







从图像分类到图像分割
卷积神经网络(CNN)自2012年以来,在图像分类和图像检测等方面取得了巨大的成就和广泛的应用。
CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。
这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
传统的基于CNN的分割方法的做法通常是:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,则所需的存储空间为原来图像的225倍。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
针对这个问题, UC Berkeley的Jonathan Long等人提出了Fully Convolutional Networks (FCN) [1] 用于图像的分割。该网络试图从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
FCN的原理
FCN将传统CNN中的全连接层转化成一个个的卷积层。如下图所示,在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
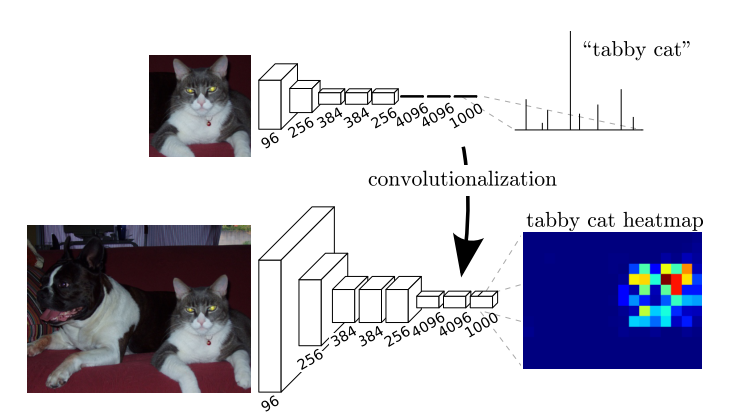
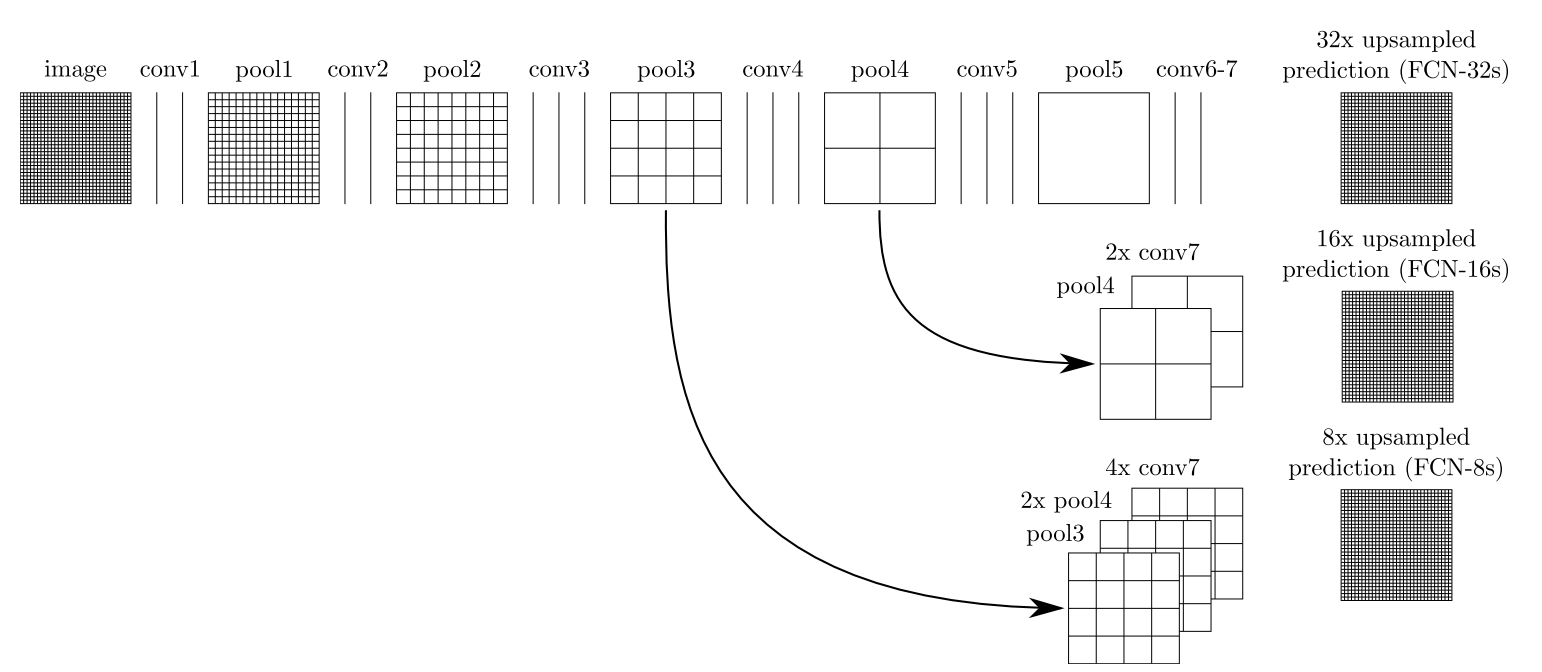
可以发现,经过多次卷积(还有pooling)以后,得到的图像越来越小,分辨率越来越低(粗略的图像),那么FCN是如何得到图像中每一个像素的类别的呢?为了从这个分辨率低的粗略图像恢复到原图的分辨率,FCN使用了上采样。例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。
这个上采样是通过反卷积(deconvolution)实现的。对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是Jonathan将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是这个卷积和反卷积上采样的过程:
