









Mask Scoring R-CNN
CVPR2019会议论文
主要任务不是实例分割,而是评估获得的实例分割的掩码的质量。文中提到,以前通常用分类类别的置信度来评估分割的掩码的质量,这是没有说服力的,从而提出了一种新的方法来评估预测的掩码质量。
Abstract
让深度网络意识到自己预测的质量是一个有趣但重要的问题。 在实例分割任务中,在大多数实例分割框架中,实例分类的置信度被用作掩码质量分数。 然而,被量化为实例掩码与其ground truth之间的 IoU 的掩码质量通常与分类分数没有很好的相关性。 在本文中,我们研究了这个问题并提出了 Mask Scoring R-CNN,它包含一个网络块来学习预测实例掩码的质量。提出的网络块将实例特征和相应的预测掩码结合起来,以回归掩码IoU。mask评分策略校准mask质量和mask评分之间的偏差,并通过在COCO AP评估期间优先考虑更准确的mask预测来提高实例分割性能。通过对COCO数据集的广泛评估,Mask Scoring R-CNN为不同模型带来了一致且显著的收益,并优于最先进的Mask RCNN。我们希望我们简单有效的方法将为改进实例分割提供一个新的方向。我们方法的源代码可在https://github.com/zjhuang22/maskscoring_rcnn上获得。
Introduction
深层网络极大地推动了计算机视觉的发展,导致出现了一系列先进的任务,包括分类[22, 16,35],目标检测[12,17,32,27,33,34],语义分割[28,4,37,18]等。从深度学习在计算机视觉的发展,我们可以发现,深层网络的能力正逐渐从进行图像级别的预测[22]到区域/边界框级别[12]的预测, 像素级预测[28],实例/掩膜级别的预测[15]。进行细粒度预测的能力不仅需要更详细的标签,还需要更精细的网络设计。
在本文中,我们关注实例分割问题,这是对象检测从粗略的边界框级实例识别到精确的像素级分类的自然下一步。 具体来说,这项工作提出了一种对实例分割假设进行评分的新方法,这对于实例分割评估非常重要。原因在于大多数评估指标是根据假设分数定义的,更精确的分数有助于更好地表征模型性能。例如,PR曲线和平均精度(AP)通常用于具有挑战性的实例分割数据集 COCO [26]。如果一个实例分割假设没有正确评分,它可能会被错误地视为假阳性或假阴性,从而导致 AP 下降。
然而,在大多数实例分割设计中,例如 Mask R-CNN [15] 和 MaskLab [3],实例掩码的分数与框级分类置信度共享,这是由应用于提议特征的分类器预测的。 使用分类置信度来衡量掩码质量是不合适的,因为它仅用于区分提议的语义类别,而不知道实例掩码的实际质量和完整性。分类置信度和掩码质量之间的偏差如图 1 所示,其中实例分割假设得到准确的框级定位结果和高分类分数,但相应的掩码不准确。 显然,使用这样的分类分数对掩码进行评分往往会降低评估结果。

Fig.1 实例分割的演示案例,其中边界框与ground truth有很高的重叠,分类分数很高,而mask不够好。Mask R-CNN和我们提出的MS R-CNN预测的分数附在相应的边界框上方。左四幅图像显示了良好的检测结果,分类分数较高,但mask质量较低。我们的方法旨在解决这个问题。最右边的图片显示了一个分类分数高的好mask。我们的方法将对高分进行再培训。可以看出,我们的模型预测的分数可以更好地解释实际的掩模质量。
与先前旨在获得更准确的实例定位或分割掩码的方法不同,我们的方法侧重于对掩码进行评分。为了实现这一目标,我们的模型学习每个掩码的分数,而不是使用其分类分数。为了清楚起见,我们将学习分数称为掩码分数。
受实例分割的AP度量的启发,该度量使用预测掩码与其ground truth掩码之间的像素级交叉-过度联合 (IoU) 来描述实例分割质量,我们提出了一种直接学习IoU的网络。在本文中,该IoU表示为MaskIoU。一旦我们在测试阶段获得了预测的MaskIoU,通过将预测的MaskIoU和分类得分相乘来重新评估mask得分。因此,掩码分数同时了解语义类别和实例掩码完整性。
学习 MaskIoU 与提议分类或掩码预测有很大不同,因为它需要将预测的掩码与对象特征进行“比较”。 在 Mask RCNN 框架内,我们实现了一个名为 MaskIoU head 的 MaskIoU 预测网络。 它将掩码头的输出和 RoI 特征作为输入,并使用简单的回归损失进行训练。我们将提议的模型命名为mask scoring R-CNN(MS R-CNN),即带有MaskIoU head的mask R-CNN。使用我们的MS R-CNN进行了大量实验,结果表明,由于掩模质量和分数之间的一致性,我们的方法提供了一致且显著的性能改进。
