






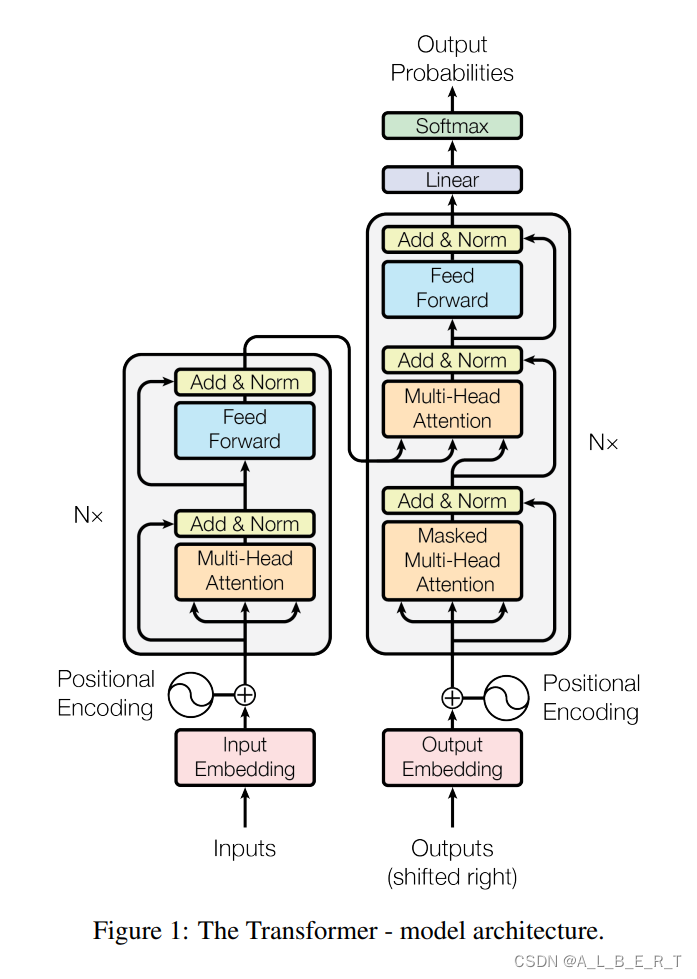
transformer结构
首先大家需要了解一些transformer的基本知识,比如什么是自注意力,什么是seq2seq,什么是位置编码等等。
原文
看我掏出经典大图
数据集介绍
该数据集被描述为 “由 NTT 创建的最大的公开可用英日并行语料库”。它主要是通过抓取网络并自动对齐平行句子而创建的。

数据集下载链接
导入库函数
导入必要的库:
- math:提供数学运算函数。
- torchtext:用于文本处理和自然语言处理任务。
- torch 及相关子模块:用于构建和训练深度学习模型。
- pandas:用于数据处理和分析。
- numpy:用于数值计算。
- pickle:用于对象序列化。
- tqdm:用于显示进度条。
- sentencepiece:用于子词分割。
设置随机种子和设备:
- torch.manual_seed(0):设置随机种子以保证结果的可重复性。
- device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’):设置计算设备为GPU(如果可用),否则使用CPU。
import math
import torchtext
import torch
import torch.nn as nn
from torch import Tensor
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
from collections import Counter
from torchtext.vocab import Vocab
from torch.nn import TransformerEncoder, TransformerDecoder, TransformerEncoderLayer, TransformerDecoderLayer
import io
import time
import pandas as pd
import numpy as np
import pickle
import tqdm
import sentencepiece as spm
torch.manual_seed(0)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# print(torch.cuda.get_device_name(0)) ## 如果你有GPU,请在你自己的电脑上尝试运行这一套代码
数据预处理
# 读取数据
df = pd.read_csv('./zh-ja.bicleaner05.txt', sep='\t', engine='python', header=None)
# 将第三列和第四列转换为列表
trainen = df[2].values.tolist()#[:10000]
trainja = df[3].values.tolist()#[:10000]
# 输出第500个元素
print(trainen[500])
print(trainja[500])
读取数据
使用pandas读取带有制表符分隔的文件zh-ja.bicleaner05.txt。
处理数据
将文件的第三列和第四列分别转换为trainen和trainja列表。
- 打印第500个元素:
输出trainen和trainja列表中的第500个元素。
trainen和trainja列表中的第500个元素的输出:
Chinese HS Code Harmonized Code System < HS编码 2905 无环醇及其卤化、磺化、硝化或亚硝化衍生物 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ...
Japanese HS Code Harmonized Code System < HSコード 2905 非環式アルコール並びにそのハロゲン化誘導体、スルホン化誘導体、ニトロ化誘導体及びニトロソ化誘導体 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ...
