






每秒处理30000个token,简直令人惊叹!
就在刚刚举行的2025 GTC大会上,英伟达宣布了一项震撼世界的技术突破——满血版DeepSeek-R1的推理性能达到了史无前例的新高度,一举刷新了行业纪录!
DGX 系统凭借八颗 NVIDIA Blackwell GPU 的强大助力,在 6710 亿参数的 DeepSeek-R1 模型推理任务中,取得了令人瞩目的成绩,刷新了世界纪录。具体来看,单用户推理速度达到每秒 250 个 token 以上,峰值吞吐量更是超过每秒 30000 个 token。
这一前所未有的性能飞跃,离不开针对NVIDIA Blackwell架构深度优化的开放生态推理开发工具链的支持。然而,这仅仅是个开始。
随着NVIDIA平台不断挖掘Blackwell Ultra GPU及Blackwell GPU架构的极限潜能,推理性能的边界将一次次被突破,未来还将迎来更多令人惊叹的可能性!
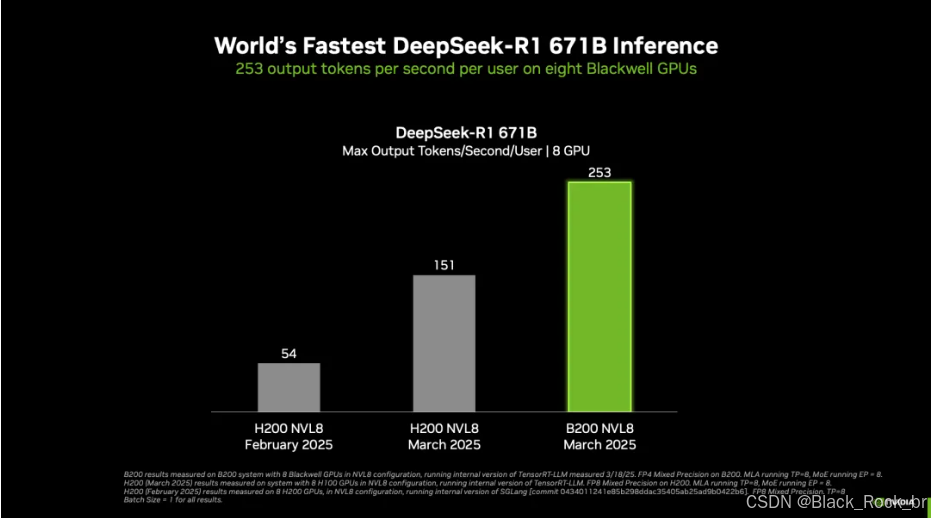
图1. 在NVL8配置下运行TensorRT-LLM软件的NVIDIA B200 GPU,在满血DeepSeek-R1 671B模型上实现了每秒每位用户最高的已发布token生成速度。
-
DGX B200 与 DGX H200 系统性能对决
-
测试时间点 :DGX B200 系统的测试数据是在 3 月获取的,DGX H200 系统的数据则是在 2 月得到的。测试过程中,均借助了内部版本的 TensorRT - LLM 工具。
-
测试条件细节 :3 月的测试中,输入长度为 1024 个 token,输出长度为 2048 个 token;而在 1 月和 2 月的测试里,输入和输出长度均为 1024 个 token。
-
测试设置 :将并发度定为 1。B200 系统在测试时使用 FP4 精度,而 H100 和 H200 系统则采用 FP8 精度进行测试。
-
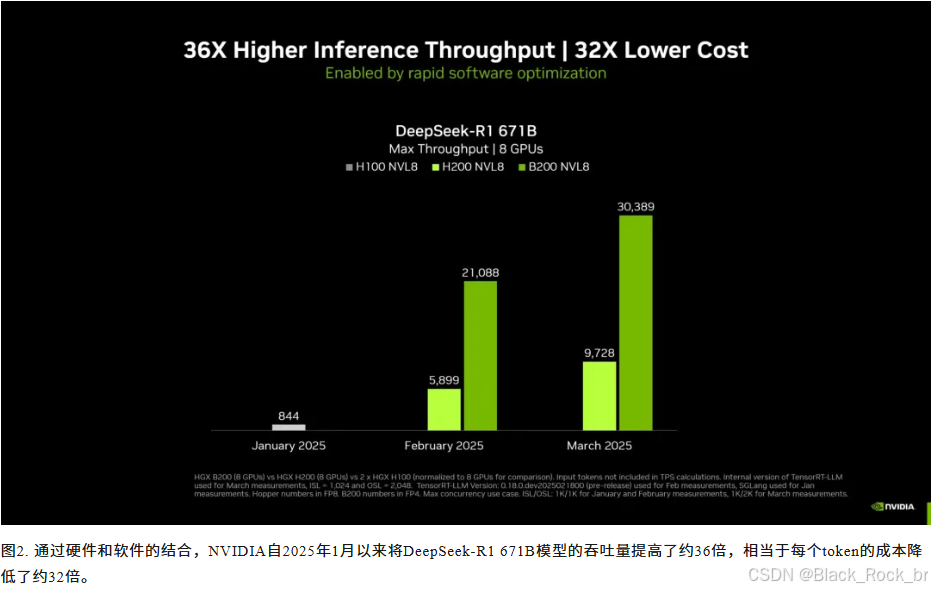
最大吞吐量对比(基于标准化的8颗GPU系统配置):
