







引言
在概率论及统计学中,马尔可夫过程(英语:Markov process)是一个具备了马尔可夫性质的随机过程,因为俄国数学家安德雷·马尔可夫得名。马尔可夫过程是不具备记忆特质的(memorylessness)。换言之,马尔可夫过程的条件概率仅仅与系统的当前状态相关,而与它的过去历史或未来状态,都是独立、不相关的。

概论

马尔可夫模型分成四种:马尔可夫链、隐马尔可夫模型(HMM)、马尔可夫决策过程(MDP)和部分可观测马尔可夫决策过程(POMDP)
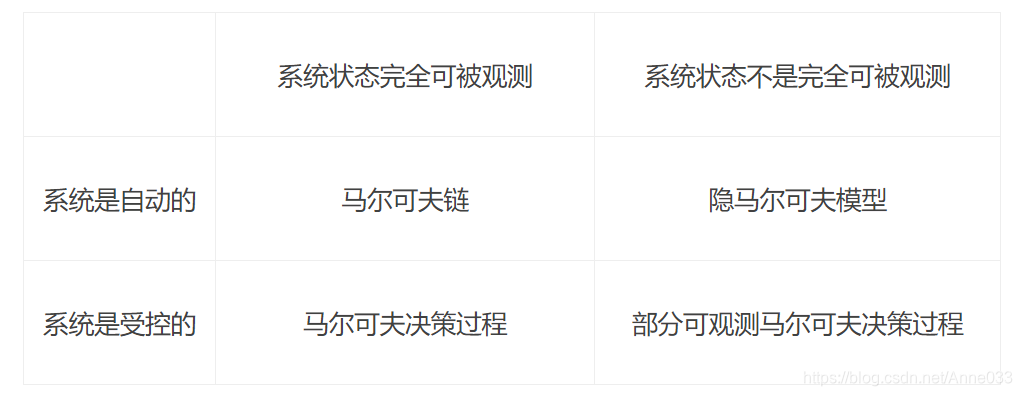
最简单的马尔可夫模型是马尔可夫链。它用一个随时间变化的随机变量来模拟系统的状态。在这种情况下,马尔可夫性质表明,这个变量的分布只取决于之前状态的分布。当马尔可夫链的状态只能部分观察到,这就是隐马尔可夫模型。隐马尔可夫模型常用的用途是语音识别,它是大多数现代自动语音识别系统的基础。
马尔可夫决策过程也是马尔可夫链,但其状态转换取决于当前状态和应用于系统的动作向量。通常,使用马尔可夫决策过程来计算行动策略,该行为策略将最大限度地提高与预期奖励相关的某种效用。它与强化学习密切相关,可以用价值迭代法和相关方法解决。
部分可观测马尔可夫决策过程是一个系统的状态只被部分观察到的马尔可夫决策过程,其中系统的状态只被部分观察到。部分可观测马尔可夫决策过程可以用于控制简单代理或机器人。
马尔可夫模型还包括马尔可夫随机场(MRF)和马尔可夫链蒙特卡洛(MCMC)——这两个模型也常常被用于近似和预测—— Tolerant Markov model (TMM)、层级马尔科夫模型(Hierarchical Markov models)、层级隐马尔可夫模型(hierarchicalhiddenMarkov model)等。
参考
解释下马尔科夫链
马尔可夫链(Markov Chain)是指具有马尔可夫性质的随机过程,它具有无记忆性的特征。在马尔可夫链中,未来的状态只依赖于当前状态,而不依赖于过去的状态。这个特性称为马尔可夫性质。
具体来说,一个马尔可夫链由一组状态以及状态之间的转移概率构成。每个状态之间存在转移概率,表示从一个状态转移到另一个状态的概率。这些转移概率可以用转移矩阵(transition matrix)来表示。

