







 本文详细介绍了基于GNN的图表示学习,包括图表示学习原理、不同方法(分解、随机游走、深度学习)对比,重点讲解了GNN在重构损失(如GAE)和对比损失(如DGI)下的应用,以及其在图数据表示学习中的优势和挑战。
本文详细介绍了基于GNN的图表示学习,包括图表示学习原理、不同方法(分解、随机游走、深度学习)对比,重点讲解了GNN在重构损失(如GAE)和对比损失(如DGI)下的应用,以及其在图数据表示学习中的优势和挑战。
图神经网络GNN学习笔记:基于GNN的图表示学习
本文主要就基于GNN的无监督图表示学习进行详解。在实际的应用场景中,大量的数据标签往往具有很高的获取门槛,研究如何对图数据进行高效的无监督表示学习具有十分重要的价值。
1. 图表示学习
图表示学习(graph embedding)又可以称为网络表示学习(network embedding),或者称为网络嵌入,主要目标是将图数据转化成低维稠密的向量化表示,同时确保图数据中的某些性质在向量空间中也能够得到对应。
这里的图数据的表示可以是节点层面的,也可以是全图层面的,但是作为图数据的基本构成元素,节点的表示学习一直是图表示学习的主要对象。
一种图数据的表示如果能够包含丰富的语义信息,那么下游的相关任务,如点分类、边预测、图分类等,就都能得到相当优秀的输入特征,通常在这种情况下,直接选用线性分类器对任务进行学习。
不同的是,图表示学习的研究对象是图数据,图数据中蕴含着丰富的结构信息,这对应着图数据因内在关联而产生的一种非线性结构。因此,图表示学习具有以下两个重要作用:
(1)将图数据表示成线性空间中的向量。
(2)位置后的学习任务奠定基础。
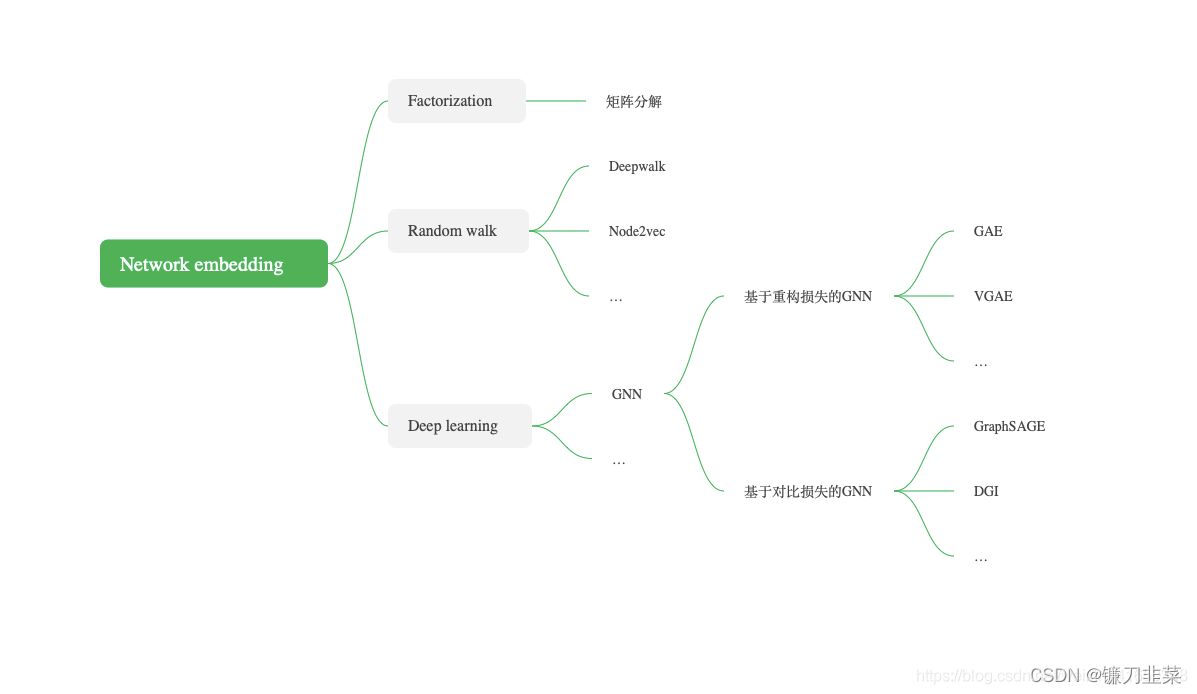
图表示学习从方法上来说,可以分为基于分解的方法、基于随机游走的方法,以及基于深度学习的方法,如下图所示。而基于深度学习的方法的典型代表就是GNN相关的方法。
-
早期,图节点的嵌入学习一般是基于分解的方法,通过对描述图数据结构信息的矩阵进行矩阵分解,将节点转化到低维向量空间中,同时保留结构上的相似性。描述结构信息的矩阵有:
邻接矩阵、拉普拉斯矩阵、节点相似度矩阵。一般这类方法都有解析解,但是由于结果依赖相关矩阵的分解计算,因此,这类方法具有很高的时间和空间复杂度。 -
最近,词向量方法在语言表示上取得了很大成功,因此一些方法将图中随机游走产生的序列看作句子,将节点看作词,以此类比词向量方法从而学习出节点的表示,典型方法有:
DeepWalk,Node2Vec等。
DeepWalk通过随机游走将图转化为节点序列,设置中心节点左右距离为 w w w的节点为上下文(context)。本质上,DeepWalk建模了中心节点与上下文节点之间的共现关系,这种关系的学习也采用了负采样的优化手段。另外DeepWalk与词向量方法具有十分一致的算法细节。
基于随机游走的方法的最大的优点是通过将图转化为序列的方式实现了大规模图的表示学习。缺点是:1. 图本身的结构信息没有被充分利用;2. 很难融合图中的属性信息进行表示学习。 -