测试对象包括单台DGX B200(配备8颗GPU)、单台DGX H200(配备8颗GPU),以及两台DGX H100(每台配备8颗GPU,共计16颗GPU)。所有测试数据均来自内部版本的TensorRT-LLM工具。
测试细节如下:
- 3月测试:输入长度为1,024个token,输出长度为2,048个token。
- 1月和2月测试:输入与输出长度均为1,024个token。
测试条件设定为:
- 并发度调至最大值(MAX)。
- DGX B200采用FP4精度,而DGX H200和DGX H100则使用FP8精度进行测试。
NVIDIA凭借全球最大的推理生态系统,为开发者提供了灵活构建AI解决方案的能力,无论是追求极致用户体验还是最大化效率,都能轻松满足。这一生态系统不仅包含NVIDIA官方的开源工具,还汇聚了社区的丰富贡献,共同释放Blackwell架构和软件技术的全部潜力。
Blackwell架构带来了显著性能提升,包括:
- 第五代Tensor Core支持FP4精度加速,AI算力较前代提升高达5倍;
- 第五代NVLink及NVLink Switch技术,带宽较前代翻倍;
- 支持更大规模的NVLink网络扩展能力。
这些创新推动了前沿大模型(如DeepSeek-R1)在高吞吐量和低延迟推理中的卓越表现。然而,硬件的强大离不开优化的软件支持。NVIDIA通过持续优化芯片、系统、库和算法等技术栈的每一层,确保当前任务高效运行,同时为未来挑战做好准备。
以下是NVIDIA推理生态系统的最新更新,涵盖的关键软件组件包括:
- NVIDIA TensorRT-LLM
- NVIDIA TensorRT
- TensorRT Model Optimizer
- CUTLASS
- NVIDIA cuDNN
- 主流AI框架(PyTorch、JAX、TensorFlow等)
此外,英伟达分享了最新的性能与精度数据,这些数据基于搭载8颗Blackwell GPU并使用双NVLink Switch互联的NVIDIA DGX B200系统实测得出。
TensorRT生态系统:为NVIDIA Blackwell量身打造的优化工具链
