










题目:TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching
作者:Wenxiang Guo, Yu Zhang, Changhao Pan, Rongjie Huang, Li Tang, Ruiqi Li, Zhiqing Hong, Yongqi Wang, Zhou Zhao
论文:TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching
Demo:TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching
1. 摘要
歌声合成任务旨在通过输入的歌词和乐谱生成高质量的歌声。随着深度学习技术的发展,现有方法在生成自然且高质量的音频方面取得了显著进展,但鲜少能实现精准控制的歌唱技巧(如强度、混声、假声和气声等)。为此,本文提出TechSinger,一种支持五种语言与七种歌唱技巧精细控制的歌声合成系统,克服传统方法在可控性和艺术表达上的局限。
2. 引言
传统歌声合成技术缺乏对歌唱技巧的精细控制,且受限于现有数据集标注不足以及控制方式复杂的问题。TechSinger 通过以下创新解决难题:
-
自动标注技术:训练技巧检测器,为开源歌声数据自动添加音素级技巧标签。
-
流匹配生成框架:基于流匹配方法精准建模不同技巧歌声的音高与梅尔频谱。
-
多种技巧控制方式:支持通过技巧标签或自然语言指令指定合成技巧。
3. 方法
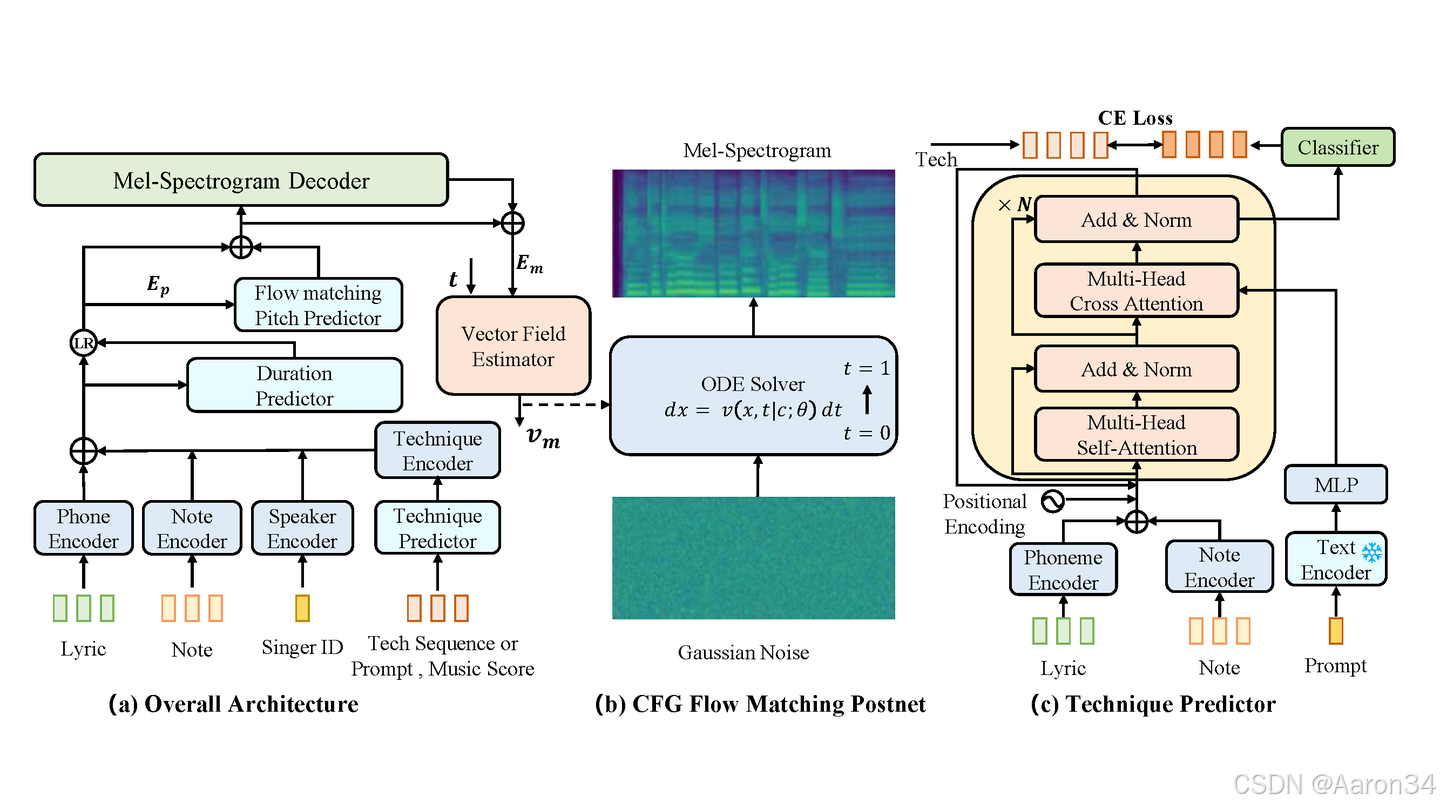
总体框架
模型输入包括乐谱、MIDI 序列、歌手和技巧信息。若输入为自然语言 prompt,预训练的技巧预测器将生成对应音素的技巧标签。模型分为两阶段:
-
第一阶段:预测音素时长,通过流匹配生成基频(F0),解码器生成粗糙梅尔频谱。
-
第二阶段:以编码信息和粗糙梅尔频谱为条件,使用流匹配策略生成高质量梅尔频谱。
流匹配策略(Flow Matching)
TechSinger 基于流匹配模型预测音高(F0)和梅尔频谱,从而实现高精度技巧控制。具体而言,Flow Matching 通过高斯噪声与目标 F0/Mel 的线性插值构建概率路径,利用ODE求解器预测向量场,以规避传统 L1 损失导致的频谱模糊问题。训练损失如下:
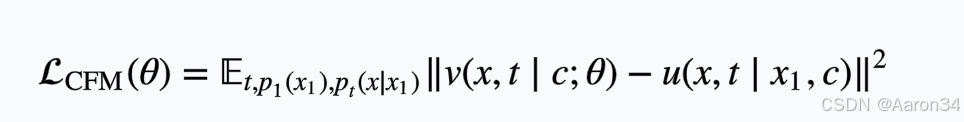 生成过程中使用 Euler ODE 求解器进行逆向生成预测:
生成过程中使用 Euler ODE 求解器进行逆向生成预测:
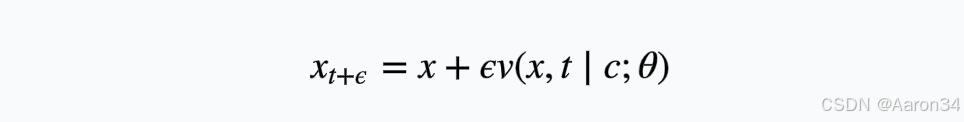
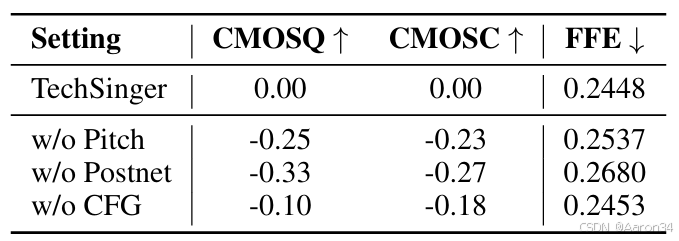
为进一步提升梅尔频谱质量,本文引入分类器无关引导(CFG)的流匹配后处理网络,结合标签随机丢弃策略,增强模型对标注噪声的鲁棒性。CFG 公式如下:
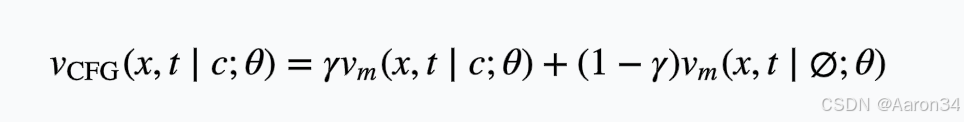
其中,缩放参数可用于调节生成技巧的强度。
技巧检测器与预测器
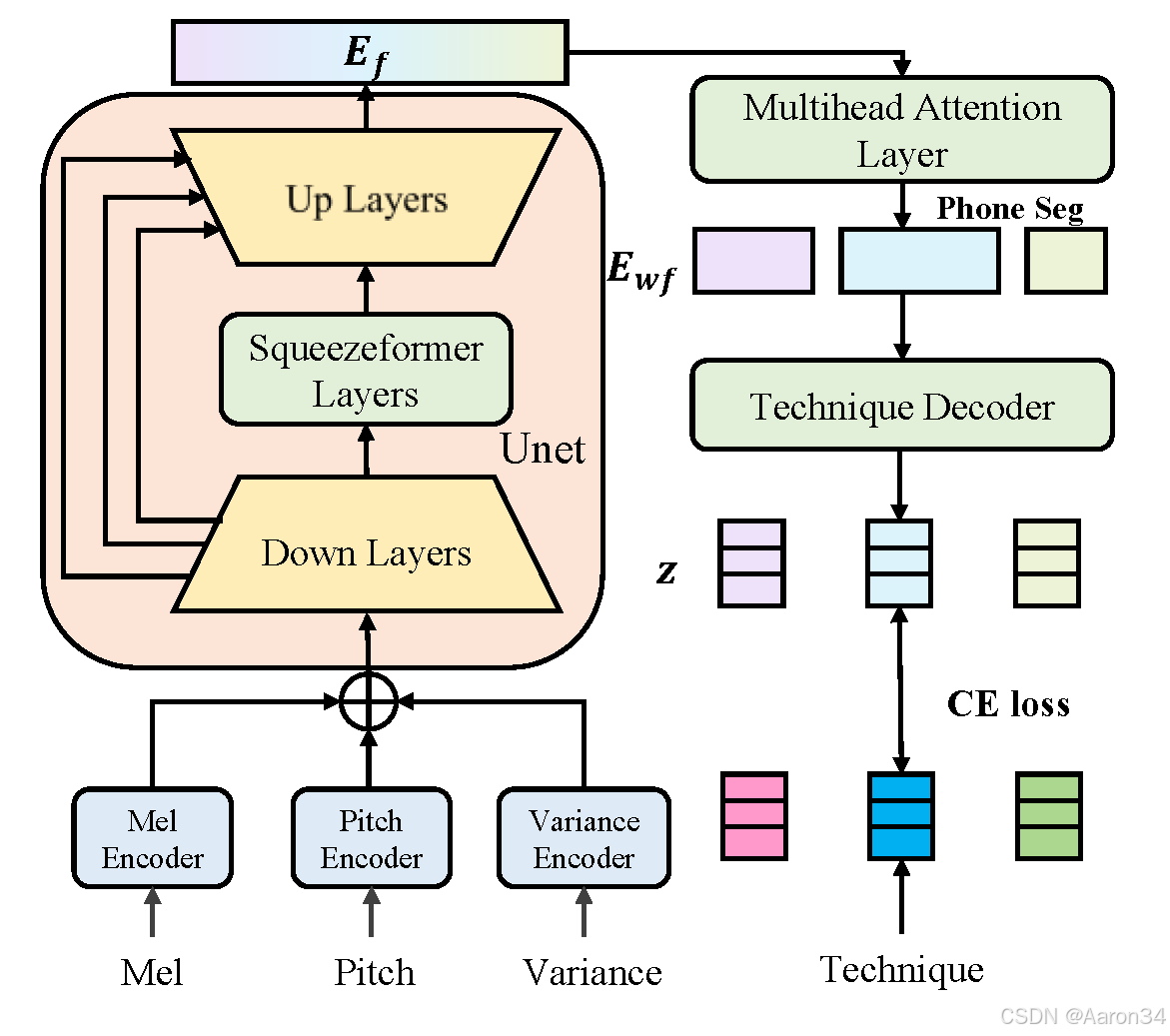
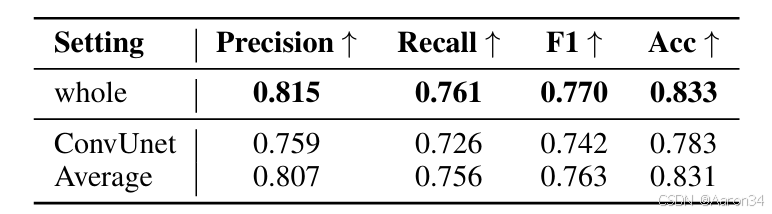
对于技巧检测器,为实现开源数据集的技巧标注,本文基于有标注的歌声数据训练技巧检测器。该检测器编码梅尔频谱、音高和能量等特征,采用以 Squeezeformer 为主体的 Unet 框架及多头注意力层,最终预测音素级技巧序列。损失函数为:
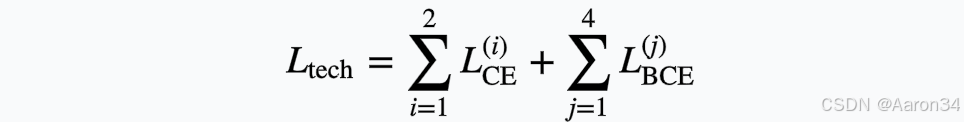
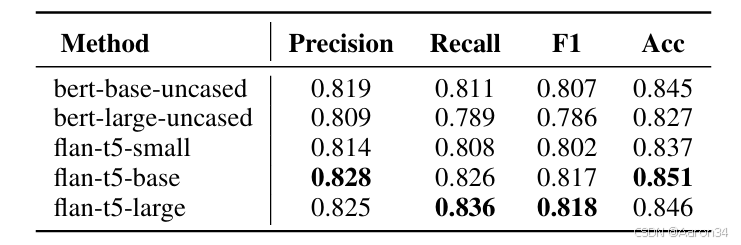
对于技巧预测器,为实现自然语言控制,本文基于 GPT-4o 设计 prompt 模板生成训练数据,并采用 FLAN-T5 编码器对用户提示(如“使用强力度演唱”)进行编码,通过 Transformer 模型预测音素级技巧序列。
4. 实验
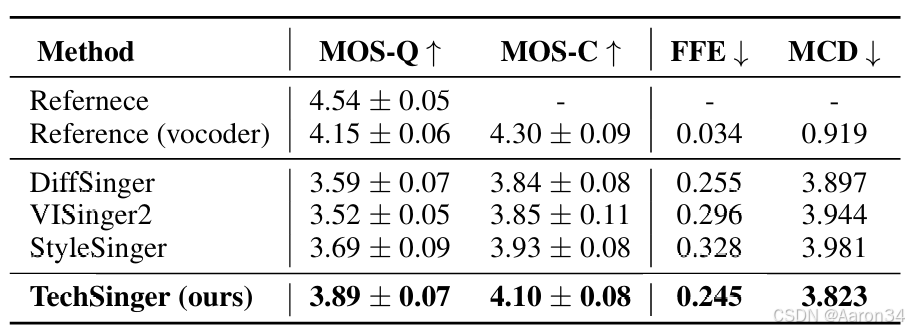
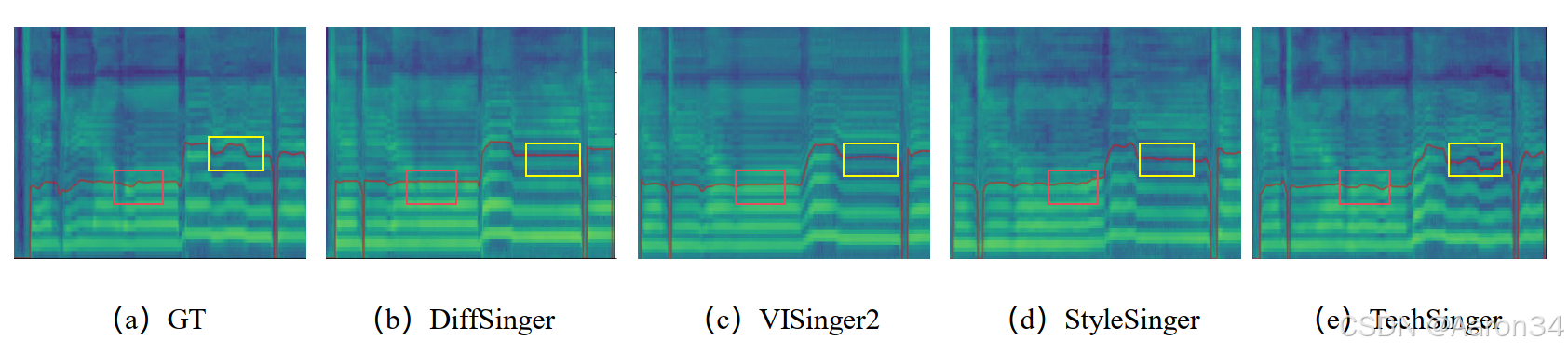
5. 总结与展望
本文提出首个基于流匹配框架的多语言、多技巧可控歌声合成系统 TechSinger,通过自动标注技术解决数据不足问题,并利用流匹配精准建模音高与频谱。此外,通过技巧预测器,实现自然语言控制歌声技巧生成。实验表明其能生成高质量、高表现力的歌声。 未来,将探索跨歌手音色迁移,控制生成技巧的强度,进一步提升创作自由度。

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