数据集txt文件前10条内容:
www.maximintegrated.com 0.825 为了在3.4V电压下保持35%的PAE,还需要高达530mA的PA集电极电流: 28dBm RF功率: 102.8 mW = 631mW 所需PA功率(VCC x ICC): 631mW/(PAE/100) = 1803mW 3.4V VCC时所需PA ICC : ICC = 1803mW/3.4V = 530mA 要保证3.4V VCC和530mA ICC, DC-DC转换器要求输入和输出电压之间有一定的裕量,如果转换器内部的p沟道MOSFET (P-FET)的导通电阻为0.4Ω,电感电阻为0.1Ω元件串联后将产生:(0.4Ω+0.1Ω) x530mA = 265mV的压差,当电池电压降至3.665V以下时,DC-DC转换器将无法支持3.4V的输出。 3.4Vで35%のPAEを維持するには、530mAという大きなPA-コレクタ電流も必要となります: 28dBmのRF電力:102.8mW = 631mW 必要なPAの電力(VCC × ICC):631mW/(PAE/100) = 1803mW 3.4VのVCCで必要なPAのICC:ICC = 1803mW/3.4V = 530mA 3.4VのVCCと530mAのICCに対応するためには、PA電力用のDC-DCコンバータに、一定量の入力-出力ヘッドルームが必要となります。たとえば、コンバータの内部PチャネルMOSFET (P-FET)のオン抵抗が0.4Ωで、インダクタの抵抗が0.1Ωの場合、これら2個の直列部品の両端における電圧降下は(0.4Ω + 0.1Ω) × 530mA = 265mVになります。
www.hscode.org 0.823 Chinese HS Code Harmonized Code System < HS编码 9001 : 光导纤维及光导纤维束;光缆,但品目8544的货品除外;偏振材料制的片及板;未装配的各种材料制透镜(包括隐 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ... Japanese HS Code Harmonized Code System < HSコード 9001 光ファイバー、光ファイバーケーブル、偏光材料製のシート及び板並びにレンズ HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ...900110 光ファイバー(束にしたものを含む。
hikersbay.com 0.823 圣胡安 设施: 餐厅, 客房服务, 24小时前台, 报纸, 露台, 禁烟客房, 无障碍设施, 家庭间, 上网服务, 电梯, 保险箱, 旅游咨询台, 传真/复印, 行李寄存, 无线网络, 免费无线网络连接, 酒店各处禁烟, 空调, 吸烟区, 阳光露台, 礼宾服务, 自动售货机(饮品), 海滨, 每日清洁服务, WiFi(覆盖酒店各处), 无障碍通道, 坐便器 - 带扶手, 坐便器较高, 盥洗盆较低, 简短描述Sandy Beach Hotel酒店位于圣胡安(San Juan)孔达杜(Condado)的海滩上,提供免费WiFi、带有线频道的电视以及提供多语种服务的24小时前台。 サンフアン 施設・設備: レストラン, ルームサービス, 24時間対応フロント, 新聞, テラス, 禁煙ルーム, バリアフリー, ファミリールーム, インターネット, エレベーター, セーフティボックス, ツアーデスク, FAX / コピー, 荷物預かり, Wi-Fi, 無料Wi-Fi, 全館禁煙, エアコン, 喫煙コーナー, サンテラス, コンシェルジュサービス, 自販機(ドリンク類), ビーチフロント, 客室清掃サービス(毎日), Wi-Fi(館内全域), 車いす対応, 手すり付きトイレ, 座面の高いトイレ, 低い洗面台, 短い説明Sandy Beach Hotelは、サンファンのオーシャンフロントのコンダード地区に位置しています。無料Wi-Fi回線、ケーブルテレビ付きの客室、24時間多言語で対応可能なフロントを提供しています。
hikersbay.com 0.823 圣胡安 设施: 会议/宴会设施, 酒吧, 24小时前台, 花园, 露台, 禁烟客房, 家庭间, 新娘套房, 上网服务, 礼品店, 传真/复印, 行李寄存, 商店(酒店内部), 无线网络, 室外游泳池, 免费无线网络连接, 酒店各处禁烟, 空调, 阳光露台, 室外游泳池(全年开放), 内部小超市, 每日清洁服务, 简短描述The Gallery Inn酒店距离圣胡安国家历史遗址(San Juan National Historic Site)不到1英里(1.6公里),提供装饰独特的客房。 サンフアン 施設・設備: 会議 / 宴会設備, バー, 24時間対応フロント, 庭, テラス, 禁煙ルーム, ファミリールーム, ブライダルスイート, インターネット, ギフトショップ, FAX / コピー, 荷物預かり, ショップ(敷地内), Wi-Fi, 屋外プール, 無料Wi-Fi, 全館禁煙, エアコン, サンテラス, 屋外プール(通年), ミニマーケット(施設内), 客室清掃サービス(毎日), 短い説明The Gallery Innはサンフアン国定史跡から約1.6kmに位置し、ユニークな内装の客室、Wi-Fi、屋外スイミングプールを提供しています。
www.hscode.org 0.822 Chinese HS Code Harmonized Code System < HS编码 8536 : 电路的开关、保护或连接用的电气装置(例如,开关、继电器、熔断器、电涌抑制器、插头、插座、灯座、接线盒 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ... Japanese HS Code Harmonized Code System < HSコード 8536 電気回路の開閉用、保護用又は接続用の機器(例えば、スイッチ、継電器、ヒューズ、サージ抑制器、プラグ、ソケット、ランプホルダー及び接 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ...
www.hscode.org 0.822 Chinese HS Code Harmonized Code System < HS编码 8515 : 电气(包括电热气体)、激光、其他光、光子束、超声波、电子束、磁脉冲或等离子弧焊接机器及装置,不论是否 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ... Japanese HS Code Harmonized Code System < HSコード 8515 はんだ付け用、ろう付け用又は溶接用の機器(電気式(電気加熱ガス式を含む。)、レーザーその他の光子ビーム式、超音波式、電子ビーム式、 HS Code List (Harmonized System Code) for US, UK, EU, China, India, France, Japan, Russia, Germany, Korea, Canada ...
