一、简介 LeNet、AlexNet、VGGNet、ResNet、NetWork In Network、GoogleNet;
LeNet-5是一个较简单的卷积神经网络。下图显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。关于CNN参见:https://blog.csdn.net/qq_42570457/article/details/81458077
LeNet-5 这个网络虽然很小,但是它包含了深度学习 的基本模块:卷积层,池化层,全连接层。是其他深度学习模型的基础, 这里我们对LeNet-5进行深入分析。同时,通过实例分析,加深对与卷积层和池化层的理解。
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
各层参数详解:
1、INPUT层-输入层
首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。
注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
输入图片:32*32
卷积核大小:5*5
卷积核种类:6
输出featuremap大小:28*28 (32-5+1)=28
神经元数量:28*28*6
可训练参数:(5*5+1) * 6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(5*5+1)*6*28*28=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5*5 的卷积核),得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:6
输出featureMap大小:14*14(28/2)
神经元数量:14*14*6
可训练参数:2*6(和的权+偏置)
连接数:(2*2+1)*6*14*14
S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 2*2核 进行池化,于是得到了S2,6个14*14的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。
4、C3层-卷积层
输入:S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核种类:16
输出featureMap大小:10*10 (14-5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合。
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。则:可训练参数:6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516
连接数:10*10*1516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5*5. 我们知道S2 有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:
C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
C3与S2中前3个图相连的卷积结构如下图所示:
上图对应的参数为 3*5*5+1,一共进行6次卷积得到6个特征图,所以有6*(3*5*5+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(下采样层)
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:5*5(10/2)
神经元数量:5*5*16=400
可训练参数:2*16=32(和的权+偏置)
连接数:16*(2*2+1)*5*5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类:120
输出featureMap大小:1*1(5-5+1)
可训练参数/连接:120*(16*5*5+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
7、F6层-全连接层
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
可训练参数:84*(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:
F6层的连接方式如下:
8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
上图是LeNet-5识别数字3的过程。
总结
LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。 卷积神经网络能够很好的利用图像的结构信息。 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。 LeNet最后使用的全连接是高斯全连接(其实就是模板),现在大部分神经网络在全连接的时候使用Softmax。
二、AlexNet
目前在自学计算机视觉与深度学习方向的论文,今天给大家带来的是很经典的一篇文章 :《ImageNet Classification with Deep Convolutional Neural Networks》。纯粹是自学之后,自己的一点知识总结,如果有什么不对的地方欢迎大家指正。AlexNet的篇文章当中,我们可以主要从五个大方面去讲:ReLU,LPN,Overlapping Pooling,总体架构,减少过度拟合。重点介绍总体结构和减少过度拟合。
1. ReLU Nonlinearity
一般神经元的激活函数会选择sigmoid函数或者tanh函数,然而Alex发现在训练时间的梯度衰减方面,这些非线性饱和函数要比非线性非饱和函数慢很多。在AlexNet中用的非线性非饱和函数是f=max(0,x),即ReLU。实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代,用ReLU比tanh快6倍。
2. 双GPU并行运行
为提高运行速度和提高网络运行规模,作者采用双GPU的设计模式。并且规定GPU只能在特定的层进行通信交流。其实就是每一个GPU负责一半的运算处理。作者的实验数据表示,two-GPU方案会比只用one-GPU跑半个上面大小网络的方案,在准确度上提高了1.7%的top-1和1.2%的top-5。值得注意的是,虽然one-GPU网络规模只有two-GPU的一半,但其实这两个网络其实并非等价的。
3. LRN局部响应归一化
ReLU本来是不需要对输入进行标准化,但本文发现进行局部标准化能提高性能。
其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
卷积核矩阵的排序是随机任意,并且在训练之前就已经决定好顺序。这种LPN形成了一种横向抑制机制。
4. Overlapping Pooling
池层是相同卷积核领域周围神经元的输出。池层被认为是由空间距离s个像素的池单元网格的组成。也可以理解成以大小为步长对前面卷积层的结果进行分块,对块大小为的卷积映射结果做总结,这时有。然而,Alex说还有的情况,也就是带交叠的Pooling,顾名思义 这指Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元的输入影响,也就是提取出来的结果可能是有重复的(对max pooling而言)。而且,实验表示使用 带交叠的Pooling的效果比的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用。
5. 总体结构
如果说前面的ReLU、LRN、Overlapping Pooling是铺垫的话,那么它们一定是为这部分服务的。
因为这才是全文的重点!!!理解这里才是把握住这篇的论文的精华!
