






作者 | 王杰 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/584827087
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【深度估计】技术交流群
后台回复【深度估计综述】获取单目、双目深度估计等近5年内所有综述!
前言
在智能驾驶场景中,深度估计已被认为是最重要的感知任务之一。尽管环视近场条件下可利用超声波雷达来获取近距离深度信息,但却很难得到更有价值的语义信息。虽然基于图像的深度估计方法已在学术界被广泛研究,但一来因为标注难度和成本,通用的单目深度估计方法难以量产;同时环视近场感知采用了鱼眼镜头,其大径向畸变给深度估计带来比较大的挑战。幸运地是,车载鱼眼相机可以记录工况视频,利用视频帧间几何约束,可以实现自监督深度估计。在此基础之上,本文还延展出一种无需畸变矫正的深度估计方法,以便适用于各类相机参数和装配条件,满足量产要求。
背景
深度估计一直都被视为视觉感知比较有挑战的任务之一,尤其会面临无纹理区域、遮挡、非朗伯表面等等。尽管采用2D图像恢复3D结构信息极具吸引力,但由于3D信息投影到2D表面必然会损失深度信息,使得其难度较大。在当前技术条件,LiDAR是最好的主动测距传感器,但其价格感人,仍面临量产难题。
深度估计是个病态问题
从一张RGB图像中恢复场景的深度信息一直被认为是一个病态问题。如图1所示,不同的3D场景可以对应同一个2D平面。
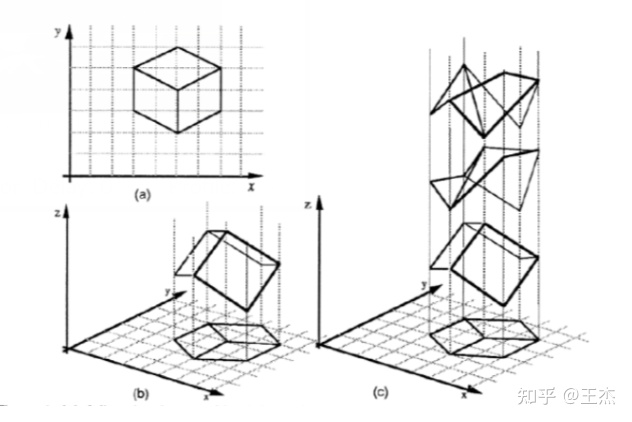
单目深度估计存在尺度混淆
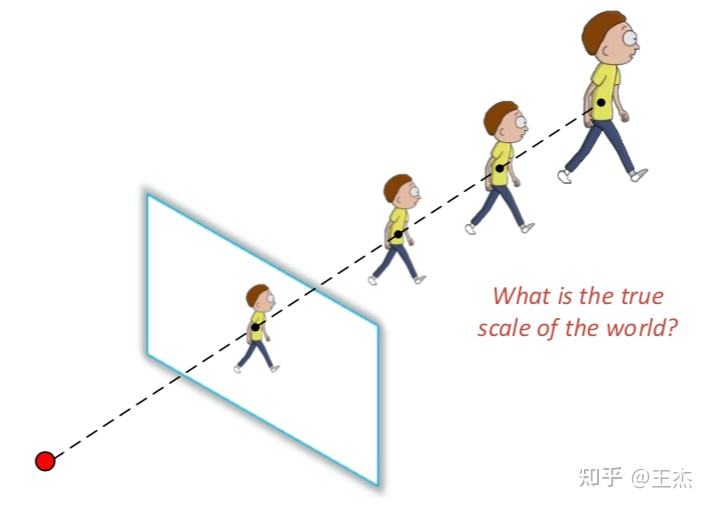
如图2所示,对于任意给定相机模型,通过调节焦距可以同比缩放像平面上的点;也即同一尺寸可能对应不同距离。因此,需要一个绝对值anchor来提供锚定,一般常用的方法如下:
采用外部传感器,如LiDAR或立体相机来测量至少一个点的绝对距离;但这个方法需要严格准确的标定。通过训练数据与测试数据的深度一致性来进行标定,但很难满足实际量产需求。通过IMU、GPS或者轮速计等测量车速并与深度估计进行一致性关联;本方案在实际量产中使用较多。
动态物体打破静态世界假设
在SfM框架下,动态物体会使得深度估计计算过程更为复杂,尤其是在像素匹配和对齐过程中。
鱼眼相机挑战更大
