






作者 | 派派星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群

Title: 3D Video Loops from Asynchronous Input
Paper: https://arxiv.org/abs/2303.05312
Code: https://github.com/limacv/VideoLoop3D
导读
开局一张图,内容全靠编写:

其实上面原本是一组异步多视图视频,为图省事,小编这里直接截了个图。本文提出了一个pipeline有效的构建出一个新颖的 3D 循环视频表示,其中图(a)是由一个静态纹理图集、一个动态纹理图集和多个作为几何代理的图块组成;而图(b)和图(c)则分别显示了此 3D 视频循环允许相应的视图和时间控制和在移动设备上进行实时呈现。
此外,有兴趣的同学可以直接访问项目主页[1]观看。如果想直接体验试玩 Demo 的小伙伴也可以直接访问这个地址[2]。打开来大概是这样子:

其中,左上角是实时参数显示,右上角可选配置,大家可以根据自己喜好调节。需要注意⚠️的是:
首先,点开网页后是一个实时渲染的动态的3D的视频,严格意义上来说是2.5D?各位小伙伴可以通过手指拖动或鼠标滑动来实时改变视角;
其次,在宽屏下体验更加,在手机上可以将手机横屏然后刷新一下网页;
最后,由于本项目是托管在Github页面上,所以加载起来可能比较慢(取决于你的设备)并伴随一丝闪烁,不过这都属于基操,大可不必担心。
下面就让我们一起跟随作者的视角和讲解一起进入今天的学习吧!
论文简介
本文主要提出了一种能从不同步的多目视频中重建出一个 3D 的动态循环视频方法,同时应用了一种能较好的压缩 3D 视频的场景表示,且能够做到在手机端实时渲染出来!
目前代码和数据集均已开源,感兴趣的朋友们帮忙多多点个
star,感谢大家的关注!
在正式深入具体方法之前,有必要向大家阐明几个基础概念。
什么是 3D 视频?
3D 视频本意上是指会动的三维场景或者可以在任意视角下看的三维视频。注意,这个跟大家耳熟能详的那种 3D 电影还是有区别的,因为 3D 电影的视角其实只有两个,即左眼和右眼。
什么是 3D 循环视频?
3D 循环视频是指在 3D 视频基础上,整成一个循环视频(looping video)。此处循环的意思是从视频最后一帧切换到第一帧时,肉眼看不出明显的切换痕迹。这样做有一个明显的好处,那便是对于本身就接近循环的场景而言,我们只需要一段短视频,就可以源源不断的生成无穷无尽的视频。
它的具体应用有哪些呢?比如用于一些网页的teaser、配图甚至是当作一些虚拟背景,例如虚拟会议的背景,VR 应用的背景等等。
什么是不同步的多目视频?
这其实是一个不严格的定义,对于这个方法的输入而言,我需要在不同视角下拍一段视频,每一段视频需要基于同一视点(可以简单的理解为相机位姿不变),但是不同视角的视频可以不同步,即可以用一个相机分别在不同的视角拍摄,像这种完全不同步的数据本文方法也是可以handle得住的。
相关工作
构建2D循环视频