首先总体概述下:
AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层;学习参数有6千万个,神经元有650,000个 AlexNet在两个GPU上运行; AlexNet在第2,4,5层均是前一层自己GPU内连接,第3层是与前面两层全连接,全连接是2个GPU全连接; RPN层第1,2个卷积层后; Max pooling层在RPN层以及第5个卷积层后。 ReLU在每个卷积层以及全连接层后。 卷积核大小数量: conv1:96 11*11*3(个数/长/宽/深度)
conv2:256 5*5*48
conv3:384 3*3*256
conv4: 384 3*3*192
conv5: 256 3*3*192
ReLU、双GPU运算:提高训练速度。(应用于所有卷积层和全连接层)
重叠pool池化层:提高精度,不容易产生过度拟合。(应用在第一层,第二层,第五层后面)
局部响应归一化层(LRN):提高精度。(应用在第一层和第二层后面)
Dropout:减少过度拟合。(应用在前两个全连接层)
第1层分析:
第一层输入数据为原始图像的227*227*3的图像(最开始是224*224*3,为后续处理方便必须进行调整),这个图像被11*11*3(3代表深度,例如RGB的3通道)的卷积核进行卷积运算,卷积核对原始图像的每次卷积都会生成一个新的像素。卷积核的步长为4个像素,朝着横向和纵向这两个方向进行卷积。由此,会生成新的像素;(227-11)/4+1=55个像素(227个像素减去11,正好是54,即生成54个像素,再加上被减去的11也对应生成一个像素),由于第一层有96个卷积核,所以就会形成55*55*96个像素层,系统是采用双GPU处理,因此分为2组数据:55*55*48的像素层数据。
重叠pool池化层:这些像素层还需要经过pool运算(池化运算)的处理,池化运算的尺度由预先设定为3*3,运算的步长为2,则池化后的图像的尺寸为:(55-3)/2+1=27。即经过池化处理过的规模为27*27*96.
局部响应归一化层(LRN):最后经过局部响应归一化处理,归一化运算的尺度为5*5;第一层卷积层结束后形成的图像层的规模为27*27*96.分别由96个卷积核对应生成,这96层数据氛围2组,每组48个像素层,每组在独立的GPU下运算。
第2层分析:
第二层输入数据为第一层输出的27*27*96的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被5*5*48的卷积核进行卷积运算,同理按照第一层的方式进行:(27-5+2*2)/1+1=27个像素,一共有256个卷积核,这样也就有了27*27*128两组像素层。
重叠pool池化层:同样经过池化运算,池化后的图像尺寸为(27-3)/2+1=13,即池化后像素的规模为2组13*13*128的像素层。
局部响应归一化层(LRN):最后经过归一化处理,分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
第3层分析
第三层输入数据为第二层输出的两组13*13*128的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*128的卷积核(两组,一共也就有3*3*256)进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有384个卷积核,这样也就有了13*13*192两组像素层。
第4层分析:
第四层输入数据为第三层输出的两组13*13*192的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*192的卷积核进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有384个卷积核,这样也就有了13*13*192两组像素层。
