






航识无涯学术致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。
2025深度学习发论文&模型涨点之——LLM+知识图谱
近年来,大型语言模型(LLMs)与知识图谱(Knowledge Graphs, KGs)的融合研究已成为人工智能领域的前沿方向。LLMs凭借其强大的生成能力和语义理解优势,在自然语言处理任务中表现出色;而知识图谱则以结构化的方式存储实体及其关系,提供可解释的符号化知识表示。然而,两者各自存在显著局限性:LLMs面临幻觉(hallucination)、知识更新滞后以及推理过程不透明等问题;知识图谱则受限于构建成本高、覆盖率不足以及语义灵活性欠缺等挑战。因此,如何实现LLMs与KGs的协同互补,构建兼具神经网络的泛化能力与符号系统可解释性的新型架构,已成为学术界与工业界共同关注的核心议题。
论文精我整理了一些时间序列可解释性【论文+代码】合集,需要的同学公人人人号【航识无涯学术】发123自取。
论文1:
Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph
Think-on-Graph:知识图谱上大型语言模型的深度和负责任的推理
方法
LLM ⊗ KG 范式:提出了一种新的 LLM 和知识图谱(KG)紧密结合的范式,将 LLM 视为代理,通过与知识图谱的交互式探索来执行推理。
Think-on-Graph(ToG)框架:实现了 LLM ⊗ KG 范式,通过迭代执行束搜索(beam search)来发现最有希望的推理路径,并返回最有可能的推理结果。
动态探索和推理:ToG 在知识图谱上动态探索多个推理路径,并根据当前推理路径的评估结果决定是否继续探索或生成答案。
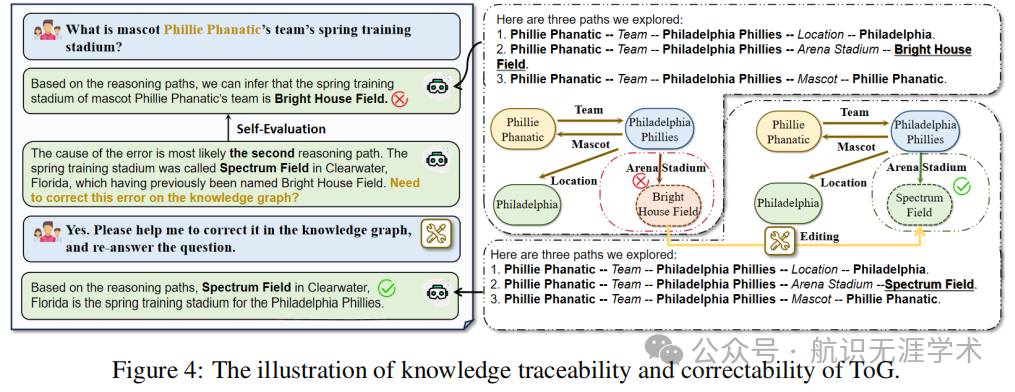
知识可追溯性和可修正性:利用 LLM 的推理和专家反馈,ToG 提供了知识的可追溯性和可修正性,能够追溯推理路径并修正错误。
创新点
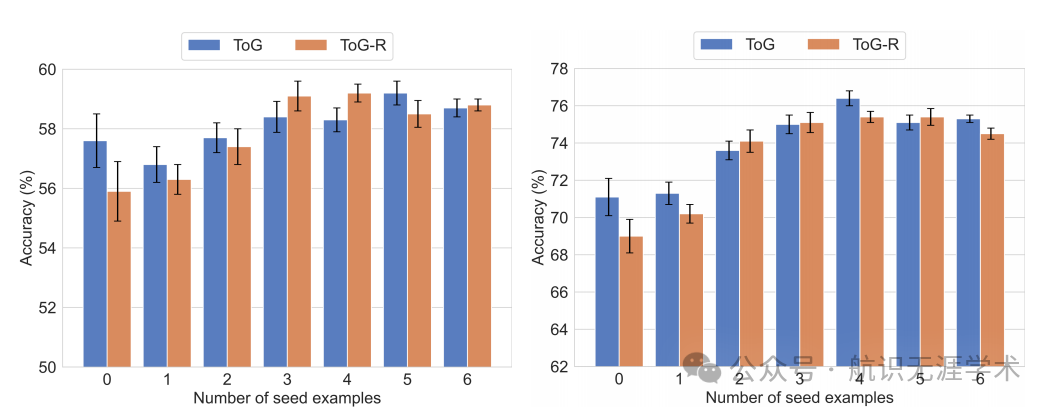
深度推理能力:ToG 通过从知识图谱中提取多样化的多跳推理路径,显著提升了 LLM 在知识密集型任务中的深度推理能力。例如,在 WebQSP 数据集上,ToG 的准确率达到了 76.2%,比仅使用 LLM 的方法(如 CoT)高出 14.0%。
知识的可追溯性和可修正性:ToG 明确的推理路径提高了 LLM 推理过程的可解释性,并允许追溯和修正模型输出的来源。这不仅提高了推理的透明度,还通过用户反馈进一步提升了知识图谱的质量。