这其实是个比较小众的方向。之前的方法大致的做法是输入一个视角不变的视频,相当于我们有 的一个视频;随后,我们通过优化方法得到每个像素位置的最佳循环,即对于 个像素,每个位置在 帧中取出一个较好的循环片段,这个片段的结尾和开头的差别不能太大。最后,我们便能重新组合出一个新的视频。此外,通过利用一些blending的操作,我们还能够吧一些不太连续的视频片段变得看起来像连续的。
感兴趣的童鞋可以看下这篇论文[3]。
3D 视频表示
其实 3D 视频本身就是一个发展中的方向,因为即使对于静态场景而言,重建出比较好的 3D 视觉表示也是一件比较困难的事情。其次,对于动态视频而言,又增加了一个维度,所以会导致问题难上加难。
最近有几个用NeRF来重建3D视频的工作,都非常不错,之后有时间来系统整理一下这方面的工作。但是这篇文章没有用NeRF,或者TensorRF,Triplane,NGP等NeRF-like的 3D 场景表示,主要是因为NeRF的训练非常占显存!特别是如果在训练过程中一次性训练一个大的video patch,对于NeRF-like的场景表示来说GPU memory占用是不可想像的。作者大致估算了下,如果用NeRF来优化本文中的方法,需要大概6TB的显存,直接Go die~~~
MPI 场景表示
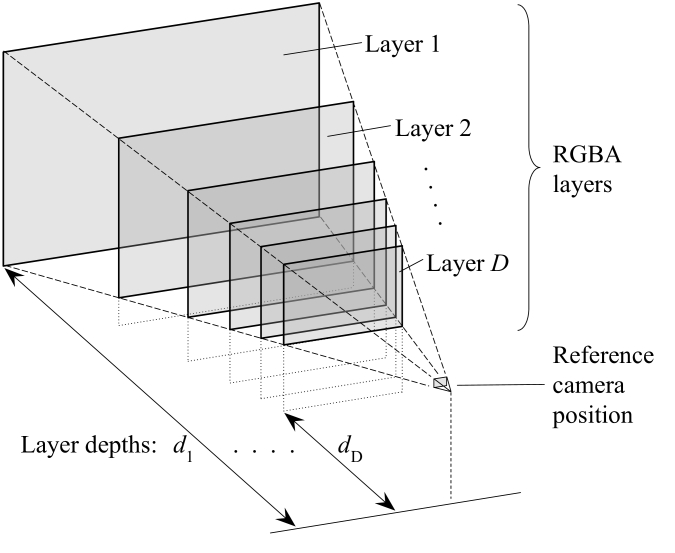
Multiplane Image,意指多层图像。这篇文章的 3D 视频表示,是基于MPI的,就是看中它渲染和优化都比较快。它的原理其实十分简单,看下图就能一眼看懂。简单理解就是分布在视锥体下的一层一层图片,每一层图片带有一个透明度的alpha通道。这样渲染的时候只要从远到近,开启alpha-blending就可以得到最终的结果。
方法
MTV场景表示
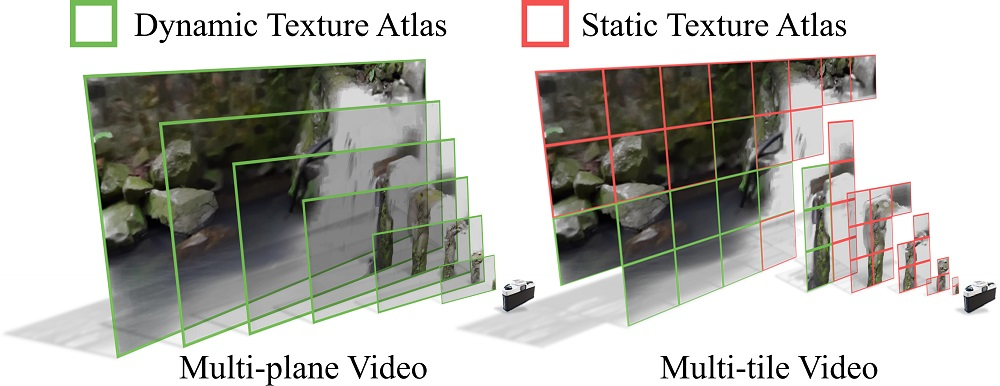
前文中提到本文方法是基于MPI的原理。但这里存在一个问题:如果我们非常直接的将MPI拓展到动态视频,它将会占用非常大的存储资源。举个例子,对于 32 层的 MPI,有 60 帧视频,图像分辨率为 640 x 360,那么将需要 个浮点字节来存储这个表示。
因此本文提出了Multi-tile Video,该想法非常好理解,就是我们把这些plane给细分成一个个tile,对于静态的部分来说,我只需要存储一个tile;对于空的tile来说,直接扔掉就可以了。如此一来,只有对于动态的场景来说,我才需要每帧存储一个tile。读到这里,确实有种大道至简的感觉!
3D 循环视频优化
有了场景表示,我们就可以通过输入的多目视频对其进行优化。此处,我们采用了和NeRF类似的优化方法:Analysis-by-synthesis,即通过可微分渲染得到结果,与输入做loss之后将error的梯度回传到表示本身。这里,应用了一个两阶段的训练方法,如下图所示:
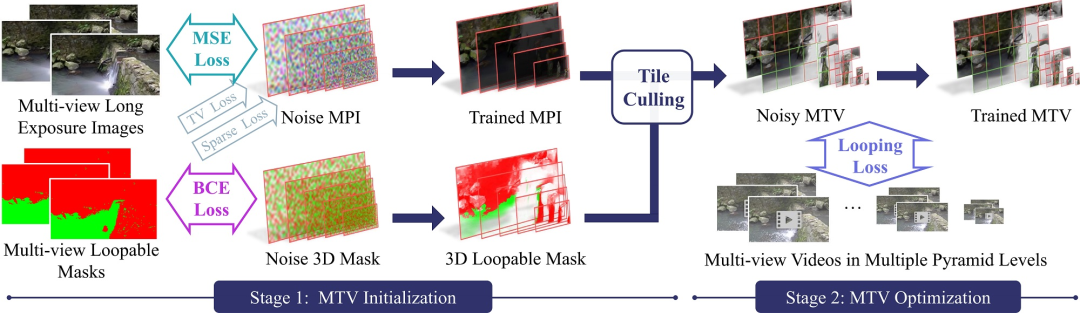
第一阶段
首先优化一个静态的MPI。我们从输入计算得到长时间曝光的图片以及静态与否的一个Mask,经过刚刚所述的优化方法可以得到两样装备,即静态的 MPI 以及 3D 的静态与否的一个 Mask。有了这两样东西,我们就可以对我们的 MPI 进行 tile 的划分以及取舍了。
