







本文首发至微信公众号:CVHub,不得以任何形式转载或售卖,仅供学习,违者必究!

Title: PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers
Paper: https://arxiv.org/pdf/2206.02066.pdf
Code: https://github.com/XuJiacong/PIDNet
导读
本文介绍了一种名为PIDNet的实时语义分割网络架构。虽然传统的双分支网络结构例如大家最熟悉的BiSeNet,其在实时语义分割任务中已经被证明有效。但是,作者认为直接融合高分辨率的空间细节信息和低频的上下文信息的方法存在缺陷,容易使得细节特征被周围的上下文信息淹没。这种现象被称为overshoot,限制了现有两分支模型的分割准确性的提高。
给大家解释下,overshoot 即超调,是控制系统中一种普遍的现象,指的是系统在达到稳态之前或之后,输出变量会超过其最终稳态值的情况。在
PID(即比例积分微分)控制器中,当反馈信号与期望值不同时,PID 控制器会根据比例、积分、微分三个部分计算出一个控制量来调整输出,从而使反馈信号逐渐接近期望值。但是在比例系数过大或系统响应过快时,控制器可能会产生超调现象,使得输出超过期望值一段时间,这可能导致系统出现震荡、不稳定等问题。【三百六十行,行行转AI!】
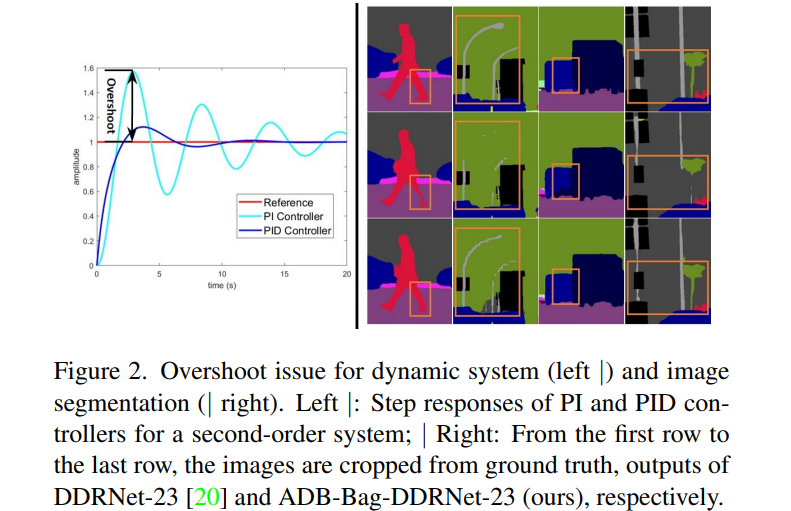
因此,为了解决这个问题,作者将卷积神经网络和比例积分微分即 PID 控制器之间建立联系,并揭示了这种双分支网络可以等效于比例积分控制器,本质上也会遭受类似的超调问题。基于这个认知,作者提出了一种新的三分支网络架构:PIDNet,其包含三个分支,分别用于解析:
- 空间细节信息
- 上下文信息
- 边界信息
同时,采用边界注意力机制来指导空间细节信息分支和上下文信息分支的融合。

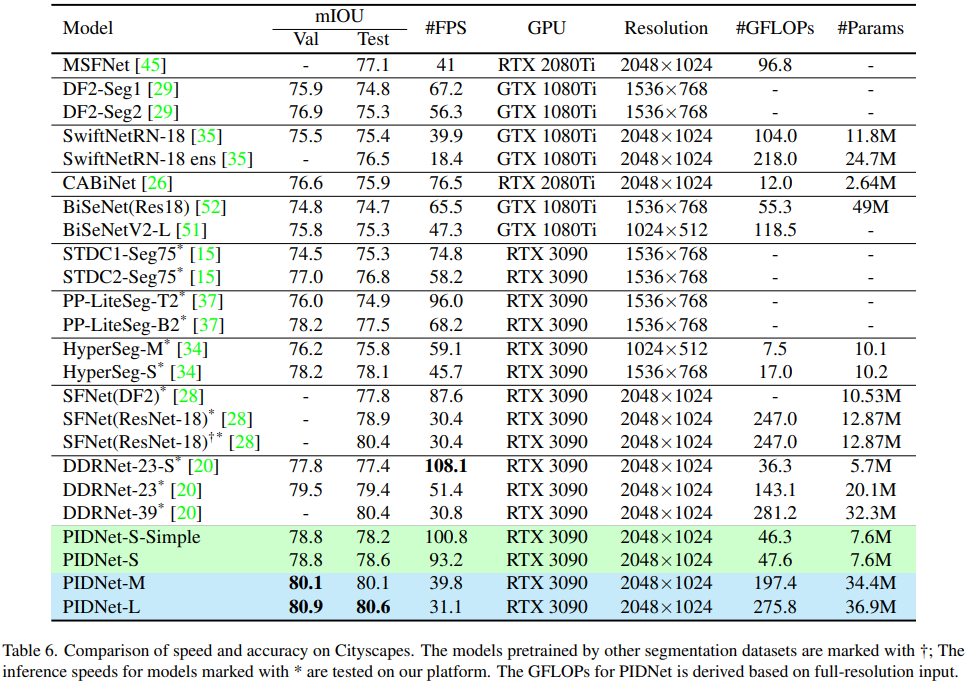
最终,PIDNet的精度超过了所有具有相似推理速度的现有模型,在Cityscapes和CamVid两个主流的道路场景解析数据集上实现了最佳的推理速度和准确度平衡。其中:
