







面向医学生/医生的实用机器学习教程系列推文
本篇主要介绍caret中常见的数据预处理步骤,而且非常简单容易记住!
之前专门写过一篇推文,详细介绍数据预处理的必要性及常见的方法实现:机器学习和预测建模中常见的数据预处理方法
这篇可以作为上一篇的补充篇,两篇推文配合阅读,效果更好,部分内容有重复。关于数据预处理后期会再出2篇推文,分别介绍如何使用tidymodels和mlr3实现数据预处理。
本期目录:
- 哑变量设置
- 零方差和近零方差变量处理
- 相关性变量处理
- 共线性变量处理
- 中心化和标准化
- 缺失值插补
- 变量变换
- 多个预处理步骤同时进行
- 类别距离计算
另外,除了caret中自带的这些数据处理步骤,caret包还可以和recipes包同时使用,支持recipes包中的数据预处理方式!
哑变量设置
哑变量是分类变量中非常常见的编码方式,在各种回归模型中都是默认操作,详细的哑变量的编码方案以及其他常见的编码方案可以参考之前的推文:分类变量进行回归分析时的编码方案
这里以earth包中的etitanic数据集为例,其中包含两个分类变量,pclass:乘客等级,1st, 2nd, 3rd;sex:乘客性别,male和female。其中survived是结果变量。
library(earth)
data(etitanic)
str(etitanic)
## 'data.frame': 1046 obs. of 6 variables:
## $ pclass : Factor w/ 3 levels "1st","2nd","3rd": 1 1 1 1 1 1 1 1 1 1 ...
## $ survived: int 1 1 0 0 0 1 1 0 1 0 ...
## $ sex : Factor w/ 2 levels "female","male": 1 2 1 2 1 2 1 2 1 2 ...
## $ age : num 29 0.917 2 30 25 ...
## $ sibsp : int 0 1 1 1 1 0 1 0 2 0 ...
## $ parch : int 0 2 2 2 2 0 0 0 0 0 ...
psych::headTail(etitanic)
## pclass survived sex age sibsp parch
## 1 1st 1 female 29 0 0
## 2 1st 1 male 0.92 1 2
## 3 1st 0 female 2 1 2
## 4 1st 0 male 30 1 2
## ... <NA> ... <NA> ... ... ...
## 1305 3rd 0 female 14.5 1 0
## 1307 3rd 0 male 26.5 0 0
## 1308 3rd 0 male 27 0 0
## 1309 3rd 0 male 29 0 0
哑变量处理无非就是用0和1代表不同的类别,我们可以使用model.matrix()实现,在此之前记得把分类变量因子化!这里已经是因子类型了,我们就不用再次设置了。
# 直接使用model.matrix(),会自动把因子型变量进行哑变量设置
# pclass, sex变成了哑变量
head(model.matrix(survived ~ ., data = etitanic))
## (Intercept) pclass2nd pclass3rd sexmale age sibsp parch
## 1 1 0 0 0 29.0000 0 0
## 2 1 0 0 1 0.9167 1 2
## 3 1 0 0 0 2.0000 1 2
## 4 1 0 0 1 30.0000 1 2
## 5 1 0 0 0 25.0000 1 2
## 6 1 0 0 1 48.0000 0 0
在caret包中提供了dummyVars()实现哑变量设置,和model.matrix()的使用方式基本类似:
# 使用dummyVars(),会自动把因子型变量进行哑变量设置
# pclass, sex变成了哑变量
library(caret)
## Loading required package: ggplot2
## Loading required package: lattice
dummies <- dummyVars(survived ~ ., data = etitanic)
head(predict(dummies, newdata = etitanic))
## pclass.1st pclass.2nd pclass.3rd sex.female sex.male age sibsp parch
## 1 1 0 0 1 0 29.0000 0 0
## 2 1 0 0 0 1 0.9167 1 2
## 3 1 0 0 1 0 2.0000 1 2
## 4 1 0 0 0 1 30.0000 1 2
## 5 1 0 0 1 0 25.0000 1 2
## 6 1 0 0 0 1 48.0000 0 0
可以看到这里的哑变量设置和model.matrix()的哑变量设置略有不同,没有截距项,有几个类别就有几个哑变量!
