







Brief introduction for Deep Learning
深度学习3步骤
- 设定神经网络(define a set of function)
- 设定Loss函数(goodness of function)
- 选出最好的函数(pick the best function)
Network parameter
θ
θ
θ:all the weights and biases in the neurons

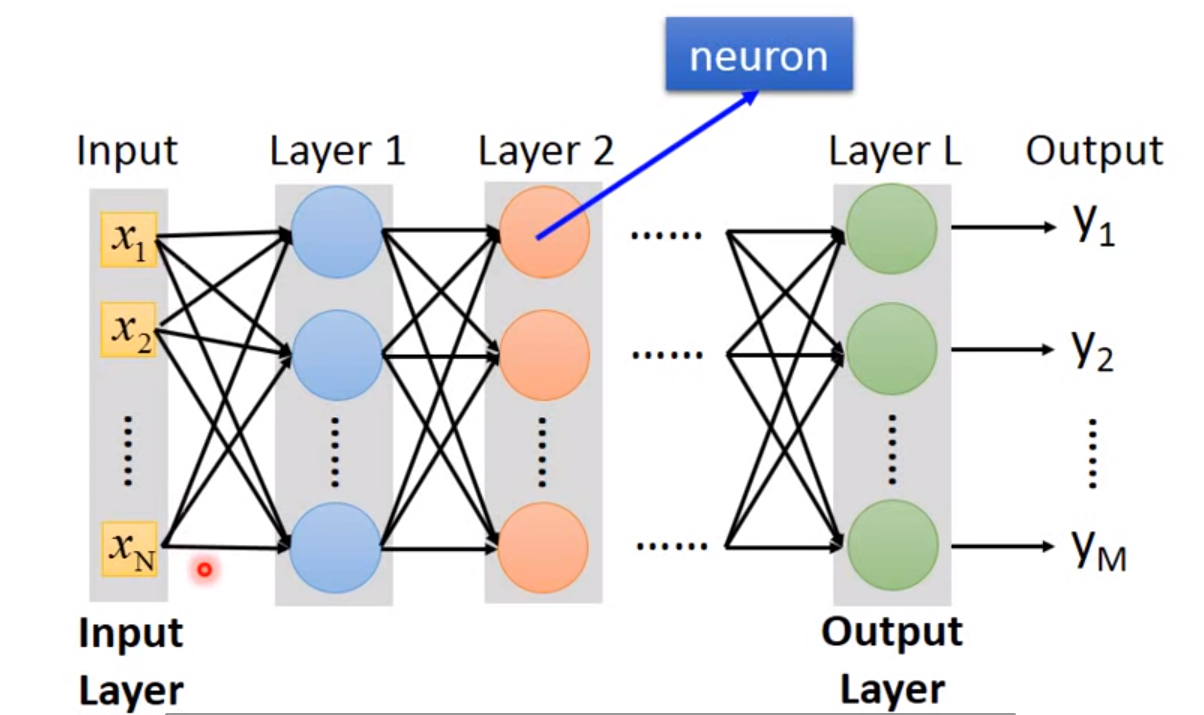
Given network structure,define a function set(还没定参数)
Deep
=
=
=Many hidden layers
Matrix Operation:
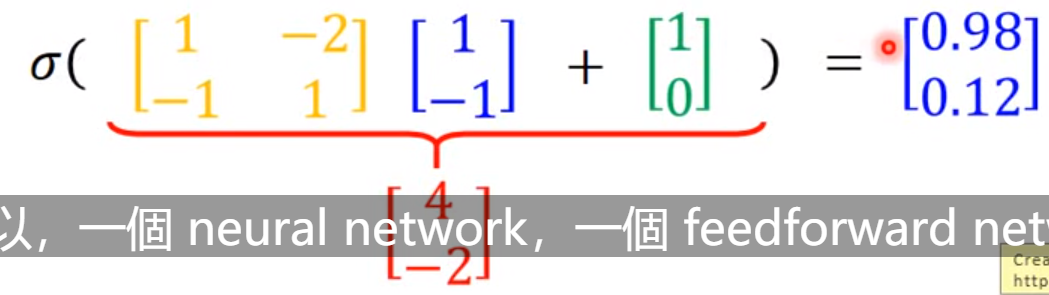
y
=
f
(
x
)
=
σ
(
w
L
.
.
.
σ
(
w
2
σ
(
w
1
⋅
x
+
b
1
)
+
b
2
)
.
.
.
+
b
L
)
y=f(x)=σ(w_L...σ(w_2 σ(w_1·x+b_1)+b_2)...+b_L)
y=f(x)=σ(wL...σ(w2σ(w1⋅x+b1)+b2)...+bL)
将Neural Network 用矩阵乘法表示,所以就可以用GPU优化加速。
How many layers?How many neurons for each layer?
- Trial and Error + Intuition 经验+直觉
Can the structure be automatically determined?
- 可以,但技术不成熟,尚未普及
Can we design the network structure?
- 可以,如:Convolutional Neural Network
Loss for an Example
用 Cross entropy:
C
(
y
,
y
^
)
=
−
∑
i
=
1
10
y
^
i
l
n
y
i
,
L
=
∑
n
=
1
N
C
n
C(y,\widehat{y})=-\sum_{i=1}^{10}{\widehat{y}_ilny_i},L=\sum_{n=1}^{N}{C_n}
C(y,y
)=−∑i=110y
ilnyi,L=∑n=1NCn
Find a fucntion is function set that minimize total loss
L
L
L
Find the network parameters
θ
∗
θ^{*}
θ∗ that minimize total loss
L
L
L
方法:还是Gradient Descent
Backpropagation算法:an efficient way to compute
α
L
α
w
\frac{αL}{αw}
αwαL in neural network
就是使用工具包
Universality Theorem
Any continuous function f
f
:
R
N
→
R
M
f:R^N \rightarrow R^M
f:RN→RM
Can be realized by a network with one hidden layer(given enough hidden neurons)















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









