






航识无涯学术致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。
2025深度学习发论文&模型涨点之——强化学习+多目标优化
近年来,强化学习(Reinforcement Learning, RL)在序列决策问题中展现出显著优势,但其传统范式通常围绕单一目标函数进行优化。然而,现实场景中的复杂系统(如机器人控制、资源调度、金融投资等)往往涉及多个相互冲突的目标(如效率、能耗、安全性等),需在帕累托最优性(Pareto Optimality)框架下进行权衡。多目标强化学习(Multi-Objective Reinforcement Learning, MORL)通过将多目标优化(Multi-Objective Optimization, MOO)的 Pareto 前沿理论引入 RL 的奖励函数设计或策略搜索过程,为解决此类问题提供了方法论基础。然而,MORL 仍面临目标空间维度灾难、稀疏奖励下的探索-利用平衡、以及动态偏好下的自适应策略生成等核心挑战
我整理了一些【论文+代码】合集,需要的同学公人人人号【航识无涯学术】发123自取。
论文精选
论文1:
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
SWEET-RL:在协作推理任务上训练多轮LLM代理
方法
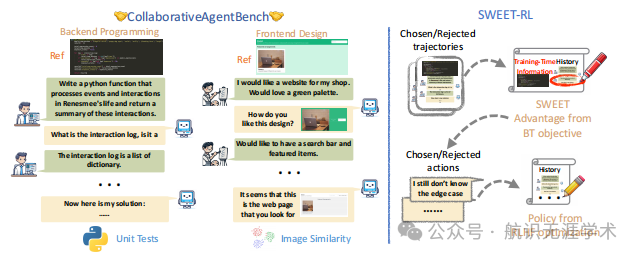
ColBench基准测试:提出了一个新的基准测试ColBench,用于评估多轮强化学习(RL)算法在真实世界任务中的表现。该基准测试专注于后端编程和前端设计领域,要求LLM代理与人类合作者进行多轮交互以完成任务。
SWEET-RL算法:提出了一种新的强化学习算法SWEET-RL,该算法通过利用训练时的额外信息(如参考解决方案)来优化LLM代理的行为策略。SWEET-RL通过训练一个批评者模型来提供每一步的奖励,从而改进策略模型。
多轮交互优化:SWEET-RL通过优化每一步的奖励信号,解决了多轮交互任务中信用分配的问题,使得代理能够更好地理解人类合作者的意图并生成符合期望的最终产品。
创新点
基准测试的多样性与实用性:ColBench提供了足够多样的任务,以支持无过拟合的RL训练,同时保持任务的复杂性,挑战代理的推理和泛化能力。该基准测试还通过使用LLM作为人类“模拟器”来减少工程开销,使得研究更加高效。
性能提升:SWEET-RL在ColBench上的表现比其他最先进的多轮RL算法提高了6%的绝对成功率和胜率,使得Llama-3.1-8B能够匹配甚至超过GPT-4o等专有模型的性能。
训练时信息的利用:SWEET-RL通过在训练过程中利用额外的训练时信息(如最终结果和参考解决方案),为代理提供了更有效的信用分配,从而提高了代理在多轮交互任务中的表现。
算法的泛化能力:SWEET-RL通过适当的优化目标和算法选择,使得LLM代理能够更好地泛化到未见过的任务,提高了代理在复杂任务中的适应性和鲁棒性。
论文2:
Training Diffusion Models with Reinforcement Learning
用强化学习训练扩散模型
方法
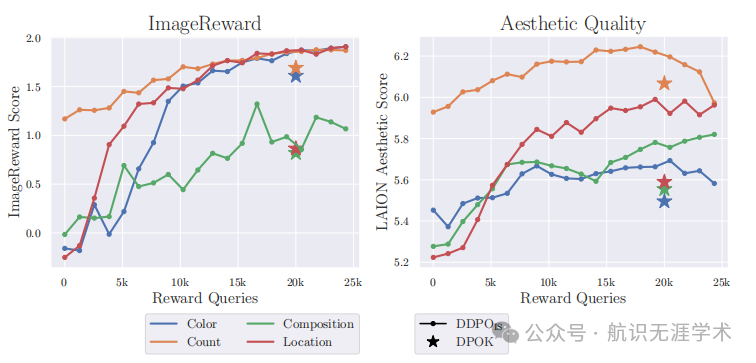