总之,这项工作的主要贡献如下:
- 我们提出了第一个解决实例分割假设评分问题的框架——mask scoring R-CNN。它探索了一个提高实例分割模型性能的新方向。通过考虑实例掩码的完整性,如果实例掩码分类得分高而掩码不够好,可以对其得分进行惩罚。
- 们的MaskIoU head 非常简单有效。在具有挑战性的COCO基准上的实验结果表明,当使用来自我们的MS r-cnn的掩码得分而不仅仅是分类置信度时,AP在各种骨干网的情况下持续提高约1.5%。
Related Work
Instance Segmentation
当前的实例分割方法可以大致分为两类。一种是基于检测的方法,另一种是基于分割的方法。基于检测的方法利用最先进的检测器(例如 Faster R-CNN [33]、R-FCN [8])来获取每个实例的区域,然后预测每个区域的掩码。皮涅罗等人[31] 提出 DeepMask 以滑动窗口方式对中心对象进行分割和分类。戴等人[6] 提出实例敏感的 FCNs 来生成位置敏感的特征图并将它们组装起来以获得最终的掩码。 FCIS [23] 采用具有内部/外部分数的位置敏感图来生成实例分割结果。 He等人[15] 提出了在 Faster R-CNN 之上添加实例级语义分割分支的 Mask R-CNN。基于Mask r-cnn,Chen等人 [3] 提出了使用位置敏感分数来获得更好结果的MaskLab。然而,这些方法的一个潜在缺点是掩模质量仅通过分类分数来衡量,因此导致了上面讨论的问题。
基于分割的方法首先预测每个像素的类别标签,然后将它们分组,形成实例分割结果。Liang等人[24]使用光谱聚类对像素进行聚类。其他工作,如[20,21],在聚类过程中添加边界检测信息。Bai等人[1]预测像素级的能量值,并使用分水岭算法进行分组。最近,有一些著作[30,11,14,10]使用度量学习来学习像素嵌入。具体来说,这些方法为每个像素学习一个嵌入,以确保来自同一实例的像素具有相似的嵌入。 之后,对学习到的嵌入进行聚类以获得最终的实例标签。 由于这些方法没有明确的分数来衡量实例掩码质量,因此它们必须使用平均像素级分类分数作为替代方案。
上述两种方法都没有考虑掩码分数和掩码质量之间的对齐。由于掩码分数的不可靠性,如果掩码分数较低,则与ground truth 的 IoU 较高的掩码假设很容易被列为低优先级。在这种情况下,最终的 AP 会因此降级。
Detection Score Correction
有几种方法专注于校正检测框的分类分数,其目标与我们的方法相似。 Tychsen-Smith 等人[36]提出了Fitness NMS,它使用检测到的边界框与其ground truth之间的IoU来纠正检测分数。 它将box IoU的预测制定为分类任务。我们的方法与此方法的不同之处在于,我们将掩码 IoU 估计制定为回归任务。 江等人[19] 提出了直接回归box IoU 的 IoU-Net,预测的 IoU 用于 NMS 和边界框细化。 在 [5] 中,Cheng 等人讨论假阳性样本并使用分离的网络来纠正这些样本的分数。 SoftNMS [2] 使用两个框之间的重叠来纠正低分框。 诺伊曼等人[29]提出了Relaxed Softmax来预测标准softmax中的温度比例因子值,用于安全关键的行人检测。
与这些专注于边界框级别检测的方法不同,我们的方法是为实例分割而设计的。 实例掩码在我们的 MaskIoU head中进一步处理,以便网络可以知道实例掩码的完整性,最终掩码分数可以反映实例分割假设的实际质量。 是提高实例分割性能的一个新方向。
Method
Motivation
在当前的 Mask R-CNN 框架中,检测(即实例分割)假设的分数由其分类分数中的最大元素决定。由于背景杂乱、遮挡等问题,有可能分类得分高但掩码质量低,如图1所示。为了定量分析此问题,我们将来自mask r-cnn的朴素Mask评分与预测的mask及其ground truthmask (MaskIoU) 之间的实际IoU进行了比较。
具体来说,我们在COCO 2017验证数据集上使用mask r-cnn和ResNet-18 FPN进行实验。然后,我们选择MaskIoU和分类得分均大于0.5的软NMS后的检测假设。MaskIoU在分类分数上的分布如图2 (a) 所示,每个MaskIoU区间的平均分类分数在图2 © 中以蓝色表示。这些数字表明,在Mask r-cnn中,分类得分和MaskIoU相关性不高。