NVIDIA TensorRT生态系统专为开发者提供全面支持,帮助在NVIDIA GPU上实现高效的推理部署。该生态包含一系列深度优化的工具和库,覆盖从模型预处理、加速优化到生产环境部署的全流程,特别针对最新的Blackwell架构进行了定制化优化。相比上一代Hopper架构,Blackwell在推理性能上实现了显著提升。
---
第一步:模型优化利器——TensorRT Model Optimizer
TensorRT Model Optimizer是推理优化的关键起点,提供了多种先进的技术来提升模型效率,包括:
- 量化(Quantization)
- 蒸馏(Distillation)
- 剪枝(Pruning)
- 稀疏化(Sparsity)
- 推测解码(Speculative Decoding)
最新发布的0.25版本新增对Blackwell架构FP4精度的支持,适用于训练后量化(PTQ)和量化感知训练(QAT)。这不仅提升了推理吞吐量,还显著降低了内存消耗。
---
高性能推理框架:TensorRT-LLM
完成模型优化后,TensorRT-LLM成为高效运行大模型推理的核心工具。它为开发者提供了丰富的功能,支持实时、高性价比且高能效的大模型推理。
最新版本0.17针对Blackwell架构进行了深度优化,充分利用其指令集、内存层次结构和FP4精度。基于PyTorch的TensorRT-LLM通过高性能内核和先进运行时特性,如动态批处理(in-flight batching)、KV缓存管理和推测解码,大幅提升了推理性能。
---
主流框架与社区支持
目前,主流深度学习框架如PyTorch、JAX和TensorFlow均已升级,全面支持Blackwell架构的训练与推理。同时,社区热门的LLM服务框架(如vLLM和Ollama)也已完成适配,其他框架的支持也在快速跟进中。
---
性能飞跃:Blackwell + TensorRT的强大组合
得益于Blackwell架构的硬件优势和TensorRT软件栈的协同优化,推理性能较上一代Hopper架构大幅提升。核心驱动力来自更高的计算能力、更大的内存带宽以及深度优化的软件栈。
