






作者 | Malignus 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/570448121?
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【车道线检测】技术交流群
后台回复【车道线综述】获取基于检测、分割、分类、曲线拟合等近几十篇学习论文!
距离Tesla的AI Day也已经过去了几天啦~知乎上很多大佬也谈了自己对整个ai day的感受,对于我自己目前的菜鸡水平而言,可能唯一能够读的比较明白的就是关于车道线检测部分~这里简单的抛砖引玉,大概说下我自己的一个梳理以及个人理解~也欢迎大家多多讨论。
Old Version (Tesla上车的老版本,针对高速场景的monocular perspective view)
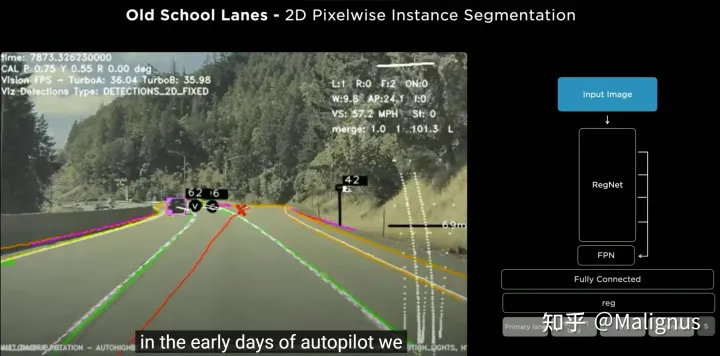
2D的像素级细粒度实例分割任务(基于图片的透视投影直接预测)
属性较为单一,只包括车道线,邻接车道线,汇入汇出的额外属性
从后续的结果来看,这种预测基本只适配高度结构化的场景(高速,郊区,总之不能拐角度大的弯,不能带路口)
Problem with the old version
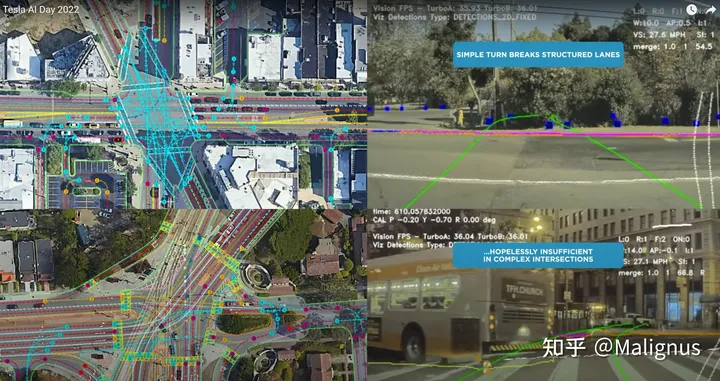
城市场景中的大量90°角及以上的拐弯,破坏了这种高度结构化的场景.
没有地图信息的情况下对于复杂的路口场景预测还是很吃力。
Result: Old version breaks down in urban scenarios.
New Version (Tesla当前基于环视相机&粗糙路网信息构建的lane net)
Target:
Produce the full set lane instances and their connectivity to each other.
Formulation
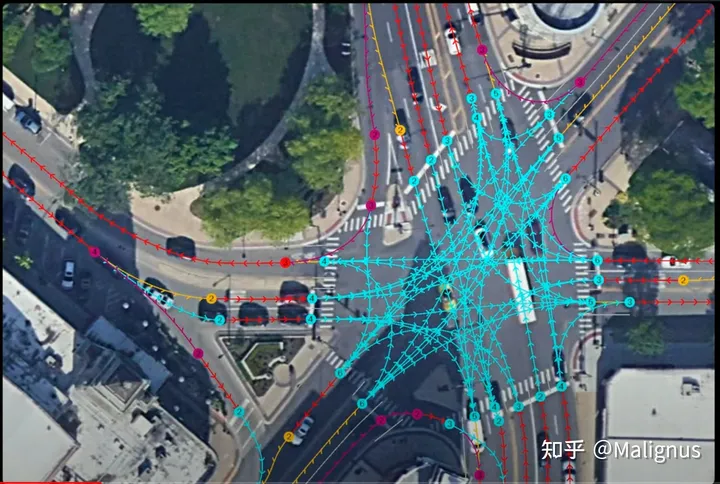
Predict a graph:
Node: lane segments.
Edges: connectivity of lanes.
