







目录
论文标题:Multi-Modal Neural Radiance Field for Monocular Dense SLAM with a Light-Weight ToF Sensor
论文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Liu_Multi-Modal_Neural_Radiance_Field_for_Monocular_Dense_SLAM_with_a_ICCV_2023_paper.html
代码:https://zju3dv.github.io/tof_slam/
引用:Liu X, Li Y, Teng Y, et al. Multi-Modal Neural Radiance Field for Monocular Dense SLAM with a Light-Weight ToF Sensor[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 1-11.

导读
这篇论文的主要目标是设计一种新型的dense SLAM(Simultaneous Localization and Mapping,同时定位与地图构建)系统,该系统的输入由单目相机的 RGB 序列和轻量级 ToF(Time-of-Flight)传感器的稀疏信号组成。dense SLAM在增强现实、室内机器人等领域有广泛的应用,现实生活中通常需要高精度和高分辨率的深度传感器,如ToF传感器或结构光传感器。然而,由于这些传感器在尺寸、重量和价格方面存在限制,因此直到最近才在少数高端移动设备中得以应用。
与此相反,轻量级ToF传感器具有成本效益高、紧凑且节能的特点,已经整合到数百种智能手机型号中。因此,本文的目标是充分利用这些轻量级ToF传感器,以实现dense SLAM,从而进一步促进增强现实、虚拟现实等应用的发展。