以当前热门大模型为例,在DGX B200平台上使用TensorRT推理软件和FP4精度,DeepSeek-R1、Llama 3.1(405B参数)和Llama 3.3(70B参数)等模型的推理吞吐量已超过DGX H200平台的3倍以上,展现出卓越的性能表现。
---
这一软硬件结合的生态系统,为AI推理任务提供了前所未有的速度与效率,为未来更复杂的应用场景奠定了坚实基础。
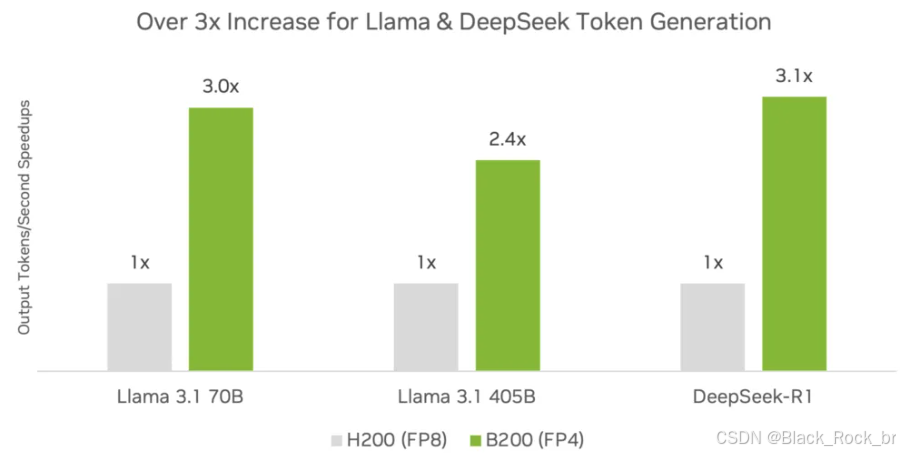
图3. 使用搭载NVIDIA Blackwell GPU的NVIDIA HGX B200以及FP4,与上一代运行FP8的GPU相比,Llama 3.1 70B、Llama 3.1 405B和DeepSeek-R1的推理吞吐量(tokens/sec)提升情况。
以下为初步规格,可能会有所调整。
关键软件版本与配置
- TensorRT 模型优化器:v0.23.0
- TensorRT-LLM:v0.17.0
- 最大批量大小:2048(实际批量大小通过 TensorRT-LLM 的动态批处理功能 Inflight Batching 实时调整)
- H200 配置:FP16/BF16 GEMM + FP8 KV 缓存
- B200 配置:FP4 GEMM + FP8 KV 缓存
在上述配置下,吞吐量显著提升,具体测试模型及参数如下:
- Llama 3.3 70B:输入序列长度(ISL)2048,输出序列长度(OSL)128
- Llama 3.1 405B:输入序列长度(ISL)2048,输出序列长度(OSL)128
- DeepSeek-R1:输入序列长度(ISL)1024,输出序列长度(OSL)1024
低精度量化对精度的影响
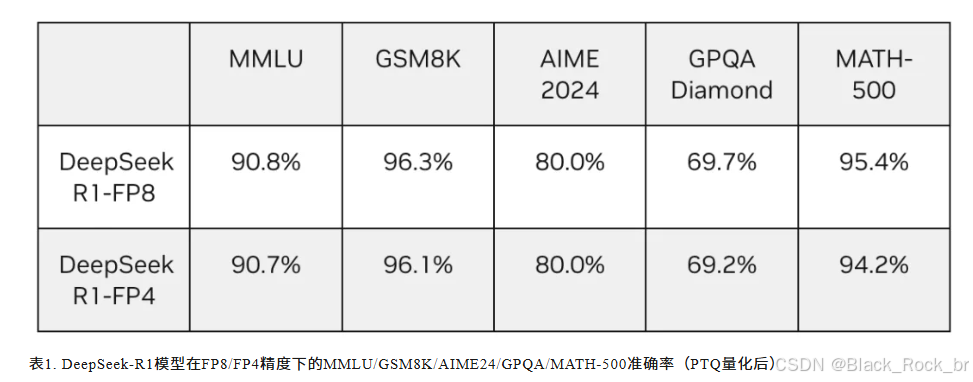
在将模型量化以利用低精度计算优势时,确保最小的精度损失是生产部署的关键。针对 DeepSeek-R1,TensorRT 模型优化器采用 FP4 训练后量化(PTQ),在多种数据集上的测试结果显示,其精度损失相较于 FP8 基线非常有限,如表 1 所示。这一结果充分验证了 FP4 量化在性能与精度之间的出色平衡能力。
