







Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos 跟随你的姿势 使用无姿势视频进行姿势引导的文本到视频生成

Abstract
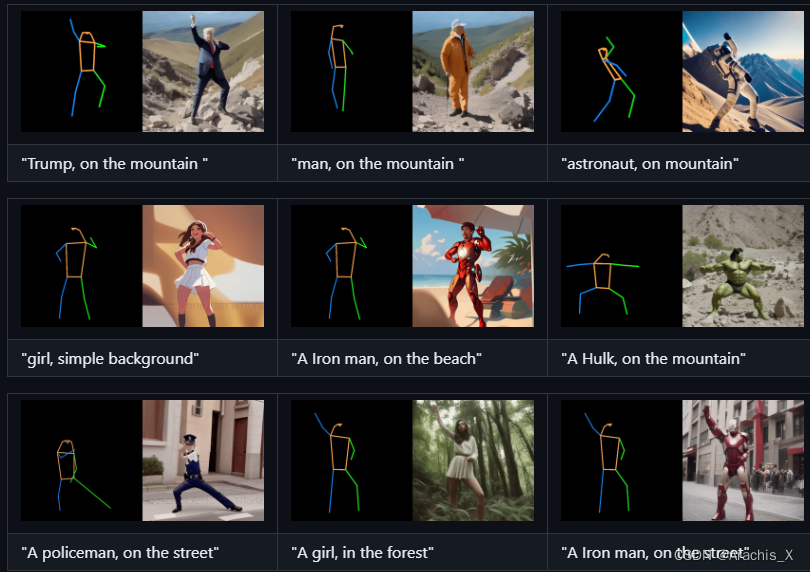
Generating text-editable and pose-controllable character videos have an imperious demand in creating various digital human. Nevertheless, this task has been restricted by the absence of a comprehensive dataset featuring paired video-pose captions and the generative prior models for videos. In this work, we design a novel two-stage training scheme that can utilize easily obtained datasets (i.e.,image pose pair and pose-free video) and the pre-trained text-to-image (T2I) model to obtain the pose-controllable character videos. Specifically, in the first stage, only the keypoint-image pairs are used only for a controllable text-to-image generation. We learn a zero-initialized convolutional encoder to encode the pose information. In the second stage, we finetune the motion of the above network via a pose-free video dataset by adding the learnable temporal self-attention and reformed cross-frame self-attention blocks. Powered by our new designs, our method successfully generates continuously pose-controllable character videos while keeps the editing and concept composition ability of the pre-trained T2I model. The code and models will be made publicly available.
生成文字可编辑、姿势可控制的人物视频是创造各种数字人类的迫切需求。
然而,这项任务一直受限于缺乏以视频与姿势字幕配对为特征的综合数据集和视频先验生成模型。
在这项工作中,我们设计了一种新颖的两阶段训练方案,可以利用容易获得的数据集(即图像姿势配对和无姿势视频)和预训练的文本到图像(T2I)模型来获得姿势可控的人物视频。
-
具体来说,在第一阶段,仅使用关键点-图像对生成可控的文本-图像。我们学习一个零初始化卷积编码器来编码姿势信息。
-
在第二阶段,我们通过无姿势视频数据集,加入可学习的时间自注意力和改革后的跨帧自注意力块,对上述网络的运动进行微调。
在新设计的支持下,我们的方法成功地生成了连续姿势可控的角色视频,同时保持了预训练 T2I 模型的编辑和概念合成能力。代码和模型将公开发布。

















 1775
1775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