Denoising Diffusion Policy Optimization (DDPO):提出了一种新的强化学习算法DDPO,将去噪过程视为一个多步决策问题,从而可以直接优化扩散模型以适应下游目标,如图像压缩性和美学质量。
多步决策过程:通过将扩散模型的去噪步骤映射到马尔可夫决策过程(MDP),DDPO能够利用每一步的精确似然值来优化模型,而不是依赖于整个去噪过程的近似似然值。
奖励函数设计:设计了多种奖励函数,包括基于文件压缩性、美学质量以及视觉语言模型(VLM)反馈的奖励函数,以适应不同的下游任务。
创新点
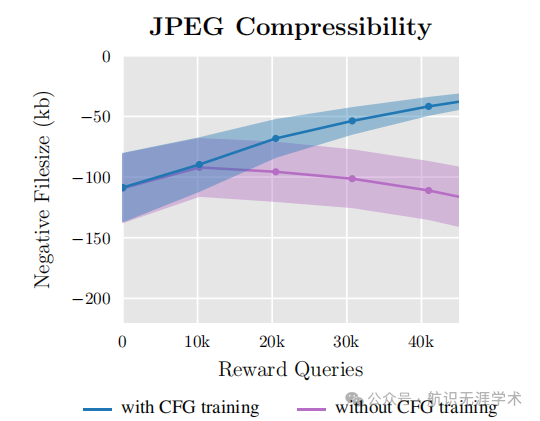
性能提升:DDPO在优化图像压缩性和美学质量等任务上表现出色,与传统的基于奖励加权似然的方法相比,DDPO在这些任务上取得了显著的性能提升。例如,在优化图像压缩性任务时,DDPO能够生成更易于压缩的图像,而在优化美学质量任务时,DDPO能够生成更具艺术感的图像。
奖励函数的多样性:DDPO能够适应多种复杂的奖励函数,包括那些难以通过传统方法编程实现的奖励函数,如基于人类反馈的美学质量评估和视觉语言模型提供的语义对齐奖励。
泛化能力:DDPO在有限的训练提示集上进行微调后,能够泛化到未见过的提示,这表明DDPO不仅能够优化特定任务,还能够学习到更通用的生成策略。
无需额外数据收集:DDPO通过利用现有的视觉语言模型反馈来优化扩散模型,避免了额外的人类标注工作,提高了模型适应新任务的效率。
论文3:
TRUST-PCL: AN OFF-POLICY TRUST REGION METHOD FOR CONTINUOUS CONTROL
TRUST-PCL:一种用于连续控制的离线信任区域方法
方法
Trust-PCL算法:提出了一种新的离线信任区域方法Trust-PCL,该方法通过在最大奖励目标中引入相对熵正则化,使得最优策略和状态值在任何路径上满足一组多步路径一致性。
相对熵正则化:Trust-PCL利用相对熵正则化来维持优化稳定性,同时利用离线数据来提高样本效率。
路径一致性学习(PCL):Trust-PCL扩展了PCL算法的思想,通过在目标中加入相对熵正则化,使得算法能够在标准的连续控制基准任务上取得更好的结果。
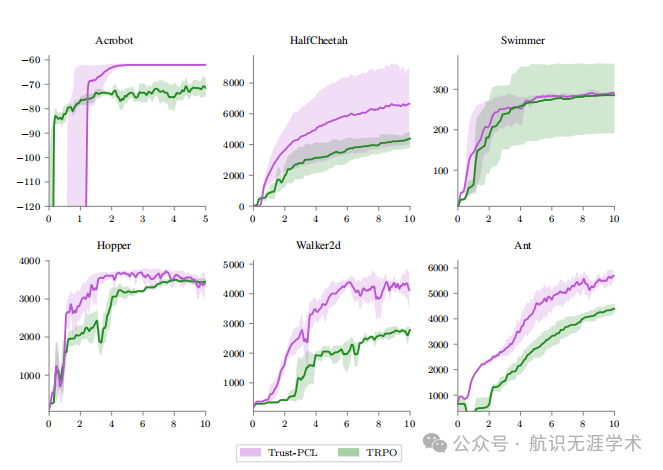
创新点
性能提升:Trust-PCL在多个连续控制任务上显著提高了TRPO的解决方案质量和样本效率。例如,在Walker2d和Ant等较难的任务上,Trust-PCL不仅能够匹配甚至超过TRPO的最终奖励,还在样本效率上表现出显著的优势。
离线学习能力:Trust-PCL能够利用离线数据进行训练,这使得它在样本效率上优于传统的信任区域方法,如TRPO,后者需要大量的在线交互。
自动调整正则化系数:Trust-PCL提出了一种方法,可以根据期望的最大相对熵差异自动调整正则化系数λ,从而减少了超参数调整的负担,并提高了算法的适应性。
算法的稳定性:Trust-PCL通过相对熵正则化和路径一致性约束,提高了算法的稳定性,使其能够在复杂的连续控制任务中更有效地优化策略。

















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