Fig.2 Mask R-CNN 和我们提出的 MS R-CNN 的比较。 (a) 显示了Mask R-CNN的结果,mask score与MaskIoU的关系较小。 (b) 显示 MS R-CNN 的结果;我们用高分和低 MaskIoU 来惩罚每个检测,并且掩码分数可以更好地与 MaskIoU 相关。 © 显示定量结果,我们平均每个 MaskIoU 区间之间的分数;我们可以看到我们的方法可以在 score 和 MaskIoU 之间有更好的对应关系。
在大多数实例分割评估协议 (例如COCO) 中,具有低MaskIoU和高分的检测假设是有害的。在许多实际应用中,确定检测结果何时可以信任以及何时不能信任非常重要 [29]。这些激励我们根据MaskIoU为每个检测假设学习校准的mask分数。在不丧失通用性的情况下,我们研究了Mask R-CNN框架,并提出了Mask Scoring R-CNN(MS R-CNN),这是一种带有额外MaskIoU head模块的MaskIoU R-CNN,用于学习MaskIoU对齐的mask得分。图2(b)和图2(c)显示了我们框架的预测掩模分数。
Mask Scoring in Mask R-CNN
Mask Scoring R-CNN在概念上很简单:Mask RCNN带有MaskIoU head,它将实例特征和预测的Mask一起作为输入,并预测输入Mask和ground truthMask之间的IoU,如图3所示。我们将在以下部分介绍我们框架的细节。

Fig.3 mask scoring r-cnn的网络架构。输入图像被馈送到骨干网中,以通过RPN生成RoI,并通过RoIAlign生成RoI特征。R-cnn head和mask head是mask r-cnn的标准组件。为了预测MaskIoU,我们使用预测的掩码和RoI特征作为输入。MaskIoU head有4个卷积层 (所有层都有内核大小 = 3,最后一层使用stride = 2进行下采样) 和3个完全连接的层 (最后一层输出C类掩码IoU。)
Mask R-CNN: 我们首先回顾一下mask r-cnn [15]。继faster r-cnn [33] 之后,Mask r-cnn由两个阶段组成。第一阶段是区域提取网络 (RPN)。它提出了候选对象边界框,而与对象类别无关。第二阶段称为r-cnn阶段,该阶段使用RoIAlign为每个区域提取特征,并执行区域分类,边界框回归和掩码预测。
Mask scoring: 我们将 Smask 定义为预测掩码的分数。理想的Smask等于预测的mask与其匹配的ground truth mask之间的像素级IoU,之前称为MaskIoU。理想的 Smask 也应该只对 ground truth 类别具有正值,而对其他类为零,因为一个 mask 只属于一个类。这需要掩码分数在两个任务上都能很好地工作:将掩码分类到正确的类别,以及将区域的 MaskIoU 回归到前景对象类别。
仅使用单一目标函数很难训练这两项任务。为了简化,我们可以将mask score学习任务分解为mask 分类和IoU回归,表示为所有对象类别的Smask=Scls·Siou。Scls侧重于将区域归类为哪个类别,而Siou侧重于回归MaskIoU。
至于Scls,Scls的目标是对属于哪个类别的区域进行分类,这是在R-CNN阶段的分类任务中完成的。所以我们可以直接取相应的分类分数。回归Siou是本文的目标,这将在下一部分中讨论。
MaskIoU head: MaskIoU head旨在回归预测掩码与其ground truth掩码之间的 IoU。我们使用来自 RoIAlign 层的特征和预测掩码的串联作为 MaskIoU head的输入。连接时,我们使用内核大小为 2、步幅为 2 的max pooing 层,以使预测的掩码具有与 RoI 特征相同的空间大小。 我们只选择回归ground truth类的MaskIoU(为了测试,我们选择预测类),而不是所有类。我们的MaskIoU head由4个卷积层和3个完全连接的层组成。对于4个卷积层,我们遵循mask head,并为所有卷积层分别设置内核大小和滤波器数为3和256。对于 3 个全连接(FC)层,我们遵循 RCNN 头部,将前两个 FC 层的输出设置为 1024,将最终 FC 的输出设置为类数。
