







1、Abstract
We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. (本文提出一种比过去使用的神经网络更深的训练网络,残差学习结构。)
We provide residual networks are easier to optimize, and can gain accuracy from considerably increased depth. (由实验证明,残差网络更容易优化,并且在增加大量深度后可以得到更好的精度。)
也就是,摘要表示,对于神经网络而言,网络深度很重要,然后残差网络帮助网络深度增加并能得到好的效果。
2、Introduction
Deep networks naturally integrate low/mid/high-level features and classifiers in an end-to-end multi-layer fashion. (在多层端对端的结构中,深度神经网络能整合低中高三个维度的特征和分类器)
自从发现深度对神经网络的重要作用之后,大家都往很深的方向发展,然后就出问题了。
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients, which hamper convergence from the beginning. This problem has been largely addressed by normalized initialization and intermediate normalization layers. (深度的增加,一个问题随之而来,堆叠更多的层能让神经网络的学习更好吗?一个障碍马上回答了这个问题,及时梯度消失,梯度消失会影响收敛,但这个问题已经被BN解决了。)
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. (当BN解决了梯度消失的问题,网络继续收敛时,另一个问题又暴露出来了,当神经网络深度增加是,精度却趋于饱和,并且迅速衰退(下降)。而且还不是过拟合的锅)
The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. (训练精度的衰退表示并不是所有的系统都是一样容易优化的。) 也就是说精度衰退是优化的不好。
There exits a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. (对于更深的模型,这有一种通过构建的解决方案:恒等映射(identity mapping)来构建增加的层,而其它层直接从浅层模型中复制。) 实践证明这是目前可以实现的最好的方法了。
In this paper, we address the degradation problem by introducing a deep residual learning framework. Formally, denoting the desired underlying mapping as ![]() , we let the stacked nonlinear layers fit another mapping of
, we let the stacked nonlinear layers fit another mapping of ![]() . The original mapping is recast into
. The original mapping is recast into ![]() . If an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers. (本文中我们使用一种深度残差网络解决退化问题,底层映射为
. If an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers. (本文中我们使用一种深度残差网络解决退化问题,底层映射为![]() ,令非线性叠层满足另一个映射
,令非线性叠层满足另一个映射![]() ,原始映射则重定义为
,原始映射则重定义为![]() ,如果可以使用恒等映射,将残差变成0比非线性堆叠更容易拟合恒等映射。)
,如果可以使用恒等映射,将残差变成0比非线性堆叠更容易拟合恒等映射。)
Shortcut connections are those skipping one or more layers. In our case, the shortcut connections simply perform identity mapping, and their outputs are added to the outputs of the stacked layers. Identity shortcut connections add neither extra parameter nor computational complexity. (shortcut connection 是跳过一层或者多层的,在本文中,shortcut connection使用的是简单的恒等映射,并将它的输出加到神经网络层的结果之中。恒等shortcut connection并不会增加额外的参数和计算复杂度。)
残差结构的优势:
Our extremely deep residual nets are easy to optimize, but the counterpart “plain” nets (that simply stack layers) exhibit higher training error when the depth increases; Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks. (我们的深度残差结构很容易优化,相对应的,一般的神经网络结构在深度增加的时候就有更高的训练误差。并且深度残差结构在增加深度时能有更好的精度,得出的结果比普通的神经网络更好。)
然后就举了ImageNet和CIFAR-10的例子,深度残差结构复杂度比VGG低,test error 也低,可以通用普适。
3、Deep Residual Learning
If one hypothesizes that multiple nonlinear layers can asymptotically approximate complicated functions, then it is equivalent to hypothesize that they can asymptotically approximate the residual functions. (一个假设,多层非线性层网络能逼近一份复杂的函数,那么它就能逼近一个残差函数。)