这里要注意下caret包中的数据预处理的使用方法,在使用了相关的数据预处理函数后,一定要使用predict()才可以把数据预处理应用于数据!
零方差和近零方差变量处理
有的预测变量全都都是一个值,这种变量是没有任何变化的,因为都一样,所以它的方差是0;或者有的预测变量可能只有少数几个频率非常低的唯一值。这两种变量对结果的贡献都是有限的,并不能提供有用的信息,需要去除。
使用mdrr数据集演示。其中一列nR11大部分都是501,这种变量方差是很小的!
data(mdrr)
table(mdrrDescr$nR11) # 大部分值都是0
##
## 0 1 2
## 501 4 23
sd(mdrrDescr$nR11)^2 # 方差很小!
## [1] 0.1731787
使用nearZeroVar()找出零方差和近零方差变量,结果中会给出zeroVar和nzv两列,用逻辑值表示是不是近零方差变量或者零方差变量。
nzv <- nearZeroVar(mdrrDescr, saveMetrics= TRUE)
nzv[nzv$nzv,][1:10,]
## freqRatio percentUnique zeroVar nzv
## nTB 23.00000 0.3787879 FALSE TRUE
## nBR 131.00000 0.3787879 FALSE TRUE
## nI 527.00000 0.3787879 FALSE TRUE
## nR03 527.00000 0.3787879 FALSE TRUE
## nR08 527.00000 0.3787879 FALSE TRUE
## nR11 21.78261 0.5681818 FALSE TRUE
## nR12 57.66667 0.3787879 FALSE TRUE
## D.Dr03 527.00000 0.3787879 FALSE TRUE
## D.Dr07 123.50000 5.8712121 FALSE TRUE
## D.Dr08 527.00000 0.3787879 FALSE TRUE
要确定这些类型的预测变量,可以计算以下两个指标(这部分可以参考之前的推文,更加详细易懂:预测建模常用的数据预处理方法):
- 个数最多的值相对于个数第二多的值 的 比值,对于表现良好的预测变量,该值将接近 1,对于高度不平衡的数据,该值非常大;
- “唯一值的百分比”是唯一值的数量除以样本总数(乘以 100),随着数据的增加,该数接近于零。
我们可以设定一个阈值,高于(或者低于)这个阈值就被认为是近零方差或者零方差变量。
去除近零方差变量:
nzv <- nearZeroVar(mdrrDescr,freqCut = 95/5,uniqueCut = 10)
filteredDescr <- mdrrDescr[, -nzv] # 去掉近零方差变量
dim(mdrrDescr) # 原数据有342列
## [1] 528 342
dim(filteredDescr) # 还剩297列
## [1] 528 297
识别高度相关的变量
有的模型在自变量高度相关时可能模型性能会更好(比如pls),但是大多数模型都需要去除高度相关的变量才能获得更好的表现。
findCorrelation()函数可以和R语言自带的cor()配合找到这种高度相关的自变量,然后根据设定的阈值,去除高度相关的自变量。
还是继续用上面的数据演示。
# 计算相关系数
descrCor <- cor(filteredDescr)
# 这个数据集里相关系数最大是1!
summary(descrCor[upper.tri(descrCor)])
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.99607 -0.05373 0.25006 0.26078 0.65527 1.00000
# 阈值设定为0.75
highlyCorDescr <- findCorrelation(descrCor, cutoff = 0.75)
# 相关系数绝对值大于0.75的变量不要了
filteredDescr <- filteredDescr[,-highlyCorDescr]
# 再次查看相关系数
descrCor2 <- cor(filteredDescr)
summary(descrCor2[upper.tri(descrCor2)])
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.70728 -0.05378 0.04418 0.06692 0.18858 0.74458