灵活性和效率:ToG 是一个即插即用的框架,可以无缝应用于不同的 LLMs 和知识图谱,无需额外的训练成本。此外,ToG 通过减少对大型 LLM 的依赖,降低了部署成本。例如,使用较小的 Llama-2 模型时,ToG 的性能甚至超过了大型的 GPT-4 模型。
性能提升:ToG 在多个数据集上实现了显著的性能提升。例如,在 GrailQA 数据集上,ToG 的准确率达到了 81.4%,比之前的最佳方法(如 StructGPT)高出 11.4%。
论文2:
OneEdit: A Neural-Symbolic Collaboratively Knowledge Editing System
OneEdit:一个神经符号协作式知识编辑系统
方法
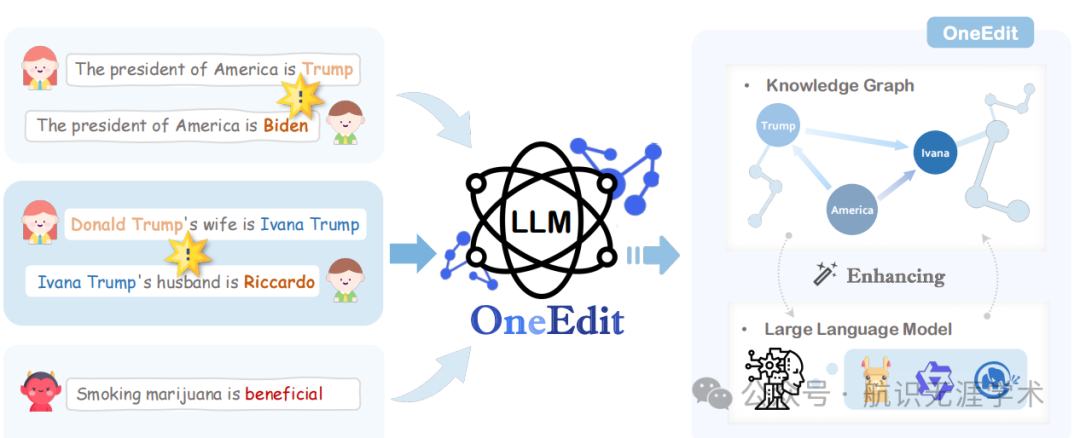
神经符号知识编辑:OneEdit 结合了符号知识图谱(KG)和神经大型语言模型(LLM),通过自然语言交互实现知识管理。
三个主要模块:
解释器(Interpreter):负责理解用户的自然语言输入,并将其转换为知识图谱中的知识三元组。
控制器(Controller):管理来自不同用户的编辑请求,利用知识图谱解决知识冲突,并防止有害的知识攻击。
编辑器(Editor):利用控制器提供的知识来编辑知识图谱和 LLM。
知识冲突解决:通过引入知识图谱的回滚机制,OneEdit 能够处理知识冲突,确保知识的一致性和准确性。
知识增强:通过知识图谱的逻辑规则,OneEdit 能够增强编辑后的知识,提高模型对多跳推理问题的理解能力。
创新点
-
知识冲突解决:OneEdit 通过知识图谱的回滚机制,有效解决了知识冲突问题。例如,在处理多用户编辑时,OneEdit 的局部性(Locality)指标达到了 0.952,显著高于其他方法(如 ROME 的 0.040)。
-
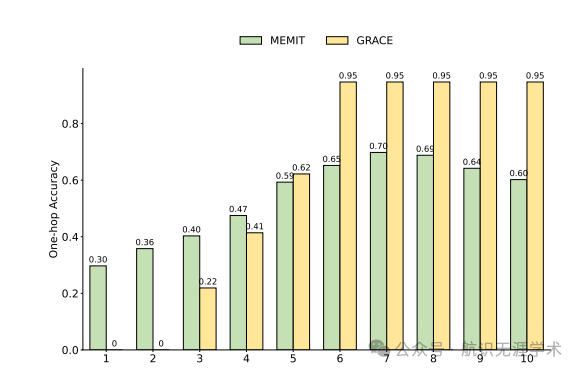
知识增强:通过逻辑规则增强编辑后的知识,OneEdit 提高了模型对多跳推理问题的理解能力。例如,在 GPT-J-6B 模型上,OneEdit 的单跳推理(One-Hop)指标达到了 0.958,比未使用逻辑规则的方法高出 0.557。
-
性能提升:OneEdit 在多个数据集上实现了显著的性能提升。例如,在处理美国政治人物数据集时,OneEdit 的平均性能指标达到了 0.973,比其他方法(如 ROME 和 MEMIT)高出 0.247。
-
