






2025深度学习发论文&模型涨点之——KAN + Transformer
Transformer架构依赖多层感知器(MLP)层来混合通道信息,但MLP在参数效率和可解释性方面存在局限性。KAN基于Kolmogorov-Arnold表示定理,通过可学习的激活函数逼近复杂函数关系,展现出较高的准确性和可解释性。然而,原始KAN在扩展到大规模模型时面临挑战,包括基函数未针对现代硬件优化、参数和计算效率低下以及权重初始化困难等问题。
-
有理基础:用有理函数替换B样条函数,提高与GPU的兼容性。
-
Group KAN:通过神经元共享激活权重,减少计算负载。
- 方差保持初始化:确保跨层激活方差的稳定性。
小编整理了一些KAN + Transformer【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学扫码添加我
回复“KAN + Transformer”即可全部领取

论文精选
论文1:
KAN4TSF: Are KAN and KAN-based models Effective for Time Series Forecasting?
KAN4TSF:KAN及其基于KAN的模型是否适用于时间序列预测?
方法
-
Kolmogorov-Arnold Network (KAN):基于Kolmogorov-Arnold表示定理,通过有限的单变量连续函数组合来表示多变量连续函数,建立了网络大小与输入形状之间的关系。
Reversible Mixture of KAN Experts (RMoK):提出了一种基于KAN的混合专家模型,使用多个KAN变体作为专家,并通过门控网络自适应地将变量分配给特定的专家进行预测。
RevIN:使用可学习的仿射变换对输入时间序列进行归一化和反归一化,以提高模型的鲁棒性。
实验验证:在七个真实世界数据集上与多种基线模型进行性能、集成、速度和可解释性的比较。
创新点
-
性能提升:RMoK在多个时间序列预测任务中取得了最佳性能,平均性能优于现有方法。
模型集成:通过将KAN集成到Transformer架构中,进一步提升了模型性能,证明了KAN在时间序列预测中的适用性。
计算效率:KAN模型在保持高性能的同时,具有较低的计算复杂度,运行速度与线性模型相当。
可解释性:通过可视化时间特征权重与数据周期性的关系,初步解释了KAN在时间序列预测中的有效性。
论文2:
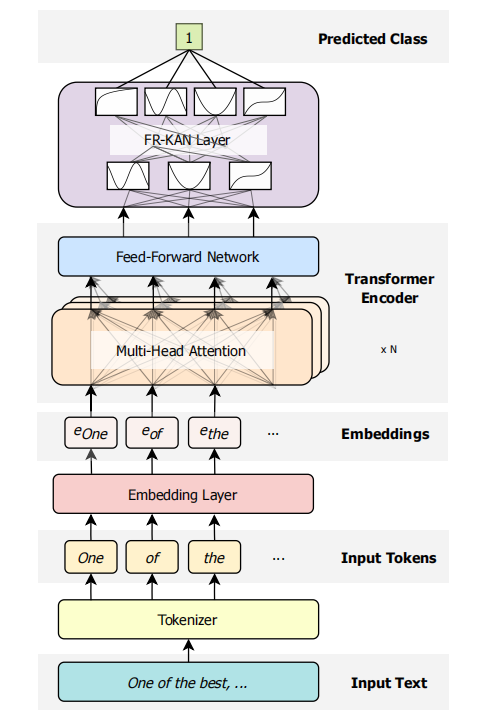
Leveraging FourierKAN Classification Head for Pre-Trained Transformer-based Text Classification
利用傅里叶KAN分类头提升预训练Transformer文本分类性能
方法
-
傅里叶KAN(FR-KAN):提出了一种基于傅里叶系数的KAN分类头,用于替代传统的多层感知机(MLP)分类头。
