






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
本文介绍了一种新的激活稀疏技术,称为Turbo Sparse,旨在加速大型语言模型(LLM)的推理过程,同时不牺牲性能。为了解决现有稀疏技术效果有限的问题,作者提出了一个新颖的dReLU函数,该函数能提高LLM的激活稀疏度,并搭配高质量的训练数据混合比例以有效稀疏化。此外,文章还利用混合专家(MoE)模型中的前馈网络(FFN)专家的稀疏激活模式,进一步提高效率。通过将提出的神经元稀疏化方法应用于Mistral和Mixtral模型,分别在每次推理迭代中激活25亿和43亿参数,同时实现了更强大的模型性能。评估结果显示,这种稀疏性可以实现2-5倍的解码加速。值得注意的是,在手机上,TurboSparse-Mixtral-47B的推理速度达到了每秒11个token。
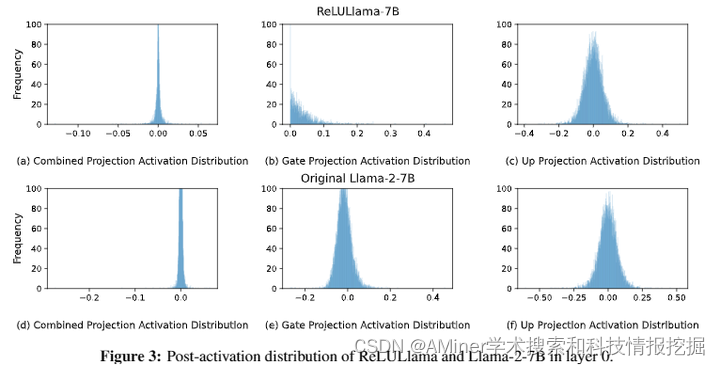
链接:https://www.aminer.cn/pub/6667b02401d2a3fbfc2e397b/?f=cs
2.MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models
这篇论文提出了一种名为MATES的数据选择方法,旨在提高语言模型预训练的效率。现有的数据选择方法通常是静态的,依赖于人为制定的规则或大型参考模型,并不能捕捉到预训练过程中数据偏好的变化。MATES通过使用数据影响模型,在预训练过程中动态地适应数据偏好的变化,选择最适合当前预训练进度的数据。实验结果表明,在零样本和少样本设置中,MATES在多个下游任务上显著优于随机数据选择方法,其效果优于最近利用大型参考模型的数据选择方法,并且能够将达到特定性能所需的总浮点运算次数减半。进一步的分析验证了预训练模型数据偏好的不断变化以及数据影响模型捕捉这些变化的有效性。
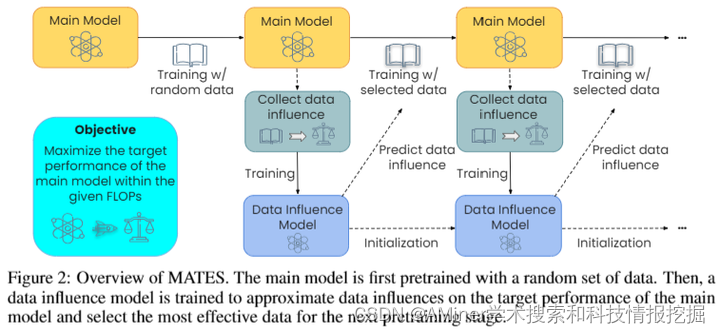
链接:https://www.aminer.cn/pub/6667b02401d2a3fbfc2e39e7/?f=cs
3.Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
本文探讨了在使用合成数据微调大型语言模型时出现的模型坍塌问题,并提出了利用合成数据上的反馈来防止模型坍塌的方法。作者推导出在何种条件下,高斯混合分类模型在用增强型合成数据训练时能达到渐进最优性能,并通过模拟验证了这些条件在有限区域内的有效性。文中还通过两个实际问题展示了理论预测的应用:一是利用变压器计算矩阵特征值,二是利用大型语言模型进行新闻摘要,这两个问题在仅使用模型生成的数据训练时都会出现模型坍塌。作者发现,通过增强型合成数据训练,不管是通过剔除错误预测还是选择多个猜测中的最佳结果,都能有效防止模型坍塌,这也验证了像RLHF这样的流行方法的有效性。