# 去除高度相关的变量后还剩50列!!297变成了50...
dim(filteredDescr)
## [1] 528 50
共线性
假设一个下面这种的数据,其中第2列和第3列的值加起来和第1列一样,第4,5,6列的值起来也和第1列一样。这种数据的某些变量间是有高度共线性的。
ltfrDesign <- matrix(0, nrow=6, ncol=6)
ltfrDesign[,1] <- c(1, 1, 1, 1, 1, 1)
ltfrDesign[,2] <- c(1, 1, 1, 0, 0, 0)
ltfrDesign[,3] <- c(0, 0, 0, 1, 1, 1)
ltfrDesign[,4] <- c(1, 0, 0, 1, 0, 0)
ltfrDesign[,5] <- c(0, 1, 0, 0, 1, 0)
ltfrDesign[,6] <- c(0, 0, 1, 0, 0, 1)
ltfrDesign
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 1 1 0 1 0 0
## [2,] 1 1 0 0 1 0
## [3,] 1 1 0 0 0 1
## [4,] 1 0 1 1 0 0
## [5,] 1 0 1 0 1 0
## [6,] 1 0 1 0 0 1
findLinearCombos()可以通过算法给出需要去除的变量,关于具体的方法可以官网查看。
comboInfo <- findLinearCombos(ltfrDesign)
comboInfo
## $linearCombos
## $linearCombos[[1]]
## [1] 3 1 2
##
## $linearCombos[[2]]
## [1] 6 1 4 5
##
##
## $remove
## [1] 3 6
结果给出了需要去除的变量是第3列和第6列。
# 去除第3列和第6列
ltfrDesign[, -comboInfo$remove]
## [,1] [,2] [,3] [,4]
## [1,] 1 1 1 0
## [2,] 1 1 0 1
## [3,] 1 1 0 0
## [4,] 1 0 1 0
## [5,] 1 0 0 1
## [6,] 1 0 0 0
中心化和标准化
这个就不用多说了,大家都知道,在caret中通过在method参数提供c("center", "scale")实现。不知道的可以参考这篇推文:预测建模常用的数据预处理方法
set.seed(96)
inTrain <- sample(seq(along = mdrrClass), length(mdrrClass)/2)
training <- filteredDescr[inTrain,]
test <- filteredDescr[-inTrain,]
trainMDRR <- mdrrClass[inTrain]
testMDRR <- mdrrClass[-inTrain]
# 中心化,标准化
preProcValues <- preProcess(training, method = c("center", "scale"))
trainTransformed <- predict(preProcValues, training)
testTransformed <- predict(preProcValues, test)
Imputation
缺失值插补,比较常用的KNN插补和随机森林插补,常见的缺失值插补方法可以参考这篇文章:我常用的缺失值插补方法
变量转化
比如用PCA提取主成分代表所有的预测变量,还有spatialSign变换,BoxCox变换,YeoJohnson变换等。 详细的方法及介绍大家可以去看之前的推文:预测建模常用的数据预处理方法
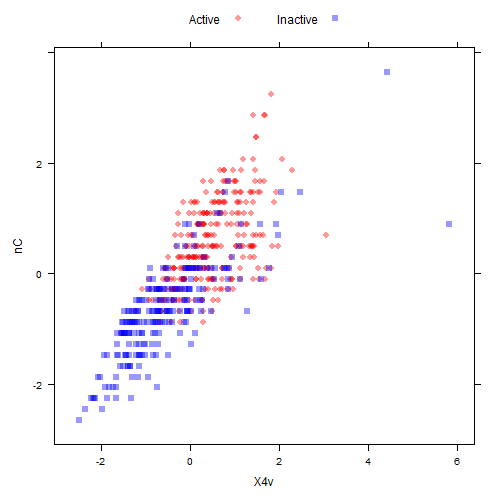
下面是一个spatialSign变换的演示。
# 没变换之前是这样的
library(AppliedPredictiveModeling)
transparentTheme(trans = .4)
plotSubset <- data.frame(scale(mdrrDescr[, c("nC", "X4v")]))
xyplot(nC ~ X4v,
data = plotSubset,
groups = mdrrClass,
auto.key = list(columns = 2))
# After the spatial sign:
transformed <- spatialSign(plotSubset)
transformed <- as.data.frame(transformed)
xyplot(nC ~ X4v,
data = transformed,
groups = mdrrClass,
auto.key = list(columns = 2))
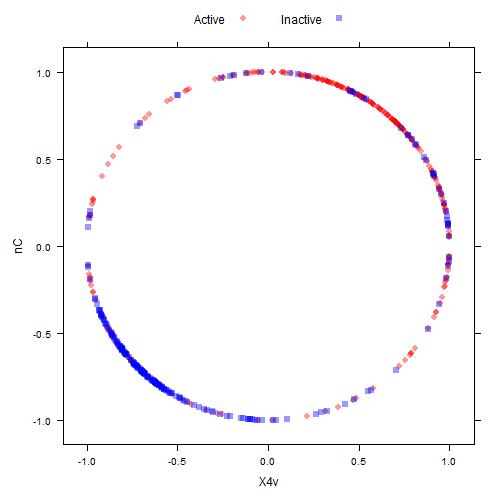
变换后就成了这样,神奇吗?