Training: 为了训练 MaskIoU head,我们使用 RPN 区域作为训练样本。训练样本要求proposal box与匹配的ground truth box之间的IoU大于0.5,这与Mask RCNN的Mask head的训练样本相同。==为了为每个训练样本生成回归目标,我们首先得到目标类的预测掩码,并使用 0.5 的阈值对预测掩码进行二值化(预测掩码难道不是本身就是二值的吗?为什么还要用阈值进行二值化,难道这个预测掩码是边界框,使用阈值判断这是前景类还是背景类?)。然后我们使用二进制掩码与其匹配的ground truth之间的MaskIoU作为MaskIoU目标。我们使用ℓ2损失对MaskIoU进行回归,损失权重设置为1(所以是说,输入的训练样本是RPN区域,回归目标是预测掩码和其对应的ground truth之间的MaskIoU)。提出的MaskIoU head集成到Mask R-CNN中,对整个网络进行端到端训练。
Interfence: 在推理过程中,我们只使用MaskIoU head来校准从r-cnn生成的分类分数。具体地,假设mask r-cnn的r-cnn阶段输出N个边界框,其中选择SoftNMS [2] 后的top-k (即k = 100) 评分框。然后将top-k个边界框输入mask head,生成多类掩模。这是标准的mask R-CNN的推理程序。我们也遵循这个程序,并提供top-k个target mask,以预测MaskIoU。将预测的MaskIoU与分类分数相乘,得到新的校准掩模分数作为最终掩模置信度。
Experiments
所有实验都是在COCO数据集[26]上进行的,共有80个对象类别。我们遵循COCO 2017的设置,使用115k图像训练分割进行训练,5k验证分割进行验证,20k测试开发分割进行测试。我们使用COCO评估指标AP(averaged over IoU thresholds)来报告结果,包括AP@0.5, AP@0.75和APs、APm、APL(不同标度的AP)。AP@0.5(或AP@0.75)表示使用IoU阈值0.5(或0.75)来确定预测的边界框或mask在评估中是否为正。除非另有说明,否则AP使用掩码IoU进行评估。
Implementation details
我们使用复制的mask r-cnn进行所有实验。我们使用基于ResNet-18的FPN网络进行消融研究,并使用基于faster RCNN/FPN/DCN FPN的ResNet-18/50/101 [9] 将我们的方法与其他基线结果进行比较。对于ResNet-18 FPN,将输入图像的大小调整为沿短轴具有600px,沿长轴具有最大1000px,以进行训练和测试(短轴和长轴?)。与标准FPN [25] 不同,我们仅将C4,C5用于ResNet-18中的RPN提取和特征提取器。
对于 ResNet-50/101,输入图像的短轴调整为 800 像素,长轴调整为 1333 像素以进行训练和测试。 ResNet-50/101 的其余配置遵循 Detectron [13]。我们对所有网络进行了 18 个 epoch 的训练,在 14 个 epoch 和 17 个 epoch 之后将学习率降低了 0.1 倍。使用动量为 0.9 的同步 SGD 作为优化器。对于测试,我们使用 SoftNMS 并保留检测分数位top-100的每张图像。
Quantitative Results
我们在不同的主干网络(包括ResNet-18/50/101)和不同的框架(包括faster R-CNN/FPN/DCN+FPN[9])上报告了我们的结果,以证明我们方法的有效性。结果如表1和表2所示。我们使用APm报告实例分割结果,使用APb报告检测结果。我们报告了我们的R-CNN结果和MS R-CNN结果。如表1所示,与mask r-cnn相比,我们的MS r-cnn对骨干网不敏感,可以在所有骨干网上实现稳定的改进: 我们的MS r-cnn可以得到显著的改进 (约1.5 AP)。特别是对于AP@0.75,我们的方法可以将基线提高约2点。表2表明,我们的MS r-cnn对不同的框架 (包括faster RCNN/FPN/DCN FPN) 具有鲁棒性。此外,我们的MS r-cnn不会损害bounding box检测性能; 实际上,它稍微提高了bounding box检测性能。test-dev的结果在表3中报告,仅报告实例分割结果。
Ablation Study
我们在 COCO 2017 验证集上全面评估我们的方法,并使用 ResNet-18 FPN 进行所有消融研究实验。