基于深度学习的方法,例如,基于GNN的图表示学习具有以下优势:
(1)非常自然地融合了图的属性信息进行学习
(2)GNN本身作为一个可导的模块,能够嵌入到任意一个支持端对端学习的系统中去,使其能够与各个层面的有监督学习任务进行有机结合
(3)GNN的很多模型如GraphSAGE、MPNN等都是支持归纳学习的,多数情况下对于新数据的表示学习可以直接进行预测,而不必重新训练
(4)分解类的方法适用小图的学习,而GNN既保证了算法的工程性,又适应大规模图的学习任务。
| 类别 | 主要思想 | 代表模型 | 优点 | 缺点 |
|---|---|---|---|---|
| 基于分解的方法 | 对结构信息进行矩阵分解 | - | - | 具有很高的计算复杂度 |
| 基于随机游走的方法 | 将随机游走所产生的序列看作是句子,节点看作是词,类比词向量Skip-gram等模型的学习方法 | DeepWalk、Node2Vec等 | 将图转化为序列,实现了大规模图的学习 | ①图本身的结构信息没有充分利用 ②很难融合属性信息进行表示学习 |
| 基于深度学习的方法 | 主要是使用基于GNN的方法进行表示学习 | GraphSAGE、GAE、DGI等 | ①融合结构和属性信息进行表示学习 ②可以将表示学习和任务学习有机结合 ③能够适应大规模图 | 在模型深度、过平滑问题等方面仍面临挑战 |
2. 基于GNN的图表示学习
依据损失函数(Loss Function)的不同,基于GNN的无监督图表示学习方法可分为2类:
(1)基于重构损失的GNN
(2)基于对比损失的GNN
2.1 基于重构损失的GNN
主要思想类似于自编码器(AE),将节点之间的邻接关系进行重构学习,并将重构的矩阵与原矩阵进行相似度对比,来更新参数。因此,这类方法也叫作图自编码器(Graph Auto Encoder, GAE)。
Z
=
G
N
N
(
X
,
A
)
Z=GNN(X, A)
Z=GNN(X,A)
A
^
=
σ
(
Z
Z
T
)
\hat{A}=\sigma(ZZ^T)
A^=σ(ZZT)
其中
Z
Z
Z是所有节点的表示矩阵,这里借助GNN模型同时对图的属性信息和结构信息进行编码学习。
A
^
\hat{A}
A^是重构后的邻接矩阵,这里适用向量的内积来表示节点之间的邻接关系。
图自编码器的重构损失定义如下: L o s s r e c o n = ∣ ∣ A ^ − A ∣ ∣ 2 Loss_{recon}=||\hat{A}-A||^2 Lossrecon=∣∣A^−A∣∣2
由于过平滑的问题,GNN可以轻易地将相邻节点学习出相似的表达,导致解码出来的邻接矩阵
A
^
\hat{A}
A^能够很快趋近于原始邻接矩阵A,模型参数难以得到有效优化。因此,为了使GNN习得更加有效的数据分布式表示,必须对损失函数加上一些约束目标。即为了防止过平滑的问题,需要加入一些噪声,迫使模型从加噪的数据中学习到有用的信息用于恢复原数据:
(1)对原图数据的特征矩阵
X
X
X适当增加随机噪声或进行置零处理;
(2)对原图数据的邻接矩阵A删除适当比例的边,或者修改边上的权重值。
另外,也可以借助其他自编码器中的设计思路。例如变分图自编码器(Variational Graph Autoencoder, VGAE)。VGAE的基础框架和变分自编码器一样,不同的是使用了GNN来对图数据进行编码学习。从三个方向介绍其基础框架:
(1)推断模型(编码器)
q
(
Z
∣
X
,
A
)
=
∏
i
=
1
N
q
(
z
i
∣
X
,
A
)
q(Z|X, A)= {\textstyle \prod_{i=1}^{N}}q(z_i|X, A)
q(Z∣X,A)=∏i=1Nq(zi∣X,A)
q
(
Z
i
∣
X
,
A
)
=
N
(
z
i
∣
μ
i
,
d
i
a
g
(
σ
i
2
)
)
q(Z_i|X, A)=N(z_i|\mu _i, diag(\sigma_i^2))
q(Zi∣X,A)=N(zi∣μi,diag(σi2))与VAE不同,这里使用两个GNN对
μ
,
σ
\mu, \sigma
μ,σ进行拟合:
μ
=
G
N
N
μ
(
X
,
A
)
,
log
σ
=
G
N
N
σ
(
X
,
A
)
\mu=GNN_{\mu}(X, A), \log{\sigma}=GNN_\sigma(X, A)
μ=GNNμ(X,A),logσ=GNNσ(X,A)
(2)生成模型(解码器)
p
(
A
∣
Z
)
=
∏
i
=
1
N
∏
j
=
1
N
p
(
A
i
j
∣
z
i
,
z
j
)
p(A|Z)=\prod_{i=1}^{N} \prod_{j=1}^{N}p(A_{ij}|z_i,z_j)
p(A∣Z)=i=1∏Nj=1∏Np(Aij∣zi,zj)
p
(
A
i
j
=
1
∣
z
i
,
z
j
)
=
σ
(
z
i
T
,
z
j
)
p(A_{ij}=1|z_i,z_j)=\sigma(z_i^T,z_j)
p(Aij=1∣zi,zj)=σ(ziT,zj)
这里也简单使用了两个节点表示向量的内积来拟合邻居关系。
(3)损失函数
L
o
s
s
=
L
o
s
s
r
e
c
o
n
+
L
o
s
s
K
L
=
−
E
q
(
Z
∣
X
,
A
)
[
log
p
(
A
∣
Z
)
]
+
K
L
[
q
(
Z
∣
X
,
A
)
∣
∣
p
(
Z
)
]
Loss=Loss_{recon}+Loss_{KL}=-E_{q(Z|X,A)}[\log{p(A|Z)}]+KL[q(Z|X,A)||p(Z)]
Loss=Lossrecon+LossKL=−Eq(Z∣X,A)[logp(A∣Z)]+KL[q(Z∣X,A)∣∣p(Z)]同样地,隐变量
z
z
z的先验分布选用标准正态分布:
p
(
Z
)
=
∏
i
p
(
z
i
)
=
∏
i
N
(
z
i
,
0
⃗
,
I
⃗
)
p(Z)=\prod_{i}p(z_i)=\prod_{i}N(z_i,\vec{0},\vec{I})
