










题目:TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
作者:Yu Zhang, Ziyue Jiang, Ruiqi Li, Changhao Pan, Jinzheng He, Rongjie Huang, Chuxin Wang, Zhou Zhao
Demo:TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
1. 摘要
风格迁移和风格控制的零样本歌声合成(SVS)旨在根据音频和文本提示生成具有未见过的音色和风格(包括演唱方法、情感、节奏、技巧和发音)的高质量歌声。然而,歌唱风格的多面性对有效的建模、迁移和控制构成了重大挑战。此外,当前的歌声合成(SVS)模型往往无法为未见过的歌手生成富含风格细微差别的歌声。为应对这些挑战,我们引入了 TCSinger,这是首个用于跨语言语音和歌唱风格进行风格迁移以及多级风格控制的零样本歌声合成模型。具体而言,TCSinger 提出了三个主要模块:1)聚类风格编码器采用聚类向量量化模型,将风格信息稳定地压缩到一个紧凑的潜在空间;2)风格与时长语言模型(S&D - LM)同时预测风格信息和音素时长,这对两者都有益;3)风格自适应解码器使用一种新颖的梅尔 - 风格自适应归一化方法来生成具有更丰富细节的歌声。实验结果表明,在包括零样本风格迁移、多级风格控制、跨语言风格迁移以及语音到歌唱风格迁移等各种任务中,TCSinger 在合成质量、歌手相似度和风格可控性方面均优于所有基线模型。
2. 引言
歌声合成(SVS)旨在利用歌词和乐谱生成高质量的歌唱声音,这引起了工业界和学术界的广泛关注。传统歌声合成系统的流程包括一个声学模型,该模型将乐谱和歌词转换为梅尔频谱图(mel - spectrograms),随后利用声码器(vocoder)将其合成为目标歌声。
近年来,歌声合成技术取得了显著的进步。然而,对个性化和可控制的歌唱体验日益增长的需求给当前的歌声合成模型带来了挑战。与传统的歌声合成任务不同,具有风格迁移和风格控制的零样本歌声合成旨在根据音频和文本提示生成具有未见过的音色和风格的高质量歌声。这种方法可扩展到更个性化和可控制的应用中,例如娱乐短视频的配音或专业音乐创作。个人歌唱风格主要包括歌唱方法(如美声唱法)、情感(快乐和悲伤)、节奏(包括单个音符的风格处理及其之间的过渡)、技巧(如假声)和发音(如咬字)。尽管如此,传统的歌声合成方法缺乏有效对这些个人风格进行建模、迁移和控制的必要机制。对于未见过的歌手,它们的性能往往会下降,因为这些方法通常假定在训练阶段目标歌手是可识别的。
目前,具有风格迁移和风格控制的零样本歌声合成主要面临两大挑战:
-
歌唱风格的多面性对全面建模以及有效迁移和控制构成了重大挑战。先前的方法使用预训练模型来捕捉风格。StyleSinger 使用残差量化(RQ)模型来捕捉风格。然而,这些模型侧重于风格的有限方面,忽略了诸如歌唱方法等风格。此外,它们无法进行多级风格控制。