在SfM框架下,视图合成方案一般仅在无畸变图像对上适用。在针孔相机模型中,深度一般与视差成反比;而对于球面图像,通过畸变矫正可获得角度视差。由于单目SfM目标限制,单目距离预测和ego移动预测均会产生尺度混淆的结果,难以实现在鱼眼图像上进行深度估计。
对于立体匹配算法而言,最大挑战在于镜面或半透明反射表面。例如,汽车挡风玻璃会降低匹配效果并导致错误估计。因此,大部分主机厂仍主要依赖LiDAR来实现深度测量。随着深度学习的快速发展,基于图像的深度估计技术取得巨大突破,有望成为量产的主流方案之一。
直接处理鱼眼图像的动机
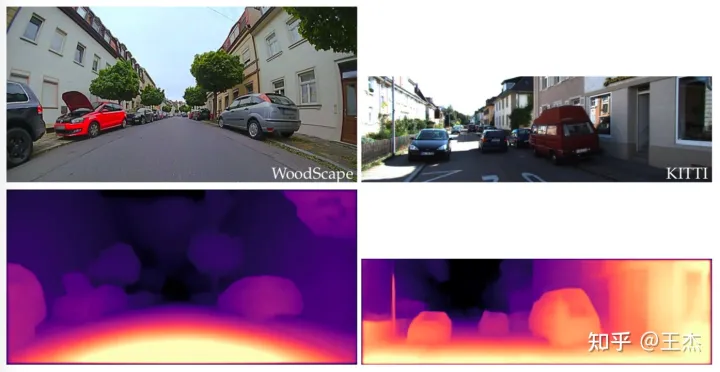
在立体相机中,对极几何约束常用于匹配计算;同时也扩展用于移动立体视觉。但对极几何约束的使用依赖于去除非线性畸变。Yadati等也论证了基于CNN的双视图深度估计在没有畸变矫正条件下是非常困难的。在KITTI数据集上尝试的大部分方法一般都采用桶形畸变矫正图像来处理。然而,环视鱼眼相机存在非常强的畸变,非常难以矫正。
图3第一排显示了一张具有桶形畸变的KITTI图像以及对应的矫正后的图片。其中红色框用于裁剪掉周边的黑色像素,但导致视场角损失。第二排则展示了具有鱼眼镜头畸变的WoodScape图像以及矫正后的图片,视角损失极大,导致30%的图像信息丢失。

视场减小只是去畸变带来的问题之一,鱼眼图像在实际量产中还面临另外两个严重问题。
重采样畸变。由于在图像畸变矫正中存在插值过程,导致图像周边存在非常大的畸变。
校正。在实际量产中,上百万个相机需要装配,它们存在各种公差;并且在不同的工况条件下,相机参数也会发生巨大变化(如环境温度会导致镜头焦距发生变化)。一般来说,数据采集和训练往往在有限的测试车辆和工况条件下中进行的,训练得到的模型直接部署到百万辆车上将会面临巨大挑战。因此设计一个能够直接处理鱼眼图像的算法模型会更加鲁棒,更能实现量产。
自监督尺度感知的深度估计方法
Zhou等人基于SfM框架提出一种自监督的单目深度估计方法:
学习一个单目距离估计模型:gd : It → D 学习一个ego移动预测模型:(It, It′ ) → It→t′,也即刚体变化的六个自由度 该方法不需要额外的标注数据,仅依赖RGB图像即可以实现,但仍然未解决尺度混淆问题。本文将介绍一种基于鱼眼图像的自监督尺度感知深度估计方法,如下图4所示。
视图合成是自监督深度估计中最关键的环节,通过原始图片It−1与It+1来合成It。针对鱼眼图像,最直接方法是先通过畸变矫正,然后再输入到Zhou等人提出的方案进行处理即可。但是否存在一个更高效更简单的方案呢?
