









SSD网络介绍
使用多个特征图作为特征预测层。
SSD (Single Shot MultiBox Detector)于2016年提出。当网络输入为300×300大小时,在VOC2007测试集上达到74.3%的mAP;当输入是512×512大小时,达到了76.9%的mAP

SSD_Backbone部分介绍
不变的部分
特征提取网络沿用了VGG-16(网络结构如图所示)的Conv5_3层之前的所有结构
改变的部分
将VGG-16的第5个池化层(pool_5)从2×2,步长2改为3×3,步长1(修改后的pool_5特征图的大小不变)
将VGG-16的两个全连接层(FC6 & FC7)改为两个卷积层(Conv6 & Conv7)
增加了4个卷积层
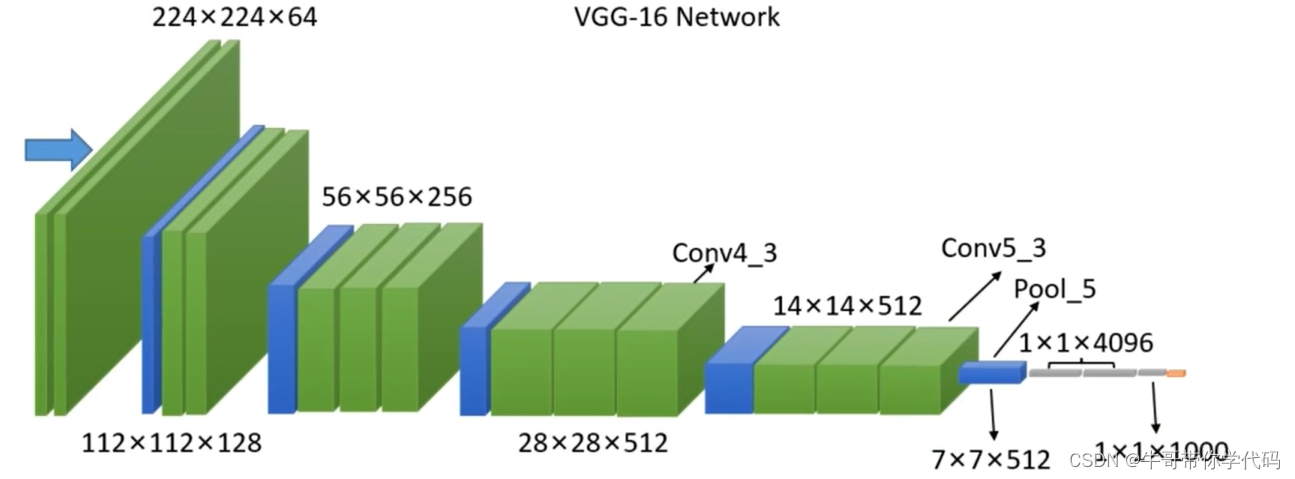
随着网络层数的加深,提取到的特征信息抽象程度也随之加大,高层语义信息中小目标物体的特征信息会减少,因此,如图所示,网络选择用较大的特征图检测较小的目标物体,用语义信息丰富的特征图检测较大的物体。选取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2的特征图作为预测特征层,从而实现针对不同大小物体的目标检测。

不同大小特征图检测不同大小目标的物体
左图中“猫”相较与“狗”的特征较小,所以对于“猫”这类尺寸较小的物体的检测来说选用浅层特征图,“狗”这类尺寸较大的物体用高层、含语义信息丰富的特征图来检测。
默认框生成机制
类似于Faster R-CNN网络中的锚框(Anchor)生成机制用来检测图片中的目标物体,SSD中有默认框(Default Box)生成机制。在每个预测特征层的每个cell上都会生成默认框。
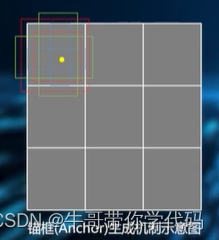
左图为默认框生成效果的简单示例,黄色点为当前cell的中心点,蓝框的宽高比为1:3和3:1、绿框的宽高比为1:2和2:1、红框的宽高比为1:1
默认框尺寸的计算公式如下所示:

式中sk为当前预测层的默认框的尺寸,smin为默认框最小尺寸,smax为默认框最大尺寸,作为网络超参数设置。m为预测特征层的数量,在SSD300网络中m为6。
默认框宽高比有1:1、1:2、2:1、1:3、3:1共5种设置,不同比例下的宽、高计算公式如下所示:

式中wak、hak分别为第k个预测特征层在比例ar下对应的宽、高。对于宽高比为1:1的默认框,其对应的尺寸除了当前预测特征层的默认框尺寸sk之外,还有sk' = √(SkSk+1)
在SSD_VGG16官方源代码中默认框的设置如下表所示:
默认框中心坐标点设置过程如下图所示。将当前特征图进行坐标遍历,图中黄色点为当前遍历到的特征图坐标点,将该点的横纵坐标值各加0.5,再分别对整个原图尺寸进行归一化操作,即得到cell相对于原图的中心坐标点,也是默认框的中心坐标点,图中绿色点为当前像素(cell)的中心坐标点。
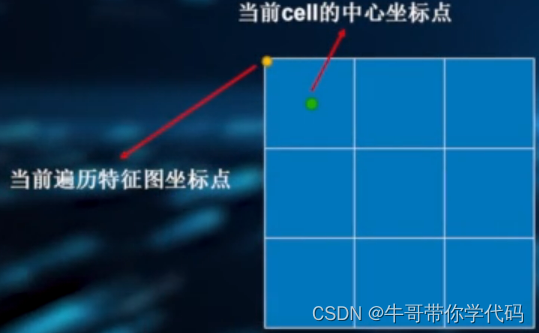
以计算中心坐标点的y轴坐标值为例:
- 先将当前层特征图的高网格点化
- 再加0.5的偏移值
- 再乘以特征图上一步对应在原图上的跨度
- 最后除以原图的高
- 得到相对于原图的中心点
正负样本匹配
正负样本选取准则:
- 选择与Ground Truth交并比最大的默认框所对应的IOU值;
- 将与当前标注信息中的每个Ground Truth交并比最大的默认框所对应的IOU值设为2,即选为正样本。若不进行这一步,将会有Ground Truth未匹配到默认框;
- 将与Ground Truth交并比大于0.5的默认框也设为正样本。
假设当前5个默认框与3个真值的交并比如下:

(1)选择与GT0框交并比最大的默认框的索引值记为idx
(2)将idx所对应的IOU值置为2.0
(3)将与GT交并比大于0.5的默认框均置为正样本
SSD的损失函数
总损失函数计算公式如下所示,式中L(·)为总损失函数,N为被选取出来的默认框的个数,包括正样本和负样本,参数a为1

坐标回归损失函数如下所示:

式中l为预测的坐标偏移量,g为默认框与Ground Truth框d的坐标偏移量。![]() 分别为中心点坐标cx、cy的偏移损失
分别为中心点坐标cx、cy的偏移损失![]() 分别为宽度w和高度h的缩放损失。计算坐标回归损失的时候只计算正样本的回归损失。
分别为宽度w和高度h的缩放损失。计算坐标回归损失的时候只计算正样本的回归损失。
类别损失函数如下所示:


预测器的实现
3×3卷积核实现类别分数预测以及坐标偏移量回归。对于每个预测特征层上的每个位置,会有k个默认框,对每个默认框进行预测,所以输出大小为:
m × n × k × (C+4)
其中, m,n为当前特征预测层的宽高,k为预测特征层每个位置上产生的默认框的个数,c为加上背景后的类别数,4为边界框坐标(x, y, OMEGA, h)回归参数的个数.
定义MobileNetV2的反向残差结构(反向残差结构如下图所示,(a)为残差结构,(b)为反向残差结构)
反向残差结构
- 先通过一个1x 1的普通卷积将h × w × d大小的特征图升维得到h×w× td大小的特征图,t对应代码中的扩展因子(expand _ratio)参数
- 再通过3×3的深度方向的卷积(Depthwise Convolution)操作,所得到的特征图大小为

- 最后通过1× 1的点卷积(Pointwise Convolution)降维,此时使用的激活函数不是ReLU6激活函数,而是线性激活函数反向残差结构中只有当步距(stride=1),且输入与输出特征维度相同时,会有和残差结构中的shortcut连接
当扩展因子为1时,反向残差结构第一层没有1×1的普通卷积。

下图为MobileNetV2网络结构示意图,图中t为扩展因子,c为输出特征图深度,n为反向残差块重复次数,s为每个反向残差层中第一个反向残差块的步距


Focal Loss损失函数
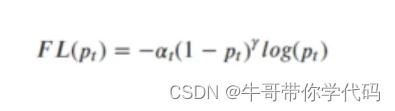
其中α,为平衡正负样本因子,y为平衡难例因子

















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











