







概述
这篇论文提出的神经雪球(Neural Snowball), 是用来应对关系增长的关系抽取模型。
“应对关系增长”什么意思呢?让我们联系现实生活:现实生活中的关系,是无穷无尽的,而且会不断增长,也就是会出现新关系。
目前关系抽取问题一般可以转换为关系分类问题。想要处理新关系,按照一般做法来说就需要新关系对应的数据。
名词介绍
实例:这里实例指的实际上就是语料库中的句子
最终目的
针对每一个新关系r,训练得到一个二分类器
使用的数据

- 大量带标注数据集,对应图中最左边的数据
- 少量带标注的新关系数据集(即上文提到的新关系r),对应中间的数据
- 大量无标注数据集 ,对应最右边的数据
使用这三种数据训练得到针对关系r的二分类器
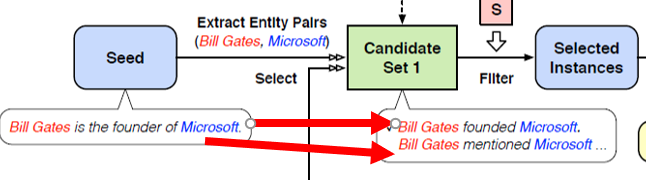
整体方法
在这一部分我们将结合下图,简单介绍各个模块的作用以及整体流程

Seed 种子集
-
种子集是关系r的实例,对应的是少量带标注的新关系数据集。
-
每一轮迭代之后,一部分未标注数据集(unlabeled Data,对应大量无标注数据集)被填充进来。
C1(Candidate Set 1)候选集
- 通过远监督的方式从unlabeled data中挖掘得到的新实例,其中远监督是指把实体相同的句子挑出来
- 不一定有我们想要的关系,因此需要进一步筛选
RSN网络(Relational Siamese Network)
- 可以获取两个实例的相似性,即获得相似性评分score
- 通过以下两个条件判断C1中的实例是否为有用的关系,满足这两个条件则认为是图中的Selected Instances
- 实例的 score为前Top k1个
- 实例的 score > α
- Fine-tune: 使用上一步过滤得到的Selected Instances数据,训练二分类器RC(请看下一部分)
这里实例的score是指:使用RSN网络获得的C1实例与当时远监督使用的种子集实例相似性评分
关系二分类器RC(Relation Classifier):
- 最终需要的二分类器
- 在神经雪球每轮的迭代中分类能力逐渐增强:其实神经雪球初期RC是比较弱的,毕竟每轮迭代获得的Selected Instances可能也就十几个,甚至只有几个(因为K1很小)
候选集C2
- 使用二分类器预测得到的正类
- 因为二分类器比较弱,所以C2还需要进一步过滤
RSN网络
- 这里又一次使用了与前面相同的RSN网络,用于对C2进行进一步过滤,按照下面两个条件:
- 实例的 score为前Top k2个
- avg(score) > β
注意,这里的score分数指代的是:当前C2中的这个实例与种子集中的每一个实例的分数
总结
- 目的:整个神经雪球迭代的目的在于逐步从未标注数据集中挖掘带标注的数据,同时逐渐提高关系二分类器的性能。
- 可以理解为两阶段任务:
- 第一阶段任务:利用远监督获取候选句子,此时实体对还是相同的
- 第二阶段任务:使用筛选后的句子增强关系分类器。利用关系分类器获取待选句子,填充种子集。由于使用了关系分类器对所有未标注数据集进行分类的原因,此时加入种子集的实体对是不相同的,即增加了种子集中实体对的多样性
思考问题:
- 怎么利用大规模标注数据集?
对比论文一开始提到的三种数据,其中的大量带标注数据集和少量带标注的新关系数据集已经被利用上了,然而大规模标注数据集始终没有被提及。
这个数据集虽然带标注,而且规模很大,但是并不是我们这里的新关系二分类器所需要的。这里留下一个悬念,悬念将在接下来的部分揭秘。
- 为什么这里针对每一个新关系要用二分类器,而不是直接使用一个多分类器?
论文中针对这个问题进行了解释

