






构建了一个简单的四层神经网络,然后把数据集送入到网络进行训练,最后在测试,得到结果如下: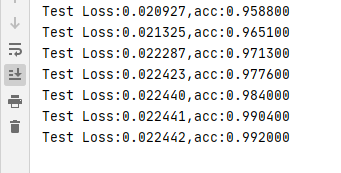
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
from torch import optim
import os
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms # 导入库以及工具包
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
batch_size = 64
learning_rate = 0.001
num_epoches = 30 # 定义参数
data_tf = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]) # 对数据集进行处理,将图片转换成tensor类型并且归一标准化
#
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 通过python内部程序dataloader下载MNIST手写字体数据集
class CNN(nn.Module): # 定义一个神经网络,作为识别分类
def __init__(self):
super(CNN, self).__init__() # 初始化模型
self.layer1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=3),
nn.BatchNorm2d(16),
nn.ReLU(True)) # 构造第一层网络(16,26,26)
self.layer2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=3),
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2)) # 构造第二层网络(32,12,12)
print()
self.layer3 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(True)) # 构造第三层网络(32,10,10)
self.layer4 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2)) # 构造第三层网络(64,4,4)
self.fc = nn.Sequential(nn.Linear(128 * 4 * 4, 1024),
nn.ReLU(True),
nn.Linear(1024, 128),
nn.ReLU(True),
nn.Linear(128, 10))
def forward(self, x): # 前向传播过程
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x
model = CNN() # 加载模型并输出参数
criterion = nn.CrossEntropyLoss() # 构造损失函数为交叉熵
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9) # 定义优化器,设置学习率以及动量
for epoch in range(num_epoches): # 开始训练,进行迭代
for tr_data in train_loader: # 开始将训练集中的数据送入模型中
train_img, train_label = tr_data
train_img = train_img.view(train_img.size(0), -1)
with torch.no_grad():
train_img = Variable(train_img)
train_label = Variable(train_label)
train_img = train_img.reshape([-1,1,28,28])
out = model(train_img)
loss = criterion(out, train_label)
print_loss = loss.item()
optimizer.zero_grad() # 先归零梯度
loss.backward() # 反向传播
optimizer.step() # 进行步长
if (epoch + 1) % 10 == 0: # 显示训练过程
print('*' * 10)
print('epoch{}'.format(epoch + 1))
print('loss:{:.4f}'.format(print_loss))
model.eval() # 调用函数开始训练
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data # 开始测试过程
img = img.view(img.size(0), -1)
with torch.no_grad():
img = Variable(img)
label = Variable(label)
img=img.reshape([-1,1,28,28])
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print(
'Test Loss:{:.6f},acc:{:.6f}'.format(eval_loss / (len(test_dataset)), eval_acc / (len(test_dataset)))) # 输出最后结果















 7665
7665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