马尔可夫链的基本性质包括:
- 马尔可夫性质:未来状态的概率分布只依赖于当前状态,与过去状态无关。
-平稳分布:如果马尔可夫链具有平稳分布,则在足够长的时间后,状态的分布会趋于该平稳分布。
-细致平衡条件:在平稳分布下,任意两个状态之间的转移概率与其逆转移概率之积相等。
-长期行为:随着时间的推移,马尔可夫链会向其平稳分布收敛。
马尔可夫链在许多领域都有广泛的应用,包括概率论、统计学、计算机科学、生物学等。它们被用来建模具有随机性质的系统,并用于分析这些系统的行为、性质和长期趋势。
解释下Markov modulated process
马尔可夫调制过程(Markov Modulated Process,MMP)是一种随机过程,它在不同的离散状态下具有不同的随机性质,这些状态之间的转移服从马尔可夫性质。
具体来说,马尔可夫调制过程可以描述为在马尔可夫链的每个状态下,存在一个独立的随机过程。在任何给定时间点,马尔可夫调制过程的状态由其所处的马尔可夫链的状态决定,而每个状态下的随机过程的行为独立于之前的状态或过程。
一个简单的例子是一个通信系统中的调制过程。在这种情况下,马尔可夫链的状态可以表示通信信道的不同条件,例如良好、中等和恶劣。每个状态下有一个不同的随机过程,例如高斯噪声的强度可能与信道的状态相关。在这种情况下,马尔可夫调制过程可以用来建模通信系统中信道条件的变化,并且可以用来分析和优化通信系统的性能。
总的来说,马尔可夫调制过程提供了一种灵活的方法来描述具有随机性质的系统,其中系统的状态以马尔可夫链的形式演变,而每个状态下的随机过程独立地影响系统的行为。
解释下Markov Modulated chain
Markov Modulated Chain(MMC)是一种结合了马尔可夫链和调制过程的随机过程。在Markov Modulated Chain中,系统的状态不仅受到内在的马尔可夫链的影响,还受到外部调制过程的影响。
具体来说,Markov Modulated Chain描述了一个状态空间由两部分组成的随机过程。一部分是马尔可夫链,它描述了系统内部状态的演变,具有马尔可夫性质,即未来状态仅依赖于当前状态。另一部分是调制过程,它决定了系统处于哪个马尔可夫链状态时的行为特性。这个调制过程可以是另一个马尔可夫链、连续时间过程或其他随机过程。

Markov Modulated Chain通常用于描述具有多个模式或行为特性的系统,其中每个模式下系统的行为可能不同。典型的应用包括通信系统中的信道建模、网络系统中的传输控制、能源系统中的电力供应管理等。
总的来说,Markov Modulated Chain提供了一种灵活的建模方法,能够同时考虑内部状态和外部调制过程,以便更准确地描述具有复杂行为的随机系统。
一、马尔科夫决策过程
机器学习算法(有监督,无监督,弱监督)中,马尔科夫决策过程是弱监督中的一类叫增强学习。增加学习与传统的有监督和无监督不同的地方是,这些方法都是一次性决定最终结果的,而无法刻画一个决策过程,无法直接定义每一次决策的优劣,也就是说每一次的决策信息都是弱信息,所以某种程度上讲,强化学习也属于弱监督学习。从模型角度来看,也属于马尔科夫模型,其与隐马尔科夫模型有非常强的可比性。
下面是一个常用的马尔科夫模型的划分关系