Model
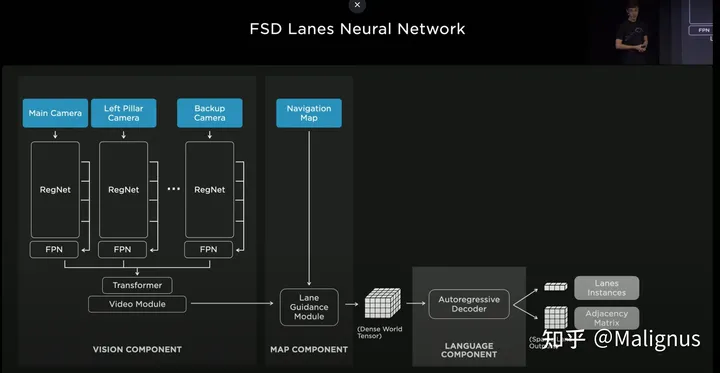
模型整体包括三个主要模块: Vision Component, Map Component, Language Component
Vision Component:
Input: 八个相机的视频流
Output: 视觉特征(估计应该是个3D的)
具体来讲,RegNet 作为backbone, 经编码后的特征输入至FPN. 随后使用transformer将不同的相机的特征进一步进行融合. 时序信息将通过video module进行引入。
Map Component:
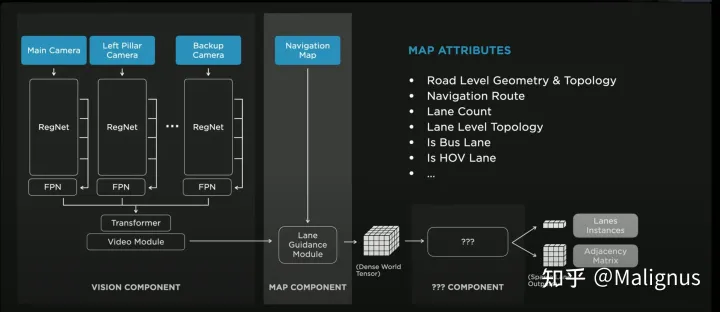
这部分Tesla的介绍非常简短,大概就是会将当前视域下一个粗糙的路网信息额外作为input,通过若干曾神经网络进行编码,输入并最终生成密集的基于世界坐标系下的tensor(3D)。根据ppt上的介绍,大概包括但不限于基于道路层面的几何信息&拓扑关系,导航路线,车道数量,车道级别的拓扑关系,是否为XX车道等(感觉已经蛮细致了,要能全部用到估计还挺麻烦)
几个发布会提到的细节:
Not an HD map
Provides hints of lanes inside intersections.
Provides lane counts on various roads.
最终输出:
A dense world tensor (3D).
Language Component
这应该是整个model的重中之重,也是整个ai day花了较大篇幅介绍的一个工作内容。
Model structures:
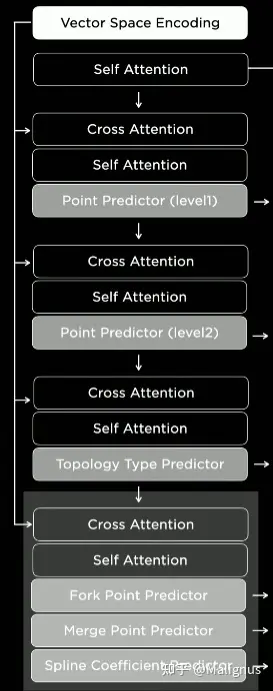
Point Predictor(Level 1): A coarse predictor (The coarse grid location of whole scene) Point Predictor(Level 2): A fine predictor(The fine grid location of target coarse grid) Topology Type Predictor: Start/continual/end/fork/merge
Fork point predictor: return its predecessor point index if there is a fork.