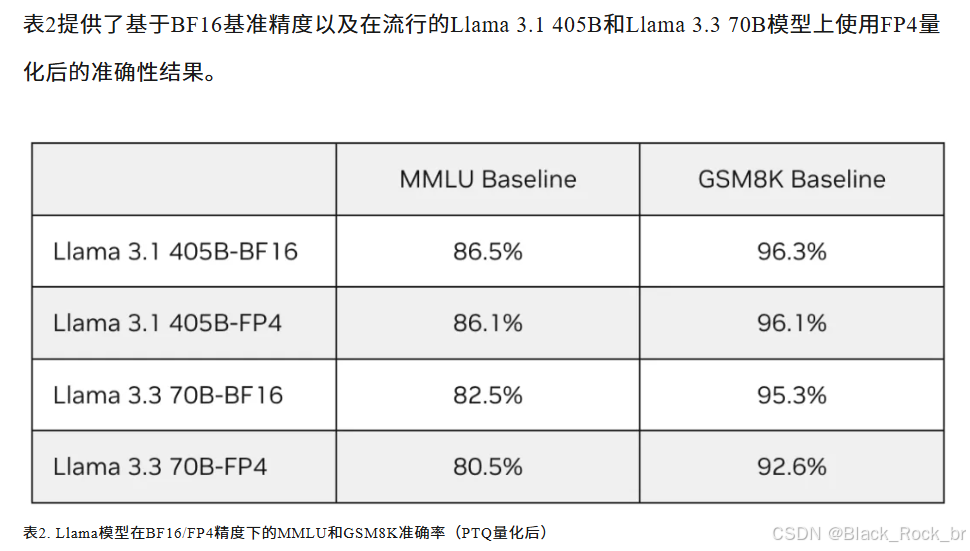
-
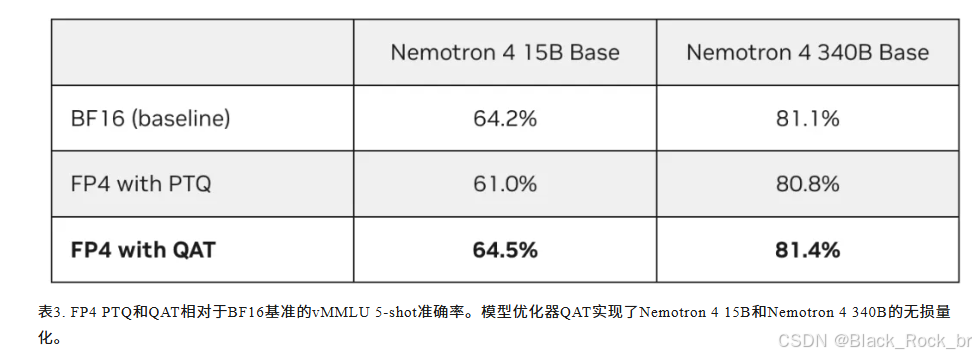
当采用低精度(如 FP4)进行部署时,若能够获取微调数据集,便可运用量化感知训练(QAT)来恢复精度。为彰显 QAT 的价值,借助 TensorRT 模型优化器,将 NVIDIA Nemotron 4 15B 和 Nemotron 4 340B 模型通过 QAT 量化为 FP4,与 BF16 基准对比,实现了无损的 FP4 量化(详见表 3)。
使用TensorRT与TensorRT Model Optimizer的FP4精度提升Blackwell平台图像生成效率
此前,NVIDIA的TensorRT和TensorRT Model Optimizer通过INT8和FP8等8比特量化技术,显著提升了扩散模型(Diffusion Models)在图像生成任务中的性能。如今,随着NVIDIA Blackwell架构与FP4精度的引入,AI图像生成效率再次迎来质的飞跃。
这一性能提升不仅惠及数据中心和专业平台,还延伸至搭载NVIDIA GeForce RTX 50系列GPU的个人AI电脑(AI PC),让用户能够在本地快速生成高质量图像。
由Black Forest Labs推出的Flux.1模型系列是业内领先的文本到图像(Text-to-Image)生成模型,以其卓越的文本提示遵循能力和复杂场景生成能力著称。开发者现可通过Black Forest Labs在Hugging Face上提供的模型库下载FP4量化的Flux模型,并直接使用TensorRT进行部署。这些FP4量化模型由Black Forest Labs团队基于TensorRT Model Optimizer的FP4工作流和优化配方生成。
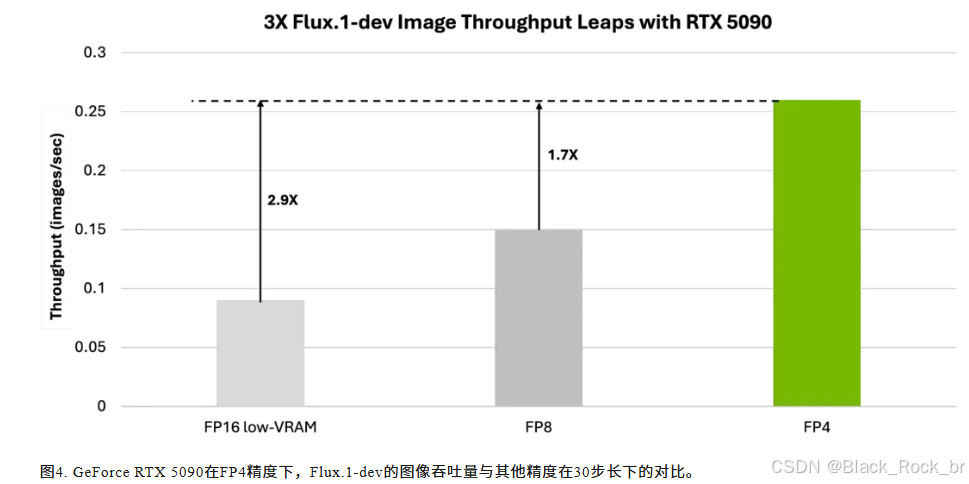
为了展示FP4精度对Blackwell平台图像生成性能的提升,Flux.1-dev模型在FP4精度下的表现相较于FP16实现了以下突破:
- 图像生成吞吐量(每秒生成图像数)最高提升3倍;
- 显存(VRAM)占用量最高压缩5.2倍;
- 在性能大幅提升的同时,生成图像的质量依然保持不变(详见表4)。
这一成果充分体现了FP4精度在效率与质量之间的出色平衡,为AI图像生成领域树立了新的标杆。
在Flux.1-dev模型中,仅Transformer主干部分采用FP4精度量化,其余部分仍保持BF16精度。
此外,TensorRT的DemoDiffusion工具提供了一种低显存(low-VRAM)模式。在该模式下,T5、CLIP、VAE以及FLUX Transformer模型会按需加载,并在任务完成后立即卸载。这种方式确保FLUX模型的峰值显存占用不超过任一子模型的最大需求,但加载和卸载的过程会增加一定的推理延迟。
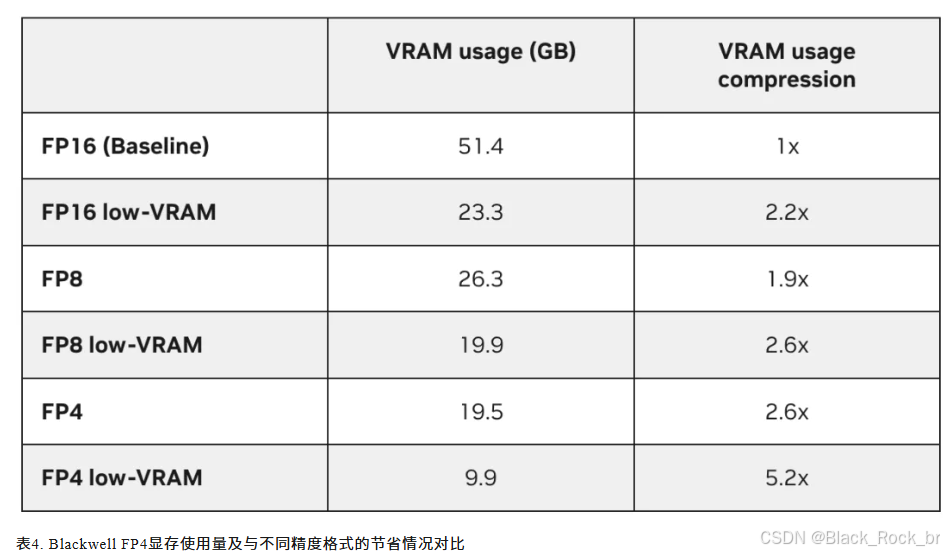
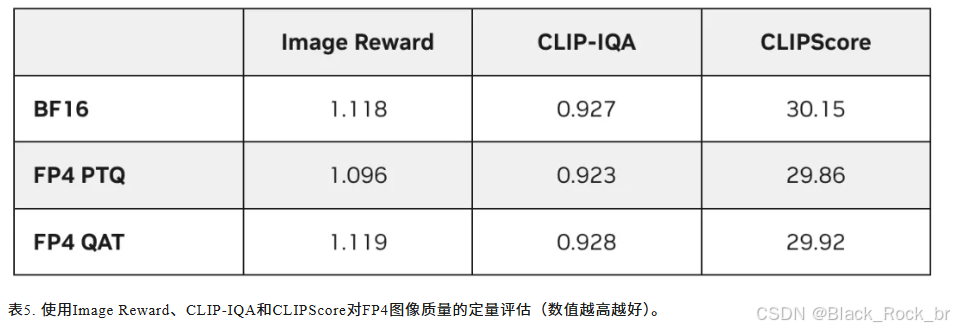
图5展示了使用FP4精度量化Flux模型生成的示例图像。对比BF16基准模型,在相同提示词下,生成图像的质量和内容保持一致。表5通过量化评估1000张生成图像,进一步验证了FP4模型在图像质量、相关性及视觉吸引力方面的优异表现。图5中示例图像对应的提示词如下↓


 Flux.1-dev模型性能测试说明
Flux.1-dev模型性能测试说明
- 测试配置:Flux.1-dev模型,推理步数为30步,生成1,000张图像,使用TensorRT Model Optimizer v0.23.0的FP4量化配方。
- 模拟环境:测试于2025年1月24日在NVIDIA H100 GPU上完成。在TensorRT内核层面,模拟结果与RTX 5090的表现数学上一致,但实际运行RTX 5090时可能因硬件差异存在细微分数波动。
TensorRT 10.8更新:性能与兼容性全面提升
TensorRT 10.8版本现已全面支持Flux.1-Dev和Flux.1-Schnell模型在高端GeForce RTX 50系列GPU上实现FP4精度的峰值性能。同时,新增的`--low-vram`(低显存)模式使得显存有限的设备(如GeForce RTX 5070)也能流畅运行这些模型,显著降低了硬件门槛。