1.1 马尔科夫决策过程定义


马尔可夫决策过程并不要求
S
S
S 或者
A
A
A 是有限的,但基础的算法中假设它们由有限的
状态(state): 智能体在每个步骤中所处于的状态集合
行为(action): 智能体在每个步骤中所能执行的动作集合
转移概率(transition): 智能体处于状态s下,执行动作a后,会转移到状态s’的概率
奖励(reward): 智能体处于状态s下,执行动作a后,转移到状态s’后获得的立即奖励值
策略(policy): 智能体处于状态s下,应该执行动作a的概率
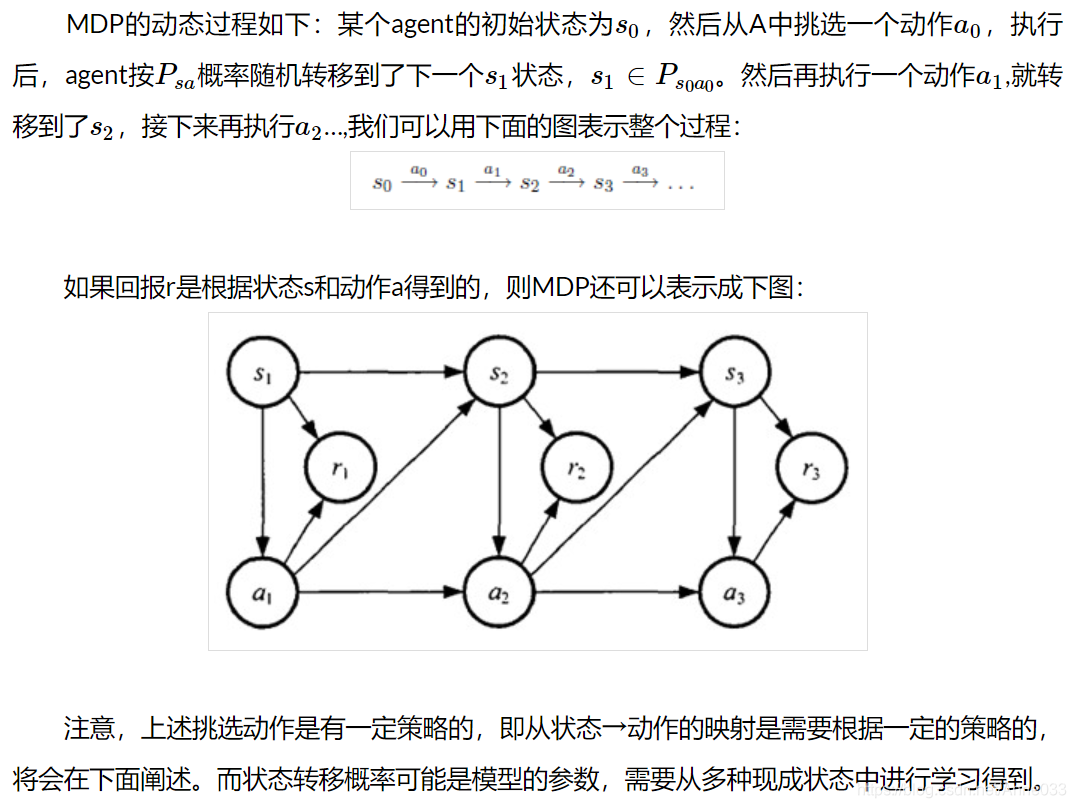
MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。举下棋的例子,当我们在某个局面(状态s)走了一步(动作a),这时对手的选择(导致下个状态s’)我们是不能确定的,但是他的选择只和s和a有关,而不用考虑更早之前的状态和动作,即s’是根据s和a随机生成的。

值得注意的是,在马尔科夫决策过程中,状态集合是离散的,动作集合是离散的,转移概率是已知的,奖励是已知的。在这个条件下的学习称之为有模型学习。
1.1.1 MDP的动态过程

1.1.2 策略 π \pi π

a policy
π
\pi
π is a distribution over actionsgiven states
π
(
a
∣
s
)
=
P
[
A
t
=
a
∣
S
t
=
s
]
\pi(a|s)=P[A_t = a | S_t =s]
π(a∣s)=P[At=a∣St=s]
A policy fully defines the behaviour of an agent
1.1.3 值函数




1.1.4 马尔科夫过程的描述

我们分三种情况来讨论:
- T=1, greedy case. 这时算法是退化的,拿我们的例子而言,机器人只会考虑下一步动作带来的影响,而不会考虑之后一系列动作带来的影响。但是这个算法却在实际应用中起着重要作用,是很多机器人问题的最优解。因为它计算起来非常简单。它的缺点也很明显,容易陷入局部最优。很明显,此时 γ 的取值不影响结果,只要满足 γ>1 即可。
- 1<T<∞, finite−horizon case. 此时,一般会取 γ=1. 意思是说每个状态转换的收益权重是一样的。有人会说这种 finite-horizon 的处理方式是最符合实际情况的。但事实上,这种 finite-horizon的情况处理起来比下边提到的infinite-horizon更加复杂。因为我们要求的动作序列是时间的函数。也就是说,即便是从相同的状态开始计算,由于时间参数 T 不同,最后得到的最优动作序列会不同。课本里的原话是, Near the far end of the time horizon, for example, the optimal policy might differ substantially from the optimal choice earlier in time, even under otherwise identical conditions (e.g., same state, same belief). As a result, planning algorithms with finite horizon are forced to maintain different plans for different horizons, which can add undesired complexity.
- T=∞, infinite−horizon case. 这种情况不会有上边所提到的计算复杂度增加的问题,因为 T 是无穷大的。在这种情况下, γ 的取值很重要,因为它需要保证计算结果是收敛的。假设
R
a
t
R_{at}
Rat 是有界的, |Rat|≤
r
m
a
x
r_{max}
rmax. 那么我们可以得到
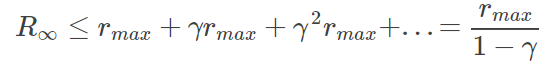
1.2 问题求解

