






论文链接:https://arxiv.org/pdf/2210.09615.pdf
主要思路
多模态3D物体检测一直是自动驾驶领域中的一个活跃研究课题,然而,探索稀疏3D点和密集2D像素之间的跨模态特征融合并非易事,最近的方法要么将图像特征与投影到2D图像平面上的点云特征融合,要么将稀疏点云与密集图像像素组合。这些融合方法经常遭受严重的信息丢失,从而导致性能次优。为了解决这些问题,本文构建了点云和图像之间的均匀结构,通过将相机特征转换到LiDAR 3D空间中来避免投影信息丢失。论文主要提出了一种用于三维目标检测的同质多模态特征融合与交互方法(HMFI)。具体来说,首先设计了一个图像体素提升模块(IVLM),以将2D图像特征提升到3D空间中并生成均匀图像体素特征。然后,通过引入基于self-attention的查询融合机制(QFM),将体素化的点云特征与来自不同区域的图像特征进行融合。接下来,提出了一个体素特征交互模块(VFIM),以增强同质点云和图像体素表示中相同对象的语义信息的一致性,这可以为跨模态特征融合提供对象级对齐指导,并增强复杂背景下的辨别能力。在KITTI和Waymo开放数据集上进行了广泛的实验,与最先进的多模态方法相比,提出的HMFI实现了更好的性能。特别是,对于KITTI基准上的骑车的人3D检测,HMFI大大超过了所有已发布的算法!!!
领域背景
3D目标检测是一项重要任务,旨在精确定位和分类3D空间中的每个物体,从而使车辆能够全面感知和了解周围环境。到目前为止,已经提出了各种基于激光雷达和基于图像的3D检测方法[33,34,36,24,40,18,41,39,9,6,26]。基于激光雷达的方法可以实现优于基于图像的方法的性能,因为点云方法包含精确的空间信息。但是,激光雷达点通常是稀疏的,没有足够的颜色和纹理信息。与基于图像的方法相比,它们在捕获语义信息方面表现更好,同时又缺乏深度信号。因此,多模态三维目标检测是一个很有前途的方向,它可以充分利用图像和点云的互补信息。最近的多模态方法通常可分为两类:决策级融合和特征级融合。决策级融合方法将检测到的目标集成在各自的模态中,其性能受每个阶段的限制。特征级融合更为普遍,因为它们融合了两种模态的丰富信息特征。图1(a)描述了三种典型的特征级融合方法,第一种是融合感兴趣区域(RoI)的多模态特征。然而,这些方法在2D平面中将3D点投影到鸟瞰图(BEV)或前视图(FV)上时会产生严重的空间信息损失,而3D信息在准确的3D目标定位中起着关键作用。另一项工作是在点/体素级别上进行融合[43,49,55,21,22,50,14,59],这可以在更精细的粒度上实现互补融合,并涉及3D点或2D像素处的低级多模态特征的组合。然而,它们只能近似地在点/体素特征和图像特征之间建立相对粗糙的对应关系,此外,由于2D密集图像像素和3D稀疏激光雷达点之间的投影不匹配,这两种特征融合方案通常会遭受严重的信息损失。