PIDNet-S在Cityscapes数据集上的推理速度为 93.2 FPS,mIOU 为 78.6%;CamVid数据集上的推理速度为 153.7 FPS,同时 mIOU 为 80.1%。
背景
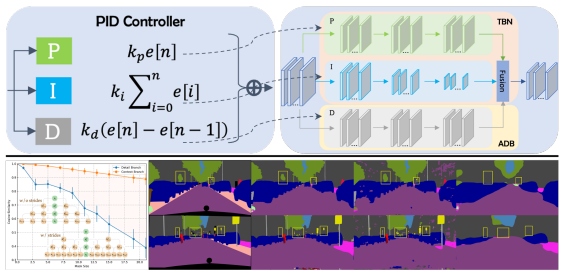
如上图上半部分所示,一个 PID 控制器包含三个组件:
- 比例(P)控制器
- 积分(I)控制器
- 微分(D)控制器
其中,P 控制器关注当前信号,而I控制器则累加所有过去的信号。由于积分的惯性效应,当信号变化相反时,简单的 PI 控制器的输出会出现超调现象。因此通常会引入了 D控制器进行调节,当信号变小时,D分量将变为负数,并作为阻尼器减少超调现象。类似地,TBN,即双分支网络也是通过不同的卷积层来解析上下文和空间细节信息。
再来看看上图下半部分,相比于空间细节信息分支,上下文信息分支对局部信息的变化不太敏感。换个角度理解,便是细节信息和上下文信息分支在空间域中的行为类似于时间域中的P(当前)和I(所有先前)控制器。
如何理解这个类比呢?我们可以从这个角度想想。
由于 PI 控制器更加关注输入信号的低频部分,不能立即对信号的快速变化做出反应,因此它天然存在超调问题。而 D 控制器通过使控制输出对输入信号的变化敏感,从而减少了超调。如上图下半部分所示,即使不准确,细节信息分支仍会解析各种语义信息,而上下文信息分支则聚合低频上下文信息,类似于在语义上使用一个较大的均值滤波器。所以直接融合细节和上下文信息会导致某些细节特征丢失。因此,本文得出这么一个结论:即 TBN 在傅里叶即频域中等价于一个 PI 控制器。【不得不说,现在发个顶会真是越来越卷啊,story 越来越高大上,下次生化环材估计也可以来个类比】
方法
上面扯了很多背景知识,其实只是“包装”,对于做科研的同学可能很有帮助。但是我们还是实事求是,看下具体的框架和细节吧。其实语义分割相对来说还是很好理解的,一般看框架图就知道大概思路了。以往的工作解决的角度无非就是从空间细节、上下文关系和边界信息入手,本文倒好,一口气解决三个。下面让我们快马加鞭的过一遍吧!