hikersbay.com 0.822 美国 设施: 停车场, 24小时前台, 健身中心, 报纸, 露台, 禁烟客房, 干洗, 无障碍设施, 免费停车, 上网服务, 电梯, 快速办理入住/退房手续, 保险箱, 暖气, 传真/复印, 行李寄存, 无线网络, 免费无线网络连接, 酒店各处禁烟, 空调, 阳光露台, 自动售货机(饮品), 自动售货机(零食), 每日清洁服务, 内部停车场, 私人停车场, WiFi(覆盖酒店各处), 停车库, 无障碍停车场, 简短描述Gateway Hotel Santa Monica酒店距离海滩2英里(3.2公里),提供24小时健身房。每间客房均提供免费WiFi,客人可以使用酒店的免费地下停车场。 アメリカ合衆国 施設・設備: 駐車場, 24時間対応フロント, フィットネスセンター, 新聞, テラス, 禁煙ルーム, ドライクリーニング, バリアフリー, 無料駐車場, インターネット, エレベーター, エクスプレス・チェックイン / チェックアウト, セーフティボックス, 暖房, FAX / コピー, 荷物預かり, Wi-Fi, 無料Wi-Fi, 全館禁煙, エアコン, サンテラス, 自販機(ドリンク類), 自販機(スナック類), 客室清掃サービス(毎日), 敷地内駐車場, 専用駐車場, Wi-Fi(館内全域), 立体駐車場, 障害者用駐車場, 短い説明Gateway Hotel Santa Monicaはビーチから3.2kmの場所に位置し、24時間利用可能なジム、無料Wi-Fi付きのお部屋、無料の地下駐車場を提供しています。
hikersbay.com 0.822 巴黎 设施: 停车场, 酒吧, 24小时前台, 报纸, 禁烟客房, 机场班车, 洗衣, 在客房内享用早餐, 上网服务, 电梯, 保险箱, 旅游咨询台, 暖气, 传真/复印, 无线网络, 免费无线网络连接, 酒店各处禁烟, 空调, 礼宾服务, 机场班车(额外收费), 每日清洁服务, WiFi(覆盖酒店各处), 简短描述Le Notre Dame Saint Michel酒店位于巴黎中心的塞纳河(Seine)畔,是一间迷人的精品酒店,可观赏巴黎圣母院(Notre-Dame Cathedral)和河流美景。 パリ 施設・設備: 駐車場, バー, 24時間対応フロント, 新聞, 禁煙ルーム, 空港シャトル, ランドリー, 朝食ルームサービス, インターネット, エレベーター, セーフティボックス, ツアーデスク, 暖房, FAX / コピー, Wi-Fi, 無料Wi-Fi, 全館禁煙, エアコン, コンシェルジュサービス, 空港シャトル(有料), 客室清掃サービス(毎日), Wi-Fi(館内全域), 短い説明Le Notre Dame Saint Michelはパリ中心部のセーヌ河岸にある魅力的なブティックホテルです。
www.maximintegrated.com 0.821 MAX66040 ISO/IEC 14443 B型安全存储器 - Maxim 美信 说明 创建原理图或仿真器件,请使用EE-Sim®: MAX66040在单芯片内集成了具有安全散列算法(SHA-1)质询和响应认证(ISO/IEC 10118-3 SHA-1)的1024位用户EEPROM、64位唯一识别码(UID)、64位密钥和13.56MHz RF接口(ISO/IEC 14443 B型,2-4部分)。 MAX66040 ISO/IEC 14443タイプB準拠セキュアメモリ - マキシム 説明 EE-Sim®を使って設計とシミュレーションを行う: MAX66040は、1024ビットのユーザーEEPROMと、セキュアハッシュアルゴリズム(SHA-1)チャレンジ&レスポンス認証(ISO/IEC 10118-3 SHA-1)、64ビットの固有ID (UID)、1つの64ビットのシークレット、および13.56MHz RFインタフェース(ISO/IEC 14443タイプB、パート2~4)をシングルチップに組み合わせています。
www.maximintegrated.com 0.821 MAX3991: 采用MAX3991实现10Gbps光接收器信号丢失精确探测 - Maxim 美信 关键词: MAX3991, LOS探测器, 10Gbps接收器, BER, 误码率, LOS滞回, 信号丢失检测, 系统数字诊断, XFP光模块, 时钟和数据恢复, CDR, 输出信号幅度, TIA, OMA, 光调制幅度 関連製品 MAX3991:MAX3991を使用した10Gbps光レシーバでの正確なロスオブシグナル(LOS)検出 - マキシム キーワード: MAX3991, LOS検出器, 10Gbpsレシーバ, 10Gbit/sレシーバ, BER, ビットエラー率, LOSヒステリシス, ロスオブシグナルモニタ, システムディジタル診断, システムデジタル診断, XFP光モジュール, クロックおよびデータリカバリ, CDR, 出力信号振幅, TIA, OMA, 光変調振幅 関連製品
分词
- 导入SentencePiece库
已引入SentencePiece库,用于加载分词模型并执行分词操作。
- 加载分词模型:
# 加载英语分词模型
en_tokenizer = spm.SentencePieceProcessor(model_file='spm.en.nopretok.model')
# 加载日语分词模型
ja_tokenizer = spm.SentencePieceProcessor(model_file='spm.ja.nopretok.model')
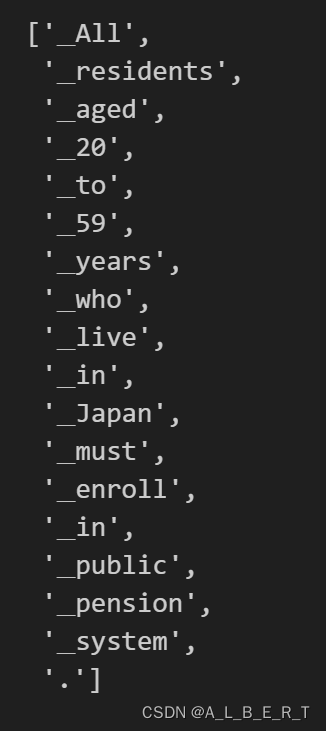
- 对句子进行分词
# 对英语句子进行分词
en_tokens = en_tokenizer.encode("All residents aged 20 to 59 years who live in Japan must enroll in public pension system.", out_type=str)
# 对日语句子进行分词
ja_tokens = ja_tokenizer.encode("年金 日本に住んでいる20歳~60歳の全ての人は、公的年金制度に加入しなければなりません。", out_type=str)
# 输出分词结果
print("English Tokens:", en_tokens)
print("Japanese Tokens:", ja_tokens)
- 输出分词结果

构建torchtext词汇表
以下代码对英语和日语的训练数据进行分词、词汇表构建以及将句子转换为词汇索引张量。
函数 build_vocab
def build_vocab(sentences, tokenizer):
counter = Counter() # 创建一个计数器对象
for sentence in sentences:
# 使用分词器对句子进行分词,并更新计数器
counter.update(tokenizer.encode(sentence, out_type=str))
# 创建词汇表对象,包含特定的特殊标记
return Vocab(counter, specials=[‘’, ‘’, ‘’, ‘’])
-
功能:
该函数用于构建词汇表(vocabulary)。词汇表是将文本中的词汇映射到索引的工具。 -
步骤:
- 创建一个计数器对象 counter。
- 对每个句子进行分词,并更新计数器,记录每个词出现的频率。
- 创建一个 Vocab 对象,它是 torchtext.vocab 模块中的一个类,用于存储词汇表,并包含一些特殊标记,如 (未知词)、(填充)、(句子开始)和 (句子结束)。
-
结果:
- 返回一个包含所有单词及其索引的词汇表对象。
构建词汇表
# 使用训练集构建日语词汇表
ja_vocab = build_vocab(trainja, ja_tokenizer)
# 使用训练集构建英语词汇表
en_vocab = build_vocab(trainen, en_tokenizer)
-
功能:
分别使用训练集中的日语和英语句子构建对应的词汇表。 -
步骤:
- 调用 build_vocab 函数,传入日语句子和日语分词器,得到日语词汇表 ja_vocab。
- 调用 build_vocab 函数,传入英语句子和英语分词器,得到英语词汇表 en_vocab。
函数 data_process
def data_process(ja, en):
data = [] # 初始化存储处理后数据的列表
for (raw_ja, raw_en) in zip(ja, en):
