







SSD论文:
https://arxiv.org/abs/1512.02325
SSD论文翻译:
https://www.cnblogs.com/pengsky2016/p/8006546.html
https://zhuanlan.zhihu.com/p/65484308
https://blog.csdn.net/weixin_43159628/article/details/88223116
论文笔记:
https://zhuanlan.zhihu.com/p/58713034
https://zhuanlan.zhihu.com/p/33544892
1、SSD简介
SSD的全拼是Single Shot MultiBox Detector,冲着YOLO的缺点提出的。SSD的框架图如下:

( a ) 表示带有两个Ground Truth边框的输入图片,( b ) 和 ( c ) 分别表示8×8网格和4×4网格,显然前者适合检测小的目标,比如图片中的猫,后者适合检测大的目标,比如图片中的狗。在每个格子上有一系列固定大小的Box(有点类似Anchor Box),这些在SSD称为Default Box,用来框定目标物体的位置,在训练的时候Ground Truth会赋予给某个固定的Box,比如 ( b ) 中的蓝框和 ( c )中的红框。
SSD的网络分为两部分,前面的是用于图像分类的标准网络(去掉了分类相关的层),后面的网络是用于检测的多尺度特征映射层,从而达到检测不同大小的目标。SSD和YOLO的网络结构对比如图所示:

SSD在保持YOLO高速的同时效果也提升很多,主要是借鉴了Faster R-CNN中的Anchor机制,同时使用了多尺度。但是从原理依然可以看出,Default Box的形状以及网格大小是事先固定的,那么对特定的图片小目标的提取会不够好。
2、SSD特点
- SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。
- SSD的核心是在不同尺度的特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移。
3、SSD结构
以VGG-16为基础,使用VGG的前五个卷积,后面增加从Conv6开始的5个卷积结构,输入图片要求300*300。

4、SSD流程

SSD中引入了Defalut Box,实际上与Faster R-CNN的anchor box机制类似,就是预设一些目标预选框,不同的是在不同尺度feature map所有特征点上是使用不同的prior boxes。