Overall
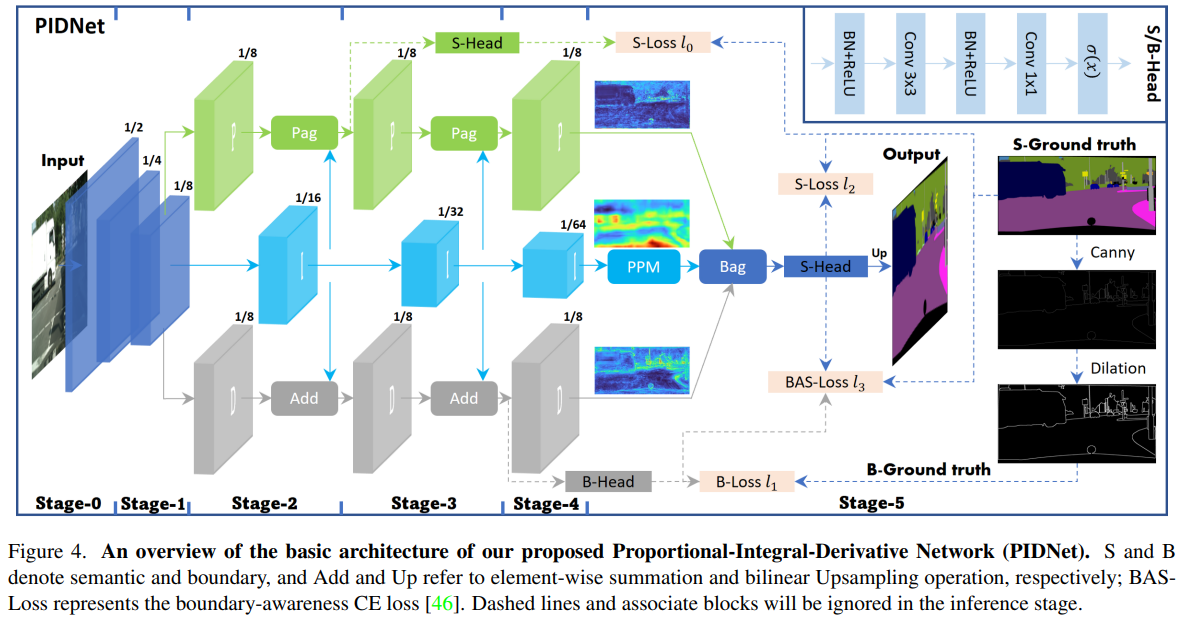
正如我们前面说到的,现有的双分支结构可以类比于 PI 控制器,这类控制器容易出现 overshoot 的问题。在控制系统中,一般我们会引入微分控制器进行调节,转换个思路,换到 CNN 这边,无非就是加多个分支嘛,你说是不是?
因此,为了缓解这个问题,本文在 TBN 上增加了一个辅助的导数分支 ADB,即在空间上模拟 PID 控制器,并突出高频语义信息。其中,考虑到每个 object 内部像素的语义是一致的,只有在相邻对象的边界处才会出现语义不一致,因此语义的差异仅在对象边界处为非零,所以 ADB 的目标是边界检测。遂本文建立了一种新的三分支实时语义分割体系结构,即比例-积分-微分网络——PIDNet,如上图所示。
PIDNet 拥有三个分支,具有互补的职责:
- 比例分支负责解析和保留高分辨率特征图中的详细信息;
- 积分分支负责聚合局部和全局的上下文信息以捕获远距离依赖;
- 微分分支负责提取高频特征以预测边界区域。
同DDRNet一样,本文也采用级联残差块作为骨干网络,以更好地移植到硬件部署。此外,为了实现更加高效,作者将 P、I 和 D 分支的深度设置为适中、较深和较浅。因此,通过加深和加宽模型可以生成一系列 PIDNet 模型,即PIDNet-S、PIDNet-M和PIDNet-L,也就是做对网络架构进行缩放啦~~~
上面大致介绍了主体的框架,下面我们重点讲解下损失函数和各个模块,GOGOGO!