# 将日语句子转换为词汇索引张量
ja_tensor_ = torch.tensor([ja_vocab[token] for token in ja_tokenizer.encode(raw_ja.rstrip("\n"), out_type=str)],
dtype=torch.long)
# 将英语句子转换为词汇索引张量
en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer.encode(raw_en.rstrip("\n"), out_type=str)],
dtype=torch.long)
# 将处理后的张量添加到数据列表中
data.append((ja_tensor_, en_tensor_))
return data
-
功能:
将原始日语和英语句子处理成词汇索引张量,并将这些张量配对存储在列表中。 -
步骤:
- 初始化一个空列表 data,用于存储处理后的数据。
- 遍历日语和英语句子的配对 (raw_ja, raw_en):
- 使用日语分词器对 raw_ja 进行分词,并将每个词转换为对应的词汇索引,生成张量 ja_tensor_。
- 使用英语分词器对 raw_en 进行分词,并将每个词转换为对应的词汇索引,生成张量 en_tensor_。
- 将 (ja_tensor_, en_tensor_) 这一对张量添加到 data 列表中。
- 返回处理后的数据列表 data。
处理训练数据
train_data = data_process(trainja, trainen)
- 功能:
使用 data_process 函数处理训练数据中的日语和英语句子,得到配对的词汇索引张量列表 train_data。 - 结果:
train_data 是一个列表,每个元素是一个元组 (ja_tensor_, en_tensor_),分别对应日语和英语句子的词汇索引张量。
数据加载器
设置批量大小和特殊标记的索引
BATCH_SIZE = 24
PAD_IDX = ja_vocab['<pad>']
BOS_IDX = ja_vocab['<bos>']
EOS_IDX = ja_vocab['<eos>']
-
功能:
- 定义批量大小 BATCH_SIZE 为 24。
- 获取特殊标记 、 和 在日语词汇表 ja_vocab 中的索引,分别存储在 PAD_IDX、BOS_IDX 和 EOS_IDX 中。
函数 generate_batch
def generate_batch(data_batch):
ja_batch, en_batch = [], []
for (ja_item, en_item) in data_batch:
# 在每个日语句子的开头和结尾添加<BOS>和<EOS>
ja_batch.append(torch.cat([torch.tensor([BOS_IDX]), ja_item, torch.tensor([EOS_IDX])], dim=0))
# 在每个英语句子的开头和结尾添加<BOS>和<EOS>
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
# 使用填充标记PAD_IDX对日语和英语批量数据进行填充
ja_batch = pad_sequence(ja_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
return ja_batch, en_batch
-
功能:
- 将输入数据批量中的每个句子转换为词汇索引张量,并在每个句子的开头和结尾添加特殊标记 和 。
- 使用填充标记 对批量数据进行填充,以使得批量中所有句子的长度相同。
-
步骤:
- 初始化空列表 ja_batch 和 en_batch,分别用于存储处理后的日语和英语句子张量。
- 遍历输入数据批量 data_batch 中的每个元组 (ja_item, en_item):
- 使用 torch.cat 将 标记、句子张量和 标记连接起来,形成完整的句子张量,并添加到对应的批量列表中。
- 使用 pad_sequence 函数对 ja_batch 和 en_batch 进行填充,使用 PAD_IDX 作为填充值,使得所有句子的长度相同。
- 返回填充后的日语和英语批量张量。
创建数据加载器
train_iter = DataLoader(train_data, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=generate_batch)
-
功能:
创建一个数据加载器 train_iter,用于迭代训练数据,并在每个批量中应用 generate_batch 函数生成批量数据。 -
参数:
- 使用 DataLoader 类创建数据加载器 train_iter。
- 设置 train_data 作为数据源。
- 设置批量大小 batch_size 为 BATCH_SIZE。
- 设置 shuffle=True,在每个epoch开始时打乱数据顺序。
- 设置 collate_fn=generate_batch,使用 generate_batch 函数生成批量数据。
seq2seq transformer
***以下内容基本与pytorch官方教程一致,只是变成了中日语翻译。
此部分总体代码:
from torch.nn import (TransformerEncoder, TransformerDecoder,
TransformerEncoderLayer, TransformerDecoderLayer)
class Seq2SeqTransformer(nn.Module):
def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward:int = 512, dropout:float = 0.1):
super(Seq2SeqTransformer, self).__init__()
# 定义编码器层
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
# 定义解码器层
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
# 定义生成器,将编码后的表示映射到目标词汇表大小的向量
self.generator = nn.Linear(emb_size, tgt_vocab_size)
# 定义源语言和目标语言的词嵌入层
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
# 定义位置编码层
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
tgt_mask: Tensor, src_padding_mask: Tensor,
tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
# 对源语言输入进行词嵌入和位置编码
src_emb = self.positional_encoding(self.src_tok_emb(src))
# 对目标语言输入进行词嵌入和位置编码
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
# 通过编码器处理源语言输入
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
# 通过解码器处理目标语言输入和编码器的输出
outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
tgt_padding_mask, memory_key_padding_mask)
# 将解码器的输出通过生成器映射到目标词汇表大小
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
# 对源语言输入进行词嵌入和位置编码,然后通过编码器
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
# 对目标语言输入进行词嵌入和位置编码,然后通过解码器
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)
import math
import torch
import torch.nn as nn
from torch import Tensor
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