第5层分析:
第五层输入数据为第四层输出的两组13*13*192的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*192的卷积核进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有256个卷积核,这样也就有了13*13*128两组像素层。
重叠pool池化层:进过池化运算,池化后像素的尺寸为(13-3)/2+1=6,即池化后像素的规模变成了两组6*6*128的像素层,共6*6*256规模的像素层。
第6层分析:
第6层输入数据的尺寸是6*6*256,采用6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算;每个6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6*6*256尺寸的滤波器对输入数据进行卷积,通过4096个神经元的输出运算结果;然后通过ReLU激活函数以及dropout运算输出4096个本层的输出结果值。
很明显在第6层中,采用的滤波器的尺寸(6*6*256)和待处理的feature map的尺寸(6*6*256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而采用的滤波器的尺寸和待处理的feature map的尺寸不相同,每个滤波器的系数都会与多个feature map中像素相乘。因此第6层被称为全连接层。
第7层分析:
第6层输出的4096个数据与第7层的4096个神经元进行全连接,然后经由ReLU和Dropout进行处理后生成4096个数据。
第8层分析:
第7层输入的4096个数据与第8层的1000个神经元进行全连接,经过训练后输出被训练的数值。
6. 减少过度拟合
6.1 数据增益
增强图片数据集最简单和最常用的方法是在不改变图片核心元素(即不改变图片的分类)的前提下对图片进行一定的变换,比如在垂直和水平方向进行一定的唯一,翻转等。
AlexNet用到的第一种数据增益的方法:是原图片大小为256*256中随机的提取224*224的图片,以及他们水平方向的映像。
第二种数据增益的方法就是在图像中每个像素的R、G、B值上分别加上一个数,用到 方法为PCA。对于图像每个像素,增加以下量 :
p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。此方案名义上得到自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的。此方法降低top-1错误率1%。
6.2 Dropout
结合多个模型的预测值是减少错误的有效方法,但是对于训练时间用好几天的大型神经网络太耗费时间。Dropout是有效的模型集成学习方法,具有0.5的概率讲隐藏神经元设置输出为0。运用了这种机制的神经元不会干扰前向传递也不影响后续操作。因此当有输入的时候,神经网络采样不用的结构,但是这些结构都共享一个权重。这就减少了神经元适应的复杂性。测试时,用0.5的概率随机失活神经元。dropout减少了过拟合,也使收敛迭代次数增加一倍。
7. 学习细节
AlexNet训练采用的是随机梯度下降 (stochastic gradient descent),每批图像大小为128,动力为0.9,权重衰减为0.005,(Alexnet认为权重衰减非常重要,但是没有讲为什么)
对于权重值的更新规则如下:
其中i是迭代指数,v是动力变量,ε是学习率,是目标关于w、对求值的导数在第i批样例上的平均值。我们用一个均值为0、标准差为0.01的高斯分布初始化了每一层的权重。我们用常数1初始化了第二、第四和第五个卷积层以及全连接隐层的神经元偏差。该初始化通过提供带正输入的ReLU来加速学习的初级阶段。我们在其余层用常数0初始化神经元偏差。
8. 实验结果
ILSVRC2010比赛冠军方法是Sparse coding,这之后(AlexNet前)报道最好方法是SIFT+FVs。CNN方法横空出世 ,远超传统方法。
ILSVRC-2012,Alex参加比赛,获得冠军,远超第二名SIFT+FVs。
定量分析:
图3显示了卷积层学到的有频率和方向选择性的卷积核,和颜色斑点(color blob)。GPU 1 (color-agnostic)和GPU 2(color-specific)学习到的卷积核并不一样。不一样的原因是3.5中的受限连接(restricted connectivity)。
图4显示,即使目标偏离中心,也可以被识别出来,比如mite。top-5预测结果是reasonable的,比如leopard的预测的可能结果是其他类型的猫科动物。但是也存在对intended focus的模糊问题,就是网络不知道我们到底想识别图片中的什么物体,比如cherry,分类结果是dalmatian,网络显然关注的是dog。
网络最后4096-d隐藏层产生的是feature activations是另一个重要指标。如果两张图像产生欧氏距离相近的feature activation vectors,那么网络的higher levels就认为他们是相似的。使用此度量,可以实现较好的图像检索。
通过欧氏距离计算两个4096维度效率太低,可以使用自动编码压缩向量成二进制码。这比直接在原始像素上使用自动编码效果更好。因为在raw pixels上使用quto-encoder,没用到标签数据,只是检索有相似边缘模式(similar patterns of edges)的图像,却不管他们语义(semantically)上是否相似。
9.探讨
深度很重要,去掉任一层,性能都会降低。
虽然通过增大网络结构和增加训练时长可以改善网络,但是我们与达到人类视觉系统的时空推理能力(infero-temporal pathway of the human visual system)还相距甚远。所以,最终希望能将CNN用到视频序列分析中,视频相对静态图像有很多有用的时间结构信息。
AlexNet的论文下载地址:点击打开链接
10.总结
AlexNet首次引入了ReLU、Dropout、LRN,但是根据最近的数据表明:当网络特别深的时候,LRN的意义不会特别大
AlexNet的论文下载地址:点击打开链接
三、VGGNet
VGG相应的论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”,下载地址:https://arxiv.org/abs/1409.1556
VGG比较出名的是VGG-16和VGG-19,最常用的是VGG-16。各种VGG的网络结构如下:
VGG-16有16个卷积层或全连接层,包括五组卷积层和3个全连接层,即:16=2+2+3+3+3+3。这个结构应该牢记于心。
认真比较ResNet和VGG,你会发现ResNet的第一个卷积层的stride=2,因此在分辨率缩小相同倍数(32倍)的情况下,它不需要像VGG那样在最后一组卷积层后面跟一个stride=2的pooling层。
VGGNet的卷积层有一个显著的特点:特征图的空间分辨率单调递减,特征图的通道数单调递增。