Merge Point predictor: return its successor point index if there is a merge. Spline Coefficient Predictor: given a more precise geometry representation of the lane.
The final outputs of Language Component
Doubts & own opinion
关于Language Component,仅从他的PPT和直播中的描述,有很多细节并没有介绍的很清楚。在他的整体刻画中,一整个scenarios是一个language。但按照他的Formuation,一整个scenarios中应该会有若干条lane, 每个lane都应该有自己的start和对应的end。根据其Example和先前的一些论文调研来看,会让我觉得有那么一点类似的是早年间Uber团队的"Hierarchical Recurrent Attention Networks for Structured Online Maps"工作
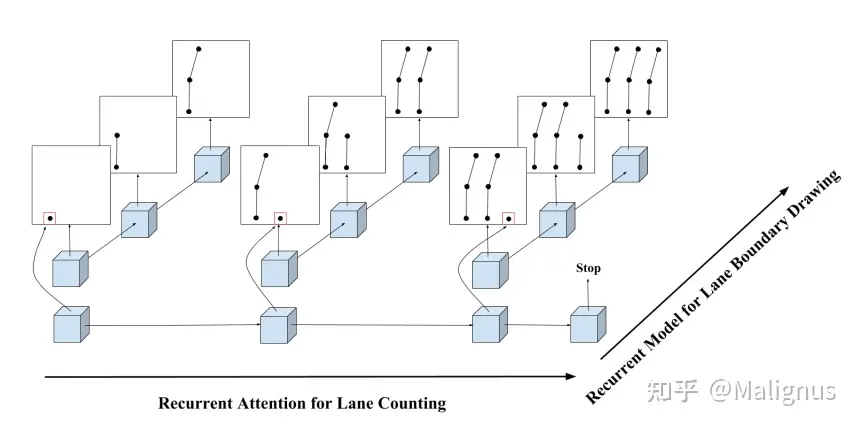
该论文提出,通过一个如上图所示的网络结构,来进行最终车道线的预测。其中水平方向负责预测具体有多少条车道线,垂直方向负责预测这个车道线具体长什么样子。
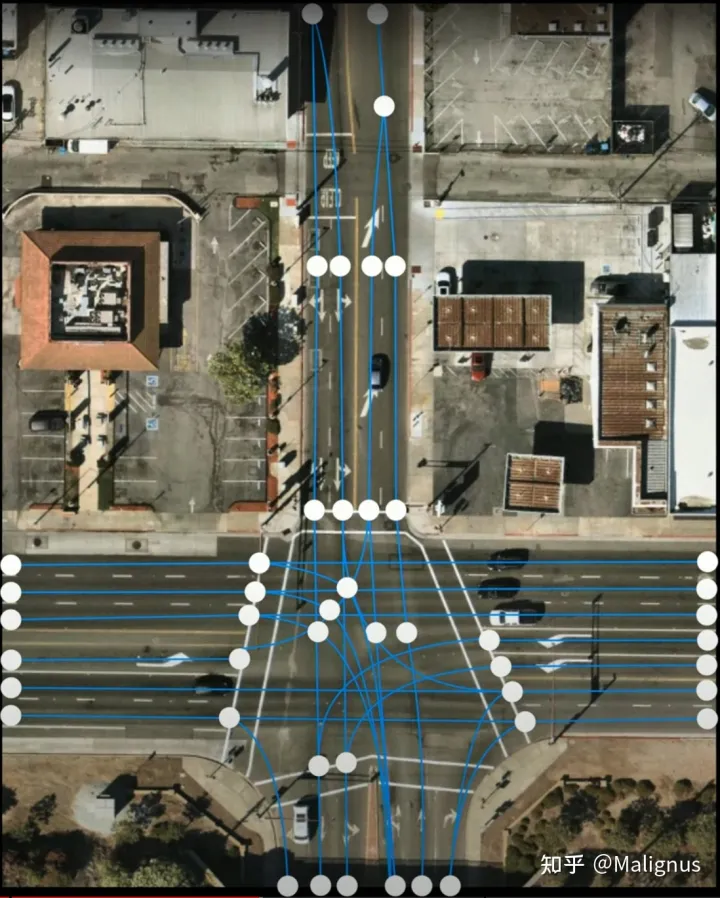
虽然Tesla全篇描述他的base element是lane,但是在他的example刻画中,感觉还是一个Point-based method,若将车道均由起点和终点以及对应的连接性进行表征。这种刻画方式很好规避了intersection中对虚拟车道线的刻画。
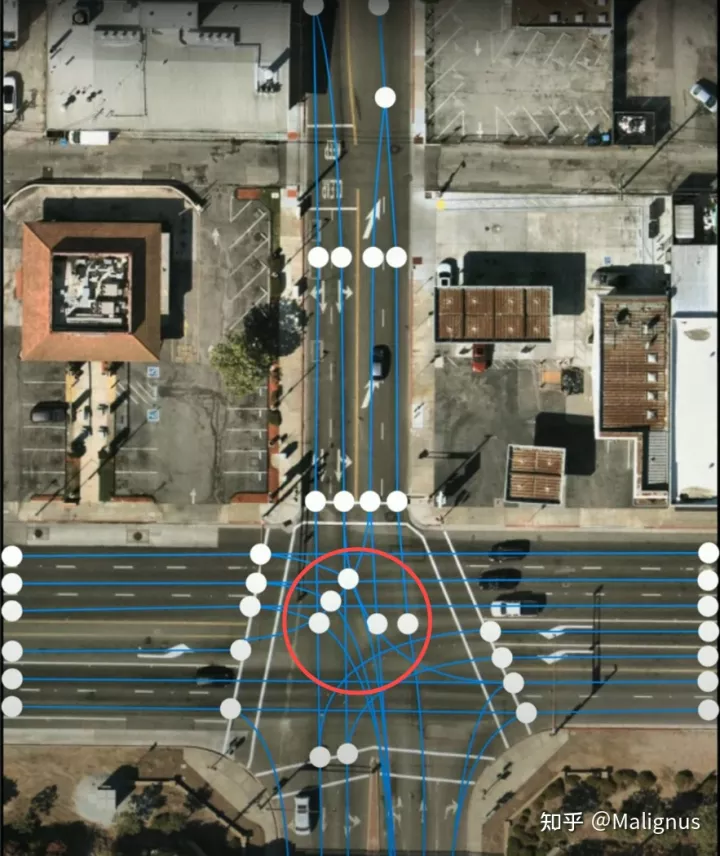
比较疑惑的一个点,在于Tesla所给的demo中(下图中红色方框圈定的位置),intersection中的部分虚拟车道线,是进行了类似中间点的标定。不知道这个GT的标注原则具体是怎样的?但总体来看,是一个基于start point & end point的Point-Based method.
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称














 4504
4504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