-
现有的歌声合成模型往往无法为未见过的歌手生成富含风格细微差别的歌声。VISinger 2 使用数字信号处理技术来提高合成质量。Diffsinger 采用扩散解码器来捕捉歌唱声音的复杂性。然而,这些方法没有将风格信息充分融入合成过程,导致在零样本任务中缺乏风格变化的结果。
为应对这些挑战,我们引入了 TCSinger,这是首个用于跨语言语音和歌唱风格进行风格迁移以及多级风格控制的零样本歌声合成模型。TCSinger 从音频和文本提示中迁移和控制风格(如歌唱方法、情感、节奏、技巧和发音)以合成高质量的歌声。为了对多种风格(如歌唱方法、情感、节奏、技巧和发音)进行建模,我们提出了聚类风格编码器,它使用聚类向量量化(CVQ)模型将风格信息压缩到一个紧凑的潜在空间,从而便于后续预测,并提高训练稳定性和重建质量。对于风格迁移和控制,我们引入了风格与时长语言模型(S&D - LM)。S&D - LM 包含一个多任务语言模块,该模块利用音频和文本提示同时预测风格信息和音素时长,从而对两者都进行增强。为了生成富含风格细微差别的歌声,我们引入了风格自适应解码器,它采用一种新颖的梅尔 - 风格自适应归一化方法,用解耦的风格信息细化梅尔频谱图。我们的实验结果表明,在包括零样本风格迁移、多级风格控制、跨语言风格迁移以及语音 - 歌唱(STS)风格迁移等各种任务中,TCSinger 在合成质量、歌手相似度和风格可控性等指标方面优于其他当前表现最佳的基线模型。
总体而言,我们的主要贡献可总结如下:
-
我们提出了 TCSinger,这是首个用于跨语言语音和歌唱风格进行风格迁移以及多级风格控制的零样本歌声合成模型。TCSinger 在个性化和可控制的歌声合成任务中表现出色。
-
我们引入了聚类风格编码器来提取风格,以及风格与时长语言模型(S&D - LM)来预测风格信息和音素时长,解决了风格建模、迁移和控制问题。
-
我们提出了风格自适应解码器,它使用一种新颖的梅尔 - 风格自适应归一化方法生成具有复杂细节的歌曲。
-
实验结果表明,在零样本风格迁移、多级风格控制、跨语言风格迁移以及语音 - 歌唱风格迁移等各种工作中,TCSinger 在合成质量、歌手相似度和风格可控性方面均优于基线模型。
3. 方法
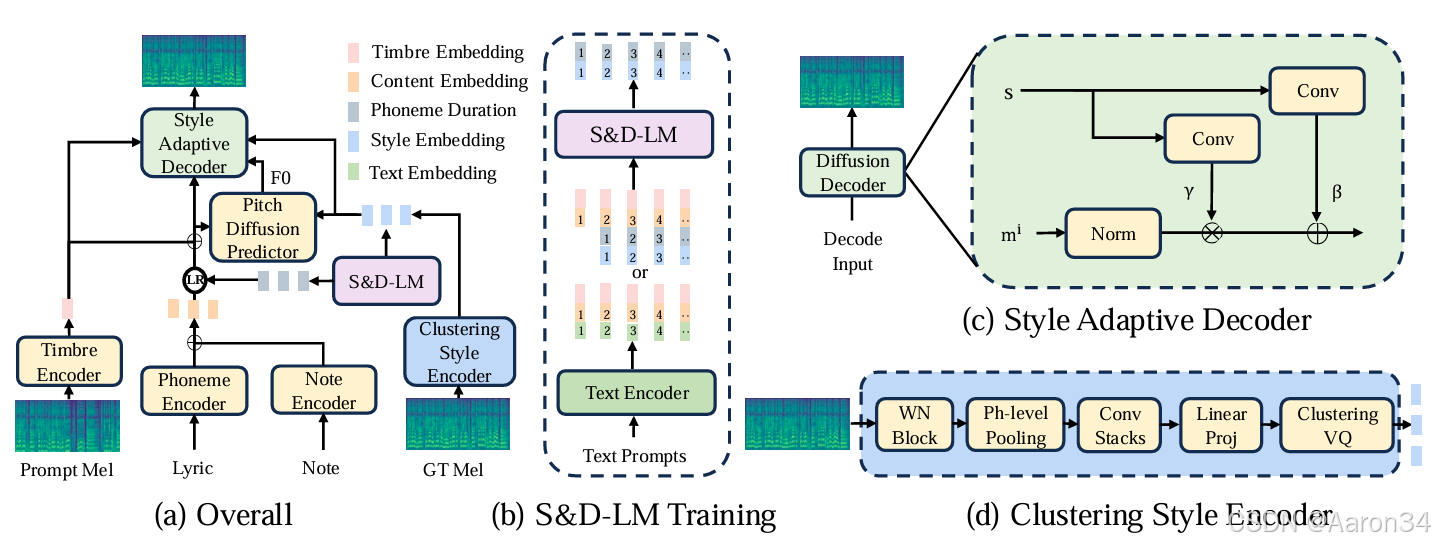
概述
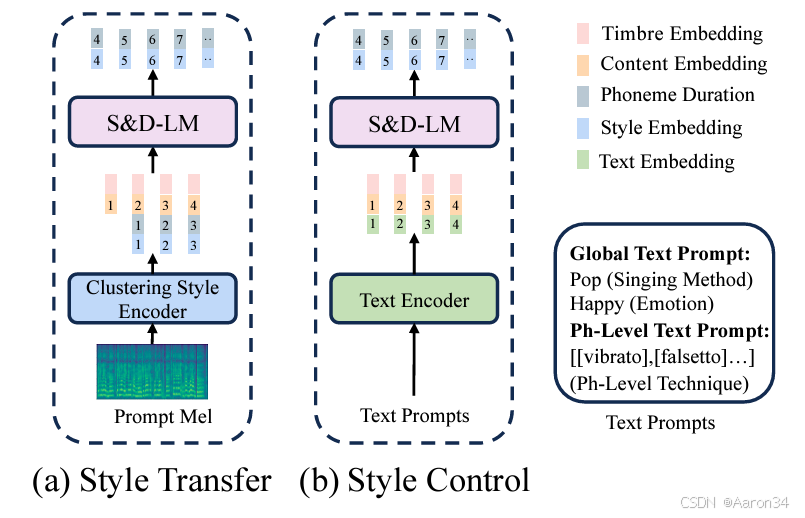