鱼眼几何建模

相机坐标到图像坐标的投影
如在环视近场感知系列之鱼眼相机模型中介绍,相机坐标系下的三维空间点可以通过4阶多项式来表达其在图像坐标中的位置:

图像坐标到相机坐标的逆投影
根据上述相机坐标到图像坐标正投影变化公式,可以预先计算好入射角与图像坐标的关系,在实际计算逆投影时,仅需采用查表法即可快速得到结果,最终可获得3D空间的欧式距离:
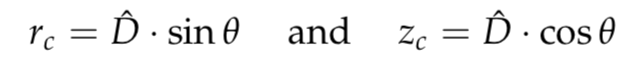
光度损失
通过深度信息,可以获得场景的3D点云信息,如下公式:
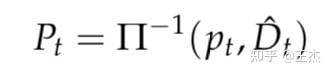
再加上姿态估计结果,即可获得下一时刻的3D点云信息,Pˆt′ = Tt→t′ Pt。将深度估计与姿态估计相结合,即可以获得下一刻视图重建结果,如下公式
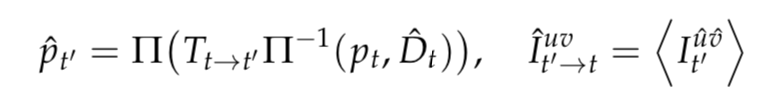
一般地,图像重建损失通常采用L1逐像素点Loss也即SSIM来评估,因此光度损失表达如下,
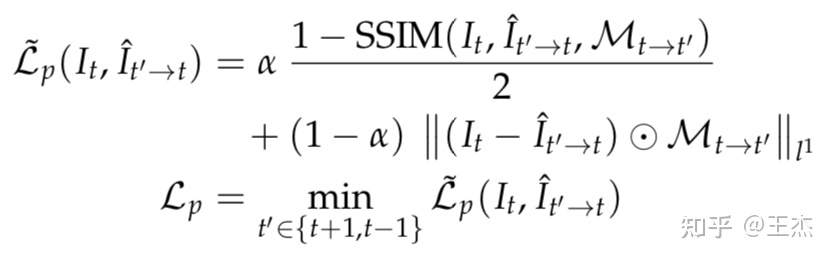
尺寸混淆
为了解决SfM框架存在的尺寸混淆问题,获得尺寸感知的深度估计结果,我们对姿态估计结果进行归一化并引入偏移参数,如下公式。其中偏移参数可以通过车辆的即时速度和时间差来进行计算。
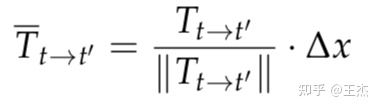
静态像素掩码和ego移动掩码
在训练中,我们引入了掩码方法来过滤静态像素,但同时该方法也会过滤掉与ego车辆相同速度的其他移动物体。因此,掩码计算并非来自物体移动估计,而是直接从光度估计中计算,如下公式:
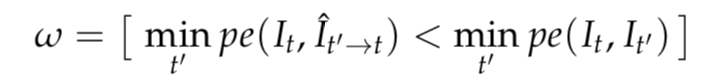
边缘感知的光滑损失
为了约束距离并且避免因遮挡和缺少纹理带来的发散值,我们引入一个几何光滑损失,如下公式:
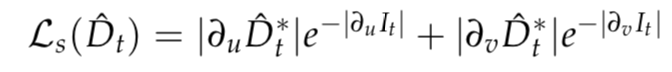
跨序列距离一致性损失
相邻两帧之间距离估计应该具备一致性约束,如下公式
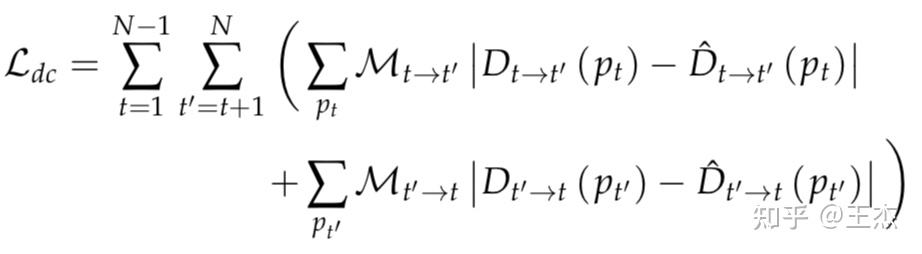
综合训练损失
为了防止训练目标陷于局部最小值,我们引入了4个缩放尺度来训练网络,如下所示:
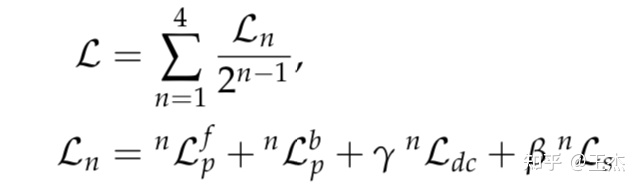