KAN架构:基于Kolmogorov-Arnold表示定理,通过非线性函数的组合来学习数据的复杂模式,避免了MLP中固定的非线性激活函数。
预训练Transformer:利用预训练的Transformer模型生成上下文嵌入,然后通过FR-KAN分类头进行分类。
实验验证:在四个文本分类任务和七个预训练Transformer模型上进行实验,验证FR-KAN的性能提升。
创新点
-
性能提升:FR-KAN分类头在多个文本分类任务中平均准确率提升了10%,F1分数提升了11%,显著优于传统MLP分类头。
参数效率:FR-KAN分类头在保持高性能的同时,所需的参数数量更少,训练速度更快。
模型适用性:证明了KAN架构在自然语言处理任务中的适用性,尤其是在资源受限的环境中表现更优。
论文3:
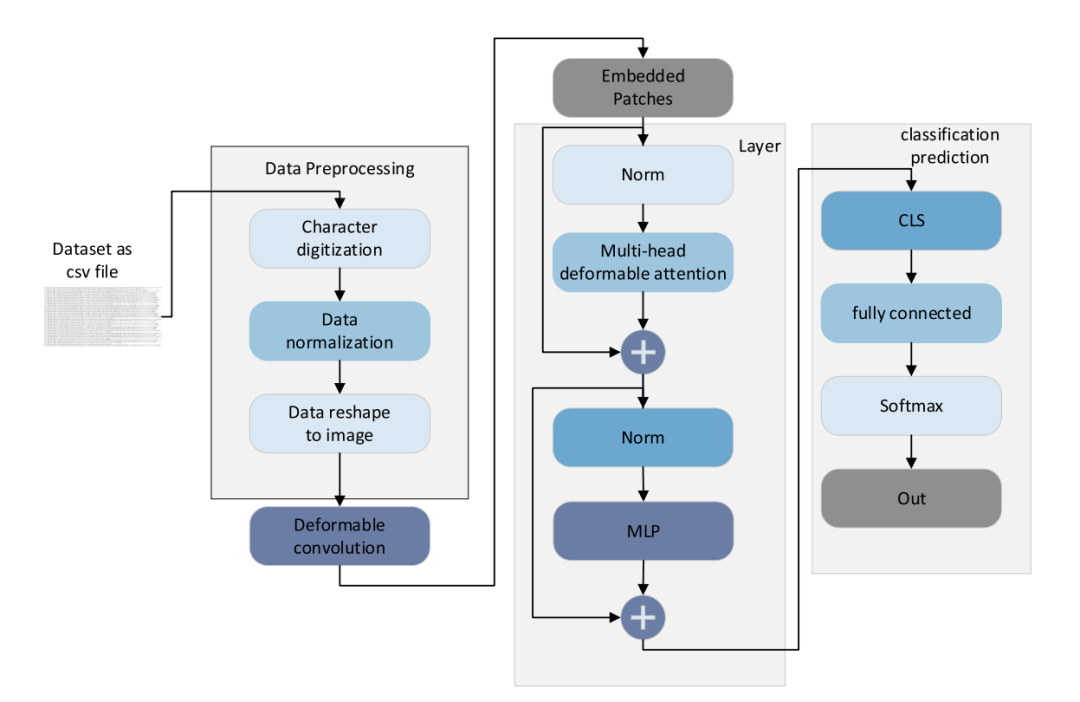
Network Intrusion Detection Based on Feature Image and Deformable Vision Transformer Classification
基于特征图像和可变形视觉Transformer的网络入侵检测
方法
-
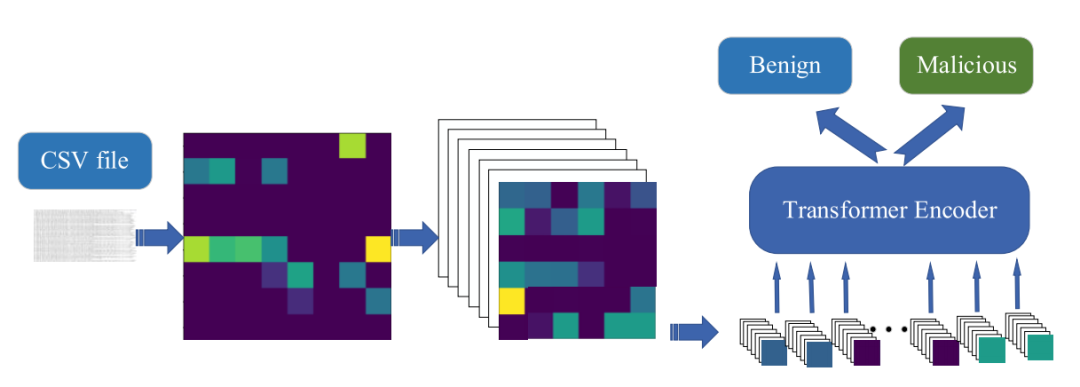
特征图像:将网络入侵检测数据转换为图像数据,通过图像分类算法进行入侵检测。