# 计算位置编码的分母部分
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
# 生成位置索引
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
# 初始化位置编码矩阵
pos_embedding = torch.zeros((maxlen, emb_size))
# 计算位置编码的正弦部分
pos_embedding[:, 0::2] = torch.sin(pos * den)
# 计算位置编码的余弦部分
pos_embedding[:, 1::2] = torch.cos(pos * den)
# 为位置编码矩阵增加一个维度
pos_embedding = pos_embedding.unsqueeze(-2)
# 定义dropout层
self.dropout = nn.Dropout(dropout)
# 将位置编码矩阵注册为buffer,模型保存时不会保存这个tensor的参数
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
# 将位置编码添加到token嵌入,并应用dropout
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
# 定义词嵌入层
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
# 将tokens转换为长整型并进行词嵌入,同时乘以嵌入尺寸的平方根进行缩放
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
def generate_square_subsequent_mask(sz):
# 创建一个上三角矩阵,并将其转置,以生成下三角掩码
mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)
# 将掩码中的0元素填充为负无穷,1元素填充为0.0
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
# 生成目标序列的掩码
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
# 生成源序列的掩码,全为0,因为源序列不需要掩码
src_mask = torch.zeros((src_seq_len, src_seq_len), device=device).type(torch.bool)
# 生成源序列和目标序列的填充掩码
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
# 定义一些超参数
SRC_VOCAB_SIZE = len(ja_vocab) # 源语言词汇表大小
TGT_VOCAB_SIZE = len(en_vocab) # 目标语言词汇表大小
EMB_SIZE = 512 # 词嵌入维度
NHEAD = 8 # 多头注意力机制中的头数
FFN_HID_DIM = 512 # 前馈神经网络的隐藏层维度
BATCH_SIZE = 16 # 批量大小
NUM_ENCODER_LAYERS = 3 # 编码器层数
NUM_DECODER_LAYERS = 3 # 解码器层数
NUM_EPOCHS = 16 # 训练的轮数
# 初始化Seq2SeqTransformer模型
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
# 对模型参数进行Xavier均匀初始化
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
# 将模型转移到指定设备(例如GPU)
transformer = transformer.to(device)
# 定义损失函数,忽略填充标记的索引
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
# 定义优化器,使用Adam优化器
optimizer = torch.optim.Adam(
transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9
)
# 定义训练一个epoch的函数
def train_epoch(model, train_iter, optimizer):
model.train() # 设置模型为训练模式
losses = 0 # 初始化损失
for idx, (src, tgt) in enumerate(train_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :] # 目标输入为目标序列去掉最后一个时间步
# 创建源和目标的掩码
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
# 模型前向传播
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
optimizer.zero_grad() # 清空梯度
tgt_out = tgt[1:, :] # 目标输出为目标序列去掉第一个时间步
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1)) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
losses += loss.item() # 累计损失
return losses / len(train_iter) # 返回平均损失
# 定义评估函数
def evaluate(model, val_iter):
model.eval() # 设置模型为评估模式
losses = 0 # 初始化损失
for idx, (src, tgt) in enumerate(val_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :] # 目标输入为目标序列去掉最后一个时间步
# 创建源和目标的掩码
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
# 模型前向传播
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :] # 目标输出为目标序列去掉第一个时间步
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1)) # 计算损失
losses += loss.item() # 累计损失
return losses / len(val_iter) # 返回平均损失
以下为分点解释:
Seq2SeqTransformer类
class Seq2SeqTransformer(nn.Module):
def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward: int = 512, dropout: float = 0.1):
super(Seq2SeqTransformer, self).__init__()
# 定义编码器层
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
# 定义解码器层
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
# 定义生成器,将编码后的表示映射到目标词汇表大小的向量
self.generator = nn.Linear(emb_size, tgt_vocab_size)
# 定义源语言和目标语言的词嵌入层
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
# 定义位置编码层
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
-
功能:
- 初始化一个Seq2Seq Transformer模型。
- 主要包括编码器、解码器、生成器、词嵌入层和位置编码层。
-
参数:
- num_encoder_layers: 编码器层的数量。
- num_decoder_layers: 解码器层的数量。
- emb_size: 词嵌入的维度。
- src_vocab_size: 源语言词汇表的大小。
- tgt_vocab_size: 目标语言词汇表的大小。
- dim_feedforward: 前馈神经网络的维度。