解决相机畸变模型
如图6展示了一种通用的自监督深度估计训练框架,可以适配各类相机畸变模型。其中畸变直接在逆投影和投影环节内部进行处理。本文也对桶形畸变的KITTI数据以及鱼眼畸变的WoodScape数据进行了测试。
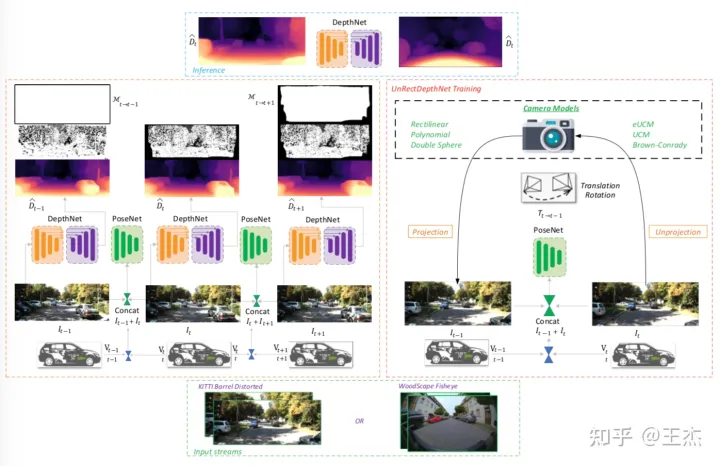
网络细节
一般地,深度估计网络通常采用encoder-decoder结构。主干网络这部分则选用了ResNet18作为编码器。常规的CNN网络由于其固定的核参数导致无法应对未知的几何畸变情况,因此我们选用了可形变卷积。一般来说,网络的中低层负责学习空间结构信息,如果此处采用可形变卷积,则会破坏深度估计与图像像素的空间对应关系。因此,可形变卷积只在最后几层网络结构中使用。

在以往公开的论文中,编码特征往往经过近邻插值来实现上采样。但这种方法最大的问题是在上采样深度图中物体边缘区域引入较大误差。此处,我们借鉴了超分辨中的次像素卷积来获得更锐利的边界。
实验分析
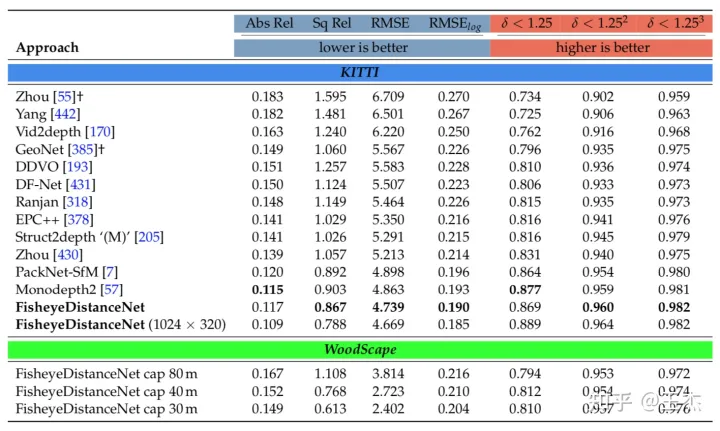
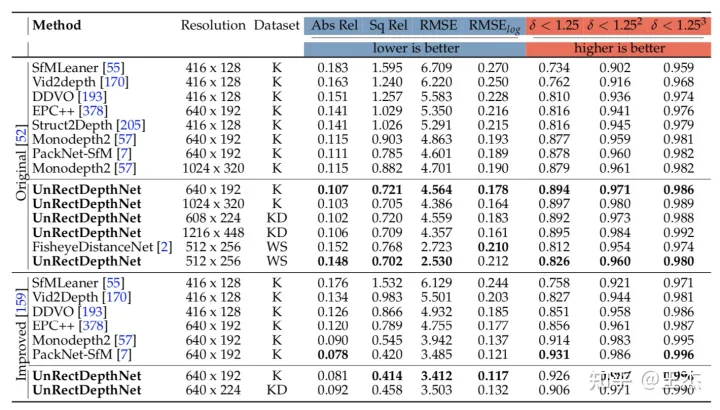
如图8和9所示,在KITTI和WoodScape两个数据集上,尺寸感知的自监督学习方法取得了SOTA的效果。
鱼眼消融实验
如下图10所示,我们对FisheyeDistanceNet模型的不同结构做了消融实验。

去除BS(Back Sequence)部分,对模型最后的效果出现了比较大的负面影响。
去除超分辨次像素卷积(SR):对模型最终效果同样产生了显著的负面影响。
去除跨序列一致性约束(CSDL):对模型产生了比较大的影响。
去除可形变卷积(DCN):模型基本失效,因为常规CNN无法很好地处理鱼眼畸变。
KITTI畸变消融实验
去除BS(Back Sequence)部分:对模型最后的效果出现了比较大的负面影响。
去除超分辨次像素卷积(SR):对模型最终效果同样产生了显著的负面影响。
去除跨序列一致性约束(CSDL):对模型产生了比较大的影响。

结论