Design choices of the input of MaskIoU head: 我们首先研究MaskIoU head输入的设计选择,这是根据mask head和RoI特征预测的mask得分图 (28×28 × c) 的融合。图4中显示了一些设计选择,并解释如下:
(a) 目标掩码连接RoI特征: 取目标类的分数图,最大池化,并与RoI特征连接。
(b) 目标掩码乘以 RoI 特征:获取目标类的分数图,最大池化并与 RoI 特征相乘。
© 所有掩码连接 RoI 特征:所有 C 类掩码分数图都进行最大池化,并与 RoI 特征连接。
(d) 目标掩码串接高分辨率RoI特征: 取目标类的分数图,串接28 × 28 RoI特征。
(e) 仅目标掩码:选择目标类的分数映射并将其合并。
(f) 仅ROI特征:仅使用ROI特征。
结果如表 4 所示。我们可以看到 MaskIoU head的性能对于融合掩码预测和 RoI 特征的不同方式具有鲁棒性。在各种设计中都可以观察到 Mask R-CNN 的性能提升。由于连接目标得分图和 RoI 特征可以获得最佳结果,因此我们将其用作我们的默认选择。

Fig.4 MaskIoU head 输入的不同设计选择。
Table1. COCO 2017 验证结果。我们报告检测和实例分割结果。 APm 表示实例分割结果,APb 表示检测结果。没有√的结果是 Mask R-CNN 的结果,而有 √ 的是我们的 MS R-CNN 的结果。结果表明,我们的方法对不同的骨干网络不敏感。
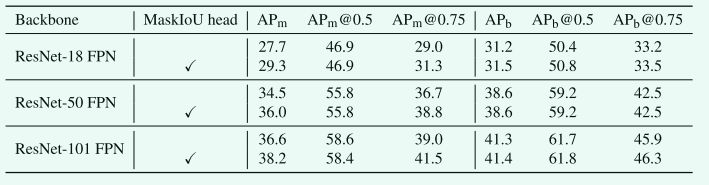
Table2. COCO 2017验证结果。我们报告检测和实例分割结果。APm表示实例分割结果,APb表示检测结果。在结果区域中,第1行和第2行使用faster r-cnn框架; 第3行和第4行另外使用FPN框架; 第5行和第6行另外使用DCN FPN。结果表明,提出的MaskIoU头得到了一致的改进。
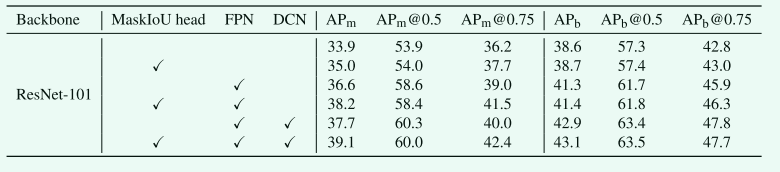
Table3. COCO 2017 test-dev上不同实例分割方法的比较

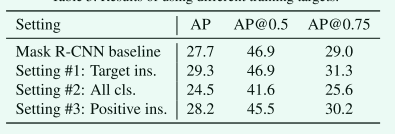
Design choices of the training target: 如前所述,我们将mask score学习任务分解为mask分类和MaskIoU回归。可以直接学习mask score吗?此外,RoI可能包含多个类别的对象。我们应该为所有类别学习MaskIoU吗?如何为MaskIoU设定训练目标仍需探索。训练目标有很多不同的选择:
- 学习目标类别的MaskIoU,同时忽略proposal中的其他类别。这也是本文的默认训练目标和本部分所有实验的对照组。
- 学习所有类别的 MaskIoU。如果某个类别没有出现在 RoI 中,则其目标 MaskIoU 设置为 0。此设置表示仅使用回归来预测 MaskIoU,这需要回归器意识到不存在不相关的类别。
- 学习所有正类别的MaskIoU,其中正类别表示该类别出现在RoI区域。区域中的其余类别被忽略。此设置用于查看是否对 RoI 区域中的更多类别执行回归可能会更好。
表5展示了上述训练目标的结果。通过比较setting #1 和setting #2,我们可以发现训练所有类别的 MaskIoU(仅基于回归的 MaskIoU 预测)会大大降低性能,这验证了我们的观点,即使用单个目标函数训练分类和回归是困难的。
setting #3 的性能不如setting #1 是合理的,因为对所有正类别回归 MaskIoU 会增加 MaskIoU head的负担。 因此,学习目标类别的 MaskIoU 作为我们的默认选择。
Table4. 用于输入MaskIoU head 的不同设计选择的结果。
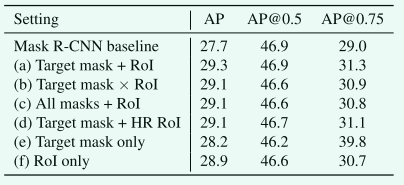
Table5. 使用不同训练目标的结果。
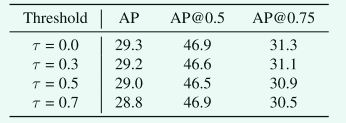
How to select training samples: 由于所提出的 MaskIoU head是建立在 Mask R-CNN 框架之上的,因此根据 Mask R-CNN 中的设置,MaskIoU head的所有训练样本的框级 IoU和ground truth边界框比 都大于 0.5。 但是,它们的 MaskIoU 可能不会超过 0.5。