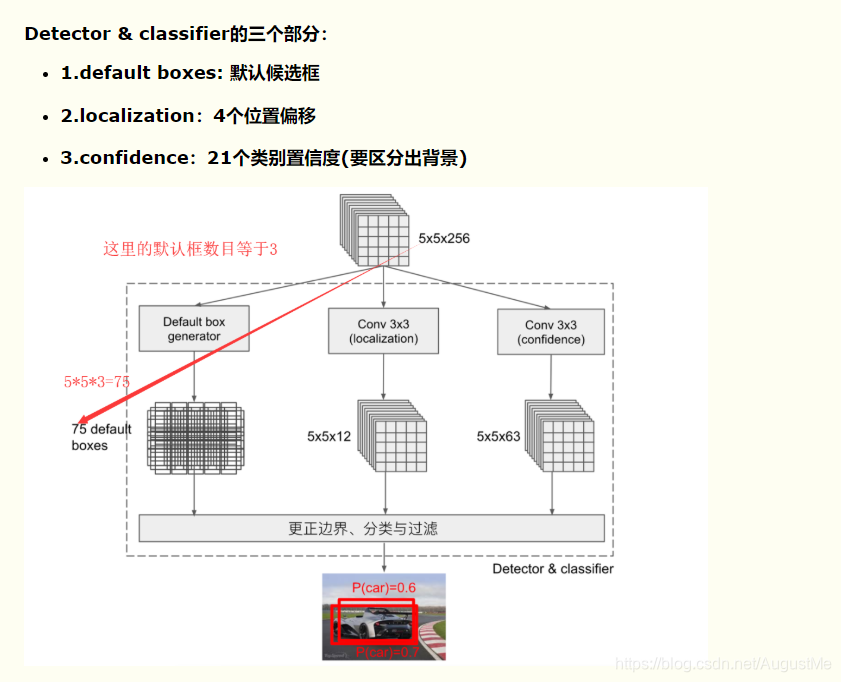

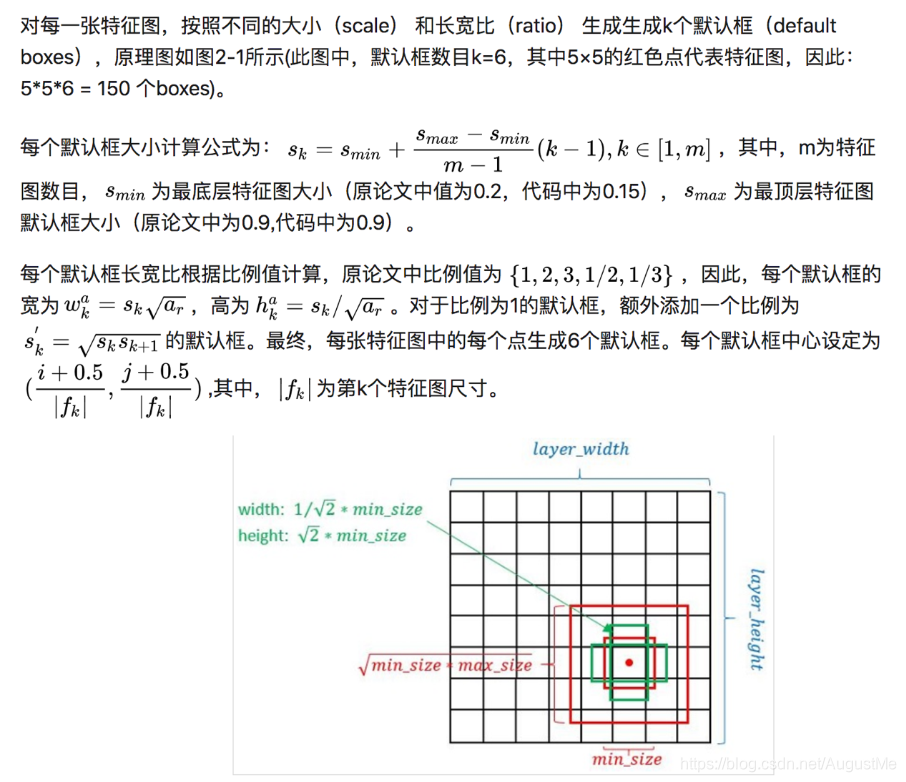
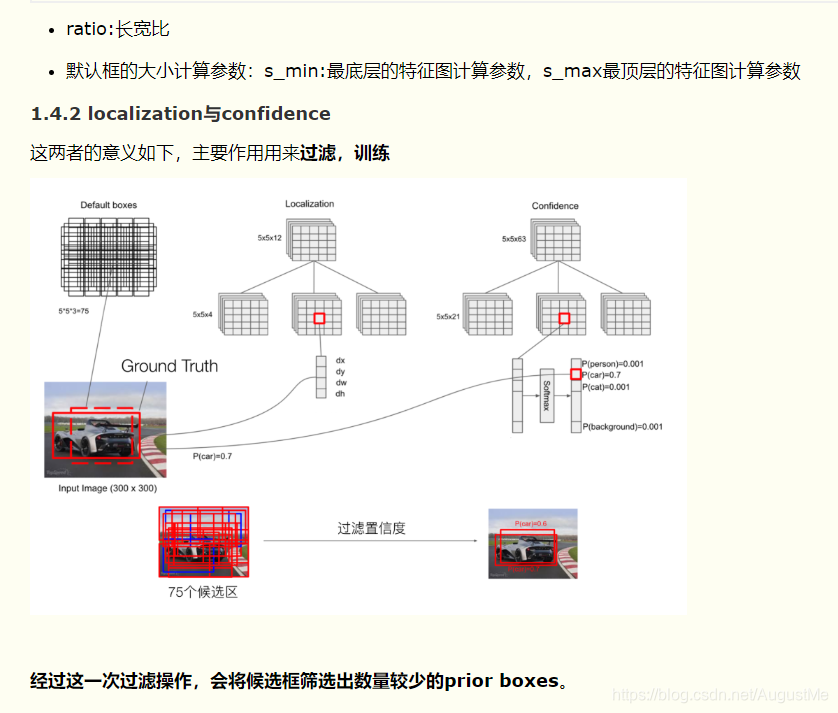



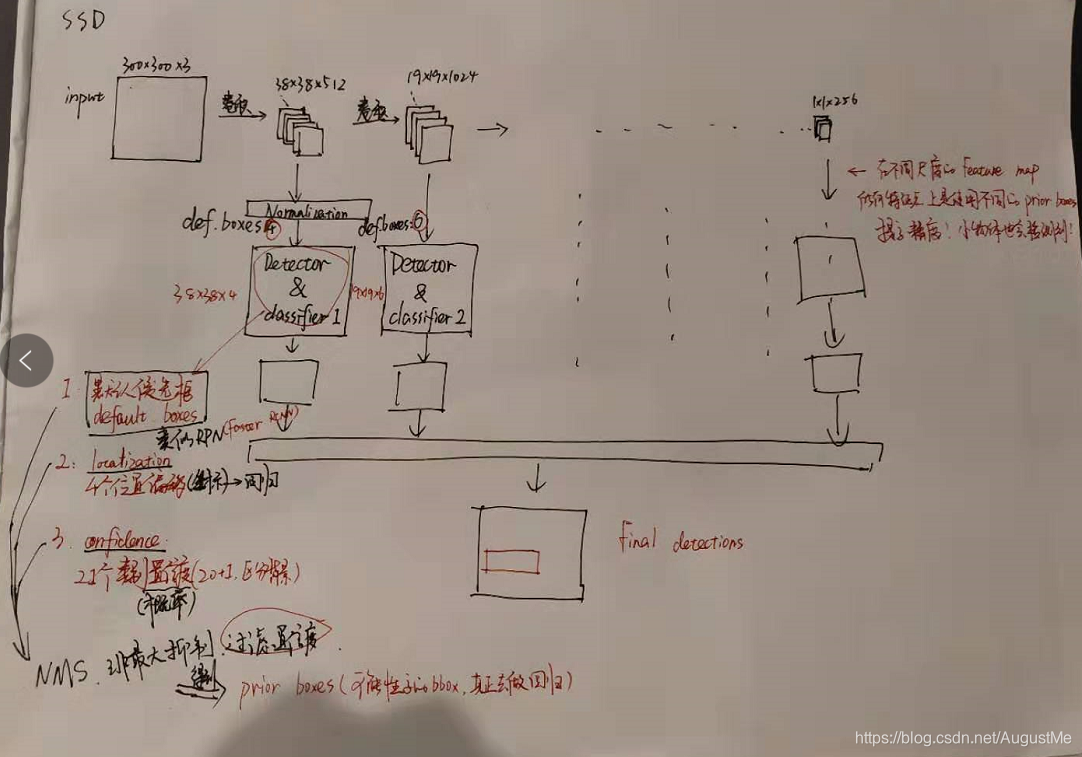
摘抄自:https://www.cnblogs.com/kongweisi/p/11151791.html 仅用来学习,侵权立删。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