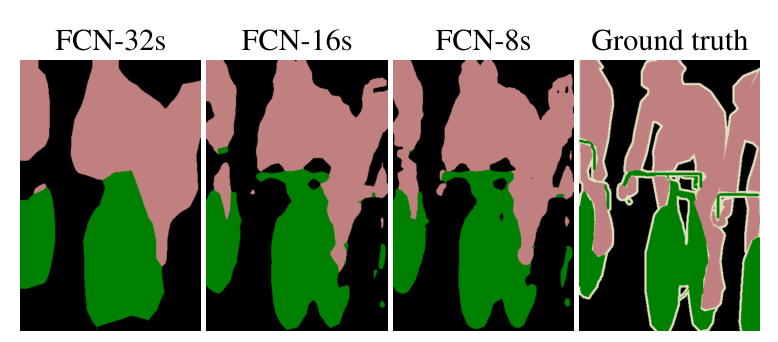
下图是32倍,16倍和8倍上采样得到的结果的对比,可以看到它们得到的结果越来越精确:
FCN的优点和不足
与传统用CNN进行图像分割的方法相比,FCN有两大明显的优点:一是可以接受任意大小的输入图像,而不用要求所有的训练图像和测试图像具有同样的尺寸。二是更加高效,因为避免了由于使用像素块而带来的重复存储和计算卷积的问题。
同时FCN的缺点也比较明显:一是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。二是对各个像素进行分类,没有充分考虑像素与像素之间的关系,忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
FCN的扩展
虽然FCN不够完美,但是其全新的思路开辟了一个新的图像分割方向,对这个领域的影响是十分巨大的,从2015年3月在arxiv和6月在CVPR会议上发表到写下这篇博客的时候一年的时间,该文章已被引用高达400次。
在FCN的基础上,UCLA DeepLab的Liang-Chieh Chen [2] 等在得到像素分类结果后使用了全连接的条件随机场(fully connected conditional random fields),考虑图像中的空间信息,得到更加精细并且具有空间一致性的结果。
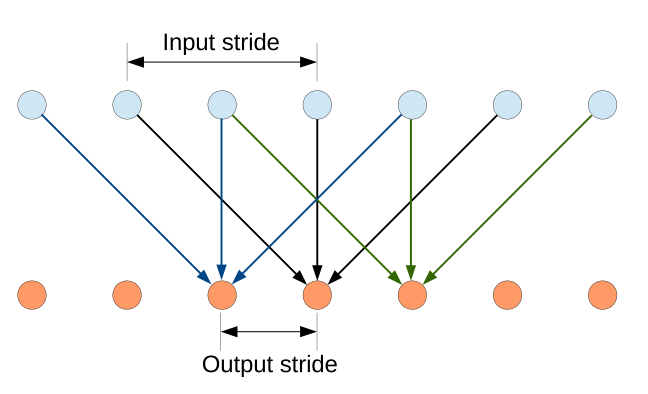
Liang-Chieh的这篇文章有两大特点,一是忽略下采样过程,转而使用稀疏的卷积核以增加感知范围。如下图所示:
二是使用了Fully Connected CRF。CRF的能量函数中包括数据项和平滑项两部分,数据项与各个像素属于各类别的概率有关,平滑项控制像素与像素间类别的一致性。传统的CRF的平滑项只考虑相邻像素类别的关联性,而Fully Connected CRF将图像中任意两个像素之间的类别关联性都考虑进来。
下图是CNN与Fully Connected CRF结合的示意图。
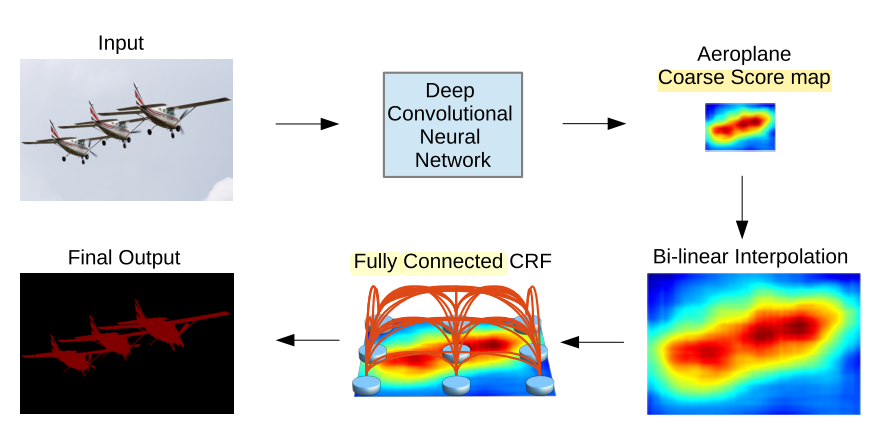