Loss
从图中可以看出,损失函数是一个复合函数,其由四部分组成。具体地:
首先,作者在第一个 Pag 模块的输出处添加了语义头,生成额外的语义损失 l 0 l_{0} l0 以更好地优化整个网络.
其次,为了处理边界检测中的不平衡问题,本文使用加权二元交叉熵损失 l 1 l_{1} l1,而不是 Dice Loss,因为这可以令网络更倾向于使用粗糙的边界来突出边界区域,并增强小物体的特征。
紧接着, l 2 l_{2} l2 和 l 3 l_{3} l3 分别代表交叉熵损失,这里使用的是输出的边界头来协调语义分割和边界检测任务,并增强 Bag 模块的功能,因此在 KaTeX parse error: Expected '}', got 'EOF' at end of input: l_{3 中采用了具有边界感知性的 CE 损失。
因此,PIDNet 的整体损失可以定义为:
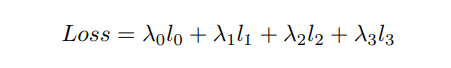
文中将这四个超参数分别设置为 0.4、20、1 和 1。
Pag: Learning High-level Semantics Selectively
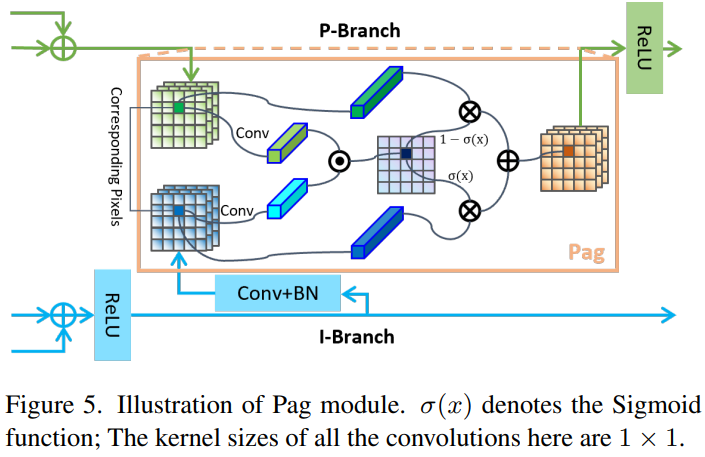
Pixel-attention-guided fusion, Pag, 即像素注意力引导模块,很好理解,就是将比例和微分分支的特征利用一个注意力机制进行交互增强。
首先,作者提到了在其他语义分割网络中常用的横向连接lateral connection技术,该技术可以加强不同尺度的特征图之间的信息传递,提高模型的表达能力。而在 PIDNet 中,I 分支提供了丰富准确的语义信息,对于 P 和 D 分支的细节解析和边界检测至关重要。因此,作者将 I 分支视为其他两个分支的备用支持,并使其能够为它们提供所需的信息。此外,与 D 分支直接添加提供的特征图不同,作者为 P 分支引入了Pag 来选择性地学习 I 分支中有用的语义特征。
PAPPM: Fast Aggregation of Contexts

(⊙o⊙)…,这图怎么这么眼熟,喔,一看就是 PPM 模块,的改进版啦!PPM 是啥,不会还有人不知道吧?