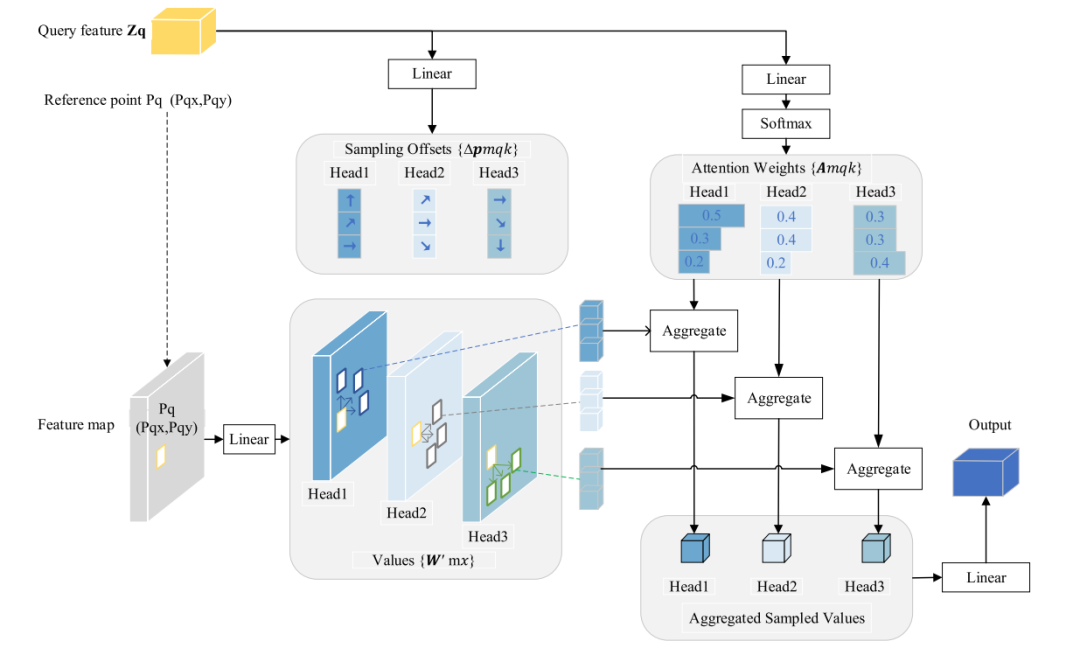
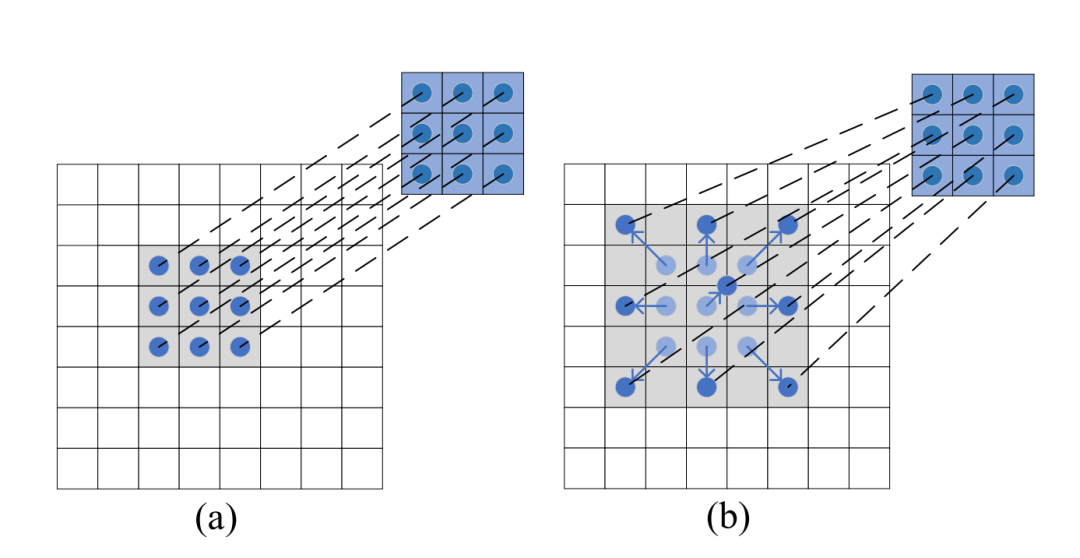
可变形注意力机制:引入可变形注意力机制,选择性地关注关键区域,减少计算成本和内存消耗。
可变形卷积:使用可变形卷积代替普通卷积,扩大每个补丁的感受野,增强模型对全局信息的感知能力。
分层焦点损失函数:提出分层焦点损失函数(L-Focal loss),解决数据不平衡问题,提高分类性能。
创新点
-
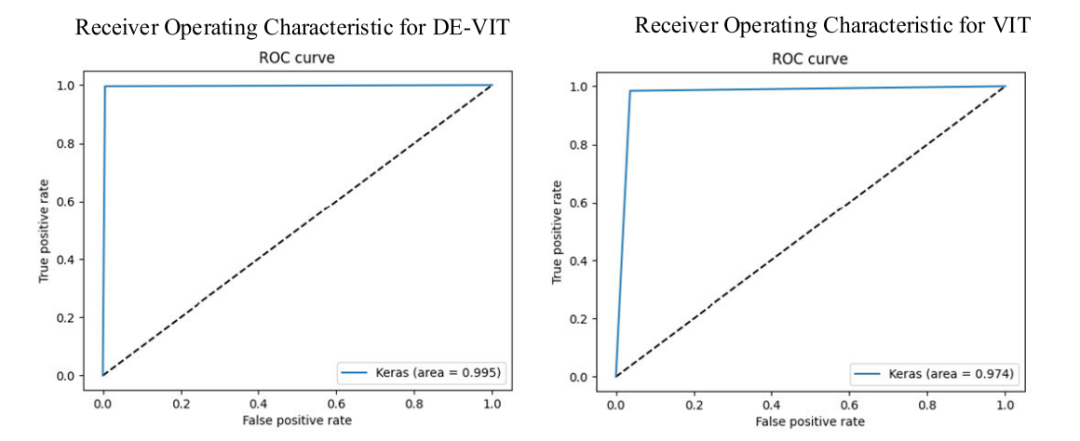
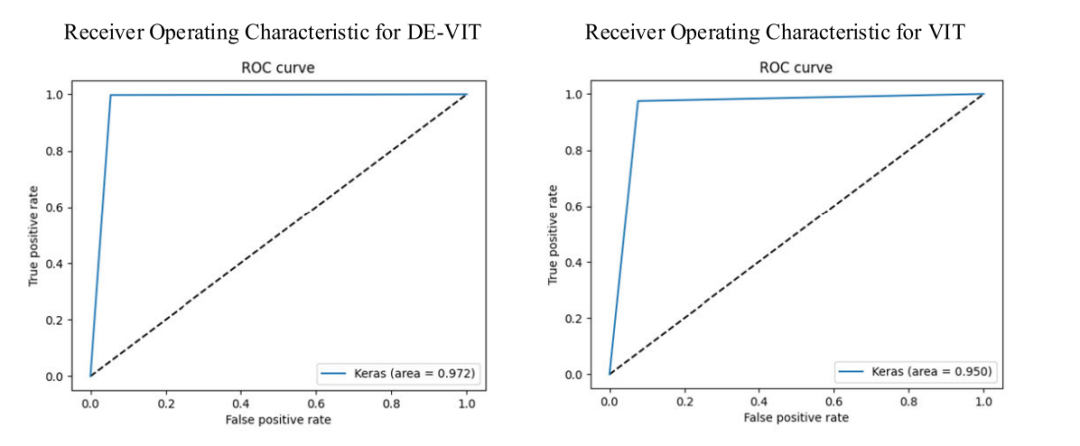
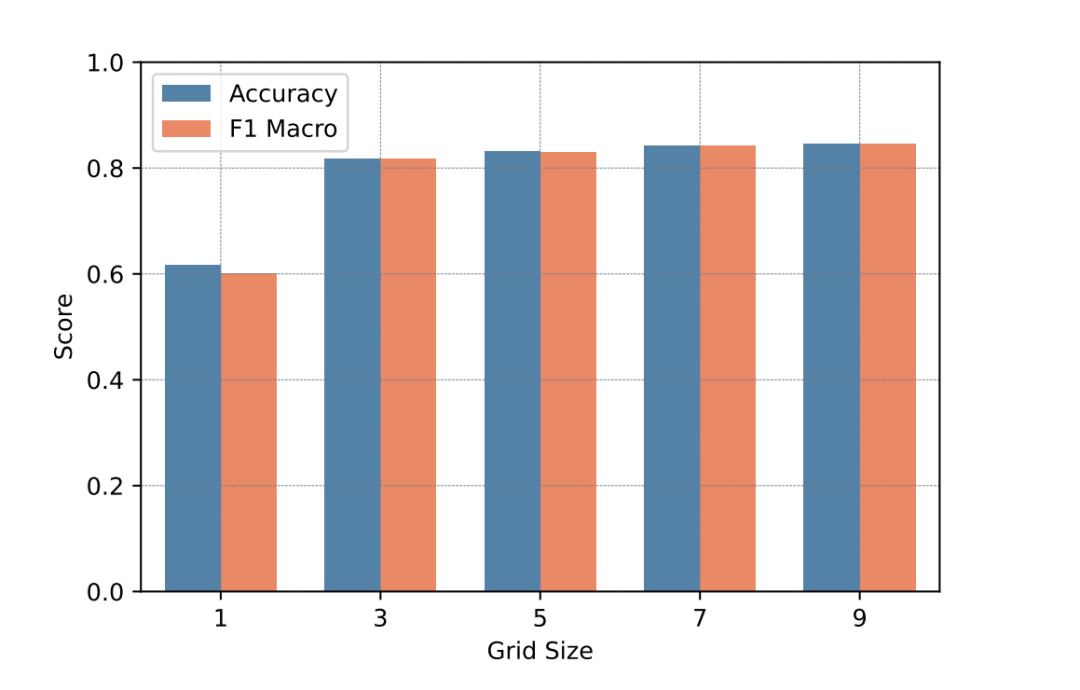
性能提升:在CIC IDS2017数据集上准确率达到99.5%,UNSW-NB15数据集上准确率达到97.25%,显著高于其他主流算法。
特征提取优化:通过可变形卷积和可变形注意力机制,模型能够更有效地提取特征,关注相关区域,减少计算成本。
数据不平衡处理:分层焦点损失函数有效解决了数据不平衡问题,提高了模型对少数类别的分类能力。
论文4:
Emerging Trends in Autonomous Vehicle Perception: Multimodal Fusion for 3D Object Detection
自动驾驶车辆感知的新兴趋势:多模态融合用于3D目标检测