实际上,CRF或者Fully Connected CRF是对CNN或者FCN输出的一种后处理技术。像素分类和空间规整这两步是分别进行的。Shuai Zheng
[3]
等人将Fully Connected CRF表示成回流神经网络的结构(recurrent neuron network,RNN),将CNN与这个RNN放到一个统一的框架中,可以一步到位地对两者同时进行训练。将图像分割中的三个步骤:特征提取、分类器预测和空间规整全部自动化处理,通过学习获得,得到的结果比FCN-8s和DeepLab的方法的效果好了许多。如下图结果:

CNN、FCN与Fully Connected CRF的结合及统一的自动训练具有很不错的应用价值,已有很多的研究对这几篇文章进行跟进([2]和[3]的引用都已过百)。例如,帝国理工的Konstantinos Kamnitsas,Daniel Rueckert等人在这几篇文章的基础上,提出了三维的多尺度CNN和全连接CRF结合的方法,称为DeepMedic, 用于脑肿瘤的分割,最近(4月4号)刚发表于arXiv。
参考文献
1,Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
2,Chen, Liang-Chieh, et al. “Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062 (2014).
3,Zheng, Shuai, et al. “Conditional random fields as recurrent neural networks.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
4,Kamnitsas, Konstantinos, et al. “Efficient Multi-Scale 3D CNN with Fully Connected CRF for Accurate Brain Lesion Segmentation.” arXiv preprint arXiv:1603.05959 (2016).















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