这样做是合理的。对于卷积神经网络而言,输入图像的维度是HxWx3(彩色图)或者是HxWx1(灰度图),而最后的全连接层的输出是一个1x1xC的向量,C等于分类的类别数(例如ImageNet中的1000类)。如何从一个HxWx3或HxWx1的图像转换到1x1xC的向量呢?上文所说的VGGNet的特点就是答案:特征图的空间分辨率单调递减,特征图的通道数单调递增,使得输入图像在维度上流畅地转换到分类向量。用于相同ImageNet图像分类任务的AlexNet的通道数无此规律,VGGNet后续的GoogLeNet和Resnet均遵循此维度变化的规律。
VGG-16具体的feature map的维度如下图所示,黑色边框是卷积层的输出,红色边框是pooling层的输出,蓝色边框是全连接层,最后的猪肝 色边框是soft-max层的输出:
上述VGG结构是用于ImageNet 1000类的图像分类数据集的,相应的VGG也有用于cifar数据集的网络。由于cifar数据集的分辨率只有32x32且类别只有10类,因此相应的VGG-cifar网络会更浅,同时全连接层的参数量大幅减少。下图是cifar数据样例:
总结
VGGNet的相对于LeNet和AlextNet,卷积核比较小,则视觉感知野也就比较少;优点是参数会少一下 为了解决感知野比较少的情况下,采用了卷积层堆叠;
三、VGGNet
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet,Alpha zero也使用了ResNet,所以可见ResNet确实很好用。
1.ResNet意义
随着网络的加深,出现了训练集 准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的 (过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构如图1; 残差指的是什么 ? [Math Processing Error]y=F(x)+x 部分。 为什么ResNet可以解决“随着网络加深,准确率不下降”的问题? 表1,Resnet在ImageNet上的结果 如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了 ,网络的性能也就不会随着深度增加而降低了。
2.ResNet结构
它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,看下图我们就能大致理解: 图1 Shortcut Connection identity mapping ,这张图也诠释了ResNet的真谛,当然大家可以放心,真正在使用的ResNet模块并不是这么单一 ,文章中就提出了两种方式: 图2 两种ResNet设计 building block “。其中右图又称为”bottleneck design”,目的一目了然 ,就是为了降低参数的数目 ,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。 实用目的 )。
问大家一个问题: 如图1所示,如果F(x)和x的channel个数不同怎么办,因为F(x)和x是按照channel维度相加的,channel不同怎么相加呢? 图3 两种Shortcut Connection方式 实线 “和”虚线 “两种连接方式, 实线 的的Connection部分(”第一个粉色矩形和第三个粉色矩形 “)都是执行3x3x64的卷积,他们的channel个数一致,所以采用计算方式: [Math Processing Error]y=F(x)+x 图4 两种Shortcut Connection方式实例(左图channel一致,右图channel不一样)
3.ResNet50和ResNet101
