






放一个学习连接:https://learn.microsoft.com/zh-cn/azure/machine-learning/how-to-train-distributed-gpu
1 单机单卡
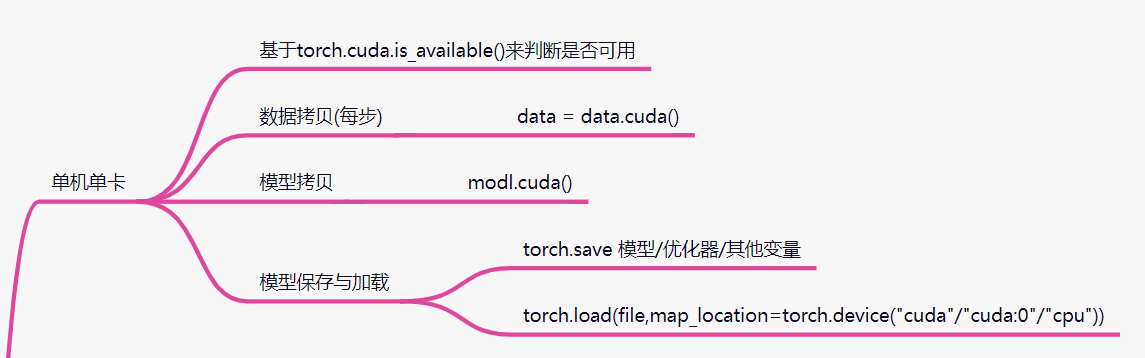
# 单机单卡 代码示例
# 1 判断cuda是否可用
if torch.cuda.is_available():
# 2 设置卡 只对"0"卡可见
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
else:
return
# 3 模型拷贝 原地操作
model.cuda()
# 4 数据拷贝 非原地操作 返回新设备的对象
# 不是cuda的方法 其实是tensor的方法
data = data.cuda()
# 加载
# cpu
ckpt = torch.load(resume)
# cuda
ckpt = torch.load(resume,map_location=torch.device("cpu"))
ckpt = torch.load(resume,map_location=torch.device("cuda:0"))
2 单机多卡

2.1 torch.nn.DataParallel
缩写:DP;
DP已经淘汰,现在大部分用DDP(见2.2);
DP缺点:
- 单进程 效率慢;
- 不支持多机情况;
- 不支持模型并行(只支持数据);

注意:
- 此处的batch_size应该是每个GPU的batch_size的总和;
- 比如2个GPU data_loader应该设置为2倍;
BATCH_SIZE = 64 * 4
# 单机多卡
# 1判断cuda是否可用
if torch.cuda.is_available():
# 2判断是否有多卡
if torch.cuda.device_count() > 1:
print()
else:
return
else:
return
# 3设置卡 对多卡可见
nn.DataParallel(model.cuda(), device_ids = [0,1,2,3])
# 4数据拷贝 非原地操作 返回新设备的对象
# 不是cuda的方法 其实是tensor的方法
data = data.cuda()
# 保存
# cpu
model.state_dict()
# 多卡
model.module.state_dict()
# 加载
# cpu gpu
ckpt = torch.load(resume,map_location=torch.device("cuda:0"))
model.load_state_dict()
2.2 torch.nn.parallel.DistributedDataParallel
缩写:DDP;
多进程
NCCL通信方式(见5);
world_size:几张卡;
rank:节点(哪个机子 单卡默认为0);

注意:
- train.py中要有接受local_rank的参数选项,launch会传入这个参数;
- 每个进程的batch_size应该是一个GPU所需要的batch_size;
- 在每个周期开始处 调用train_sampler.set_epoch(epoch)可以是的数据充分打乱;
- 有了sampler, DataLoader中不用设置shuffle;
# 从命令行接受参数
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", help="local device id on curr node",type=int)
args = parser.parse_args()
if torch.cuda.is_available():
# 2判断是否有多卡
if torch.cuda.device_count() > 1:
print()
else:
return
else:
return
# 初始化一个进程组
n_gpus = 2
torch.distributed.init_process_group("nccl",world_size=n_gpus,rank=args.local_rank)
# 指定卡
torch.cuda.set_device(args.local_rank)
# 模型拷贝 放入DDP
model = nn.parallel.DistributedDataParallel(model.cuda(local_rank),device_ids = local_rank)
# 创建train_sampler
train_sampler = DistributedSampler(train_dataset)
train_data_loader = torch.util.data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
sampler=train_sampler
)
# 每epoch修改
# 为了让每张卡在每个周期中得到的数据是随机的
train_sampler.set_epoch(epoch_index)
# 数据拷贝
data = data.cuda(local_rank)
# 保存 local_rank=0上保存
# 加载
# 运行
python -m torch.distributed.launch --nproc_per_node=n_gpus train.py
3 多机多卡
torch.nn.parallel.DistributedDataParallel