方法
-
U-KAN架构:将Kolmogorov-Arnold Networks(KAN)集成到U-Net架构中,通过分层的KAN层增强模型的非线性建模能力和可解释性。
分层KAN块:在U-Net的瓶颈附近引入分层的KAN块,将中间特征投影到标记空间,并应用KAN操作提取信息模式。
扩散模型扩展:将U-KAN扩展到扩散模型中,作为噪声预测器,验证其在生成任务中的潜力。
实验验证:在多个医学图像分割和生成任务中验证U-KAN的性能,与现有方法进行比较。
创新点
-
性能提升:在医学图像分割任务中,U-KAN在多个数据集上取得了最高的IoU和F1分数,平均性能优于现有方法。
效率提升:U-KAN在保持高性能的同时,具有较低的计算复杂度(Gflops)和参数数量,与现有方法相比具有显著优势。
可解释性增强:KAN层的引入提高了模型的可解释性,能够更准确地激活与目标区域相关的特征,提升模型的决策透明度。
生成任务潜力:在扩散模型中,U-KAN作为噪声预测器表现出色,生成的图像在FID和IS指标上优于现有方法,证明了其在生成任务中的潜力。
小编整理了KAN + Transformer论文代码合集
需要的同学扫码添加我
回复“ KAN + Transformer”即可全部领取


















 1487
1487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