这里把ResNet50和ResNet101特别提出,主要因为它们的出镜率很高,所以需要做特别的说明。给出了它们具体的结构: 表2,Resnet不同的结构 conv1,conv2_x,conv3_x,conv4_x,conv5_x ,之后的其他论文也会专门用这个称呼指代ResNet50或者101的每部分。 注:101层网络仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内;
4.基于ResNet101的Faster RCNN
文章中把ResNet101应用在Faster RCNN上取得了更好的结果,结果如下: 表3,Resnet101 Faster RCNN在Pascal VOC07/12 以及COCO上的结果 Faster RCNN中RPN和Fast RCNN的共享特征图用的是conv5_x的输出么? 图5 基于ResNet101的Faster RCNN
总结
ResNet增加了向后传递误差的通道(从底层传到顶层),来提高网络训练的深度。
四、NIN
1×1的卷积核
卷积核在CNN中经常被用到,一般常见的是3×3的或者5×5的,见下图,这里不多赘述
1×1卷积核的作用
那么1×1卷积核有什么作用呢,如果当前层和下一层都只有一个通道那么1×1卷积核确实没什么作用,但是如果它们分别为m层和n层的话,1×1卷积核可以起到一个跨通道聚合的作用 ,所以进一步可以起到降维(或者升维)的作用,起到减少参数的目的 。
Network in Network
NIN网络是第一个提出1×1卷积核的论文,同时其也提出了Network in Network的网络概念。因为一般卷积操作可以看成特征的提取操作,而一般卷积一层只相当于一个线性操作,所以其只能提取出线性特征。所以该作者就像能否在卷积层后也加入一个MLP使得每层卷积操作能够提取非线性特征。 其实这里的MLP,指的是同一层中,不同特征层之间,同一个位置上的值的MLP
NIN与1×1卷积核的关系
那么NIN与1×1卷积核又有什么关系呢
用卷积核实现全连接层
In Convolutional Nets, there is no such thing as “fully-connected layers”. There are only convolution layers with 1x1 convolution kernels and a full connection table. – Yann LeCun
LeCun经常说一个全连接层的网络可以用1×1卷积核去替换,虽然这个说法被批了(见参考文献1)
先选择7×7的卷积核,输出层特征层数为4096层,这样得到一个[1×1×4096]层的 然后再选择用1×1卷积核,输出层数为1000层,这样得到一个[1×1×1000]层的 这样就搞定了。
扩展:用卷积层代替全连接层的好处
这样做其实有非常多的好处,比如上面的例子中输入是224x224x3 的图像,如果此时图像变得更大了,变成384x384大小的了,那么一开始按照32作为步长来进行卷积操作,最后还按照这个网络结构能得到一个[6×6×1000]层的,那么前面那个[6×6]有什么用呢,这个代表每一个位置上,其属于1000个分类结果中的打分,所以这在图像分割等领域等领域有着非常重要的作用【之前一篇论文就是用的这种方法Fully Convolutional Networks for Semantic Segmentation】。
总结
NIN最主要的提出了1*1的卷积核,以及移除全连接层,将每幅特征图池化为单个输出;
四、GoogleNet
提出背景
始于LeNet-5,一个有着标准的堆叠式卷积层冰带有一个或多个全连接层的结构的卷积神经网络。通常使用dropout来针对过拟合问题。
相关工作
GoogLeNet参考Robust object recognition with cortex-like mechanisms.中利用固定的多个Gabor滤波器 来进行多尺度处理的方法,对inception结构中的所有滤波器都进行学习,并运用至整个22层网络。