- dropout: dropout的比率。
类的forward 方法
def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
tgt_mask: Tensor, src_padding_mask: Tensor,
tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
# 对源语言输入进行词嵌入和位置编码
src_emb = self.positional_encoding(self.src_tok_emb(src))
# 对目标语言输入进行词嵌入和位置编码
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
# 通过编码器处理源语言输入
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
# 通过解码器处理目标语言输入和编码器的输出
outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
tgt_padding_mask, memory_key_padding_mask)
# 将解码器的输出通过生成器映射到目标词汇表大小
return self.generator(outs)
-
功能:
- 完成源语言到目标语言的整个翻译过程。
-
步骤:
- 对源语言输入进行词嵌入和位置编码。
- 对目标语言输入进行词嵌入和位置编码。
- 使用编码器处理源语言输入,得到编码器输出 memory。
- 使用解码器处理目标语言输入和编码器的输出 memory,得到解码器输出 outs。
- 将解码器的输出通过生成器映射到目标词汇表大小。
encode 方法
def encode(self, src: Tensor, src_mask: Tensor):
# 对源语言输入进行词嵌入和位置编码,然后通过编码器
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
-
功能:
对源语言句子进行编码。 -
步骤:
- 对源语言输入进行词嵌入和位置编码。
- 使用编码器处理源语言输入,返回编码器的输出。
decode 方法
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
# 对目标语言输入进行词嵌入和位置编码,然后通过解码器
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)
-
功能:
对目标语言句子进行解码。 -
步骤:
- 对目标语言输入进行词嵌入和位置编码。
- 使用解码器处理目标语言输入和编码器的输出 memory,返回解码器的输出。
位置编码
简单来说位置编码使得模型能够识别序列中单词的位置,位置编码的方式也不止transformer论文里的一种,大家可以自行查询。
位置编码(Positional Encoding)是 Transformer 模型中用来引入序列顺序信息的一种方法。由于 Transformer 模型本质上是并行处理输入数据的,它没有内在的机制来捕捉输入序列的顺序信息,因此需要位置编码来补充这一点。
import math
import torch
import torch.nn as nn
from torch import Tensor
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
# 计算位置编码的分母部分
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
# 生成位置索引
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
# 初始化位置编码矩阵
pos_embedding = torch.zeros((maxlen, emb_size))
# 计算位置编码的正弦部分
pos_embedding[:, 0::2] = torch.sin(pos * den)
# 计算位置编码的余弦部分
pos_embedding[:, 1::2] = torch.cos(pos * den)
# 为位置编码矩阵增加一个维度
pos_embedding = pos_embedding.unsqueeze(-2)
# 定义dropout层
self.dropout = nn.Dropout(dropout)
# 将位置编码矩阵注册为buffer,模型保存时不会保存这个tensor的参数
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
# 将位置编码添加到token嵌入,并应用dropout
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])
-
功能:
计算并应用位置编码,使模型能够利用序列中单词的位置信息。 -
步骤:
- 计算位置编码的分母部分。
- 生成位置索引。
- 初始化位置编码矩阵。
- 计算位置编码的正弦和余弦部分,并填充到位置编码矩阵中。
- 将位置编码矩阵增加一个维度,并注册为 buffer,这样在模型保存时不会保存这个 tensor 的参数。
- 定义 dropout 层。
-
forward 方法:
在前向传播中,将位置编码添加到 token 嵌入,并应用 dropout。
词嵌入
在自然语言处理(NLP)任务中,我们首先需要将文本数据转换为模型可以理解的数值形式。为此,我们通常会构建一个词汇表,其中包含所有可能出现在文本中的单词或 token。每个单词或 token 都会被分配一个唯一的索引。词嵌入将 token 索引转换为高维向量表示,便于模型处理。
假设我们有一个词汇表大小为 10,000 的词汇表,每个单词要转换为一个 300 维的向量表示。嵌入层的参数可以表示为一个 10,000 x 300 的矩阵,其中每一行对应一个词汇表中的单词,每一行的 300 个值是该单词的嵌入向量。
"hello" -> 0 -> [0.25, -0.1, 0.4, ..., 0.05] # 300 维向量
"world" -> 1 -> [-0.3, 0.2, -0.5, ..., 0.1] # 300 维向量
当我们将 token 索引输入到嵌入层时,该索引会作为查找表的行索引,从矩阵中提取对应的嵌入向量。
这些高维向量表示具有以下几个优点:
-
捕捉语义信息:词嵌入向量能够捕捉单词之间的语义关系。例如,在一个良好的嵌入空间中,“king” 和 “queen” 的向量距离会比 “king” 和 “apple” 更接近。
-
便于模型处理:神经网络模型处理的是数值数据,因此需要将离散的 token 索引转换为连续的数值向量。高维向量表示提供了模型可以直接操作的数值输入。
-
通用性和可扩展性:嵌入向量可以被应用到各种 NLP 任务中,如文本分类、机器翻译、情感分析等。
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
# 定义词嵌入层
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
# 将tokens转换为长整型并进行词嵌入,同时乘以嵌入尺寸的平方根进行缩放
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
-
功能:
将输入的 token 索引转换为词嵌入向量。 -
步骤:
- 定义词嵌入层。
- 在前向传播中,将 tokens 转换为长整型并进行词嵌入,同时乘以嵌入尺寸的平方根进行缩放。
tokenizer&embedding
在自然语言处理(NLP)任务中,tokenizer 和 embedding 是两个不同但紧密相关的步骤,它们在将文本数据转换为模型可处理的数值表示的过程中扮演着重要角色。
Tokenizer(分词器)
-
功能:将文本数据拆分成更小的单元(tokens),通常是单词或子词。
将这些 tokens 映射到唯一的索引。 -
过程:
- 文本输入:例如 “Hello, world!”
- 分词:将句子拆分为 tokens,例如 [“Hello”, “,”, “world”, “!”]
- 索引映射:将每个 token 映射到一个唯一的索引,例如 {“Hello”: 0, “,”: 1, “world”: 2, “!”: 3}
# 示例代码
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Hello, world!"