此外,TensorRT 10.8还新增对Black Forest Labs提供的Depth和Canny Flux ControlNet模型的支持。开发者可立即通过TensorRT自带的`demo/Diffusion`工具体验这些新功能,进一步拓展AI图像生成的应用场景。
cuDNN深度学习原语全面优化支持Blackwell架构
自2014年推出以来,NVIDIA cuDNN库始终是GPU加速深度学习的核心组件。通过高度优化的基础原语,cuDNN助力PyTorch、TensorFlow和JAX等主流框架实现行业领先的性能,并贯穿训练与推理全流程。
随着cuDNN 9.7版本发布,Blackwell架构的支持已扩展至数据中心和GeForce系列产品线。开发者将现有cuDNN算子迁移到Blackwell的新一代Tensor Core后,性能显著提升。新版库提供优化的通用矩阵乘法(GEMM)API,充分利用Blackwell在FP8和FP4区块缩放操作上的优势,简化底层复杂性,让开发者专注于创新。
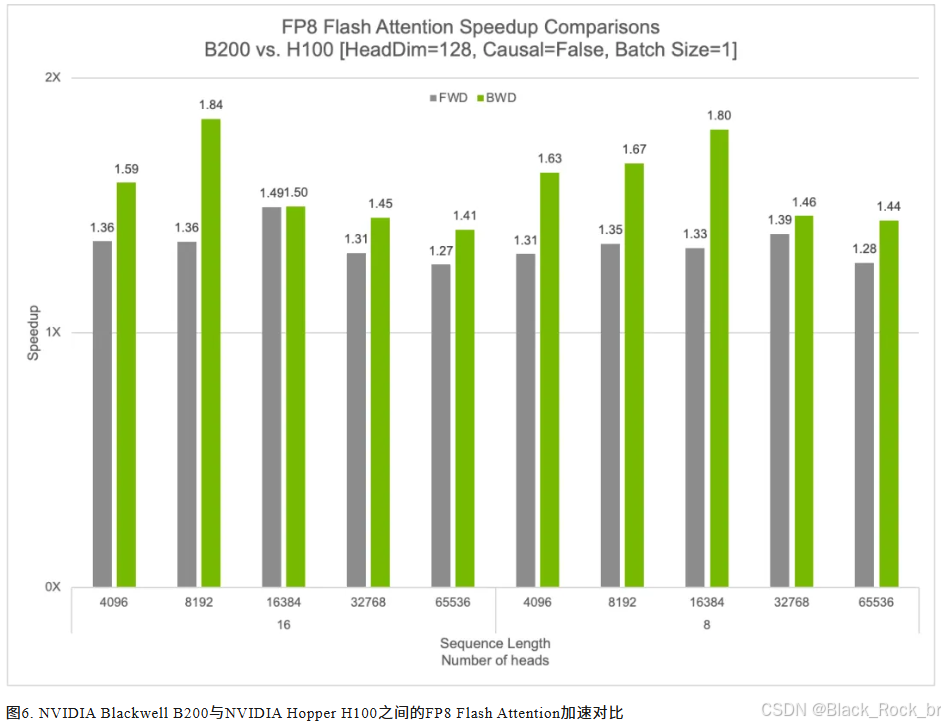
针对FP8精度的Flash Attention操作,Blackwell架构下的cuDNN实现了显著性能提升:
- 前向传播性能提升高达50%;
- 反向传播性能提升更高达84%。
此外,cuDNN还为Blackwell架构引入了高效的算子融合能力,进一步优化GEMM操作。未来,cuDNN将持续扩展算子融合支持,推动深度学习工作负载性能迈向新高度。
借助CUTLASS打造高性能的Blackwell架构CUDA内核
自2017年首次推出以来,CUTLASS一直是研究人员和开发者在NVIDIA GPU上实现高性能CUDA内核的重要工具。
CUTLASS通过提供丰富的工具集,帮助开发者高效设计针对NVIDIA Tensor Core的自定义计算操作,例如通用矩阵乘法(GEMM)和卷积(Convolution)等,使硬件感知算法(Hardware-aware Algorithms)的开发变得更加高效。