基本思想及过程
GoogLeNet提出最直接提升深度神经网络的方法就是增加网络的尺寸,包括宽度和深度。深度也就是网络中的层数,宽度指每层中所用到的神经元 的个数。但是这种简单直接的解决方式存在的两个重大的缺点。 过拟合 。 可由 逐层分析与输出高度相关的上一层的激活值和聚类神经元的相关统计信息来优化。但是这有非常多的限制条件。因此提出运用Hebbian原理 ,它可以使得上述想法在少量限制条件下就变得实际可行。
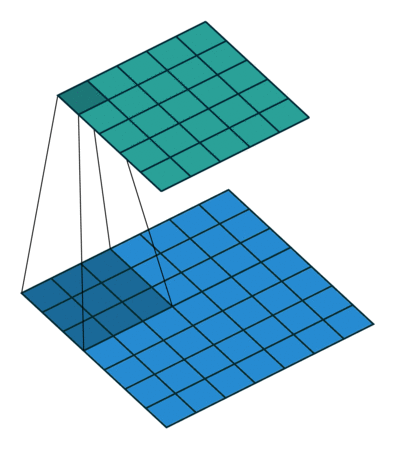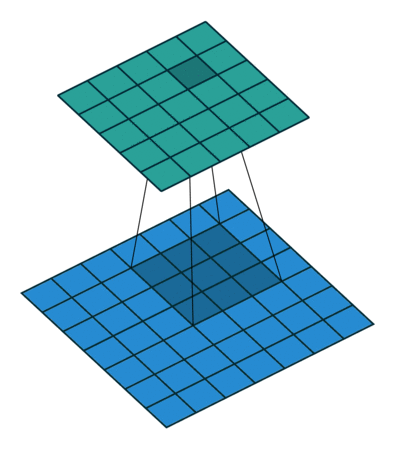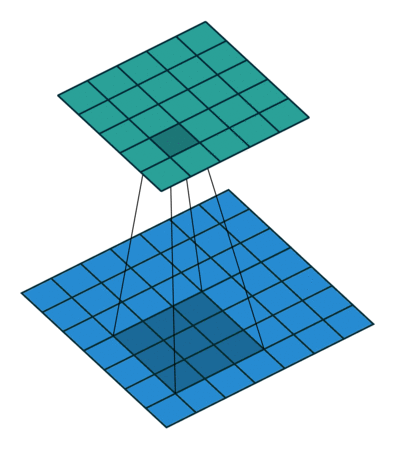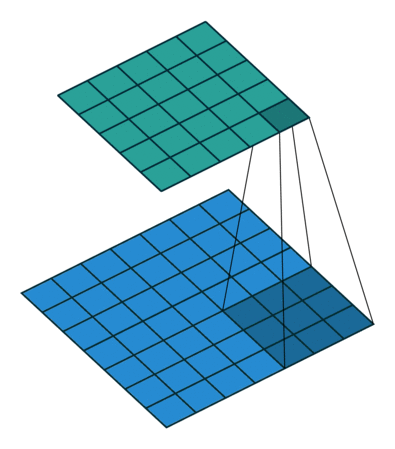
inception结构的主要思想在于卷积视觉网络中一个优化的局部稀疏结构怎么样能由一系列易获得的稠密子结构来近似和覆盖。上面提到网络拓扑结构是由逐层分析上一层的相关统计信息并聚集到一个高度相关的单元组中,这些簇(单元组)表达下一层的单元(神经元)并与之前的单元相连接,而靠近输入图像的底层相关的单元在一块局部区域聚集,这就意味着我们可以在一块单一区域上聚集簇来结尾,并且他们能在下一层由一层1x1的卷积层覆盖,也即利用更少的数量在更大空间扩散的簇可由更大patches上的卷积来覆盖,也将减少越来越大的区域上patches的数量。
inception结构中有很多嵌套,低维嵌套包含了大量的图片patch信息,且这种嵌套表达了一个稠密且压缩的信息的形式,但我们想要表达的更加稀疏,并且只在大量聚集的时候才对信号进行压缩,因此考虑利用在3x3和5x5卷积操作前进行1x1卷积来进行降维处理,1x1不仅降维,而且还引入了ReLU非线性激活。实际发现,只在高层中使用inception结构对整个网络更加有利。
上图为GoogLeNet的网络框图细节,其中“#3x3 reduce”,“#5x5 reduce”代表在3x3,5x5卷积操作之前使用1x1卷积的数量。输入图像为224x224x3,且都进行了零均值化的预处理操作,所有降维层也都是用了ReLU非线性激活函数。
如上图用到了辅助分类器,Inception Net有22层深,除了最后一层的输出,其中间节点的分类效果也很好。因此在Inception Net中,还使用到了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception Net的训练很有裨益。
总结
GoogleNet主要贡献是:使用1*1卷积来进行降维;多个尺寸上同时卷积在进行聚类;为网络的宽度增加提供了思路。
文章的参考链接
了解更多关于《计算机视觉与图形学》相关知识,请关注公众号:
LeNet :https://www.cnblogs.com/duanhx/articles/9655228.html













































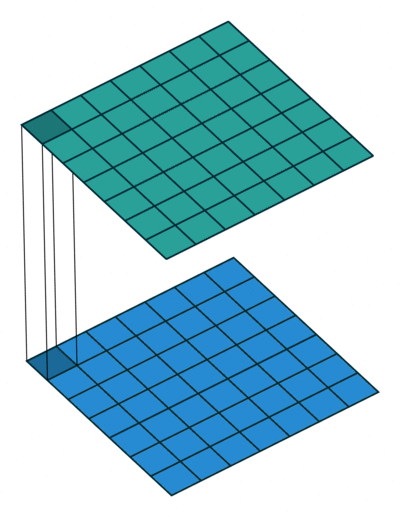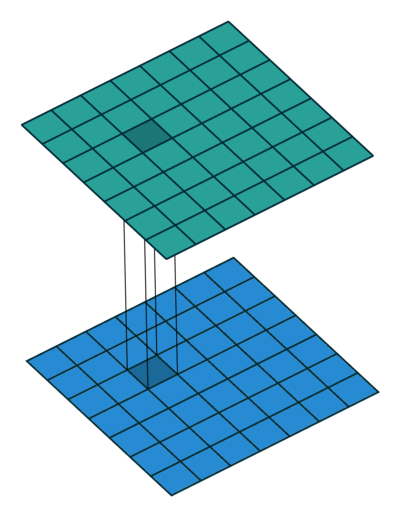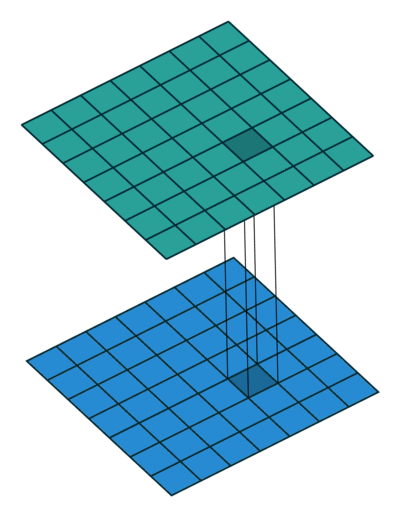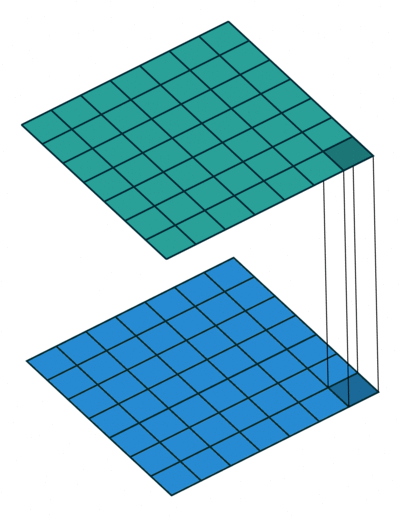























 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









