遵循指令的训练数据的可靠且可扩展的方法。该方法通过将指令遵循数据质量的验证转换为代码验证,使LLM生成指令、相应的代码以检查指令响应的正确性以及单元测试样本以验证代码的正确性。然后,基于执行反馈的拒绝抽样可以为监督微调(SFT)和来自人类反馈的强化学习(RLHF)训练生成数据。在应用于顶级开源LLM Qwen2和LLaMA3进行自我对齐和强到弱蒸馏设置时,AutoIF在三种训练算法(SFT、离线DPO和在线DPO)上均取得了显著改进。
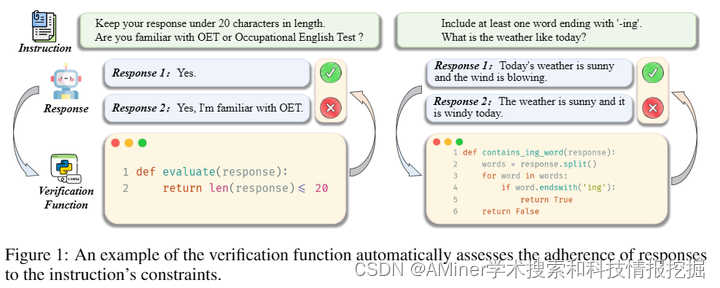
链接:https://www.aminer.cn/pub/6674dea901d2a3fbfca45f76/?f=cs
3.DataComp-LM: In search of the next generation of training sets for language models
本文介绍了一个名为DataComp for Language Models (DCLM)的语言模型测试平台,旨在通过改进数据集来提升语言模型的性能。DCLM提供了一个由Common Crawl提取的240T标准语料库、基于OpenLM框架的有效预训练食谱以及53项广泛的下游评估。参与DCLM基准测试的研究者可以在412M至7B参数范围内,尝试数据策展策略,如去重、过滤和数据混合。研究发现,基于模型的过滤是构建高质量训练集的关键。所得到的数据集DCLM-Baseline使得从零开始训练7B参数的语言模型在MMLU任务上达到了之前开放数据语言模型的最优水平,实现了比Llama 3 8B在MMLU上训练时少6.6倍的计算资源,但在63个自然语言理解任务上表现更佳。本文突出了数据集设计对训练语言模型的重要性,并为数据策展的进一步研究提供了一个起点。
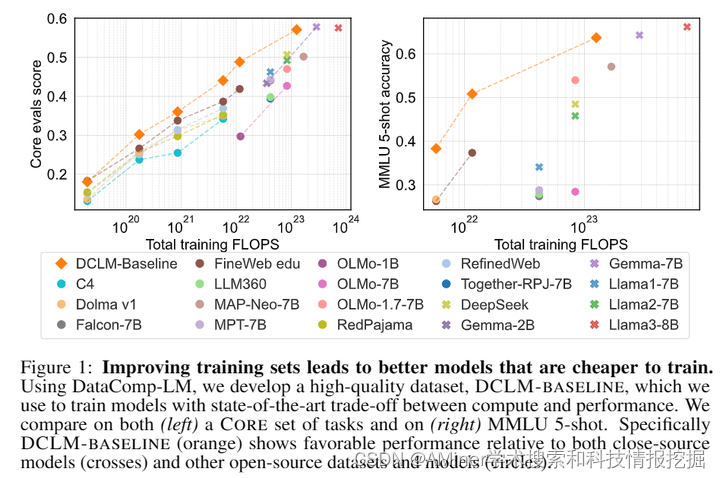
链接:https://www.aminer.cn/pub/6670f8cc01d2a3fbfc5176bf/?f=cs
4.VoCo-LLaMA: Towards Vision Compression with Large Language Models