tokens = tokenizer.tokenize(text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens:", tokens)
print("Indexed Tokens:", indexed_tokens)
Embedding(词嵌入)
-
功能:将 tokens 的索引转换为高维向量表示(通常是密集向量),这些向量捕捉了词汇的语义信息。
这种向量表示有助于模型理解和处理自然语言中的语义关系。 -
过程:
- 索引输入:例如 [0, 1, 2, 3]
- 词嵌入:将每个索引映射到一个高维向量
# 示例代码
import torch
import torch.nn as nn
# 假设词汇表大小为 10, 词嵌入维度为 5
vocab_size = 10
emb_size = 5
embedding = nn.Embedding(vocab_size, emb_size)
indexed_tokens = torch.tensor([0, 1, 2, 3])
embedded_tokens = embedding(indexed_tokens)
print("Embedded Tokens:", embedded_tokens)
Tokenizer 和 Embedding 的关系
-
顺序关系:分词(tokenization)是词嵌入(embedding)的前置步骤。文本首先需要通过分词器转换为 tokens,并进一步转换为索引,然后这些索引才能输入到嵌入层以获得高维向量表示。
-
数据转换:
- Tokenizer:将原始文本转换为 tokens 和索引。
- Embedding:将这些索引转换为稠密的向量表示。
-
作用对象:
- Tokenizer:作用于文本数据,将其转换为模型可理解的格式。
- Embedding:作用于索引数据,将其转换为便于模型处理的高维向量。
生成掩码
def generate_square_subsequent_mask(sz):
# 创建一个上三角矩阵,并将其转置,以生成下三角掩码
mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)
# 将掩码中的0元素填充为负无穷,1元素填充为0.0
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
- 功能:生成一个大小为 sz 的下三角掩码,用于掩盖未来的 tokens。在解码时,确保模型只能看到当前 token 及其之前的 tokens。
- 步骤:
- 创建一个上三角矩阵,并将其转置以生成下三角掩码。
- 将掩码中的 0 元素填充为负无穷,1 元素填充为 0.0。
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
# 生成目标序列的掩码
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
# 生成源序列的掩码,全为0,因为源序列不需要掩码
src_mask = torch.zeros((src_seq_len, src_seq_len), device=device).type(torch.bool)
# 生成源序列和目标序列的填充掩码
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
-
功能:
生成源序列和目标序列的掩码。 -
步骤:
- 获取源序列和目标序列的长度。
- 生成目标序列的下三角掩码。
- 为源序列生成全零的掩码,因为源序列不需要掩码。
- 生成源序列和目标序列的填充掩码,标记填充位置。
模型&超参数
# 定义一些超参数
SRC_VOCAB_SIZE = len(ja_vocab) # 源语言词汇表大小
TGT_VOCAB_SIZE = len(en_vocab) # 目标语言词汇表大小
EMB_SIZE = 512 # 词嵌入维度
NHEAD = 8 # 多头注意力机制中的头数
FFN_HID_DIM = 512 # 前馈神经网络的隐藏层维度
BATCH_SIZE = 16 # 批量大小
NUM_ENCODER_LAYERS = 3 # 编码器层数
NUM_DECODER_LAYERS = 3 # 解码器层数
NUM_EPOCHS = 16 # 训练的轮数
# 初始化Seq2SeqTransformer模型
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
# 对模型参数进行Xavier均匀初始化
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
# 将模型转移到指定设备(例如GPU)
transformer = transformer.to(device)
# 定义损失函数,忽略填充标记的索引
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
# 定义优化器,使用Adam优化器
optimizer = torch.optim.Adam(
transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9
)
- 功能:
- 定义模型超参数,初始化 Transformer 模型,并对模型参数进行 Xavier 均匀初始化。
- 定义损失函数和优化器。
训练函数
# 定义训练一个epoch的函数
def train_epoch(model, train_iter, optimizer):
model.train() # 设置模型为训练模式
losses = 0 # 初始化损失
for idx, (src, tgt) in enumerate(train_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :] # 目标输入为目标序列去掉最后一个时间步
# 创建源和目标的掩码
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
# 模型前向传播
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
optimizer.zero_grad() # 清空梯度
tgt_out = tgt[1:, :] # 目标输出为目标序列去掉第一个时间步
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1)) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
losses += loss.item() # 累计损失
return losses / len(train_iter) # 返回平均损失
- 设置模型为训练模式。
- 初始化损失。
- 遍历训练数据,获取源序列和目标序列,并将其转移到设备。
- 去掉目标序列的最后一个时间步,生成目标输入。
- 创建源和目标的掩码。
- 模型前向传播计算输出。
- 清空梯度,计算损失并进行反向传播。
- 更新模型参数。
- 累计损失并返回平均损失。
评估函数
# 定义评估函数
def evaluate(model, val_iter):
model.eval() # 设置模型为评估模式
losses = 0 # 初始化损失
for idx, (src, tgt) in enumerate(val_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :] # 目标输入为目标序列去掉最后一个时间步
# 创建源和目标的掩码
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
# 模型前向传播
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :] # 目标输出为目标序列去掉第一个时间步
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1)) # 计算损失
losses += loss.item() # 累计损失
return losses / len(val_iter) # 返回平均损失
- 设置模型为评估模式。
- 初始化损失。
- 遍历验证数据,获取源序列和目标序列,并将其转移到设备。
- 去掉目标序列的最后一个时间步,生成目标输入。
- 创建源和目标的掩码。
- 模型前向传播计算输出。
- 计算损失并累计。
- 返回平均损失。
训练
for epoch in tqdm.tqdm(range(1, NUM_EPOCHS+1)):
start_time = time.time()
train_loss = train_epoch(transformer, train_iter, optimizer)
end_time = time.time()
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "
f"Epoch time = {(end_time - start_time):.3f}s"))

翻译日文
贪婪解码
贪婪解码简单而言就是每一步都选择概率最大的单词输出,最后组成整个句子输出。具体可以参考这篇博客。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
# 将源序列和掩码转移到设备(如GPU)
src = src.to(device)
src_mask = src_mask.to(device)
# 编码源序列
memory = model.encode(src, src_mask)
# 初始化解码序列,开始符号作为第一个输入
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
for i in range(max_len-1):
memory = memory.to(device)
# 创建解码序列和编码序列之间的掩码
memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool)
# 创建目标序列的掩码
tgt_mask = (generate_square_subsequent_mask(ys.size(0))