If the optimal function is closer to an identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one. (若优化函数更接近与恒等映射而不是0映射,相对于学习这个函数得到一个新的结果,求解器更容易得到一个恒等映射的波动。)
![]()
![]() residual mapping,
residual mapping, ![]()
The dimensions of x and F must be equal in Eqn. (1). If this is not case (e.g., when changing the input/output channels), we can perform a linear projection Ws by the shortcut connections to match the dimensions:
![]()
在Eqn.(1)中,输入输出必须维度一致,当维度不一致时,我们需要增加一个线性矩阵Ws让shortcut connection维度匹配,得到Eqn. (2)。
另外,只有恒等映射就可以解决degradation问题,但是在单层的神经网络里就没法使用残差网络了。We also note that although the above notations are about fully-connected layers for simplicity, they are applicable to convolutional layers. The function ![]() can represent multiple convolutional layers. The element-wise addition is performed on two feature maps, channel by channel. (我们还发现不仅是对于全连接层,对于卷积层也是同样适用的。函数
can represent multiple convolutional layers. The element-wise addition is performed on two feature maps, channel by channel. (我们还发现不仅是对于全连接层,对于卷积层也是同样适用的。函数![]() 可以表示多个卷积层,在两个特征图的通道之间执行元素逐级的加法。)
可以表示多个卷积层,在两个特征图的通道之间执行元素逐级的加法。)
4、Network Architectures
Plain work:
plain网络结构主要受VGG网络的启发。卷积层主要为3*3的滤波器,并遵循以下两点要求:1) 输出特征尺寸相同的层含有相同数量的滤波器;2) 如果特征尺寸减半,则滤波器的数量增加一倍来保证每层的时间复杂度相同。
Residual work:
在以上plain网络的基础上,插入shortcut连接将网络变成残差版本。输入和输出的维度相同,直接使用恒等shortcuts; 当维度增加时有两种方案:
(A) shortcut仍然使用恒等映射,在增加的维度上使用0来填充,这样做不会增加额外的参数;
(B) 使用Eq.2的映射shortcut使维度保持一致(通过1*1的卷积)。
残差网络的实现细节:略
5、Experiments
论文使用了两个项目来对残差网络进行实验和对比,以验证残差网络的特点和效果。
首先,在ImageNet Classification中,用了ImageNet 2012 classification datasets,分别测试了不同深度(18 and 34)的plain network 和residual network。从测试结构我们可以看出 ,使用plain network在34 层深度增加是training error和validation error都有不同程度的增加,而使用residual network 层数增加时,对两种error都有一定的降低。
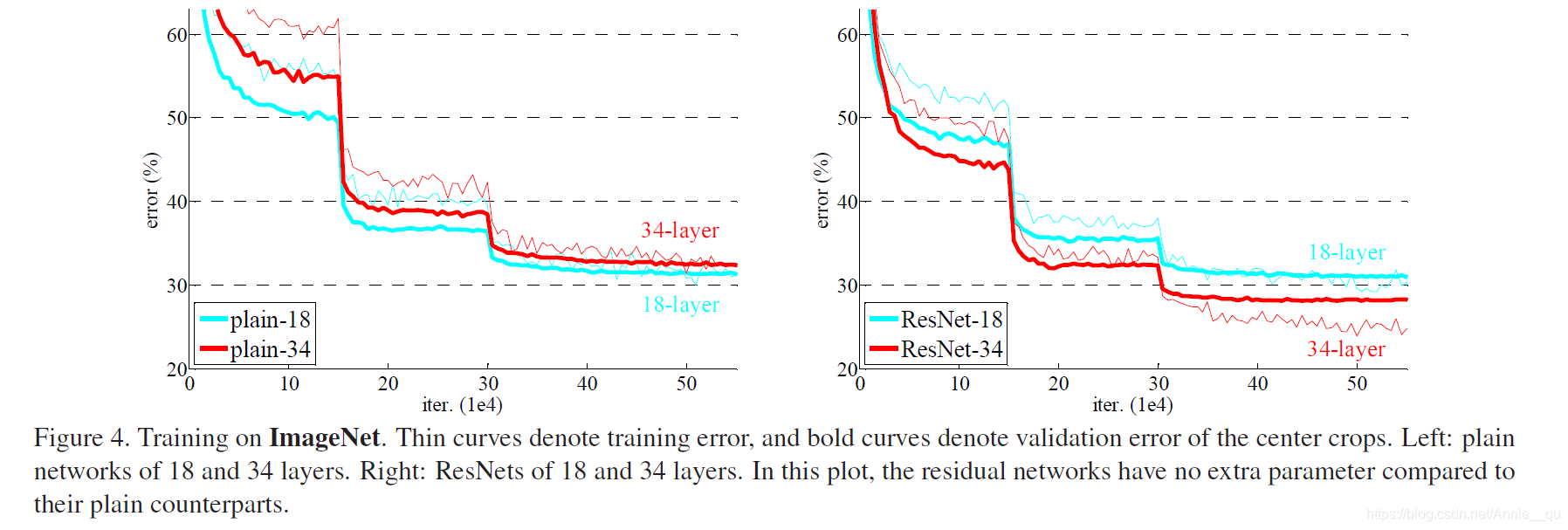
另外,top-1 error表示,ResNet 解决了因增加深度带来的degradation问题,并且相对于plain network,降低了top-1 error。18层的两种结构的准确率差不多,但是ResNet 收敛更快,所以在not overly deep时,SGD在ResNet 收敛更快。
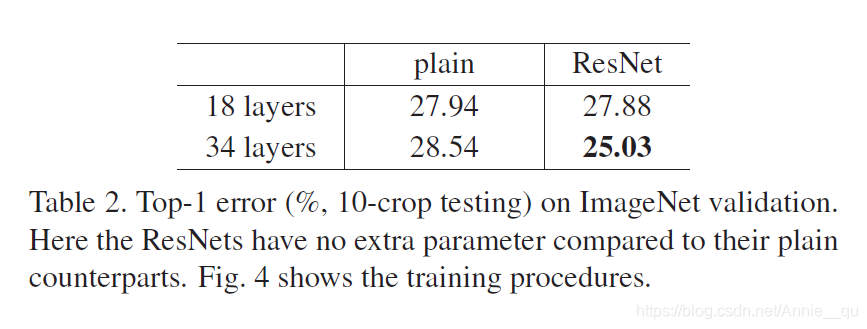
Project shortcut are not essential for address the degradation problem. Identity shortcut are particular important for not increasing the complexity of the bottleneck architectures that are introduced below. (Project shortcut 确实比identity shortcut要好,但这个好的程度不高并且带来了更复杂的结构,所以综合结构复杂度来看,还是采用identity shortcut。)
然后增加网络深度到50、101、152结果更加精确,也没有degradation problem。
另外,还有一个人future study:34层的training error在迭代后期更高,虽然用了BN,没有vanish gradient。准确率还可以,即求解器有效,也就收敛率不高了。
对CIFAR-10的测试:
使用的网络和ImageNet差不多,只是在110层改了一下增加前期的学习速率。分析其层响应:the residual functions might be generally closer to zero than the non-residual functions. When there are more layers, an individual layer of ResNet tends to modify the signal less.
超过1000层后,没有优化困难并且结果很好,但是test error很大,层数太多过拟合了。以后也可以使用更好的正则化得到更好的效果。















 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