本文提出了第一个使用单目相机和轻型ToF传感器密集SLAM系统。具体来说,本文提出了一种多模态的隐式场景表示,支持对来自RGB相机和轻量级ToF传感器的信号进行渲染。同时,还引入了深度估计模型,以预测中间的高分辨率深度,以提供额外的监督。最终,本文还开发了一种时间滤波技术,以增强轻量级ToF传感器信号和深度预测性能。
本文贡献
-
本文首次提出了基于轻量级ToF传感器和单眼相机的稠密SLAM系统
-
本文提出了一种多模态的隐式场景表示方法,支持渲染来自RGB相机和轻量级ToF传感器的信号。这个表示方法允许系统同时处理不同领域的输入信号,有助于实现准确的相机姿态跟踪和精细的场景重建。
-
为了提高轻量级ToF传感器的信号质量,作者引入了深度估计模型,用于预测中间的高分辨率深度信息。
-
为了解决嘈杂信号和数据缺失的问题,作者开发了一种时间滤波技术,以增强轻量级ToF传感器信号和深度预测性能
本文方法

本文的方法使用一个单目相机和一个轻量级的ToF传感器作为输入,同时恢复相机运动和场景结构。通过可微分渲染技术,本文的方法能够渲染多模态信号,包括彩色图像、深度图像和区域级别的L5信号。通过最小化重新渲染损失,优化场景结构和相机姿态。
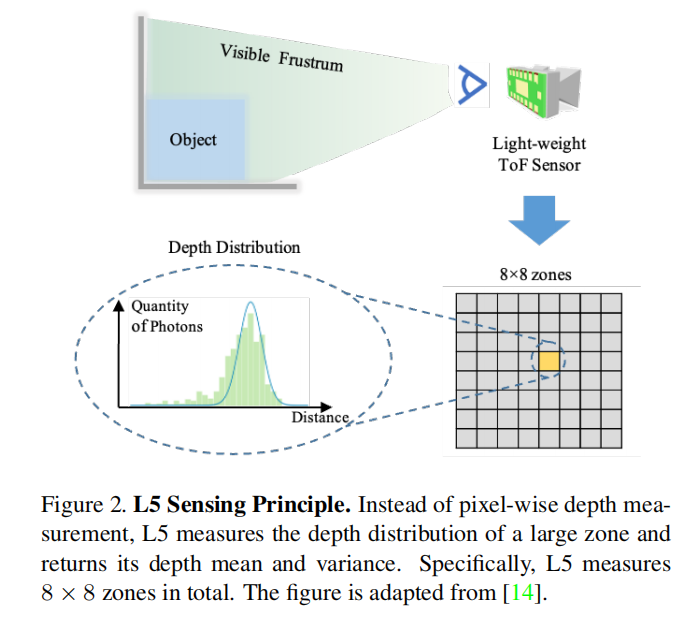
轻量级ToF传感器的感知原理
轻量级ToF传感器旨在低成本、小尺寸和低能耗,并已大规模部署在移动设备上。与传统的ToF传感器相比,传统的ToF传感器提供高分辨率的深度测量,并测量到场景中每个像素的距离。
轻量级ToF传感器通常具有极低的分辨率(例如,8×8个区域),并测量每个区域的深度分布。在这里,我们以ST VL53L5CX [29](简称为L5)作为轻量级ToF传感器的代表,介绍这些传感器的感知原理。
如图2所示,L5通过计算在特定时间间隔内接收的光子数来测量深度分布。然后,结果被拟合为高斯分布,L5仅传输均值和方差以减少能耗和宽带负载。由于其低分辨率和高不确定性,以往的研究中没有探讨过将L5用于SLAM等下游应用。