本文针对自监督深度估计领域提出了两个针对原始畸变图像直接处理的新方法。一是采用自监督训练方法直接在无畸变矫正的鱼眼图像进行深度度量;二是提供了一种通用的自监督方案来处理各类畸变图像的深度估计。实验结果也应证了FisheyeDistanceNet和UnRectDepthNet在KITTI和WoodScape数据集上取得了SOTA效果。在KITTI数据集上,可以发现在无畸变矫正的原始图像上所计算的深度图,其精度与畸变矫正后的图像上所计算的结果基本一致。综合来看,基于CNN的深度估计方案有望实现量产,从而取代传统的深度计算方法。
参考文献
V. Kumar, S. Hiremath, M. Bach, S. Milz, C. Witt, C. Pinard, S. Yogamani, P. Mäder. “FisheyeDistanceNet: Self-Supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera for Autonomous Driving.” In the IEEE International Conference on Robotics and Automation (ICRA), 2020 [2].
V. Kumar, S. Yogamani, M. Bach, C. Witt, S. Milz, P. Mäder. “UnRectDepthnet: Self-supervised Monocular Depth Estimation using a Generic Framework for Handling Common Camera Distortion Models.” In the International Conference on Intelligent Robots and Systems (IROS), 2020 [3].
T. Zhou, M. Brown, N. Snavely, and D. G. Lowe, “Unsupervised learning of depth and ego-motion from video,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1851–1858.
往期回顾

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 9171
9171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