各模块介绍
RSN

- 用于获取两个实例句子的相似性
- 输入: 两个实例
- 输出:0-1之间的实数,代表两个实例的相似度
- 结构:
- 使用权值共享的两个encoder获得输入实例的表示向量
- 使用距离公式计算相似度:可以理解为加权的L2距离范数,这里的权值是训练得到的。
这里我理解的权值共享,意思是两个encoder的所有参数是一样的,实际上就是一个encoder,在两个地方使用了。(这个理解不一定对)
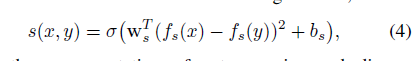
关系二分类器RC(Relation Classifier)
- 包括encoder 和 线性层
- 输入:一个句子(实例)
- 输出: 0-1之间的实数,可以使用超参数阈值使得输出为0 or 1
- Encoder 的作用:把句子转换为表示向量
- 线性层:其实就是一个简单的全连接层,激活函数为线性激活函数。这里的f(x)就是上一层encoder的输出结果
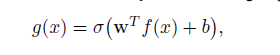
Encoder层:提取句子的抽象表示
- 是RSN和关系分类器的一部分
- 实验使用了:CNN、BERT
-
一维的CNN:使用word embedding 和position embedding作为输入,参考python深度学习一书对一维CNN的阐述

-
BERT:老自然语言处理了,需要进一步了解
-
训练细节介绍
在这一部分我们将解答前面提到的问题,即:怎么利用大规模标注数据集
Pretraining: 开始Neural Snowball之前
RSN
- 使用大规模标定数据集进行训练,这里使用
Sn指代大规模标定数据集 - 采样: 采样的两个相同关系类型的句子则认为输出为1,两个不同关系类型的句子则认为输出为0
新关系二分类器RC
- 为了训练二分类器的encoder层,且适应大规模数据集有多种关系的情况,使用
Sn训练一个多分类器。 - 后面要用二分类器的时候再把最后的全连接层换掉,只保留encoder层。
Fine-tuning:在Neural Snowball的迭代过程中
RSN
- 冻结全部层
- 认为通过
Sn预训练已经学到如何提取特征了
新关系二分类器RC
- 冻结encoder层,训练二分类的线性层:w, b
- 正样本:来自新增的种子集
- 负样本:来自
Sn(除了新关系之外的所有其他关系都是负样本,没毛病) - 使用带权重的交叉熵:因为来自新增种子集的正样本很少(这点在整体方法部分也有提及),而负样本来自大规模标定数据集,数据量与正样本自然不是一个数量级的
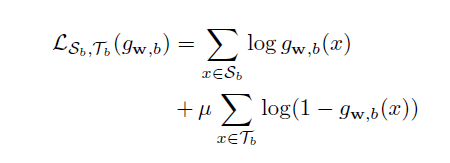
总结
整体流程
- 通过Seed set远监督获取C1
- 使用RSN筛选C1
- 使用筛选后的C1 微调二分类器RC
- 使用R筛选所有的未标注数据集,获得C2
- 使用RSN筛选C2,加入Seed
训练细节
- Pretraining
- Fine-tuning
亮点
- 利用上了三种数据
- 使用RSN辅助新关系二分类器的训练
未来工作
- 探索如何跳出”舒适区”
这里的跳出舒适区大概可以理解成:如何发现更多样性的实例,而不是语义相近的实例 - 探索学习新关系的时候同时调整RSN
毕竟RSN是针对大规模标注数据集,通过RSN学到的表示知识可能不一定适用于新关系的数据集
问题
需要数量非常庞大的无标注数据集,因为要从中找到与种子集实例相同的实体对,还要进一步筛选,可能不一定适合实际工业项目的情况。















 2741
2741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