多模态隐式场景表示
几何编码与蒙版渲染
作者采用了一种被称为"Masked Rendering"的方法,灵感来自于MipNeRF中提出的集成位置编码(IPE)理论。这个方法被推广到了基于网格的场景表示中。
IPE的核心思想是通过低通滤波器传递输入特征,即如果特定特征的频率具有大于射线的周期,则该特征不受影响;否则,该特征将朝零缩小。
在网格表示的情况下,作者将来自不同级别特征网格的特征串联在一起,并使用渲染蒙版来根据当前渲染尺度屏蔽来自过高空间频率网格中提取的特征。作者将场景几何编码为包含四个层次的多级特征网格,其中包括区域级别的特征网格和像素级别的特征网格。作者使用蒙版渲染技术在几何编码中进行渲染,以同时获得区域级别的L5信号和像素级别的深度图像。
颜色编码
对于颜色信息,作者仅在最精细级别使用一个单独的特征网格和解码器来进行编码。在解码颜色时,作者还使用了射线方向,以获得3D点的颜色值。
L5信号、颜色和深度图像的渲染
作者使用体积渲染技术来渲染颜色和深度值。具体来说,对于每个颜色像素,沿着发射的射线采样N个点,并通过累积透明度和颜色值来获得最终的颜色像素值。
对于L5信号的渲染也类似,不同之处在于,对于每个L5区域的均值深度值,作者从该区域的中心发射射线,并通过累积距离值来获得最终的深度值。
渲染监督
最终,渲染出的颜色图像、L5信号和深度图像被用于监督系统,以进行相机姿态跟踪和地图构建。深度图像的监督还包括来自之前深度估计模型的深度预测。
时间滤波技术
正如前面提到的,我们使用DELTAR [14]来预测像素级深度图作为额外的监督。DELTAR是一个经过预训练的神经网络,它以L5信号和RGB图像作为输入,并预测相应的深度图。
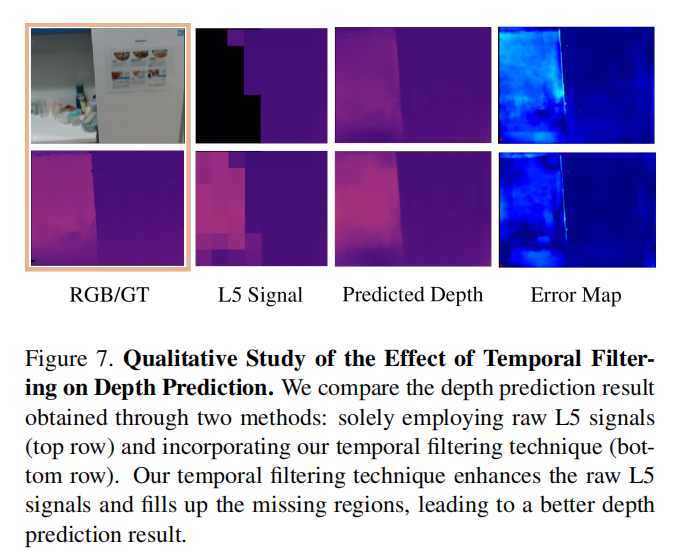
我们观察到,当存在大量缺失或嘈杂的L5信号时,DELTAR预测的深度图可能会因缺失或嘈杂区域的固有深度模糊而包含严重伪影,从而进一步污染隐式特征的学习并降低SLAM系统的性能。这促使我们开发了一种显式的时间滤波技术(图4)
