







选择性搜索 2013
文章目录
距离现在时间好像有点远了,但是作为传统图像处理方法,论文方法和思想还是很值得深度阅读,并且它确实为早期目标检测(2013-2015前后)的发展做出了很多基础贡献。整个论文有一种“缝合怪”的感觉,就是拿了好几个方法的优点过来组合在一起,达成了当时的 sota。
不过现在站在上帝角度回头来看的话,尽管论文已经尽力采用很多避免重复计算的设计,比如基于特征计算而非原图信息计算,基于自底向上自然地利用层级并获得多种尺度,但是传统特征提取与 CNN 在图像特征提取方面的能力相比,还是捉襟见肘。因此,发展到 faster-RCNN 时,Selective Search 就被“优化”掉了。
Abstract
- 解决物体检测任务中,搜索可能存在物体的位置框。(其实说位置框是不准确的,因为矩形框在很多时候并不能很好地说明物体的位置,但是后面提到这个概念我还是先用的框的概念,可以理解成“多边形框/区域”会更合适。)
- Seletive Search 兼具暴力搜索和图像分割的优点,利用分割过程中的图像结构来指导生成生成尽可能多地物体框样本。
- 使用多种而非单一策略和各种互补的图像分割以实现处理尽可能多的情况。
- 生成较少的(相对暴力搜索的物体框数量)数据驱动、独立于类别、高质量的物体框。
- 因为生成的框相对较少,可以减少运算压力,因此可以使用一些更好的机器学习技术及模型来实现物体检测。
Introduction
很长一段时间,物体检测的第一步是寻找候选框,如果说候选框太狭义(因为并不是所有的物体都适合用长方形来表示),第一步是“描绘物体”。所以这自然而然地使图像分割在这个过程中可以担任“描绘”工作。但是一般的图像分割算法,对某图片的处理结果只有一种。但是实际上,图像中自然地有层级概念,或者可以叫有“上下文”。各种物体之间也是有层级概念的,比如桌子和盘子之间肯定有关联性,水果和苹果也有关联性。比如图像中有一张桌子,桌子上有一个盘子。你可以说桌子本身是桌子,也可以说包含了盘子在内的叫桌子。也就是说,在图像分割工作上,好像并没有完美的唯一答案。
传统的图像分割算法往往采用唯一的策略来实现分割,比如边缘。那么如果对于边缘效果不好的情况,也就无法完成有效的分割。或者比如汽车的轮胎这种有包围情况的。本文就不是单一策略了,包括颜色、纹理等。对于毛衣上面有一张人脸的情况,除非你知道整体是个人,否则你不会把毛衣和人脸作为一个物体框起来。但是这样就悖论了,即原本为了做检测所以先画框,现在为了画好框反而需要检测之后的类别结果。
一种解决这种悖论的方法就是穷举,按照锚点、尺寸和比例来穷举图片中的框。但是这样计算量非常大,而且很多物体没有办法使用矩形框来框得很好,比如草地、沙滩等。
本文就是使用自底向上的图像分割方法,利用了图像中自然存在的结构,并且按照穷举的思想,尽可能多地搜索物体框。
Related Work
这里还是前面有说到,本文就是在做“缝合怪”。它缝合了暴力穷举、图像分割,在图像分割部分又借助多种策略且自底向上地实现分割。
Exhaustive Search
暴力分割不再赘述。不同锚点、尺寸、比例的穷举,生成位置框过多,且很多与图中真实物体情况并不吻合。
Segementation
这里亮点就是多策略、自底向上,还有层级概念。
Other Sampling Stategies
主要对比深度学习 CNN,2012 Alexnet 使用分类器来判断有无物体,需要有学习过程,相比来说, Selective Search 自底向上,过程中自然地就获取了结构信息,所以不需要学习。
Selective Search
自底向上可以获得任何尺寸的物体框,这个过程也包含了层级概念的实现。
多种策略实现图像分割。
输出的框整体质量更好,自然可以避免很多不必要的计算。
Selective Search by Hierarchical Grouping
自底向上本身就具有层级的属性,且能找到任意尺度的目标。算法简单可以分为初始化、计算相似度、根据相似度合并更新、重复前两步一直到全图都为一个目标。其中邻居对儿是不断删除添加更新的,区域是不断求并集更新的。最后,邻居对集合 S 应该为空,区域集合中也包含了各个尺寸的区域。
相似度计算部分,需要较为快速,且基于特征而非原区域部分的像素。这样的话,决定合并某两个区域时,合并后的新区域的特征能直接从刚刚两个较小区域的特征计算得来。