我们将歌声分解为内容、风格(包括演唱方法、情感、节奏、技巧和发音)和音色的单独表征。对于内容表征,歌词通过音素编码器进行编码,而音符编码器用于捕捉音符。对于风格表征,我们在聚类风格编码器中使用聚类向量量化(CVQ),将风格信息稳定地压缩到一个紧凑的潜在空间,从而便于后续预测。对于音色表征,我们将从同一位歌手的不同音频中采样得到的提示梅尔频谱图输入到音色编码器中,以获得一维音色向量,从而将音色与其他信息分离。然后,我们利用风格与时长语言模型(S&D - LM)来预测风格信息和音素时长。由于歌声的风格和时长密切相关,一个复合模块对两者都有益。此外,S&D - LM 通过音频和文本提示实现风格迁移和风格控制。接下来,我们使用音高扩散预测器进行基频(F0)预测,并使用风格自适应解码器来生成目标梅尔频谱图。风格自适应解码器使用一种新颖的梅尔 - 风格自适应归一化方法生成具有复杂细节的歌声。在训练期间,我们在第一阶段训练聚类风格编码器以进行重建,并在第二阶段训练 S&D - LM 以进行风格预测。在推理期间,我们可以向 S&D - LM 输入音频提示或文本提示以进行风格迁移或控制。
聚类风格编码器(Clustering Style Encoder)
为了从梅尔频谱图全面地捕捉风格(如演唱方法、情感、节奏、技巧和发音),我们引入了聚类风格编码器。 输入的梅尔频谱图首先通过WaveNet模块进行细化,然后基于音素边界的池化层将其压缩为音素级别的隐藏状态。随后,卷积栈捕捉音素级别的相关性。接下来,我们使用线性投影将输出映射到低维潜在变量空间以进行码本索引查找,这可以显著提高码本的使用率。然后,CVQ层利用这些输入x生成音素级别的风格表征,建立一个信息瓶颈,从而有效地去除非风格信息。通过线性投影的降维和CVQ的瓶颈作用,我们实现了风格与音色和内容信息的解耦。与传统的VQ相比,CVQ在训练期间采用动态初始化策略,确保较少使用或未使用的码向量比频繁使用的码向量有更多的修改,从而解决了码本崩溃问题。为了增强训练稳定性并提高重建质量,我们对编码后的潜在变量以及码本中的所有潜在变量应用L2归一化。值得注意的是,我们是首个在歌唱领域使用CVQ的,确保了稳定且高质量的风格信息提取。我们在训练期间输入真实值(GT)音频以学习多样的风格,并在推理期间输入提示音频以进行风格迁移。
风格自适应解码器(Style Adaptive Decoder)
歌声的动态特性对传统的梅尔解码器构成了重大挑战,传统的梅尔解码器往往无法有效地捕捉梅尔频谱图的复杂性。此外,使用向量量化(VQ)来提取风格信息本身是有损失的,并且密切相关的风格很容易被编码成相同的码本索引。因此,如果我们在这里使用传统的梅尔解码器,我们合成的歌声可能会变得生硬且缺乏风格变化。
为了应对这些挑战,我们引入了风格自适应解码器,它采用了一种新颖的梅尔 - 风格自适应归一化方法。虽然自适应实例归一化方法已在图像任务中广泛使用,但我们的工作首次使用解耦的风格信息来细化整个梅尔频谱图。我们的方法可以将风格变化融入梅尔频谱图中,从而生成更自然、更多样的音频结果,即使在解码器输入中对密切相关的风格使用相同的风格量化时也是如此。
我们的风格自适应解码器基于一个 8 步的基于扩散的解码器。我们利用快速傅里叶变换(FFT)作为去噪器,并通过多层我们的梅尔 - 风格自适应归一化方法对其进行增强。给定去噪器中间状态m和风格编码s,我们进行归一化和风格增强:
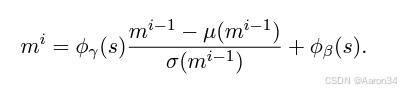
由于注入了风格变体信息,这促使相似的解码器输入生成自然且多样的梅尔频谱图。为了训练解码器,我们使用平均绝对误差(MAE)损失和结构相似性指数(SSIM)损失。
S\&D-LM
歌唱风格(如演唱方法、情感、节奏、技巧和发音)通常表现出局部和长期的依赖关系,并且它们随时间快速变化,与内容的相关性较弱。这使得条件语言模型在本质上非常适合用于预测风格。同时,音素时长具有丰富的变化并且与歌唱风格密切相关。因此,我们提出了风格与时长语言模型(S&D - LM)。通过 S&D - LM,我们可以利用音频和文本提示实现零样本风格迁移和多级风格控制。
对于风格迁移,给定目标的歌词、音符,以及音频提示(audio prompt)的歌词l、音符n、梅尔频谱图m,我们的目标是合成具有音频提示中未见过的音色和风格的高质量目标歌声的梅尔频谱图。首先,我们使用不同的编码器来提取音频提示的音色信息t、内容信息c和风格信息s以及目标内容信息:
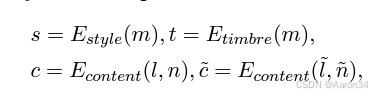
其中E表示针对每个属性的编码器。鉴于目标音色预期与音频提示相似,我们还需要目标风格。利用语言模型强大的上下文学习能力,我们设计了风格与时长语言模型(S&D - LM)来预测。同时,我们还利用 S&D - LM 预测目标音素时长d,利用歌声中音素时长和风格之间的强相关性来增强这两个预测。我们的 S&D - LM 基于仅解码器(decoder - only)的基于 Transformer 的架构。我们将提示音素时长、提示风格、提示内容、目标内容和目标音色连接起来形成输入。自回归预测过程将是:
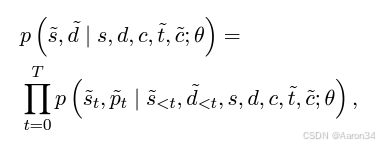
最后,令P表示音高扩散预测器(pitch diffusion predictor),D表示风格自适应解码器(style adaptive decoder),来生成目标的F0和mel:
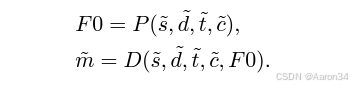
对于风格控制,使用替代的文本提示时,我们不需要从音频提示中提取风格信息和音素时长。相反,我们使用文本编码器对全局演唱方法和情感和音素级每个音素的技巧的文本提示进行编码,然后将其与内容信息、目标内容信息和目标音色连接起来以形成输入。风格与时长语言模型(S&D - LM)的预测过程变为:
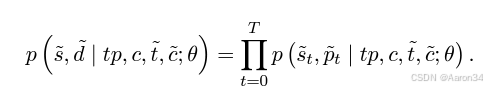
在训练期间,我们对风格信息使用交叉熵损失(cross - entropy loss),对音素时长使用均方误差(Mean Squared Error,MSE)损失。对于风格迁移,聚类风格编码器从真实值(Ground Truth,GT)梅尔频谱图中提取风格信息,以教师强制(teacher - forcing)模式训练风格与时长语言模型(S&D - LM)。我们设置一个概率参数,用于决定是训练风格迁移任务还是风格控制任务,这使得我们的模型能够处理这两种任务。
