









现在我们要让计算机去跑系数,而不是自己设定,于是我们想到了梯度下降
关于梯度下降,参考:https://blog.csdn.net/CSDNXXCQ/article/details/113871648
关于随机梯度下降,简单来说就是b = b+learning-rate*(y-yp)yp(1-yp)*x,参考:https://blog.csdn.net/CSDNXXCQ/article/details/113527276
里面的例子都是针对单个的,推广成递推式有:
yp→y_prediction
b0(t+1) = b0(t) +learning_rate * (y(t)-yp(t))* yp(t)* (1-yp(t))
b1(t+1) = b1(t) +learning_rate * ( y(t)-yp(t))* yp(t)* (1-yp(t)) * x1(t)
error = prediction - expected
问题来了yp(t)* (1-yp(t)是哪来的呢
先看一个引子
Sigmoid(其实就是逻辑回归函数):

它对0与1的分类效果如图:
y越接近1就越认为是1类

对sigmod进行求导
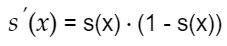
现在对比下刚刚提到的推广公式:
yp→y_prediction
b0(t+1) = b0(t) +learning_rate * (y(t)-yp(t))* yp(t)* (1-yp(t))
b1(t+1) = b1(t) +learning_rate * ( y(t)-yp(t))* yp(t)* (1-yp(t)) * x1(t)
error = prediction - expected
现在使用随机梯度下降去跑/计算系数
算法的一般运行流程
1,epochs(时代/学习周期)→模型通过不断地运行(学习)→不断的更新coefficient(系数)→更好地拟合数据
即b=b-learningrate* error * x
2把所有地epoch(学习周期,注意,每个epoch里会有相应的训练集)进行loop(循环迭代)
3每一次系数(coefficient)循环都会进行系数调优
构建随机梯度下降函数:
def using_sgd_method_to_calculate_coefficients(training_dataset, learning_rate, n_times_epoch):
coefficients = [0.0 for i in range(len(training_dataset[0]))]
for epoch in range(n_times_epoch):
the_sum_of_error = 0
for row in training_dataset:
y_hat = prediction(row, coefficients)
error = row[-1] - y_hat
the_sum_of_error += error ** 2
coefficients[0] = coefficients[0] + learning_rate * error * y_hat * (1.0 - y_hat)
for i in range(len(row) - 1):
coefficients[i + 1] = coefficients[i + 1] + learning_rate * error * y_hat * (1.0 - y_hat) * row[i]
print("This is epoch 【%d】,the learning rate we are using is 【%.3f】,the error is 【%.3f】" % (
epoch, learning_rate, the_sum_of_error))
return coefficients
learning_rate = 0.1
n_times_epoch = 1000
coef = using_sgd_method_to_calculate_coefficients(dataset, learning_rate, n_times_epoch)
print(coef)
运行结果:

















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