多个预处理步骤放一起
在caret中是通过preProcess()函数里面的method参数实现的,把不同的预处理步骤按照顺序写好即可。
library(AppliedPredictiveModeling)
data(schedulingData)
str(schedulingData)
## 'data.frame': 4331 obs. of 8 variables:
## $ Protocol : Factor w/ 14 levels "A","C","D","E",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ Compounds : num 997 97 101 93 100 100 105 98 101 95 ...
## $ InputFields: num 137 103 75 76 82 82 88 95 91 92 ...
## $ Iterations : num 20 20 10 20 20 20 20 20 20 20 ...
## $ NumPending : num 0 0 0 0 0 0 0 0 0 0 ...
## $ Hour : num 14 13.8 13.8 10.1 10.4 ...
## $ Day : Factor w/ 7 levels "Mon","Tue","Wed",..: 2 2 4 5 5 3 5 5 5 3 ...
## $ Class : Factor w/ 4 levels "VF","F","M","L": 2 1 1 1 1 1 1 1 1 1 ...
# 中心化、标准化、YeoJohnson变换
pp_hpc <- preProcess(schedulingData[, -8],
method = c("center", "scale", "YeoJohnson"))
pp_hpc
## Created from 4331 samples and 7 variables
##
## Pre-processing:
## - centered (5)
## - ignored (2)
## - scaled (5)
## - Yeo-Johnson transformation (5)
##
## Lambda estimates for Yeo-Johnson transformation:
## -0.08, -0.03, -1.05, -1.1, 1.44
# 应用于数据
transformed <- predict(pp_hpc, newdata = schedulingData[, -8])
head(transformed)
## Protocol Compounds InputFields Iterations NumPending Hour Day
## 1 E 1.2289592 -0.6324580 -0.0615593 -0.554123 0.004586516 Tue
## 2 E -0.6065826 -0.8120473 -0.0615593 -0.554123 -0.043733201 Tue
## 3 E -0.5719534 -1.0131504 -2.7894869 -0.554123 -0.034967177 Thu
## 4 E -0.6427737 -1.0047277 -0.0615593 -0.554123 -0.964170752 Fri
## 5 E -0.5804713 -0.9564504 -0.0615593 -0.554123 -0.902085020 Fri
## 6 E -0.5804713 -0.9564504 -0.0615593 -0.554123 0.698108782 Wed
mean(schedulingData$NumPending == 0)
## [1] 0.7561764
# 进行中心化、标准化、YeoJohnson、nzv
pp_no_nzv <- preProcess(schedulingData[, -8],
method = c("center", "scale", "YeoJohnson", "nzv"))
pp_no_nzv
## Created from 4331 samples and 7 variables
##
## Pre-processing:
## - centered (4)
## - ignored (2)
## - removed (1)
## - scaled (4)
## - Yeo-Johnson transformation (4)
##
## Lambda estimates for Yeo-Johnson transformation:
## -0.08, -0.03, -1.05, 1.44
predict(pp_no_nzv, newdata = schedulingData[1:6, -8])
## Protocol Compounds InputFields Iterations Hour Day
## 1 E 1.2289592 -0.6324580 -0.0615593 0.004586516 Tue
## 2 E -0.6065826 -0.8120473 -0.0615593 -0.043733201 Tue
## 3 E -0.5719534 -1.0131504 -2.7894869 -0.034967177 Thu
## 4 E -0.6427737 -1.0047277 -0.0615593 -0.964170752 Fri
## 5 E -0.5804713 -0.9564504 -0.0615593 -0.902085020 Fri
## 6 E -0.5804713 -0.9564504 -0.0615593 0.698108782 Wed
如果你用过tidymodels,那你应该知道里面的数据预处理步骤是通过recipes包完成的,每一步都是step_xx,说实话我觉得caret的这种方式更加简洁易懂!
面向医学生/医生的实用机器学习教程,往期系列推文:

















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