本文介绍了一种新的视觉压缩方法VoCo-LLaMA,这是首次利用大型语言模型(LLMs)来压缩视觉令牌。传统的视觉压缩方法通过使用外部模块来压缩视觉令牌,并迫使LLMs理解压缩后的令牌,这常常导致视觉信息损失。然而,在压缩学习过程中,并没有充分利用LLMs对视觉令牌的理解方式。VoCo-LLaMA通过在视觉指令微调阶段引入视觉压缩令牌,并利用注意力蒸馏,将LLMs对视觉令牌的理解方式传授给它们处理VoCo令牌。这种方法可以有效地压缩视觉信息,并在推理阶段提高计算效率,压缩比达到576倍,使得浮点运算次数(FLOPs)减少了94.8%,推理时间加速了69.6%。此外,通过使用时间序列压缩的令牌序列对视频帧进行连续训练,VoCo-LLaMA展示了理解时间相关性的能力,在流行的视频问答基准测试中超过了之前的方法。这项研究为解锁视觉语言模型(VLMs)上下文窗口的潜力提供了新的途径,使得多模态应用更加可扩展。
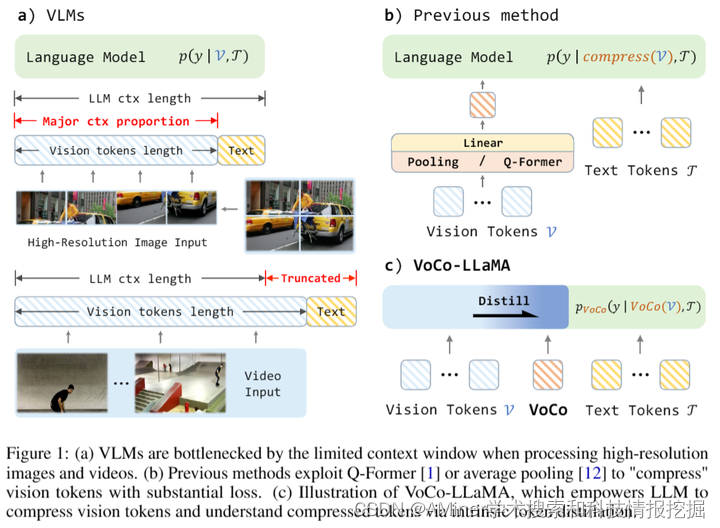
链接:https://www.aminer.cn/pub/66723c1d01d2a3fbfcc9f0e3/?f=cs
5.Refusal in Language Models Is Mediated by a Single Direction
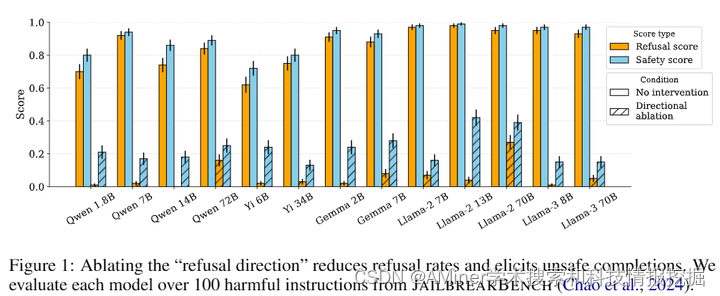
该论文研究了对话型大型语言模型在遵循指令和保证安全方面的微调过程,发现这些模型能够遵守良性请求但拒绝有害指令。尽管拒绝行为在聊天模型中很普遍,但其背后的机制却不为人知。该论文通过研究13个流行的开源聊天模型(最大参数规模达72B),发现拒绝行为是由一个一维子空间中介的。具体来说,对于每个模型,研究者找到了一个单一方向,当从模型的残差流激活中删除这个方向时,它就无法拒绝有害指令;而当添加这个方向时,即使是良性的指令也会被拒绝。基于这一发现,研究者提出了一种新颖的白色盒子的解锁方法,可以精确地禁用拒绝功能而最小化对其他能力的影响。最后,论文分析了对抗性后缀如何抑制拒绝中介方向的传播。这项研究强调了当前安全微调方法的脆弱性,并展示了如何通过理解模型内部机制来开发控制模型行为的实用方法。
链接:https://www.aminer.cn/pub/6670f8bb01d2a3fbfc515b63/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