给定阈值 τ,我们使用 MaskIoU 大于 τ 的样本来训练 MaskIoU head。表 6 显示了结果。结果表明,使用所有示例进行训练获得了最佳性能。
Table6. Mask IoU head 选择不同训练样本的结果
Discussion
在本节中,我们将首先讨论预测的MaskIoU的质量,然后研究Mask Scoring r-cnn的上限性能,如果MaskIoU的预测是完美的,最后分析MaskIoU头的计算复杂性。在讨论中,使用弱骨干网 (即ResNet-18 FPN) 和强骨干网 (即ResNet-101 DCN FPN) 在COCO 2017验证集上获得了所有结果。
The quality of the predicted MaskIoU: ==我们使用ground truth和预测的MaskIoU之间的相关系数来衡量我们预测的质量。回顾我们的测试过程,我们根据分类分数选择SoftMS后的前100个评分框,将检测到的框输入mask head,得到预测的掩模,然后使用预测的掩模和RoI特征作为MaskIoU head的输入。MaskIoU head和分类分数的输出进一步整合到最终的mask分数中。
我们为COCO 2017验证数据集中的每个图像保留前100ge预测的MaskIoU,从所有5,000个图像中收集500,000个预测。我们在图5中绘制了每个预测及其相应的ground truth。我们可以看到,MaskIoU预测与其ground truth具有良好的相关性,尤其是对于那些具有较高MaskIoU的预测。对于 ResNet-18 FPN 和 ResNet-101 DCN+FPN 骨干网络,预测与其ground truth之间的相关系数约为 0.74。 这表明预测的质量对骨干网络的变化不敏感。 这个结论也与表 1 一致。由于之前没有预测 MaskIoU 的方法,我们参考了之前关于预测边界框 IoU 的工作 [19]。 [19] 获得了 0.617 的相关系数,低于我们的。

Fig.5 MaskIoU 预测及其ground truth的可视化。 (a) ResNet-18 FPN 主干的结果和 (b) ResNet-101 DCN+FPN 主干的结果。 x 轴表示ground truth MaskIoU,y 轴表示提议的MaskIoU head的预测MaskIoU。
The upper bound performance of MS R-CNN: 这里我们将讨论我们的方法的上限性能。对于每个预测掩模,我们可以找到其匹配的ground truth掩模;然后,当ground truth MaskIoU大于0时,我们只使用ground truth MaskIoU来代替预测的MaskIoU。结果见表7。结果表明,mask scoring R-CNN优于 mask R-CNN。与mask scoring R-CNN的理想预测相比,mask scoring R-CNN仍有改进空间, ResNet - 101主干网为2.2% AP, ResNet - 101 DCN+FPN主干网为2.6% AP。
FLOPs and running time:
我们的 MaskIoU head大约有 0.39G FLOPs,而 Mask head对于每个区域大约有 0.53G FLOPs。 我们使用一个 TITAN V GPU 来测试速度(秒/图像)。 至于 ResNet-18 FPN,Mask R-CNN 和 MS R-CNN 的速度都在 0.132 左右。 至于 ResNet-101 DCN+FPN,Mask R-CNN 和 MS R-CNN 的速度都在 0.202 左右。 Mask Scoring R-CNN中MaskIoU head的计算成本可以忽略不计。
Conclusion
在本文中,我们研究了对实例分割掩码进行评分的问题,并提出了mask scoring RCNN。 通过在 Mask R-CNN 中添加 MaskIoU head,掩码的分数与 MaskIoU 对齐,这在大多数实例分割框架中通常被忽略。 提出的 MaskIoU head非常有效且易于实现。 在 COCO 基准测试中,大量结果表明 Mask Scoring R-CNN 始终且明显优于 Mask R-CNN。 它也可以应用于其他实例分割网络以获得更可靠的掩码分数。 我们希望我们简单有效的方法将作为基准,并有助于未来的实例分割任务研究。















 2870
2870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