为了解决上述问题,论文提出了一种同质融合方案,该方案将图像特征从2D平面提升到3D密集体素结构。在同质融合方案中,提出了同质多模态特征融合与交互方法(HMFI),该方法利用了多模态特征中的互补信息,并减轻了由降维映射引起的严重信息损失。此外,基于同构3D结构在目标层次上构建点云特征和图像特征之间的跨模态特征交互,以增强模型将图像语义信息与点云融合的能力。具体来说,论文设计了一个图像体素提升模块(IVLM)来提升2D图像,首先将图像特征映射到3D空间,并构造2D图像的均匀体素结构,用于多模态特征融合,该融合由点云作为深度提示进行引导,融合这两个多模态数据不会造成信息丢失。还注意到,跨模态数据的均匀体素结构有助于特征融合和交互。因此,本文引入了查询融合机制(QFM),该机制引入了一种基于self-attention的操作,可以自适应地结合点云和图像特征。每个点云体素将查询所有图像体素以实现同质特征融合,并与原始点云体元特征组合以形成联合相机LiDAR特征。QFM使每个点云体素能够自适应地感知公共3D空间中的图像特征,并有效地融合这两种同质表示。
此外,本问探索在同质点云和图像体素特征,而不是在感兴趣区域中基于RoI的细化(用于将低级LiDAR和相机特征与联合相机LiDAR特征融合)。论文认为,尽管点云和图像表示方式不同,但同构结构中的对象级语义属性应该相似。因此,为了加强点云和图像在共享3D空间中的抽象表示,并利用两种模式中相同目标属性的相似性,在目标级别上提出了一个体素特征交互模块(VFIM),以提高点云和3D RoI中图像同质表示的一致性。具体而言,使用体素RoI池[6]根据预测的建议提取这两个同质特征中的特征,并生成成对的RoI特征集。然后,采用每对RoI特征之间的余弦相似性损失,并加强点云和图像中对象级属性的一致性。在VFIM中,在这些同构成对的RoI特征中构建特征交互可以提高两个同构表示之间的对象级语义一致性,并增强模型实现跨模态特征融合的能力。在KITTI和Waymo开放数据集上进行的大量实验表明,与最先进的多模态方法相比,该方法可以获得更好的性能。
领域的一些工作
基于激光雷达的三维目标检测
基于点的方法:这些方法[33,34,42,40]采用原始点云并使用堆叠的MLP层来提取点特征。PointRCNN使用PointNets作为点云编码器,然后基于提取的语义和几何特征生成建议,并通过3D ROI池操作对这些粗略proposal进行细化。Point GNN设计了一个图形神经网络来检测3D目标,并在相邻图形附近的固定半径内对点云进行编码。由于点云无序且数量庞大,基于点的方法通常会面临较高的计算成本。
基于体素的方法:这些基于体素方法[57,63,6,41,20,39,27]倾向于将点云转换为体素,并利用体素编码层提取体素特征。SECOND提出了一种新的稀疏卷积层来代替原始的计算密集型3D卷积。PointPillars将点云转换为伪图像,并应用2D CNN生成最终检测结果。其他一些工作[6,39,20,41,26]遵循[57],利用3D稀疏卷积运算对体素特征进行编码,并以粗到精的两阶段方式获得更准确的检测结果。最近的CT3D[38]设计了一种通道式transformer架构,以最小的手工设计构成3D目标检测框架。
基于图像的3D目标检测
许多研究人员也非常关注如何使用相机图像进行3D检测[24,60,25,9,36]。具体而言,CaDDN[36]设计了一个Frustum特征网络,将图像信息投影到3D空间中。通过点云投影直接引入深度仓,并使用非参数化模块将图像特征提升到3D空间。LIGA Stereo[9]利用基于LiDAR的模型来指导基于立体的3D检测模型的训练,并实现最先进的立体检测性能。尽管相机是最常见的传感器,而且价格低廉,但由于缺乏准确的深度信息,基于图像的方法的性能仍然不如基于激光雷达的方法。
多模态3D目标检测
多模态3D对象检测已经受到越来越多的关注,它可以最大限度地利用每个单一模态的互补信息。融合有两个级别:决策级融合[17,4,32,53,29]和特征级融合[56,59,49,55,14,43,21,22]。以前的融合方法[29]直接集成每个模态的检测结果。他们的表现受到每个阶段的限制。对于多模态数据融合的特征级融合方法,AVOD利用点云BEV以及图像特征,并将特征馈送到区域建议网络(RPN)中,以提高检测性能。F-ConvNet遵循[32],利用平截头体点云和前视图图像进行3D目标检测。PointFusion和PointPainting通过经过良好预训练的图像语义分割网络[10],用相应的类别预测分数增强原始点云。EPNet[14]将点云投影到图像平面中,以逐点方式以多级分辨率检索语义信息。MVXNet[43]利用预先训练的2D检测器[37]产生语义图像特征,以在早期阶段增强体素特征表示。这些方法仅利用图像中包含的丰富信息的一部分,并遭受严重的信息损失[51]。3D-CVF[59]将图像特征提升到密集的3D体素空间,但通过交叉视图空间特征融合策略融合BEV中的多模态特征。虽然已经提出了许多多模态网络,但它们并不容易优于先进的仅基于激光雷达的检测器。这些融合方法在点云特征和语义图像特征之间建立了粗略的关系,此外,它们还因透视投影而遭受严重的信息损失。现有的融合方法在跨模态融合中没有利用对象级语义信息的相似性,本问的方法旨在克服这些挑战,实现更好的3D检测性能!
论文的方法
模型框架
所提出的同质多模态融合与交互(HMFI)方法的总体架构如图2所示。首先利用点编码网络来提取点云的特征,然后将它们合并以获得体素特征P∈ ,其中是体素特征的通道数,,,是网格大小。