两种求解有限状态MDP具体策略的有效算法。这里,我们只针对MDP是有限状态、有限动作的情况。
1.2.1 策略迭代算法



1.2.2 值迭代算法



1.3 实例
1.3.1 策略迭代实例

使用马尔科夫决策过程策略迭代算法进行计算,具体过程详见,
https://github.com/persistforever/ReinforcementLearning/tree/master/carrental
1.3.2 值迭代实例
赌徒问题 :一个赌徒抛硬币下赌注,如果硬币正面朝上,他本局将赢得和下注数量相同的钱,如果硬币背面朝上,他本局将输掉下注的钱,当他输光所有的赌资或者赢得$100则停止赌博,硬币正面朝上的概率为p。赌博过程是一个无折扣的有限的马尔科夫决策问题。
使用马尔科夫决策过程值迭代算法进行计算,具体过程详见,
https://github.com/persistforever/ReinforcementLearning/tree/master/gambler
1.4 MDP中的参数估计



1.4.1 Policies策略

1.4.2 Policy based Value Function基于策略的价值函数

1.4.3 Bellman Expectation Equation贝尔曼期望方程



1.4.4 Optimal Value Function最优价值函数

1.4.5 Theorem of MDP定理

1.4.6 Finding an Optimal Policy寻找最优策略

1.4.7 Bellman Optimality Equation贝尔曼最优方程


1.4.7.1 Solving the Bellman Optimality Equation求解贝尔曼最优方程
贝尔曼最优方程是非线性的,通常而言没有固定的解法,有很多著名的迭代解法:
- Value Iteration 价值迭代
- Policy Iteration 策略迭代
- Q-learning
- Sarsa
这个可以大家之后去多了解了解。
1.5 最优决策
也许上面的目标函数还不清晰,如何求解最有决策,如何最大化累积回报
下面结合例子来介绍如何求解上面的目标函数。且说明累积回报函数本身就是一个过程的累积回报,回报函数才是每一步的回报。

下面再来看求解上述最优问题,其中 就是以s为初始状态沿着决策函数走到结束状态的累积回报。
1.6 值迭代

1.7 策略迭代
值迭代是使累积回报值最优为目标进行迭代,而策略迭代是借助累积回报最优即策略最优的等价性,进行策略迭代。

1.8 MDP中的参数估计
回过头来再来看前面的马尔科夫决策过程的定义是一个五元组,一般情况下,五元组应该是我们更加特定的问题建立马尔科夫决策模型时该确定的,并在此基础上来求解最优决策。所以在求解最优决策之前,我们还需更加实际问题建立马尔科夫模型,建模过程就是确定五元组的过程,其中我们仅考虑状态转移概率,那么也就是一个参数估计过程。(其他参数一般都好确定,或设定)。
假设,在时间过程中,我们有下面的状态转移路径:

二、连续时间马尔科夫过程
2.1 连续时间马尔科夫链的一般定义

和起始时间t无关的话,我们称这是时间齐次的马尔科夫链。这个转移矩阵和离散时间不同的是,离散时间给出的是一步转移概率,但是连续马尔科夫链的转移概率给出的是和时间相关的。
2.2 连续时间马尔科夫链的另一类定义
我们考虑连续时间马尔科夫链从一个状态 i开始,到状态发生变化,比如变成j所经过的时间,由于马尔科夫链的马尔科夫性,这个时间是具有无记忆性的,所以这个时间是服从指数分布的。这和离散时间马尔科夫链是密切相关的,离散时间马尔科夫链中的时间是离散时间,因为由无记忆性,所以是服从几何分布的。
这样我们就可以这样定义连续时间马尔科夫链。马尔科夫链是这样的一个过程。
- (i)在转移到不同的状态 i i i前,它处于这个状态的时间是速率为 v i v_i vi的指数分布。
- (ii)当离开状态
i
i
i时,以某种概率
P
i
j
P_{ij}
Pij进入下一个状态
j
j
j,当然
P
i
j
P_{ij}
Pij满足

