






嘿,大家好!这里是一个专注于AI智能体的频道~
今天分享这篇很干的文章!通过对RAG系统的用户Query进行难度区分,进而可以将系统划分为4个等级。
Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
使用外部数据增强的大型语言模型 ( LLMs ) 在完成现实世界任务方面表现出了卓越的能力。外部数据不仅增强了模型的特定领域专业知识和时间相关性,而且还减少了幻觉的发生率,从而增强了输出的可控性和可解释性。将外部数据集成到LLMs中的技术,例如检索增强生成(RAG)和微调,正在获得越来越多的关注和广泛应用。尽管如此,在各个专业领域有效部署数据增强LLMs仍面临着巨大的挑战。这些挑战涵盖了广泛的问题,从检索相关数据和准确解释用户意图到充分利用LLMs的推理能力来完成复杂的任务。我们相信,对于数据增强LLM应用程序来说,没有一种万能的解决方案。在实践中,效果不佳通常是由于未能正确识别任务的核心焦点,或者因为该任务本质上需要混合多种功能,必须将这些功能分解以获得更好的解决方案。在本次调查中,我们提出了一种 RAG 任务分类方法,根据所需的外部数据类型和任务的主要关注点将用户查询分为四个级别:显式事实查询、隐式事实查询、可解释的基本原理查询和隐藏的基本原理查询。我们定义这些级别的查询,提供相关数据集,并总结关键挑战和应对这些挑战的最有效技术。最后,我们讨论了将外部数据集成到LLMs中的三种主要形式:上下文、小模型和微调,强调了它们各自的优势、局限性以及它们适合解决的问题类型。本文旨在帮助读者深入理解和分解构建LLM应用程序的数据需求和关键瓶颈,为不同的挑战提供解决方案,并作为系统开发此类应用程序的指南。
LLMs在各个专业领域较容易遇到一些问题,如模型幻觉、与特定领域知识的不一致等。所以整合特定领域的数据对于满足特定行业需求是非常重要的。通过RAG和微调等技术,基于RAG的LLM应用在多个方面显示出比仅基于通用LLM的应用的优势。
通常,基于RAG的LLM应用可以表述为一个映射过程,即基于给定数据D,将用户输入(查询Q)映射到预期响应(答案A)。
根据与外部数据D的交互程度和所需的认知处理水平,我们可以将查询分为不同层次。
- 显式事实查询 (Level-1 Explicit Facts), 最简单的数据增强查询形式,示例:
-
“2024年夏季奥运会将在哪里举行?”(给定一系列关于奥运会的文档)
-
“公司X的AI战略是什么?”(给定关于公司X的最新新闻和文章系列)
- 隐式事实查询 (Level-2 Implicit Facts),涉及需要一些常识推理或基本逻辑推理的查询,示例:
-
“样本大小大于1000的实验有多少个?”(给定一系列实验记录)
-
“最常提及的前3个症状是什么?”(给定一系列医疗记录)
-
“公司X和公司Y的AI战略有什么区别?”(给定关于公司X和Y的最新新闻和文章系列)
- 解释性理由查询 (Level-3 Interpretable Rationales),不仅需要掌握事实内容,还要能够理解领域数据,示例:
-
“根据胸痛管理指南,应该如何诊断和治疗有特定症状描述的胸痛患者?”