具体的操作方法其实也很直观:
将每个
plane划分成规律的tile;对于每一个
tile,找到它里面最大的透明度,最可能是动态的Mask;根据这两个值来判断是否将当前
tile丢弃,或者将它设为静态tile;
这样一来,我们便能获得了一个完整的MTV表示。
第二阶段
此阶段可开始优化动态的MTV。如上所述,基于同样的优化方法,我们将每一个iteration渲染一个视频patch,然后与输入求loss。值得关注的是,此处我们新提出的一个looping loss,该方法受此篇文章[4]启发。具体的思想参照下图:
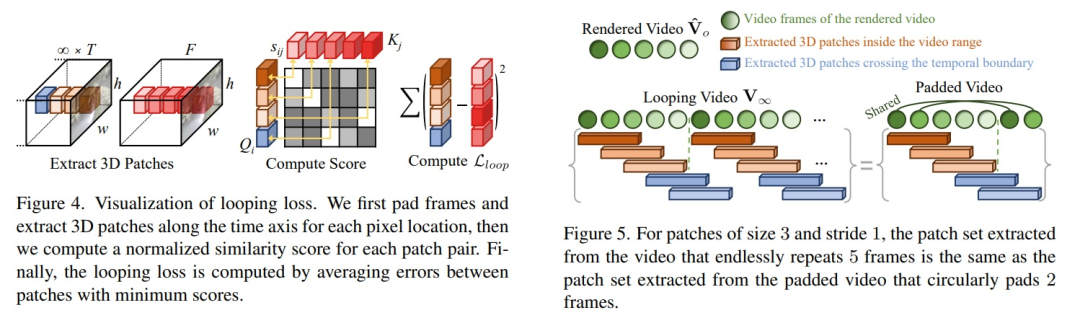
为了计算这个loss,我们首先对每个pixel对位置采取同样的策略。对于每一个像素位置,我们先在输入视频和生成视频的时序上提取所有的3D patch。其次,对于这两组3D patch,我们会计算一个相似性分数;最后,我们再对最相似的两个patch进行一个简单的MSE的计算,然后把所有3D patch对的MSE加起来,就得到了我们的looping loss。
需要注意的是,在提取patch的时候,我们要提取的应该是最终循环视频的patch。换句话说就是有无限多的patch需要提取,这显然是不现实的,但是根据上图我们可以看到,其实只要对生成的短视频加上几帧pad,提取出来的patch就和原来无限多patch的分布是一样的。惊不惊喜,意不意外?
效果


更多 Demo 请上项目主页查看。
局限性
合成结果仍然会包含一些伪影,即本不应该出现但却出现的东东;
它无法对复杂的视图相关效果进行建模,例如非平面镜面反射;
本文假设场景具有循环模式,这最适合流水和摇曳的树木等自然场景。然而,如果场景不可循环,所提方法将会失败,因为每个视图都有完全独特的内容;
使用的 MTV 表示实际上是 2.5D 表示,仅支持具有窄基线的合成新颖视图。
总结
本文提出了一种实用的解决方案,用于在给定完全异步多视图视频的情况下构建 3D 循环视频表示。实验验证了所提方法的有效性,并证明在几个基线上质量和效率有了显着提高。作者希望这项工作将进一步推动对动态 3D 场景重建的研究。
References
[1]
Project: https://limacv.github.io/VideoLoop3D_web/
[2]Demo: https://limacv.github.io/VideoLoopUI/
[3]Fast computation of seamless video loops: https://hhoppe.com/fastloops.pdf
[4]looping loss: https://arxiv.org/pdf/2103.15545v1.pdf
往期回顾
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)

国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