p(Z)=i∏p(zi)=i∏N(zi,0,I)
VAE和GNN的结合,不仅可以被用来学习图数据的表示,更是提供了一个图生成模型的框架,能够在相关图生成的任务中得到应用。
2.2 基于对比损失的GNN
对比损失通常会设置一个评分函数
D
(
⋅
)
D(\cdot)
D(⋅),用来提高正样本的得分、降低负样本的得分。
类比词向量的学习,在图中,节点看作是词,上下文代表与节点有对应关系的对象。通常,图里的上下文从小到大依次可以是节点的邻居、节点所处的子图、全图。如何定义节点的“上下文”就成为一个值得研究的问题。目前为止共有3中定义方式:
(1)邻居作为上下文
(2)子图作为上下文
(3)全图作为上下文
不论是何种定义方式,我们都可以定义一个通用的损失函数:
L
o
s
s
v
i
=
−
log
(
D
(
z
i
,
c
)
)
+
log
(
D
(
z
i
,
c
ˉ
)
)
Loss_{v_i}=-\log{(D(z_i,c))}+\log{(D(z_i,\bar{c}))}
Lossvi=−log(D(zi,c))+log(D(zi,cˉ)),其中
c
c
c为上下文的表示向量
c
‾
\overline{c}
c为非上下文的表示向量。
(1)邻居作为上下文
通过损失函数建模节点和邻居节点之间的关系,GraphSAGE中就使用了这种思路。主要思想类似于DeepWalk,将随机游走时与中心节点
v
i
v_i
vi一起出现在固定窗口内的节点
v
j
v_j
vj视为邻居,同时通过负采样的手段,将不符合该关系的节点作为负样本。与DeepWalk不同的是,节点的表示学习模型仍使用GNN,即:
Z
=
G
N
N
(
X
,
A
)
Z=GNN(X, A)
Z=GNN(X,A)
L
o
s
s
v
i
=
log
(
1
−
σ
(
z
i
T
,
z
j
)
)
+
E
v
n
∼
P
n
(
v
i
)
log
(
σ
(
z
i
T
,
z
v
n
)
)
Loss_{v_i}=\log{(1-\sigma(z_i^T,z_j))}+E_{v_n\sim P_n(v_i)}\log{(\sigma(z_i^T,z_{v_n}))}
Lossvi=log(1−σ(ziT,zj))+Evn∼Pn(vi)log(σ(ziT,zvn)),这里的
p
n
p_n
pn是一个关于节点出现概率的负采样分布,得分函数使用向量内积加sigmoid函数,将分数限制在
[
0
,
1
]
[0,1]
[0,1]内。该方法在优化目标上与图自编码器基本相同,但是这种负采样形式的对比优化并不需要自编码器一样显式地解码出邻接矩阵
A
^
\hat{A}
A^,由于
A
^
\hat{A}
A^破坏了原始邻接矩阵的稀疏性,因此该方法不需要承担
O
(
N
2
)
O(N^2)
O(N2)的空间复杂度。
(2)将子图作为上下文
邻居作为上下文强调的是节点之间的共现关系,但是有时候距离远的节点的结构未必没有相似之处,如此一来就缺乏对节点结构相似性的捕捉。