.type(torch.bool)).to(device)
# 通过解码器生成输出
out = model.decode(ys, memory, tgt_mask)
out = out.transpose(0, 1)
# 通过生成器生成下一个单词的概率分布
prob = model.generator(out[:, -1])
# 选择概率最高的单词作为下一个单词
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.item()
# 将下一个单词添加到解码序列中
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
# 如果下一个单词是结束符号,则停止解码
if next_word == EOS_IDX:
break
return ys
- 将源序列和掩码转移到指定设备(如 GPU)。
- 对源序列进行编码,得到编码表示 memory。
- 初始化解码序列,以开始符号作为第一个输入。
- 逐步解码,直到达到最大长度或遇到结束符号:
- 创建解码序列和编码序列之间的掩码。
- 创建目标序列的掩码。
- 通过解码器生成输出,并通过生成器计算下一个单词的概率分布。
- 选择概率最高的单词作为下一个单词,并添加到解码序列中。
- 如果下一个单词是结束符号,则停止解码。
- 返回生成的解码序列。
翻译函数
translate 函数调用 greedy_decode 来翻译源语言句子,并将生成的目标序列转换为目标语言句子。
def translate(model, src, src_vocab, tgt_vocab, src_tokenizer):
model.eval() # 设置模型为评估模式
# 将源语言句子编码为词汇索引序列,并添加开始和结束符号
tokens = [BOS_IDX] + [src_vocab.stoi[tok] for tok in src_tokenizer.encode(src, out_type=str)] + [EOS_IDX]
num_tokens = len(tokens)
# 创建源序列张量和掩码
src = (torch.LongTensor(tokens).reshape(num_tokens, 1))
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
# 使用贪婪解码生成目标序列
tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
# 将目标序列的词汇索引转换为对应的单词,并去除开始和结束符号
return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")
- 将模型设置为评估模式。
- 将源语言句子编码为词汇索引序列,并添加开始和结束符号。
- 创建源序列张量和掩码。
- 使用贪婪解码生成目标序列。
- 将目标序列的词汇索引转换为对应的单词,并去除开始和结束符号。
- 返回翻译后的目标语言句子。
实例
因为使用的训练语料都与电气相关(可以参考本文数据加载阶段展示的部分语料),对于其他方面的日语翻译结果惨不忍睹,故只使用电气相关的中文句子通过百度翻译成日语,再用于测试本模型。
print(translate(transformer, "HSコード 8515 はんだ付け用、ろう付け用又は溶接用の機器(電気式(電気加熱ガス式を含む。)", ja_vocab, en_vocab, ja_tokenizer))
print(translate(transformer, "建築電気工学の配線システムは、主に380V / 220Vの定格です。", ja_vocab, en_vocab, ja_tokenizer))
print(translate(transformer, "主に電気駆動、電気暖房、電気照明などを指し、他の建築設備と一致します", ja_vocab, en_vocab, ja_tokenizer))
print(translate(transformer, "電気ヒーターとそのスイッチおよびソケット用の専用電源または変換電源 ...", ja_vocab, en_vocab, ja_tokenizer))

以下代码展示了训练语料库的部分内容:
trainen.pop(5)
trainja.pop(5)
输出:
'美国 设施: 停车场, 24小时前台, 健身中心, 报纸, 露台, 禁烟客房, 干洗, 无障碍设施, 免费停车, 上网服务, 电梯, 快速办理入住/退房手续, 保险箱, 暖气, 传真/复印, 行李寄存, 无线网络, 免费无线网络连接, 酒店各处禁烟, 空调, 阳光露台, 自动售货机(饮品), 自动售货机(零食), 每日清洁服务, 内部停车场, 私人停车场, WiFi(覆盖酒店各处), 停车库, 无障碍停车场, 简短描述Gateway Hotel Santa Monica酒店距离海滩2英里(3.2公里),提供24小时健身房。每间客房均提供免费WiFi,客人可以使用酒店的免费地下停车场。'
'アメリカ合衆国 施設・設備: 駐車場, 24時間対応フロント, フィットネスセンター, 新聞, テラス, 禁煙ルーム, ドライクリーニング, バリアフリー, 無料駐車場, インターネット, エレベーター, エクスプレス・チェックイン / チェックアウト, セーフティボックス, 暖房, FAX / コピー, 荷物預かり, Wi-Fi, 無料Wi-Fi, 全館禁煙, エアコン, サンテラス, 自販機(ドリンク類), 自販機(スナック類), 客室清掃サービス(毎日), 敷地内駐車場, 専用駐車場, Wi-Fi(館内全域), 立体駐車場, 障害者用駐車場, 短い説明Gateway Hotel Santa Monicaはビーチから3.2kmの場所に位置し、24時間利用可能なジム、無料Wi-Fi付きのお部屋、無料の地下駐車場を提供しています。'
保存词典和模型
保存词汇表
import pickle
# 打开一个文件,以二进制写模式存储英语词汇表
file = open('en_vocab.pkl', 'wb')
# 将英语词汇表对象写入文件
pickle.dump(en_vocab, file)
# 关闭文件
file.close()
# 打开另一个文件,以二进制写模式存储日语词汇表
file = open('ja_vocab.pkl', 'wb')
# 将日语词汇表对象写入文件
pickle.dump(ja_vocab, file)
# 关闭文件
file.close()
保存模型
方法一
保存模型用于推理。
# save model for inference
torch.save(transformer.state_dict(), 'inference_model')
加载方法:
# 创建模型实例
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS, EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, FFN_HID_DIM)
# 加载模型参数
transformer.load_state_dict(torch.load('inference_model'))
# 将模型设置为评估模式
transformer.eval()
方法二
保存模型用于推理和继续训练。
# save model + checkpoint to resume training later
torch.save({
'epoch': NUM_EPOCHS,
'model_state_dict': transformer.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': train_loss,
}, 'model_checkpoint.tar')
加载方法
# 创建模型实例和优化器
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS, EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, FFN_HID_DIM)
optimizer = torch.optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# 加载检查点
checkpoint = torch.load('model_checkpoint.tar')
transformer.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
train_loss = checkpoint['loss']
# 将模型设置为训练模式
transformer.train()
区别
-
保存内容:
- 推理模型:只保存模型的参数。
- 训练检查点:保存模型的参数、优化器的状态、当前的训练轮数 和训练损失等。
-
使用场景:
- 推理模型:适用于只需进行推理,不再继续训练的场景。
- 训练检查点:适用于需要中断并恢复训练的场景。
-
加载方法:
- 推理模型:只需加载模型的参数,并设置模型为评估模式。
- 训练检查点:需要加载模型的参数、优化器的状态,并恢复训练轮数和其他相关信息,设置模型为训练模式。
总结
本模型是一个序列到序列(Seq2Seq)的 Transformer 模型,设计用于翻译任务。它的主要目标是将源语言句子翻译成目标语言句子。Transformer 模型采用自注意力机制(self-attention)和并行处理,可以高效处理长距离依赖问题,并且在许多自然语言处理任务中表现出色。
Seq2Seq Transformer 模型通过编码器和解码器结构,结合自注意力机制,能够有效地进行序列到序列的翻译任务。通过位置编码和词嵌入,模型能够捕捉序列的顺序信息和语义关系。贪婪解码和翻译函数提供了从源语言到目标语言的翻译能力,适用于各种机器翻译任务。模型的保存与加载方法确保了模型可以在推理和继续训练中灵活使用。
***如果想提升翻译性能,可以参考此链接训练一个比调用的sentencepiece库更好的中文分词器。















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