众所周知,Pyramid Pooling Module, PPM,主要用于构建全局场景的先验信息。实现上,PPM 就是对不同尺度的特征图进行池化操作,然后将不同尺度的池化特征图进行拼接,形成本地和全局上下文的表示。说白了就是个多尺度融合。
作者认为 PPM 虽然能够很好地嵌入上下文信息,但它的计算过程无法并行化,非常耗时,而且对于轻量级模型来说,PPM 包含的每个尺度的通道数太多,可能会超过这些模型的表示能力。因此,作者对 PPM 进行了修改,提出了一种可并行化的新的 PPM,叫做 Parallel Aggregation PPM, PAPPM,并将其应用于PIDNet-M 和 PIDNet-S 以保证它们的速度。对于深度模型 PIDNet-L,作者仍然选择 PPM,但减少了每个尺度的通道数,以减少计算量并提高速度。
Bag: Balancing the Details and Context

最后,边界注意力引导 Bag 模块的作用是利用边界特征来指导细节(P)和上下文(I)表示的融合,以实现更好的语义分割效果。作者指出,尽管上下文分支具有语义精度,但它在边界区域和小物体上丢失了太多的空间和几何细节,因此,PIDNet 利用细节分支来提供更好的空间细节,并强制模型在边界区域更加信任细节分支,同时利用上下文特征来填充其他区域。
效果
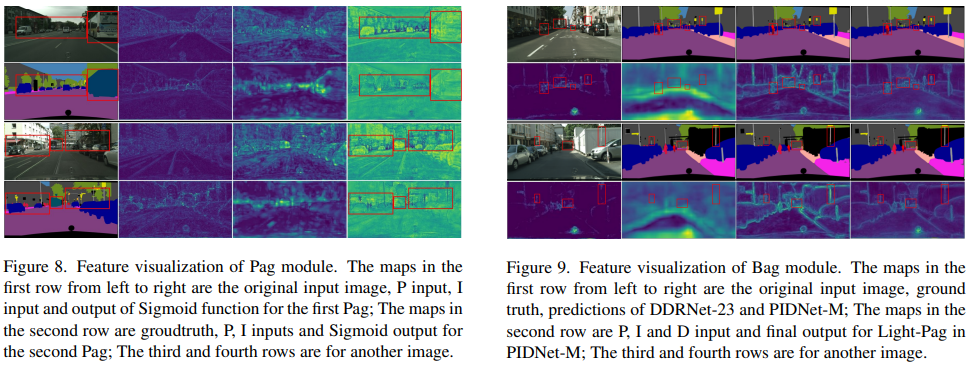
总结
本文提出了一种新颖的用于实时语义分割的三分支网络架构PIDNet。该模型的目标是实现对图像的语义分割和边界检测。其中,语义分割需要解析图像中的细节信息,而边界检测需要高频语义信息。为了解决这个问题,模型使用了比例分支(P)、积分分支(I)和微分分支(D)。
其中,P 分支解析高分辨率特征图中的细节信息,I 分支聚合局部和全局的上下文信息以捕获远距离依赖,而 D 分支提取高频特征以预测边界区域。整个模型使用级联残差块作为主干网络,并使用不同深度和宽度的网络来生成 PIDNet 系列模型。
此外,所提方法还使用了一种复合的损失函数进行优化,包括边界感知交叉熵损失等。同时,引入了像素注意力引导模块(Pag)和边界注意力引导模块(Bag)来协调不同分支的特征融合。最后,为了更好地捕捉上下文信息,模型还基于 PPM 模块提出了一个并行的高效 PPM 模块来增强上下文嵌入能力。
总的来说,PIDNet 实现了推理时间和准确性之间的最佳折衷。然而,由于 PIDNet 利用边界预测来平衡细节信息和上下文信息,因此通常需要花费较多的时间来处理边界周围的精确注释以获得更好的性能。
写在最后
如果您也对网络架构设计、目标检测、语义分割等技术感兴趣,欢迎扫描屏幕下方二维码,备注“技术”,加入 CVHub 官方的技术交流群进行更深入的细节探讨,期待您的加入!

















 3386
3386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