-
“在现实场景中应如何回应用户的问题?”(给定客户服务工作流程)
- 隐藏理由查询 (Level-4 Hidden Rationales),最具挑战性的查询类型,需要从外部数据中推断出未明确记录的推理规则。
-
“经济形势将如何影响公司未来的发展?”(给定一系列财务报告,需要经济和财务理由)
-
“使用数字5、5、5和1如何得到24点?”(给定一系列24点游戏的示例和相应答案)
-
“阿富汗是否允许父母将其国籍传给在国外出生的孩子?”(给定GLOBALCIT公民法数据集)
上述文字对应了下图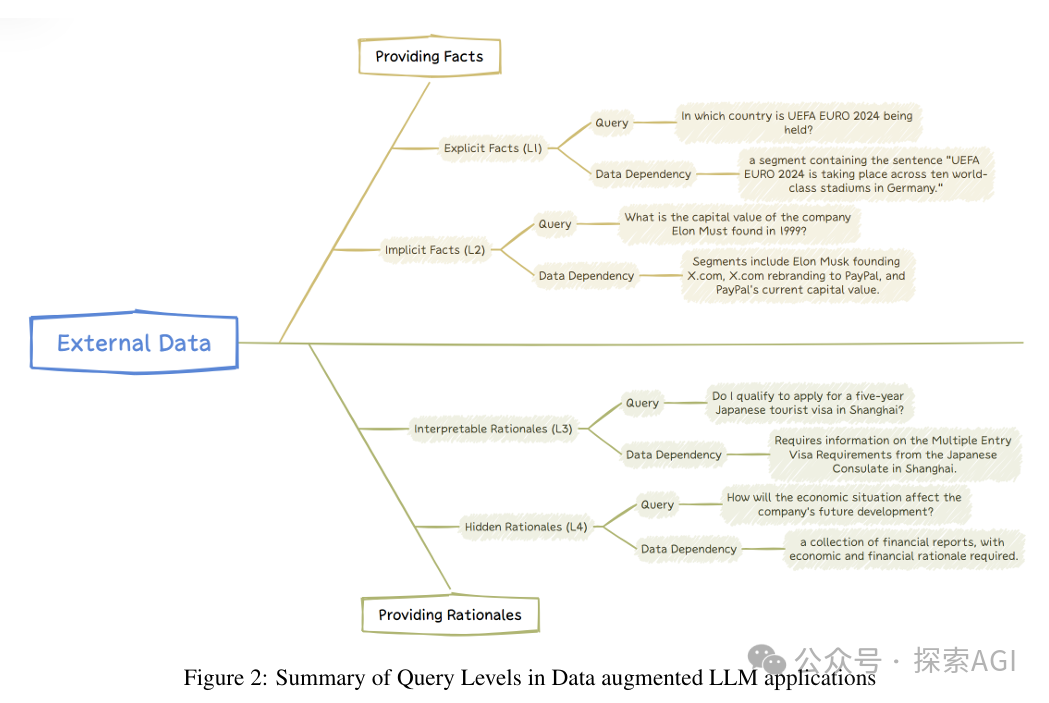
对RAG技术感兴趣,可以通过这本书全面学习。据了解这是目前第一本关于rag的书籍,很不错:
然后综述中用大量的篇幅来介绍了这4类的挑战和解决方案
L1 显式事实查询
挑战:
-
外部数据通常是高度非结构化的,并且包含多模态组件,如表格、图像、视频等。此外,将这些数据分割或“块化”处理时,保持原始上下文和意义是一个挑战。
-
数据检索困难:从大型非结构化数据集中检索相关数据段可能计算密集且容易出错。
-
评估困难:评估RAG系统(特别是组件级别)的性能是一项复杂任务,需要开发能够准确评估数据检索和响应生成质量的健壮指标。
解决方案:(介绍了非常多的高级RAG技巧)