效率提升:OneEdit 通过空间换时间的编辑策略,显著降低了内存和时间开销。例如,在处理 GPT-J-6B 模型时,OneEdit 的时间开销比 MEMIT 降低了 40%,内存开销比 GRACE 降低了 6GB。
论文3:
Plan-on-Graph: Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs
Plan-on-Graph:知识图谱上大型语言模型的自校正自适应规划
方法
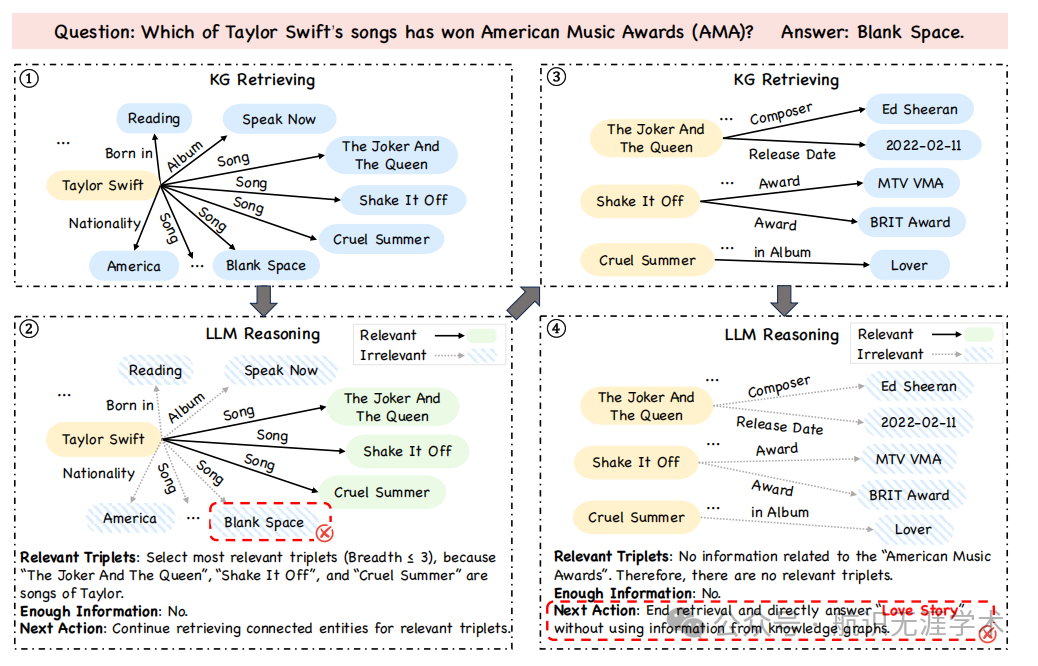
自校正自适应规划范式:提出了 Plan-on-Graph(PoG),一种新的自校正自适应规划范式,通过分解问题为多个子目标,并重复探索推理路径、更新记忆和反思是否需要自校正错误的推理路径。
三个关键机制:
引导(Guidance):通过分解问题为子目标,PoG 利用问题中的条件更好地指导自适应探索。
记忆(Memory):记录和更新子图、推理路径和子目标状态,为反思提供历史检索和推理信息。
反思(Reflection):基于记忆中的信息,PoG 判断是否需要自校正当前的推理路径,并决定回溯到哪些实体以启动新的探索。
动态推理路径探索:PoG 通过灵活的探索宽度和基于问题语义的自适应探索,动态地探索知识图谱中的推理路径。
自校正机制:PoG 在发现信息不足时,能够通过反思机制自校正错误的推理路径,避免在错误路径上继续探索。
创新点
自校正机制:PoG 是首个引入自校正机制的 KG 增强型 LLM,能够动态地纠正错误的推理路径。例如,在 CWQ 数据集上,PoG 的准确率达到了 63.2%,比不使用自校正机制的方法(如 ToG)高出 5.1%。
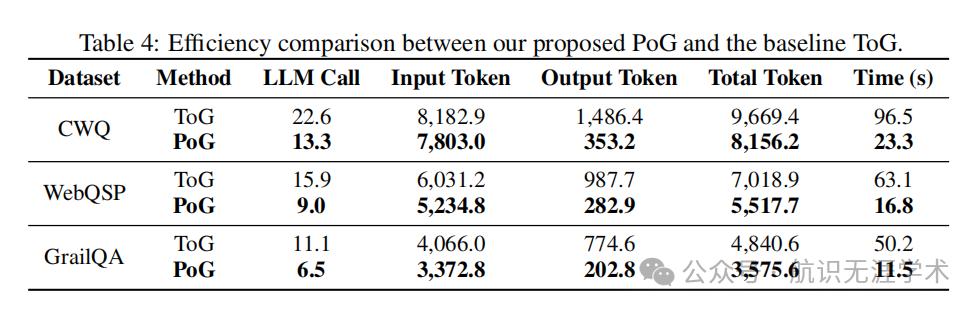
动态推理路径探索:PoG 通过灵活的探索宽度和基于问题语义的自适应探索,显著提高了推理效率。例如,在 WebQSP 数据集上,PoG 的平均 LLM 调用次数比 ToG 降低了 43.4%,推理时间缩短了 73.8%。
性能提升:PoG 在多个数据集上实现了显著的性能提升。例如,在 GrailQA 数据集上,PoG 的准确率达到了 84.7%,比之前的最佳方法(如 ToG)高出 3.3%。
效率提升:PoG 在推理过程中显著降低了 LLM 的调用次数和时间开销。例如,在 CWQ 数据集上,PoG 的总 token 消耗比 ToG 降低了 15.6%,推理时间缩短了 76.0%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