node_rank:区分是哪个机子;
python -m torch.distributed.launch
--nproc_per_node=n_gpus
--nnodes=2
--node_rank=0
--master-addr="主节点IP"
--master_port=主节点端口 train.py
python -m torch.distributed.launch
--nproc_per_node=n_gpus
--nnodes=2
--node_rank=1
--master-addr="主节点IP"
--master_port=主节点端口 train.py
4 模型并行
当模型的参数太大,单个GPU无法容纳,需要将模型的不同层拆分到不同GPU上;
官网文档:https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html;
举个例子:
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self):
# net1和net2放入不同GPU训练
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
5 分布式训练底层原理
5.1 分布式原理
分布式训练:在多个机器上一起训练模型,提高训练效率。
- 模型并行:将一个大型模型拆分成小模型,分别放在不同的设备上,每个设备运行模型的一部分(效率很低,需要不同设备模型之间的频繁通信);
- 数据并行:完整的模型在每个机器上都有,但是把数据分成多份给每个模型,每个模型输入不同的数据进行训练(最常见的);
5.2 Tensorflow:Parameter Server架构
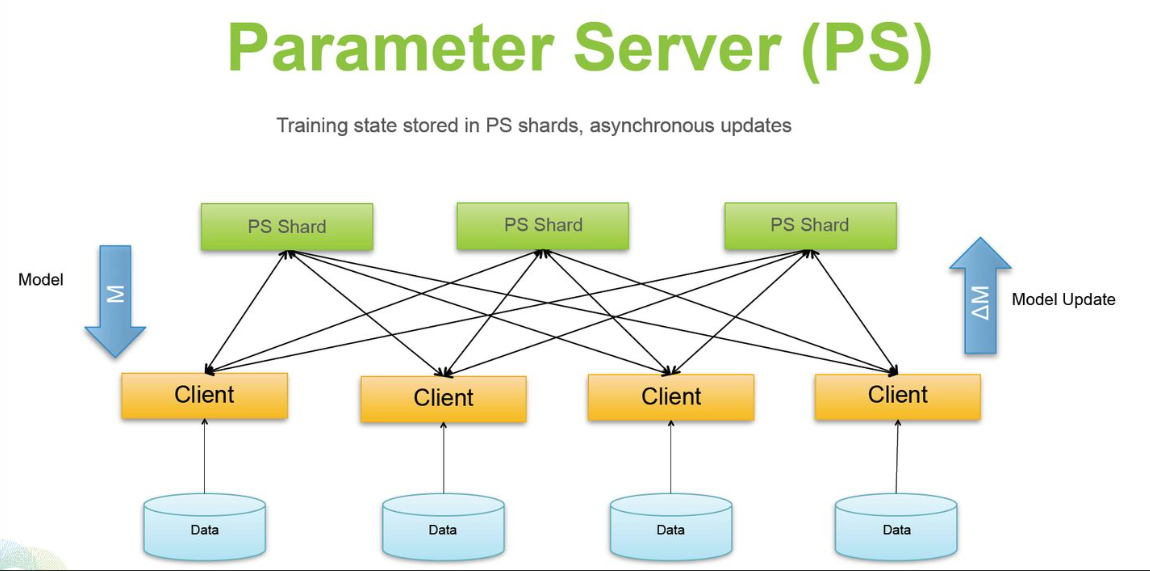
Parameter Server架构包含一到多个server节点,多个worker节点;
server节点保存模型参数,如果有多个server节点会把模型参数保存多份到多个server上;
特点:随着worker数量增加,模型的运行效率并不是线性提升的(worker的增加导致worker与server通信时长增加);
worker负责使用server上的参数以及本worker上的数据计算梯度;
训练过程:
- 1:每个worker从server上拷贝完整的模型参数;
- 2:每个worker用本worker上的数据在这份参数上计算梯度;
- 3:每个worker将计算的结果回传给server,server进行参数更新;
实现方式:
- 1:异步更新
- 每个设备上自己进行训练,不用等其他设备,自己训练完一个step得到梯度,传回给server后,server就直接用这个梯度更新模型参数;
- 效率高 可能出现无效梯度导致模型效果不好(精度下降);
- 2:同步更新
- 等到所有worker都回传了梯度后,才进行参数更新,强保障了各个worker计算梯度时参数的一致性,不会出现无效梯度问题;
- 效率低 同步阻塞问题(精度高);
5.3 Pytorch:Ring AllReduce架构
详情见:Ring Allreduce - 简书 (jianshu.com);
特点:运行效率随着worker数量的增加线性增加;
Ring AllReduce架构中没有server,都是worker,所有worker组成一个环形,每个worker和另外两个worker相连。每个worker都只和相邻的两个worker进行信息传递。每个worker上都有一份完整的模型参数,并进行梯度计算和更新。
训练过程(假设5个worker):
- 1:scatter reduce;
- 将每个设备上计算出来的梯度分割成5等份,通过worker之间的5次通信,让每个worker上都有一部分参数的梯度是完整的;
- 2:allgather;
- 让所有worker上的所有网络参数的梯度都是上一步中某个worker上完整的梯度。这里需要再次进行4次信息传递,把每个worker上各自梯度完整的部分传播到其他worker上;
6 NCCL
NCCL全称NVIDIA Collective Communication Library;
NCCL的聚合通信接口采用异步调用的方式(通过stream来实现),接口调用后立即返回,用户需要调用cudaStreamSynchronize等待聚合通信完成。
NCCL聚合通信包括以下接口:
- AllReduce
- 对所有GPU上的目标数据进行reduce操作(例如sum,max),并将结果写到所有的GPU上 ;
- Broadcast
- 将root GPU上的数据发送到所有GPU上,其中root可以由用户进行指定;
- Reduce
- 对所有GPU的数据进行reduce操作(例如sum,max),并将结果写到用户指定的GPU上;
- AllGather
- 集合所有GPU上的数据,并将集合后的数据写到所有的GPU上;
- ReduceScatter
- 对所有GPU上的数据进行reduce操作(如sum max),然后将结果切分到所有的GPU上;
- Scatter
- Gather
- All-to-All















 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