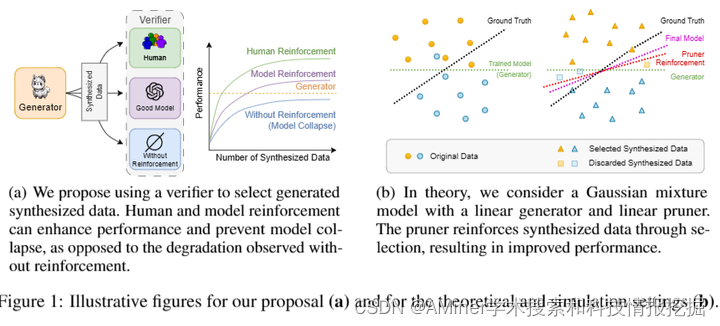
链接:https://www.aminer.cn/pub/6669033801d2a3fbfc452c28/?f=cs
4.It Takes Two: On the Seamlessness between Reward and Policy Model in RLHF
这篇论文探讨了在强化学习从人类反馈(RLHF)中,政策模型(PMs)和奖励模型(RMs)之间的无缝协作问题。RLHF涉及训练PMs和RMs以使语言模型与人类偏好保持一致。作者提出在微调过程中研究它们之间的互动,引入了“无缝”这一概念。研究起始于观察到一个饱和现象,即RM和PM的持续改进并没有带来RLHF的进步。分析表明,RMs不能为PM的响应分配合适的分数,导致PM和RM之间存在显著的偏差。为了衡量PM和RM之间的无缝程度,作者提出了一种自动度量方法SEAM,它量化了由数据样本引起的PM和RM判断之间的偏差。作者通过数据选择和模型增强来验证SEAM的有效性。实验证明,使用SEAM过滤的数据进行RL训练可以提高RLHF的性能4.5%,而SEAM指导的模型增强比标准增强方法效果更佳。
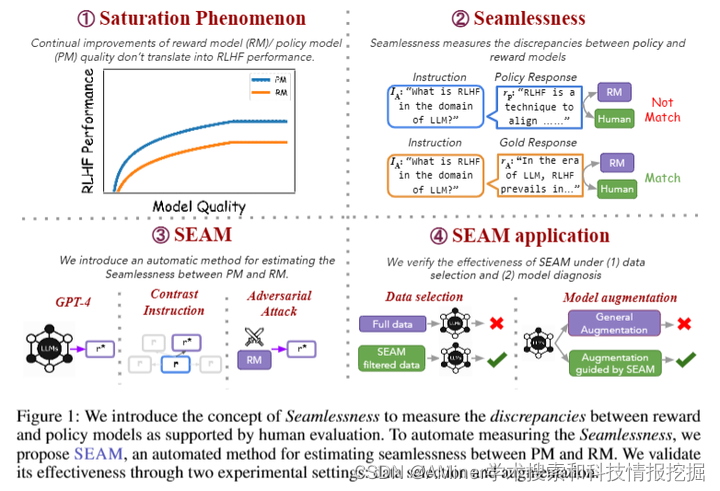
链接:https://www.aminer.cn/pub/666a52ae01d2a3fbfc634ba2/?f=cs
5.Mistral-C2F: Coarse to Fine Actor for Analytical and Reasoning Enhancement in RLHF and Effective-Merged LLMs
本文介绍了一种新的两步粗到细的演员模型Mistral-C2F,以提高小型LLM(如Llama和Mistral)在对话和分析能力方面的固有限制。该方法首先利用基于策略的粗演员和一种名为“连续最大化”的技术来建立一个增强的、知识丰富的池,以适应人类的分析和建议风格。然后通过RLHF过程,采用连续最大化策略,动态地、适应性地延长输出长度限制,从而生成更详细和分析性的内容。随后,细演员对这种分析性内容进行细化,解决粗演员生成过多冗余信息的问题。我们引入了一种“知识残差融合”方法,对粗演员生成的内容进行细化,并与现有的指令模型融合,以提高质量、正确性并减少冗余。我们将这种方法应用于流行的Mistral模型,创建了Mistral-C2F,该模型在11个通用语言任务和MT-Bench对话任务中表现出色,甚至超过了具有13B和30B参数的大型模型。我们的模型显著提高了对话和分析推理能力。
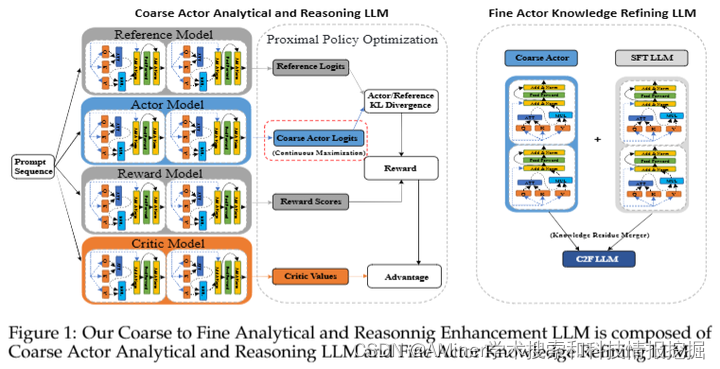
链接:https://www.aminer.cn/pub/666ba41801d2a3fbfc11aa70/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