通常节点局部结构上的相似性是节点分类任务中一个比较关键的因素。
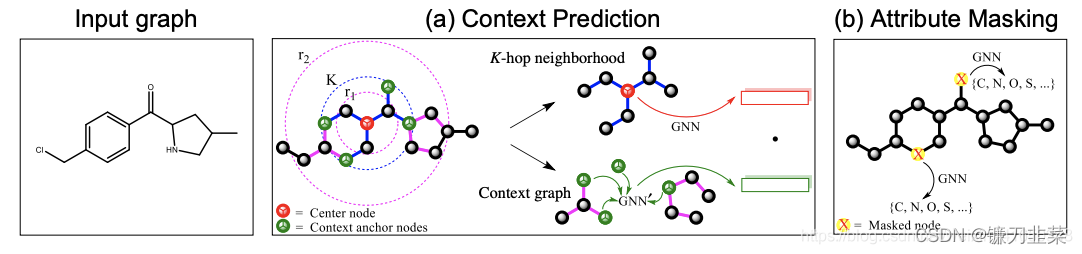
对于一个中心节点,用一个GNN在其K阶子图上提取其表示向量,同时将处于中心节点
r
1
−
h
o
p
r_1-hop
r1−hop与
r
2
−
h
o
p
r_2-hop
r2−hop之间的节点定义为该中心节点的上下文锚点。如上图所示,设
K
=
1
,
r
1
=
1
,
r
2
=
4
K=1,r_1=1,r_2=4
K=1,r1=1,r2=4,用另一个GNN来提取每个节点作为上下文锚点时的表示向量,同时为了得到一个总的、固定长度的上下文表示向量,使用读出机制来聚合上下文锚点的表示向量。公式如下:
Z
=
G
N
N
(
X
,
A
)
,
Z
c
o
n
t
e
x
t
=
G
N
N
c
o
n
t
e
x
t
(
X
,
A
)
Z=GNN(X, A), Z_{context}=GNN_{context}(X, A)
Z=GNN(X,A),Zcontext=GNNcontext(X,A)
c
i
=
R
(
{
Z
c
o
n
t
e
x
t
[
j
]
,
∀
v
j
是
v
i
的
上
下
文
锚
点
}
)
c_i=R(\{Z_{context}[j], \forall v_j是v_i的上下文锚点\})
ci=R({Zcontext[j],∀vj是vi的上下文锚点})
L
o
s
s
v
i
=
log
(
1
−
σ
(
z
i
T
c
i
)
)
+
log
(
σ
(
z
i
T
c
j
∣
j
≠
i
)
)
Loss_{v_i}=\log{(1-\sigma(z_i^Tc_i))}+\log{(\sigma(z_i^Tc_{j|j\ne i}))}
Lossvi=log(1−σ(ziTci))+log(σ(ziTcj∣j=i))
其中一共用到2个GNN。一个用来在
K
K
K阶子图上提取其特征向量
Z
Z
Z,另一个提取每个节点作为上下文锚点时的表示向量
Z
c
o
n
t
e
x
t
Z_{context}
Zcontext,使用读出机制来聚合上下文锚点的表示向量
c
i
c_i
ci。
(3)全图作为上下文
Deep Graph Infomax(DGI)的方法对图数据进行无监督表示学习,该方法实现了一种节点与全图之间的对比损失的学习机制。做法如下:
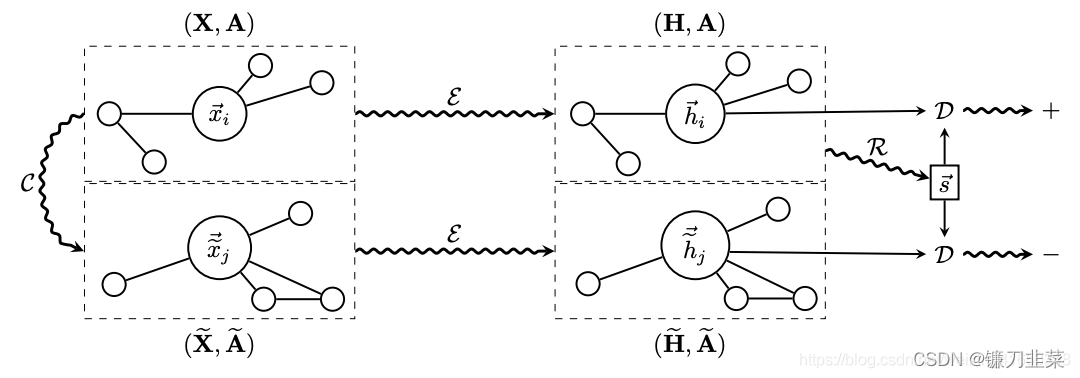
相关公式如下:
Z
=
G
N
N
(
X
,
A
)
,
Z
‾
=
G
N
N
(
X
c
u
r
r
u
p
t
,
A
c
u
r
r
u
p
t
)
Z=GNN(X, A), \overline{Z}=GNN(X_{currupt}, A_{currupt})
Z=GNN(X,A),Z=GNN(Xcurrupt,Acurrupt)
s
=
R
e
a
d
o
u
t
(
{
z
i
,
∀
v
i
∈
V
}