Diversification Strategies
- 不同的颜色空间,针对不同的场景和光照条件。RGB + I + Lab + rgI + HSV + normRGB(rgn) + C + Hue。前面算法计算过程中,都是用单独一个颜色空间,不会混用。
- 不同的相似度计算方法,四个组合在一起。颜色、纹理、尺寸和填充。
- 不同的初始区域,论文的初始化算法其实是一种,但是由于有不同的颜色空间,所以也造成了使用同一种算法的初始化结果会有不同。
其实这一部分我认为可以主动地从“特征”方面去理解。这部分在追求一定泛化性(颜色空间和随机初始化)的同时,在获取尽可能多/客观的特征来描述对应区域的像素/区域。
颜色:
某个 region 的单个通道使用 25 bins 的直方图来表示,按照 3 个通道来计算就是长度为 75 的特征向量,该向量会先经过 L1-norm。两个区域之间的相似度按位取特征向量的较小值:
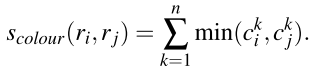
新区域的颜色特征向量,可以通过两个小的区域的特征向量直接获取,不用再访问原图重新计算:
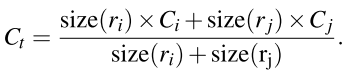
纹理:
纹理特征使用 SIFT 特征计算,因为 SIFT 本身就很适合材质识别。某个 region 的单通道 8 个方向,每个方向使用 10 bins 直方图表示,这样 3 通道的 region 在纹理方面的特征向量长度为 3 × 8 × 10 = 240,同样该向量会先经过 L1-norm。两个区域之间的相似度类似颜色部分:
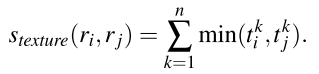
在计算新区域的纹理特征向量时,也类比颜色特征计算。
尺寸:
尺寸特征的存在使得小区域更容易被合并,同时也是为了防止某些区域“一家独大”一直从小“长”到大,而别的位置的区域得不到机会“长大”。
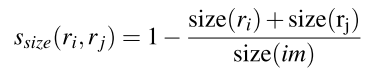
填充:
这点上的考虑是,合并之后的区域应该也很“正常”,也就是说两个区域合并之后形成的新区域不应该出现很奇怪的形状。即使两个区域其他的特征都很相似,如果合并之后形状非常不匹配,那这是不符合预期的。这里使用合并前两区域的外接矩形重合度,来计算填充部分的特征。
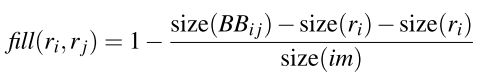
论文中是把上面四个特征合并在一起使用的:
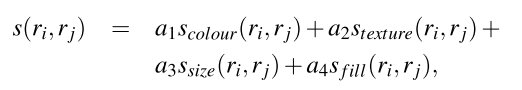
Combining Locations
本部分主要是为了能区分开各个候选区域。很多算法只会要求返回前 N 个结果,况且确实并不是每个候选框的“价值”都是一样的。比如先被“候选”的框分值比后“候选”出来的高一点,多次被“候选”的分值高一点。这里的一个 tirck 是,针对很多分值一样无法很好排序的情况,直接乘以随机数(去掉运气不好的候选框/(ㄒoㄒ)/~~)。
Object Recognition using Selective Search
这里使用的是 SVM 分类器,pipline 如下:
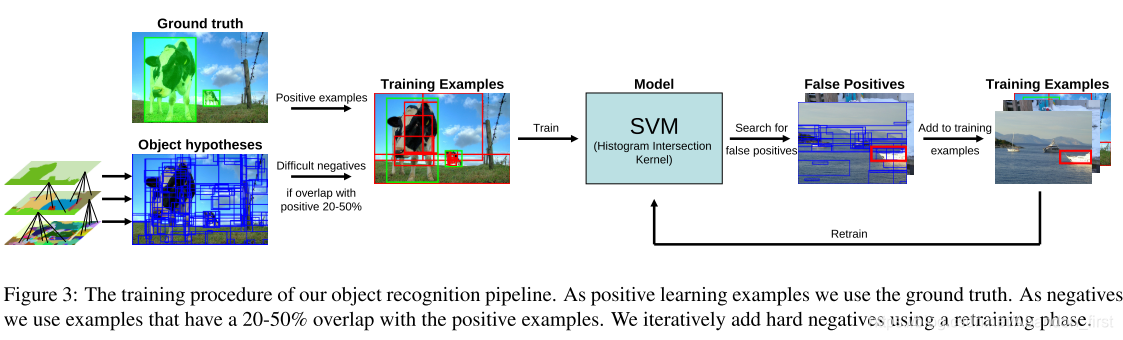
在训练过程中需要注意的是,物体检测经常会出现正负样本数量过于悬殊的情况。这里使用的正样本即 ground truth,使用的负样本是与正样本重合 20~50%的矩形框。所有小图上的红色框都是负样本,训练不断迭代,根据之前训练结果表现不佳的“假阳性”作为负样本添加回训练数据。
重叠率超过 70% 的负样本,会被去掉;还会随机去掉一半的负样本。
越是接近 ground truth 正样本的负样本,越是最难区分的,difficult negative samples。
Conclusions
总之就是个缝合怪啦~














 3879
3879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