-
多模态文档解析 (表格转文本、图片/视频内容转换成文本)
-
块大小优化:固定大小、文档结构递归切分、滑动窗口、基于语义
-
索引:bm25、香莲、hybird
-
query、doc 文档对齐:传统对齐,hyde文档域对齐,query域对齐
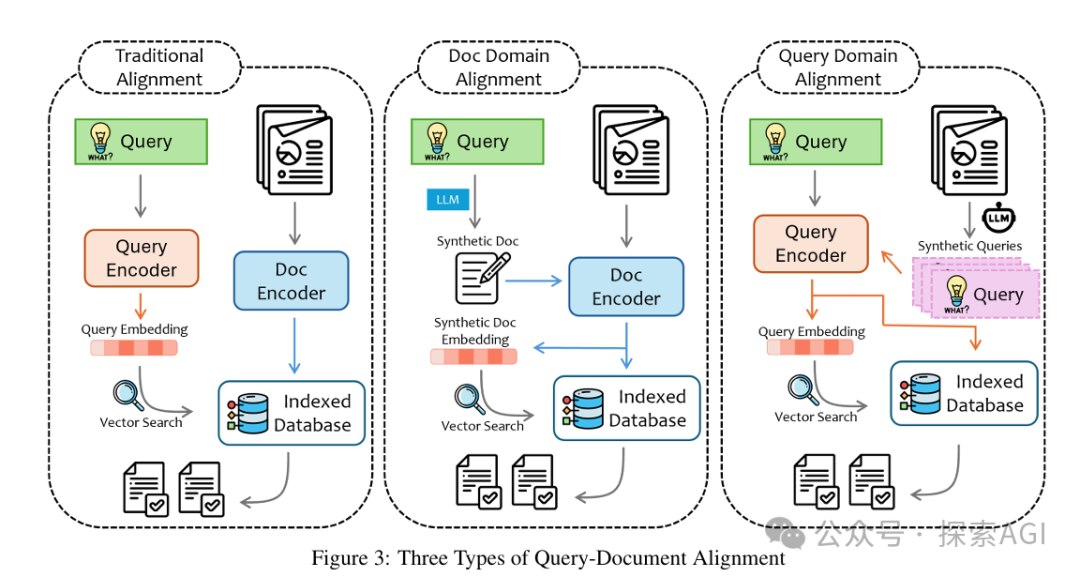
-
rerank修正:rerank
-
递归检索,迭代解锁:通过多次检索来逐步解决查询中的不明确问题。
-
生成:确定检索到的信息是否足够,或者是否需要额外的外部数据;处理检索到的知识与模型内部先验知识之间的冲突。
-
微调:通过设计训练数据来提高RAG系统在生成响应时的性能。
-
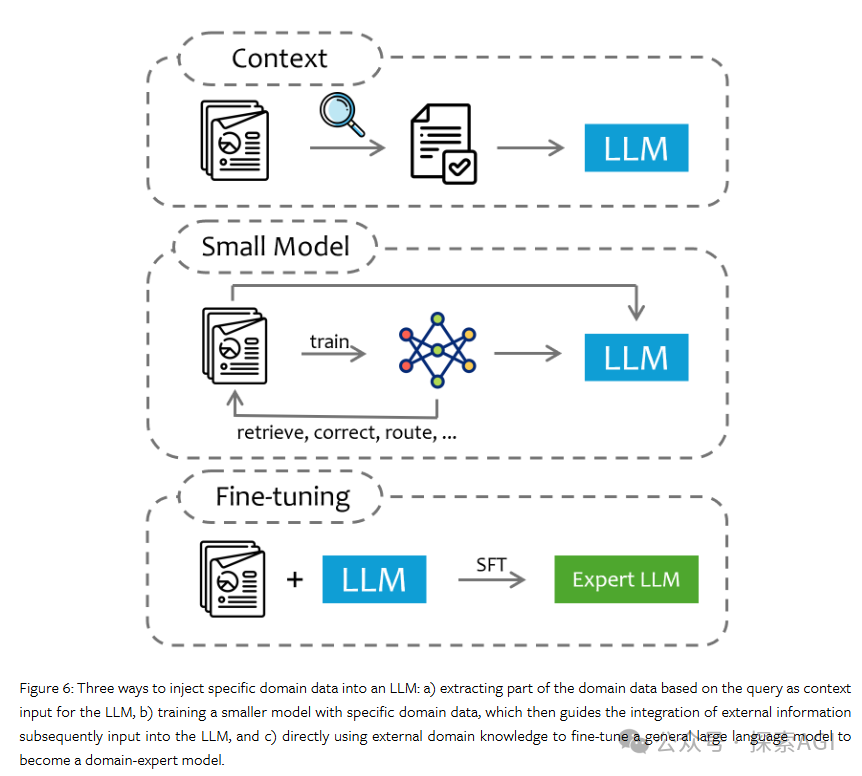
-
联合训练:在训练阶段同时训练检索器和生成器,以提高两者在RAG系统中的协同性能。
L2 隐式事实查询
挑战:
-
自适应:不同问题可能需要不同数量的检索上下文。固定数量的检索可能导致信息噪声过多或信息不足。
-
推理检索间的协调:推理可以指导需要检索的内容,而检索到的信息又可以迭代地细化推理策略。
解决方案:
-
迭代RAG:通过多步骤RAG过程动态控制,迭代地收集或纠正信息,直到达到正确答案。
-