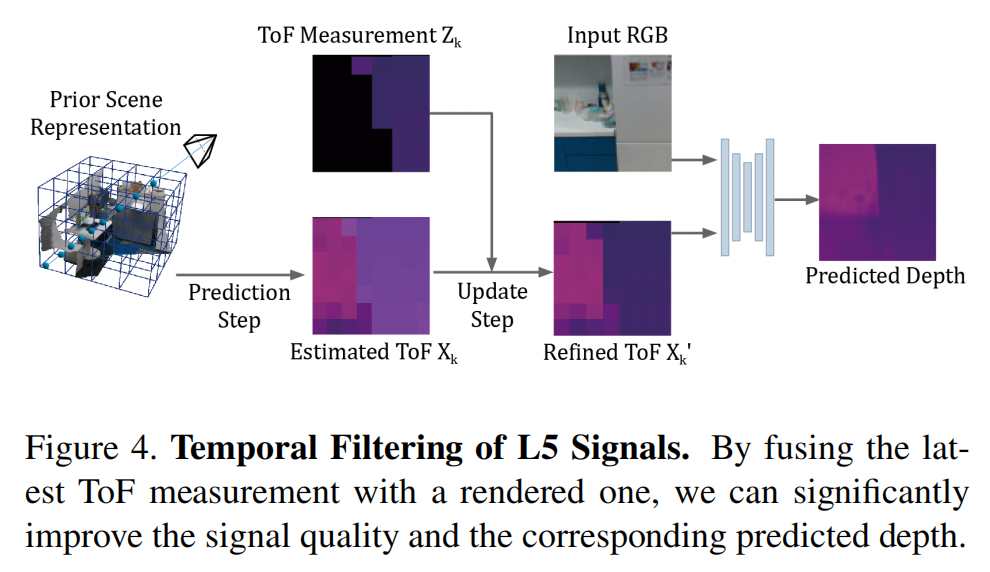
具体来说,所提出的滤波算法包含两个步骤:预测步骤和更新步骤。
在预测步骤中,我们使用具有初始化姿态的神经渲染(Eq. 4)来预测时间戳k中的每个区域的ToF测量Xk = {µ1, σ1}:

然后,使用当前的 L5 测量 Zk = {µ2, σ2} 来更新 Xk 为 X'k :
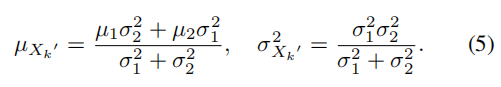
实验
实验结果
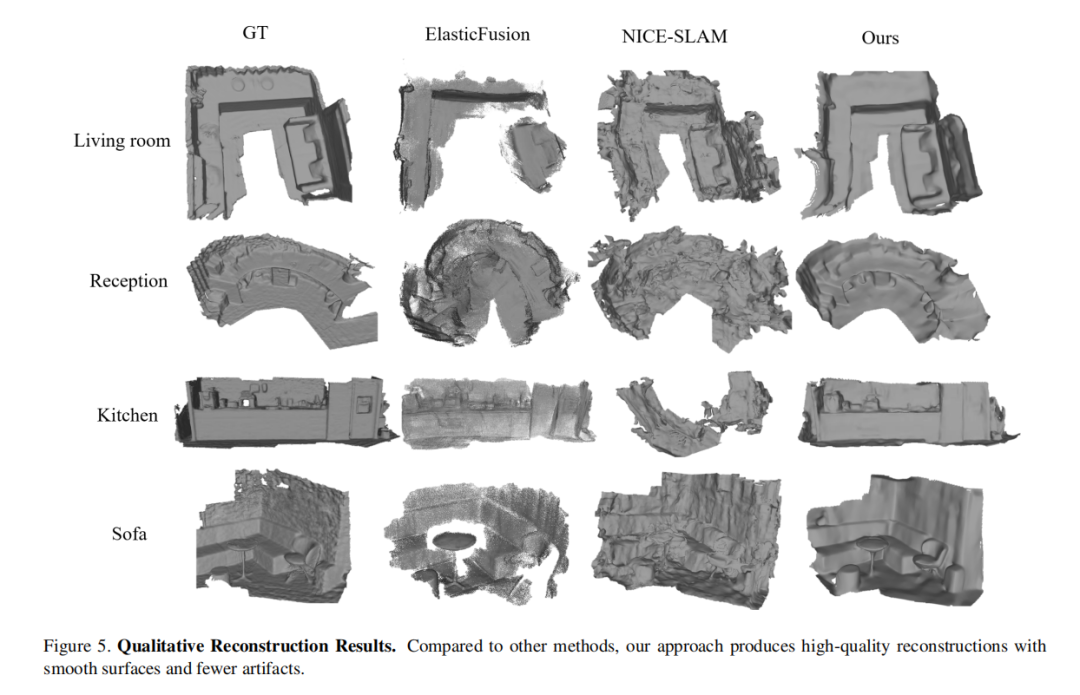
定性重建结果:
没有像素级深度监督的结果:
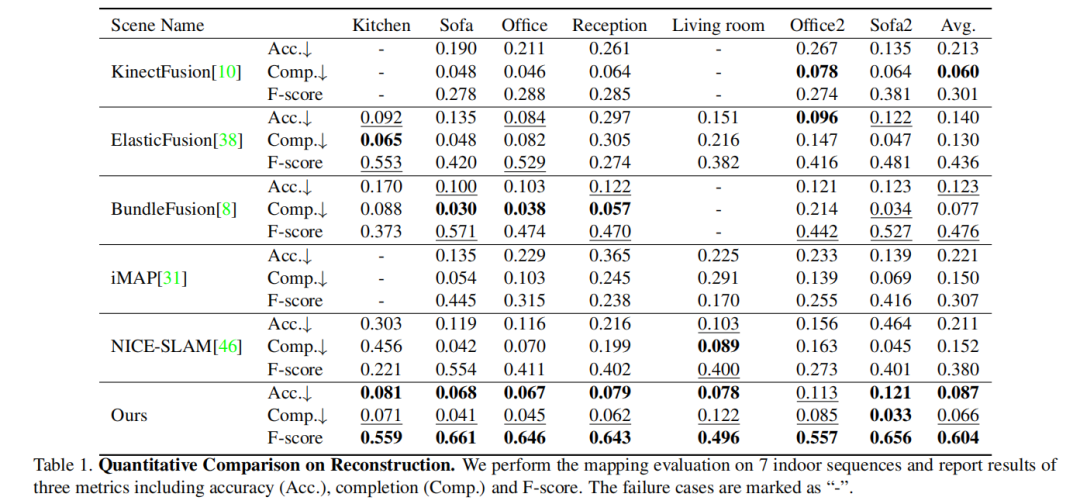
重建过程中的定量比较:
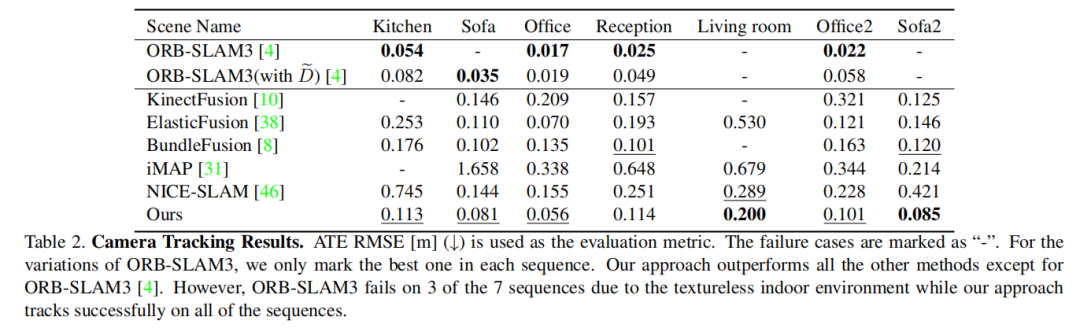
相机跟踪结果:
消融实验

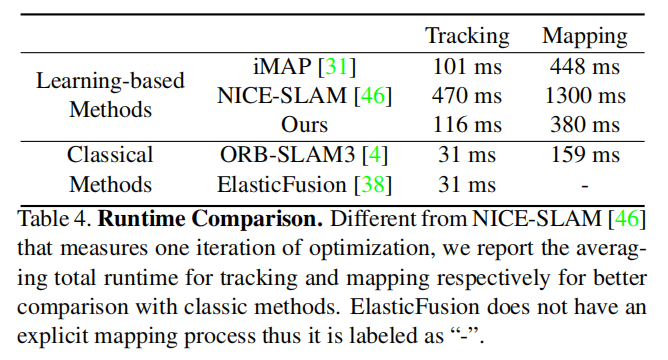
运行时间比较:
结论
本文提出了一种新颖的稠密视觉SLAM框架,使用RGB相机和轻量级ToF传感器,采用神经隐式场景表示。为了适应这种新的输入方式,论文提出了一种新颖的多模态特征网格,可以同时用于ToF传感器的区域级别渲染和其他高分辨率信号的像素级渲染。为了确保稳健的跟踪和地图构建,论文利用每个像素的深度预测作为附加监督,该监督进一步通过一种新颖的时间滤波策略进行改进。实验证明,所提出的方法能够在室内场景上提供准确的相机跟踪和高质量的重建结果。
未来工作
进一步改进系统,以克服ToF传感器在室外场景中的限制,并使其足够高效,以在移动机器人上运行。



















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