这推动了FlashAttention等创新算法的出现,也确立了CUTLASS在GPU加速计算领域的重要地位。
此次CUTLASS 3.8版本的发布,全面增加了对NVIDIA最新Blackwell架构的支持,帮助开发者充分利用新一代Tensor Core所支持的所有新数据类型,包括最新的窄精度MX数据格式以及NVIDIA自研的FP4精度。
这一更新将使开发者能更有效地为自定义算法和生产工作负载进行性能优化,充分释放加速计算的最新潜力。
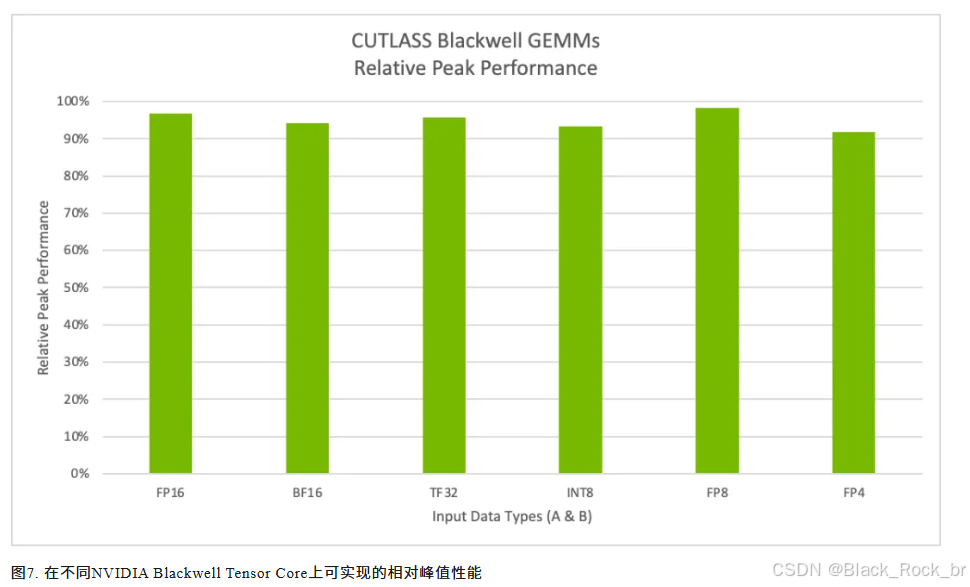
如图7所示,借助CUTLASS,我们在Tensor Core计算操作上的性能表现已经达到相对峰值性能的98%。
测试环境与CUTLASS新功能介绍
测试在B200系统上进行,参数设置为M=K=16384,N=17290。最新版本的CUTLASS为Blackwell架构引入了多项热门功能,进一步提升计算效率:
- Grouped GEMM(分组GEMM):能够高效并行处理多个“专家”计算,显著加速混合专家(MoE)模型的推理过程。
- Mixed Input GEMM(混合输入GEMM):支持量化内核,有效降低大型语言模型(LLM)权重对GPU显存的占用,提高资源利用效率。
此外,Blackwell架构还获得了OpenAI Triton编译器的支持,进一步增强了其性能优化能力。
总结:
NVIDIA Blackwell架构融合了多项前沿技术,显著提升了生成式 AI 推理性能,比如第二代 Transformer Engine 和 FP4 Tensor Core、第五代 NVLink 与 NVLink Switch 技术。凭借这些优势,NVIDIA DGX 系统(搭载 8 颗 Blackwell GPU)在 DeepSeek - R1 模型推理测试中打破世界纪录,单用户推理速度超每秒 250 个 token,最大吞吐量超每秒 3 万个 token。

















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