图像被馈入ResNet-50主干,以提取图像特征,为了融合三维空间中的点云特征和图像特征,论文还提出一种图像体素提升模块(IVLM)来投影图像特征F进入3D均匀图像体素空间,作为。然后,使用查询融合机制(QFM)融合同质点体素P和图像体素I,生成融合表示。之后,使用检测模块基于P生成每个目标的分类和3D框。同时,提出了一个体素特征交互模块(VFIM),用于基于检测结果在目标级进行特征交互,以提高这两个同质交叉模态特征的语义一致性。
图像体素提升器模块
为了有效地编码图像中的感知深度信息并构造用于多模态特征融合和交互的均匀结构,本文提出了图像体素提升模块(IVLM),通过将图像特征与离散化深度图相关联来将2D图像特征提升到3D空间中。该过程如图3所示。为了构建图像特征体素,遵循[30,36],将图像平面特征转换为截头体特征G,截头体可以对图像特征中的深度信息进行编码。因此,我们散射图像 feature map F中的每个像素(m,n)的矢量沿图像平截头体透视投影线投影到由depth bin ,确定的3D空间中。

查询融合机制
为了利用点云和图像的互补信息,论文引入了查询融合机制(QFM),该机制使每个点云体素特征能够感知整个图像,并选择性地组合图像体素特征。文章认为LiDAR体素可以感知整个图像体素特征,而不是简单地融合跨模态体素对。为了有效地聚集两种模态的互补信息,建议使用自关注模块[48],将图像和点云的每个体素特征向量视为同质标记。更具体地说,使用点云体素特征FP作为查询,图像体素特征FI作为键以及用于进行融合并形成融合体素特征P的值∗。


体素特征交互模块
激光雷达和相机在场景尽管模态彼此不同,但目标级表示应该相似。基于这一观察,设计了一个体素特征交互模块(VFIM),基于点云和图像中目标级属性的一致性,在这两个跨模态特征中构建特征交互。并且可以充分利用同质特征P和I之间的相似性约束和目标级引导,以实现更好的跨模态特征融合。

如图4所示,我们对来自3D检测头的N个3D检测方案进行了采样,即,,,。然后,我们在均匀点体素特征P和图像体素特征I上引入体素RoI池[6],以获得相应的RoI特征,包括,,,和,,,。最后,受[5]的启发,改进了输出向量之间的相似性根据成对的RoI特征和,将它们都输入编码器Ω 并使用基于MLP的预测器ψ将这些编码的RoI特征的输出转换为度量空间!