训练和推理
在训练阶段,TCSinger 的最终损失项由以下部分组成:1)聚类向量量化(CVQ)损失:聚类风格编码器的 CVQ 损失;2)音高重建损失、:音高扩散预测器中预测的音高频谱图与真实值(GT)音高频谱图之间的高斯扩散损失和多项式扩散损失;3)梅尔重建损失、:风格自适应解码器中预测的梅尔频谱图与真实值(GT)梅尔频谱图之间的平均绝对误差(MAE)损失和结构相似性指数(SSIM)损失。4)时长预测损失:在教师强制(teacher - forcing)模式下,风格与时长语言模型(S&D - LM)中预测的与真实值(GT)音素级时长(以对数尺度)之间的均方误差(MSE)损失;5)风格预测损失:在教师强制(teacher - forcing)模式下,风格与时长语言模型(S&D - LM)中预测的与真实值(GT)风格信息之间的交叉熵损失。
在零样本风格迁移推理过程中,我们使用从音频提示中提取的内容信息、音色信息、风格信息、音素时长以及目标内容作为风格与时长语言模型(S&D - LM)的输入,并得到目标风格信息。然后,由于目标的音色和提示保持不变,我们将目标的内容、音色、风格信息和音素时长连接起来,通过音高扩散预测器生成基频(F0),再通过风格自适应解码器生成最终的梅尔频谱图。因此,生成的目标歌声能够有效地迁移音频提示的音色和风格。此外,我们还可以进行跨语言语音和歌唱风格的迁移。对于跨语言实验,提示中的歌词和目标中的歌词语言不同(例如英语和汉语),但过程是相同的。对于语音 - 歌唱(STS)实验,语音数据被用作音频提示,使得目标歌声能够迁移语音的音色和风格,其余步骤保持一致。
在多级风格控制推理期间,音频提示仅提供音色,无需使用聚类风格编码器来提取提示风格。全局和音素级别的文本提示都通过文本编码器进行编码以替代风格信息和音素时长,合成目标目标风格信息和目标音素时长,其余过程与风格迁移任务一致。全局文本提示包含演唱方法(例如美声、流行)和情感(例如快乐、悲伤),而音素级别的文本提示控制每个音素的技巧(例如混声、假声、气声、颤音、滑音、咽音)。通过这些文本提示,我们能够生成在全局和音素级别上具有个性化音色和可独立控制风格的歌声。
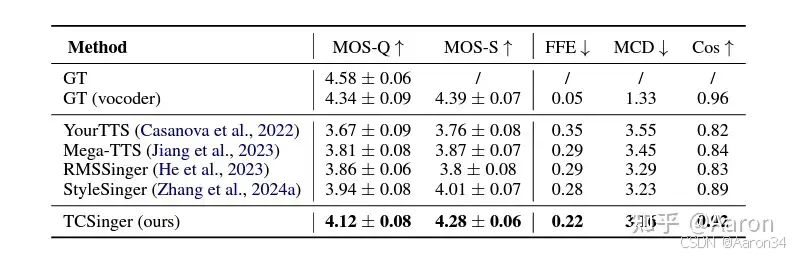
4. 实验
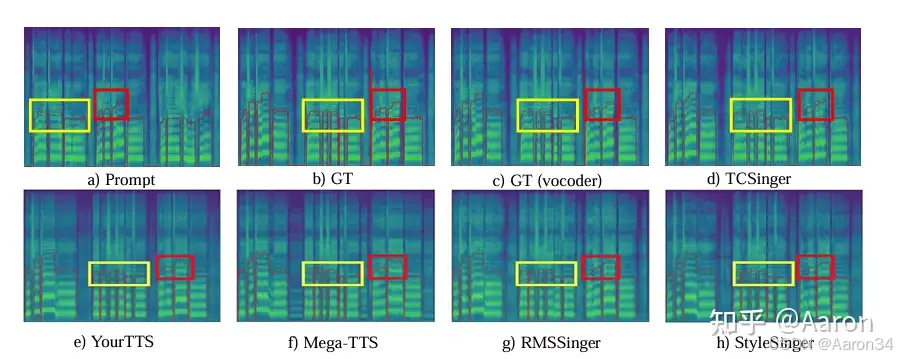
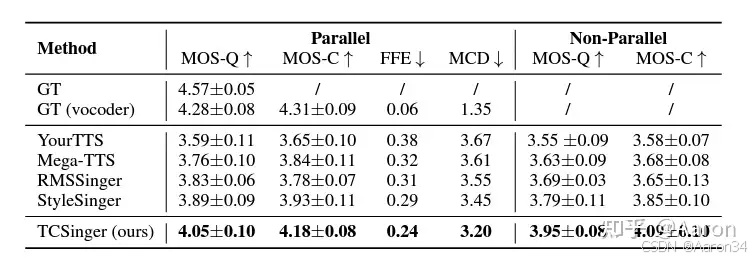
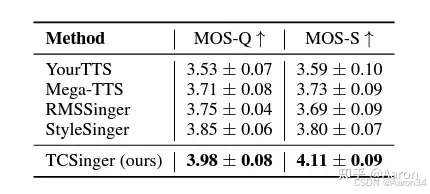
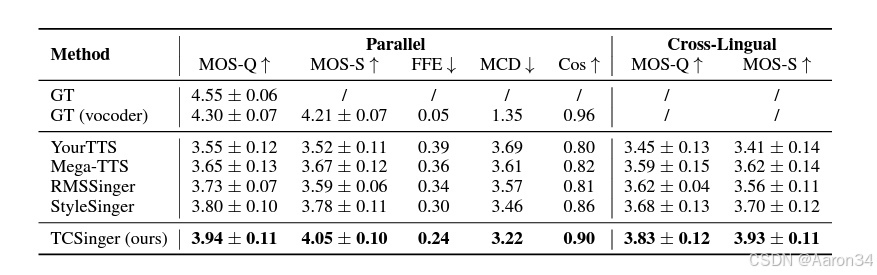

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









