









整体思路
训练流程和传统的神经网络类似,构建loss function,然后根据BP算法进行训练,不同之处在于传统的神经网络的训练准则是针对每帧数据,即每帧数据的训练误差最小,而CTC的训练准则是基于序列(比如语音识别的一整句话)的,比如最大化 p(z|x) ,序列化的概率求解比较复杂,因为一个输出序列可以对应很多的路径,所有引入前后向算法来简化计算。
前期准备
- 输入
x ,长度为T - 输出集合
A 表示正常的输出
A′=A⋃{blank} 表示输出全集
A′T 表示输入x对应的输出元素集合 - 输出序列
π 表示输出路径
l 表示输出label序列
表示路径到label序列的映射关系 - 概率
ytk 表示时间t输出k的概率
p(π|x)=∏t=1Tytπt 表示基于输入x的输出 π 路径的概率
p(l|x)=∑π∈−1(l)p(π|x) 表示输出label序列的概率是多条路径的概率和。
前后向算法
考虑到计算
p(l|x)
需要计算很多条路径的概率,随着输入长度呈指数化增加,可以引入类似于HMM的前后向算法来计算该概率值。
为了引入blank节点,在label首尾以及中间插入blank节点,如果label序列原来的长度为U,那么现在变为U’=2U+1。
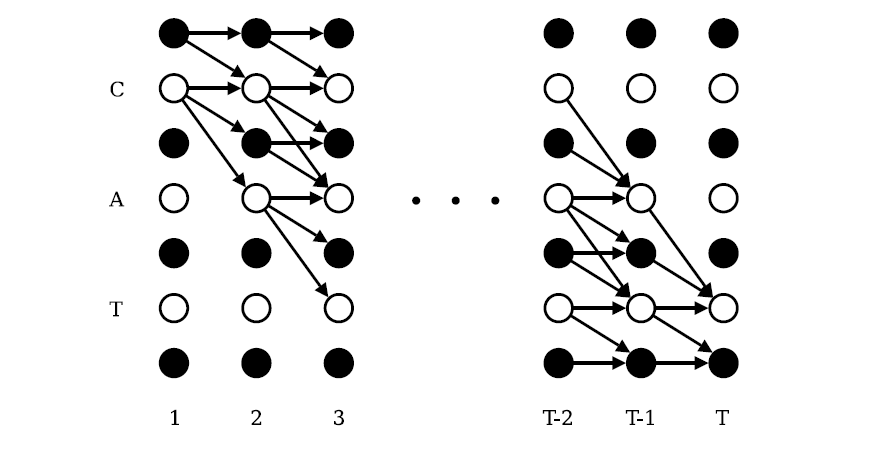
前向
前向变量为
α(t,u)
,表示t时刻在节点u的前向概率值,其中
u∈[1,2U+1]
.
初始化值如下:
α(1,1)=y1b
α(1,2)=y1l1
α(1,u)=0,∀u>2
递推关系:
α(t,u)=ytl′u∑i=f(u)uα(t−1,i)
其中
f(u)={u−1u−2if l′u=blank or l′u−2=l′uotherwise
注:如果l表示{c,a,t},那么l’表示为{b,c,b,a,b,t,b},所以原来在l中的下标u为2,在l’中的下标u变为4。
α(t,u)=0∀u<U′−2(T−t)−1
对应于上图中的右上角部分,因为时间的限制,有些节点不可能到达最后的终止节点。
根据上图,很容易理解前向的递推关系。
后向
初始化值:
β(T,U′)=1
β(T,U′−1)=1
β(T,u)=0,∀u<U′−2
α(1,u)=0,∀u>2
递推关系:
β(t,u)=∑i=ug(u)β(t+1,i)yt+1l′i
其中
g(u)={u+1u+2if l′u=blank or l′u+2=l′uotherwise
取log
概率计算在log计算,避免underflow,其中log加可以通过以下形式转化:
ln(a+b)=lna+ln(1+elnb−lna)
训练
loss function
CTC的loss function使用最大似然:
L(S)=∑(x,z)∈SL(x,z)
L(x,z)=−lnp(z|x)
根据前后向变量,可以求得:
p(z|x)=∑u=1|z′|α(t,u)β(t,u)
|z′| 表示z对应的label长度的U’, α(t,u)β(t,u) 表示t时刻经过节点u的所有路径的概率和。
L(x,z)=−ln∑u=1|z′|α(t,u)β(t,u)
bp训练
ytk
表示t时刻输出k的概率
atk
表示t时刻对应输出节点k在做softmax转换之前的值
∂L(x,z)∂ytk=−1p(z|x)∂p(z|x)∂ytk
只需要考虑t时刻经过k节点的路径即可
∂p(z|x)∂ytk=∑u∈B(z,k)∂α(t,u)β(t,u)∂ytk
其中 B(z,k) 表示节点为k的集合
考虑到
α(t,u)β(t,u)=∑π∈X(t,u)∏t=1Tytπt
其中 X(t,u) 表示所有在t时刻经过节点u的路径。
所以
∂p(z|x)∂ytk=∑u∈B(z,k)α(t,u)β(t,u)ytk
可以到损失函数对 ytk 偏导数
∂L(x,z)∂ytk=−1p(z|x)ytk∑u∈B(z,k)α(t,u)β(t,u)
同时可以得到损失函数对于 atk 偏导数
∂L(x,z)∂atk=ytk−1p(z|x)∑u∈B(z,k)α(t,u)β(t,u)
推导参考:


后续可以使用 BPTT算法 得到损失函数对神经网络参数的偏导。
参考
《Supervised Sequence Labelling with Recurrent Neural Networks》 chapter7















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