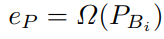


损失函数
在以前的方法中,图像主干直接使用来自其它外部数据集(如ImageNet)的固定预训练权重进行初始化。相反,论文的HMFI通过端到端的两阶段流程进行训练,论文利用多任务损失函数来联合优化整个网络,总损失可表述为:



Experiments
论文主要在KITTI和Waymo Open Dataset上进行评测!KITTI是一个广泛使用的数据集。它包括7481个训练帧和7518个测试帧,包括街道上汽车、行人和骑自行车的人的2D和3D注释。根据物体的大小、遮挡程度和截断程度,物体被分为三个难度级别:容易、中等和难。为了验证,训练样本通常分为3712个样本的训练集和3769个样本的val集。Waymo开放数据集(WOD)是一个用于自动驾驶的大规模数据集,共有798个场景用于训练,202个场景用于验证。每个场景是一个连续片段,具有大约20秒的传感器数据。请注意,WOD中的相机仅覆盖250° 视场(FOV),不同于全360中的LiDAR点和3D标签。为了遵循KITTI的相同设置,只选择前摄像头视场中的激光雷达点和地面实况进行训练和评估,从所有训练样本中每隔5帧采样一次,以形成新的训练集(∼32k帧)!
实验细节
在KITTI基准上,将点云的范围设置为(x,y,z)轴上的[0,70.4],[-40,40],[-3,1]m。LiDAR体素结构除以体素大小(0.05、0.05、0.1)m,同时将每个图像体素大小设置为(0.2、0.2、0.4)m,以与点云分支的特征大小相匹配。
对于Waymo,我们使用[0,75.2],[-75.2,75.2],[-2,4]m作为点云范围,使用(0.1,0.1,0.15)m作为体素大小。并且将每个图像体素大小设置为(0.4,0.4,0.6)m以适合点云特征大小。在QFM中,比例因子λ设置为4,注意头的计数r和隐藏单位分别设置为4和64。在VFIM中,体素RoI池操作的设置与体素RCNN[6]相同,对N=128个提案进行采样,其中一半是IoU>0.55的阳性样本,带有相应的gt box,编码器的隐藏单元数Ω 并且预测器ψ都被设置为256。
训练:为了验证HMFI的有效性,选择Voxel RCNN作为基线。本文的HMFI通过两阶段流程进行训练,采用OpenPCDet作为代码库,并采用预先训练的ResNet50作为2D骨干,以产生图像特征F,用于图像体素提升器模块。使用Adam[15]优化器训练模型,该优化器使用单周期策略[44],初始学习率为0.0005。批量大小设置为2。对于KITTI[7]和WOD[45],训练时期的总数设置为80个。
KITTI测试集上性能对比(可以看到骑车的人提升非常明显):


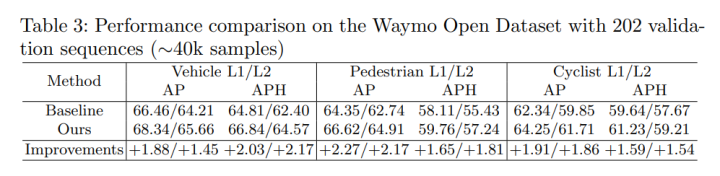
Waymo测试集与验证集上的结果:
消融实验
查询融合机制的效果:查询融合机制(QFM)根据图像特征和点云特征之间的关注图,根据它们的相关性选择性地组合图像和点云特性。在表4中,观察到QFM可以生成增强的联合相机LiDAR功能,并在APEasy、APMod、APHard分别获得增益:0.83%、0.58%、 0.62% 。
多模态特征结构的影响:在表4中观察到,IVLM可以在APEasy、APMod和APHard中带来0.35%、0.60%和0.72%的性能增益。IVLM利用点云体素特征将图像特征提升到同构空间,这不仅有助于特征融合,而且能够实现两个同构特征之间的对象级语义一致性建模。
体素特征交互的效果:论文观察到,体素特征交互模块(VFIM)在APEasy、APMod和APHard中分别将基线提高了0.84%、0.95%和0.53%。这表明VFIM在本文的多模态检测框架中起着关键作用。它可以提高两个同质特征之间的对象级语义一致性,并使检测器能够基于对象级语义相似性跨同质表示聚合成对特征。

参考
[1] Homogeneous Multi-modal Feature Fusion and Interaction for 3D Object Detection.















 3162
3162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