对比于半马尔科夫链,我们可以发现,连续时间马尔科夫链是一种特殊的半马尔科夫链,在一个状态所待的时间是只不过是一个具体的分布–指数分布,而半马尔科夫链只是说所待的时间是任意的一个随机时间。
2.3 生灭过程

2.4 连续时间马尔科夫链的两个定义(2.1和2.2)之间的关系


接下来,我们举个例子来说明马尔科夫链的极限分布的应用




%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%




2.5 最优决策
也许上面的目标函数还不清晰,如何求解最优决策,如何最大化累积回报
下面结合例子来介绍如何求解上面的目标函数。且说明累积回报函数本身就是一个过程的累积回报,回报函数才是每一步的回报。
下面再来看求解上述最优问题,其中 就是以s为初始状态沿着决策函数走到结束状态的累积回报。
2.5.1 值迭代
2.5.2 策略迭代
值迭代是使累积回报值最优为目标进行迭代,而策略迭代是借助累积回报最优即策略最优的等价性,进行策略迭代。
2.6 MDP中的参数估计
回过头来再来看前面的马尔科夫决策过程的定义是一个五元组,一般情况下,五元组应该是我们更加特定的问题建立马尔科夫决策模型时该确定的,并在此基础上来求解最优决策。所以在求解最优决策之前,我们还需更加实际问题建立马尔科夫模型,建模过程就是确定五元组的过程,其中我们仅考虑状态转移概率,那么也就是一个参数估计过程。(其他参数一般都好确定,或设定)。
假设,在时间过程中,我们有下面的状态转移路径:
2.7 转移速率
连续时间马尔科夫链的假设
- 当前状态i到下一个转移的时间服从参数 v i v_i vi的指数分布,且独立于之前的历史过程和下一个状态
- 当前状态i以概率 p i j p_{ij} pij到达下一个状态j,而且独立于之前的历史过程和下一个状态

三、马尔可夫链
3.1 一些定义

3.2 C-K方程
查普曼-柯尔莫格洛夫方程(Chapman-Kolmogorov equation,C-K equation)给出了计算 [公式] 步转移概率的一个方法:


3.3 状态的分类


命题得证。
很显然,暂态也是一个类性质。而利用上述性质可以得到:有限马尔可夫链的所有状态不可能都是暂态,有限不可约马尔可夫链的所有状态都是常返态。

3.4 长程性质和极限概率



%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
马尔可夫决策过程为决策者在随机环境下做出决策提供了数学架构模型,为动态规划与强化学习的最优化问题提供了有效的数学工具,广泛用于机器人学、自动化控制、经济学、以及工业界等领域。当我们提及马尔可夫决策过程时,我们一般特指其在离散时间中的随机控制过程:即对于每个时间节点,当该过程处于某状态(s)时,决策者可采取在该状态下被允许的任意决策(a),此后下一步系统状态将随机产生,同时回馈给决策者相应的期望值

,该状态转移具有马尔可夫性质。

https://zhuanlan.zhihu.com/p/35354956
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
四、马尔可夫过程
https://zhuanlan.zhihu.com/p/30317123
4.1 markov过程定义

4.2 markov过程和指数过程有什么关系
Markov过程和指数过程都是随机过程的特殊类型,它们之间存在一定的关系,尤其是在描述状态转移时。
-
Markov过程(Markov Process):Markov过程是一种具有马尔可夫性质的随机过程,即给定当前状态,未来状态的概率分布仅依赖于当前状态,而与过去状态的历史无关。它的状态空间可以是有限或无限的,且状态转移概率必须满足马尔可夫性质。Markov过程可以是离散的(如马尔可夫链)或连续的(如连续时间马尔可夫过程)。
-
指数过程(Exponential Process):指数过程是一种连续时间的随机过程,其状态的持续时间遵循指数分布。在指数过程中,状态停留的时间间隔服从指数分布,这意味着它具有无记忆性质,即未来的停留时间与过去停留时间的长度无关。
关于两者的关系:
-
Markov过程中的状态转移时间分布:在Markov过程中,虽然状态之间的转移概率可能是任意的,但转移时间的分布通常不受具体过程的马尔可夫性质限制。因此,某些Markov过程中的状态转移时间可以符合指数分布。
-
指数过程中的状态转移:指数过程的核心特征之一是其状态转移时间服从指数分布。这意味着在指数过程中,状态之间的转移具有无记忆性,与之前的状态停留时间无关。尽管指数过程本身并不一定是马尔可夫的,但其具有类似的特性,因为状态的转移不受过去状态的历史影响。
因此,尽管Markov过程和指数过程是两个不同的概念,但在某些情况下它们可能存在一定程度的联系,尤其是在描述状态转移时的时间分布特性上。
五、Markov Reward Process马尔可夫奖励过程
5.1 MRP
简单来说,马尔可夫奖励过程就是含有奖励的马尔可夫链,要想理解MRP方程的含义,我们就得弄清楚奖励函数的由来,我们可以把奖励表述为进入某一状态后收获的奖励。奖励函数如下所示:

5.2 Return回报

5.3 Value Function价值函数

5.4 Bellman Equation贝尔曼方程

六、广义马尔科夫模型
广义马尔科夫模型 (generalized Markov model) 指的是连续时间上的随机过程,在一系列时间点 0 ≤ S 1 ≤ S 2 ≤ ≤ . . . 0 \leq S_1 \leq S_2 \leq \leq ... 0≤S1≤S2≤≤...上满足Markov特性。
6.1 Markov renewal process
In probability and statistics, a Markov renewal process (MRP) is a random process that generalizes the notion of Markov jump processes. Other random processes like Markov chains, Poisson processes and renewal processes can be derived as special cases of MRP’s.
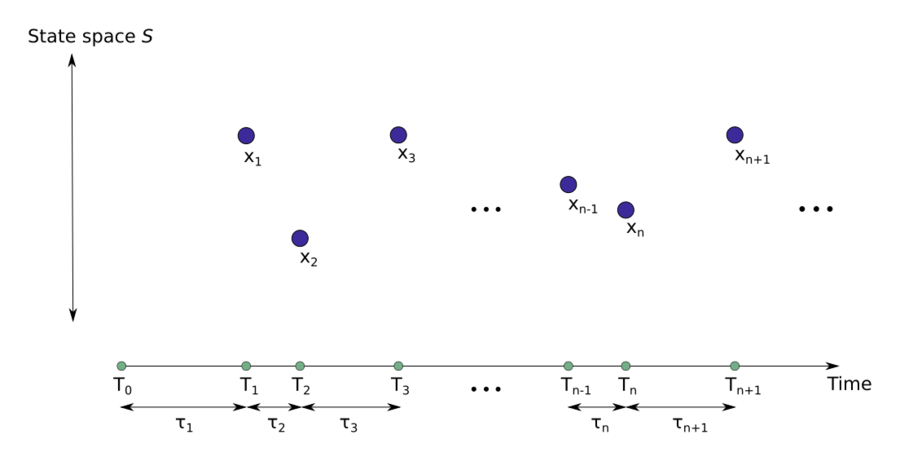
Consider a state space
S
\mathrm{S}
S. Consider a set of random variables
(
X
n
,
T
n
)
(X_{n},T_{n})
(Xn,Tn), where
T
n
T_{n}
Tn are the jump times and $X_{n} $are the associated states in the Markov chain (see Figure above). Let the inter-arrival time,
τ
n
=
T
n
−
T
n
−
1
\tau_n=T_n-T_{n-1}
τn=Tn−Tn−1. Then the sequence
(
X
n
,
T
n
)
(X_n,T_n)
(Xn,Tn) is called a Markov renewal process if
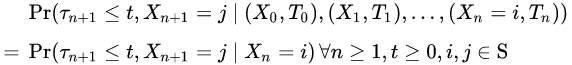
What is Markov Modulated Poisson Process (MMPP)
1.A process, belonging to the class of markov renewal processes, where arrivals occur according to a statedependent poisson process with different rates governed by a continuous-time markov chain.
https://mp.weixin.qq.com/s?__biz=Mzg3OTAyMjcyMw==&mid=2247485738&idx=1&sn=f31a646d6cee548fd99525d2c798fdf4&chksm=cf0b8ec6f87c07d05960be03b64eddbce47426bc6ccaef7a97c49c2ff5f23c07a940e2b557cf&token=1326040548&lang=zh_CN#rd
https://zhuanlan.zhihu.com/p/149765762
http://xtf615.com/2017/07/15/RL/
https://zhuanlan.zhihu.com/p/271221558
https://zhuanlan.zhihu.com/p/148932940

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