基于图/树的RAG:使用图或树结构来自然地表达文本之间的关系,适合处理需要综合多参考信息的查询。
-
NL2SQL:当处理结构化数据时,将自然语言查询转换为SQL查询可以有效地检索信息。
剩下2种不做更多介绍了,有点扯远了,一张图表示如下:
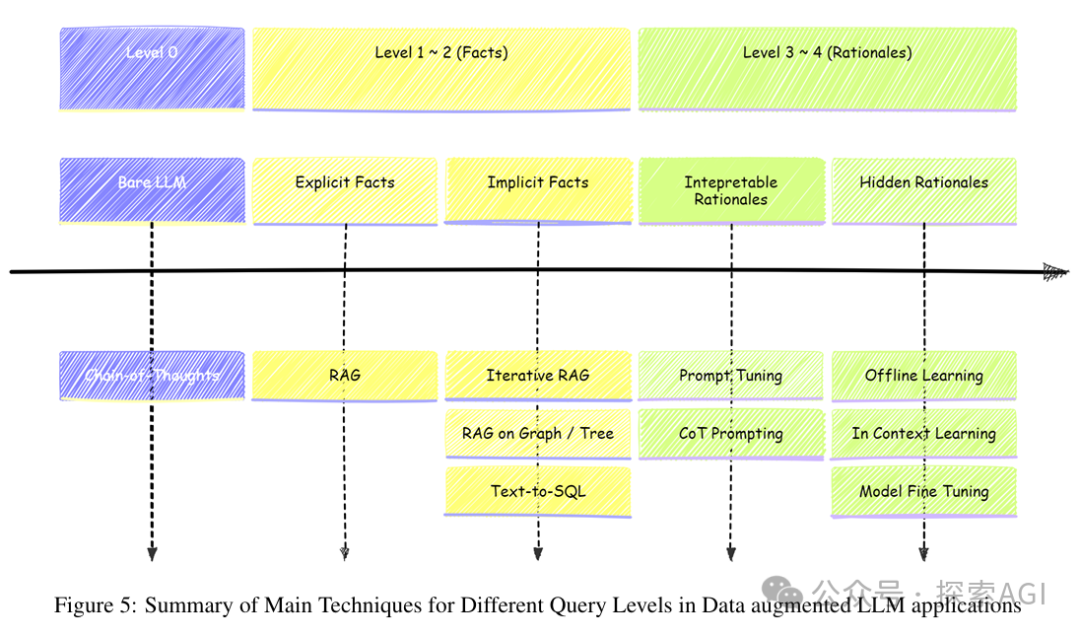
好了,这就是我今天想分享的内容。如果你对构建AI智能体感兴趣,别忘了点赞、关注噢~
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。
路线图很大就不一一展示了 (文末领取)

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥两本《中国大模型落地应用案例集》 收录了近两年151个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

👉GitHub海量高星开源项目👈
💥收集整理了海量的开源项目,地址、代码、文档等等全都下载共享给大家一起学习!

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告(持续更新)👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