)
s=Readout(\{z_i, \forall v_i\in V\})
s=Readout({zi,∀vi∈V})
L
o
s
s
v
i
=
log
(
1
−
D
(
z
i
,
s
)
)
+
log
(
D
(
z
‾
i
,
s
)
)
Loss_{v_i}=\log{(1-D(z_i,s))}+\log{(D(\overline{z}_i,s))}
Lossvi=log(1−D(zi,s))+log(D(zi,s))
其中
(
A
c
u
r
r
u
p
t
,
X
c
u
r
r
u
p
t
)
(A_{currupt},X_{currupt})
(Acurrupt,Xcurrupt)为加噪声构造的负采样样本。将正负样本送入同一个GNN中进行学习。使用读出机制得到全图的向量表示
s
s
s。
首先,为了得到负采样样本,需要对图数据进行相关扰动,得到 ( A c u r r u p t , X c u r r u p t ) (A_{currupt},X_{currupt}) (Acurrupt,Xcurrupt)。然后将着两组图数据送到同一个GNN模型中进行学习。为了得到图的全局表示,使用读出机制对局部节点的信息进行整合。在最后的损失函数中,固定全图,对节点进行负采样的对比学习。
从互信息的角度看,通过一个统一的全局表示最大化全图与节点之间的互信息,可以在所有节点的表示之间建立一层更直接的联系。
同时在全图层面的无监督学习上,上述损失函数的负样本刚好相反,需要抽取其他图的表示 s ‾ \overline{s} s来代替,即 L o s s s = E v i ∈ G s log ( 1 − D ( z i , s ) ) + E v i ∈ G s log ( D ( z i , s ‾ ) ) Loss_{s}=E_{v_i\in G_s}\log{(1-D(z_i, s))}+E_{v_i\in G_s}\log{(D(z_i,\overline{s}))} Losss=Evi∈Gslog(1−D(zi,s))+Evi∈Gslog(D(zi,s)),此时,由于是全图层面的任务,希望通过上式让全图与其所有局部节点之间实现互信息最大化,即获得全图最有效、最具代表性的特征。
参考资料
[1] 《深入浅出图神经网络:GNN原理解析》
[2] GNN的理论与发展梳理(总结版)
[3] DeepWalk: Online Learning of Social Representations
[4] VGAE(Variational graph auto-encoders)论文详解
[5] 带你读论文 | 图神经网络预训练新思路
[6] Pre-training Graph Neural Networks
[7] DEEP GRAPH INFOMAX 阅读笔记


















 4700
4700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











