






作者 | 汽车人 编辑 | 自动驾驶与AI
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【点云处理】技术交流群
本文只做学术分享,如有侵权,联系删文
❝论文:https://arxiv.org/pdf/2303.12384.pdf
代码:https://github.com/IRMVLab/RegFormer
作者单位:上海交通大学 中国矿业大学 ETH Zurich 微软

论文思路:
虽然点云配准在目标级和室内场景方面取得了显著的进展,但是大规模的配准方法却很少被探索。挑战主要来自于户外LiDAR扫描的巨大点数、复杂分布和异常值。此外,现有的大多数配准工作一般采用两阶段的配准范式:首先通过提取有区别的局部特征来寻找对应,然后利用估计量(如RANSAC)来过滤异常值,这些异常值高度依赖于精心设计的描述符和后处理选择。为了解决这些问题,本文提出了一种端到端transformer网络(RegFormer),用于大规模的点云对齐,而不需要任何后续处理。具体来说,本文提出的了一种projection-aware的分层transformer,通过全局提取点特征来捕获远程依赖并过滤异常值。本文的transformer具有线性复杂度,即使在大规模场景下也能保证高效率。此外,为了有效地减少不匹配,设计了一个bijective association transformer来回归初始变换。在KITTI和NuScenes数据集上的大量实验表明,本文的RegFormer在准确性和效率方面都具有竞争力。
主要贡献:
本文提出了一个用于大规模点云配准的完全端到端网络。它不需要任何关键点匹配和后处理,既不需要关键点,也不需要RANSAC。本文的高效模型可以实时处理数十万个点。
本文的RegFormer的全局建模能力可以有效地过滤离群值。此外,设计了一种Bijective Association Transformer(BAT),通过将交叉注意与最粗层上的所有点相关策略相结合来减少不匹配。
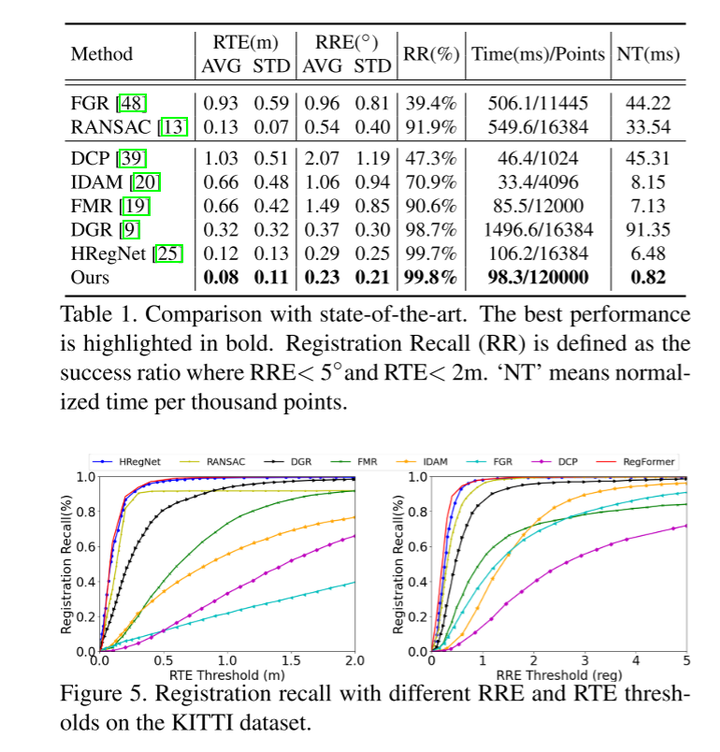
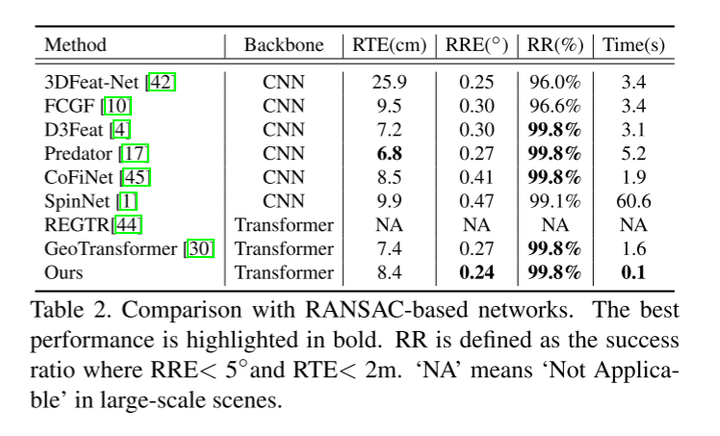
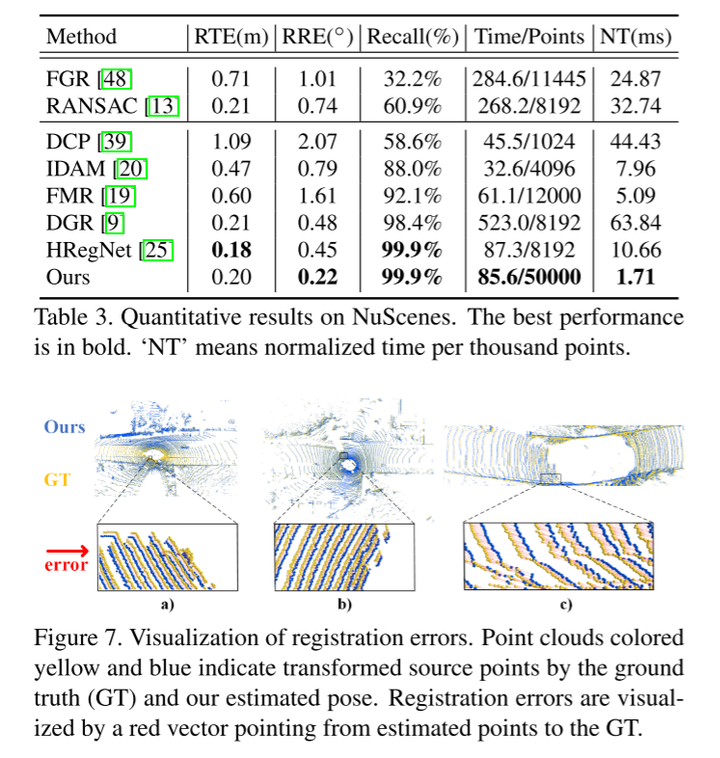
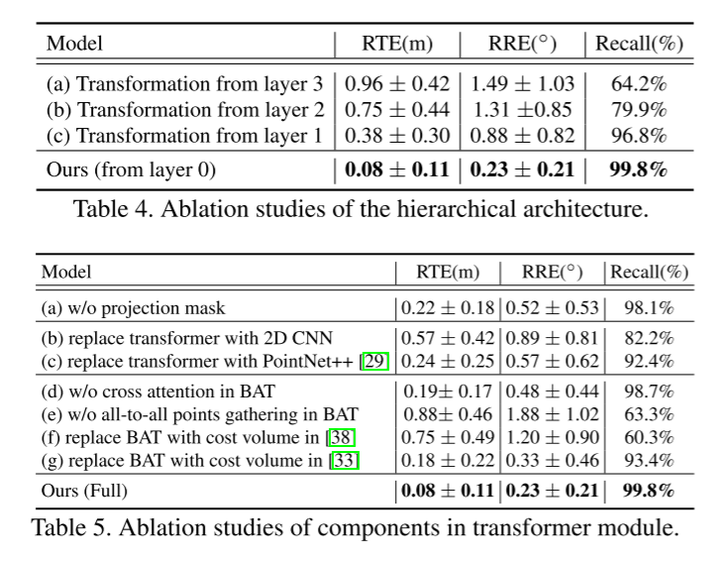
在KITTI[16,15]和NuScenes[5]数据集上的实验结果表明,本文的RegFormer配准召回率分别达到99.8%和99.9%,达到了最先进的性能。
网络设计:
虽然基于学习的方法在目标级或室内配准任务中显示了巨大的潜力[42,10,1,17],但大规模点云配准的研究较少。挑战主要有三方面:1)室外LiDAR扫描可能由几十万个非结构化的点组成,这些点本质上是稀疏的、不规则的,并且具有很大的空间范围。在一个推理[44]中有效地处理所有原始点是非常重要的。2)来自动态对象和遮挡的异常值会引入不确定的运动和不一致性,降低配准精度。3)当直接利用基于距离的最近邻匹配方法(如KNN)对遥远的点云对时,存在许多不匹配[25]。
对于第一个挑战,之前的配准主要是对输入点进行体素化[4,25],然后通过选择关键点和学习有特色的局部描述符来建立假定的对应关系[42,10,1]。然而,在体素化 [18]过程中,量化误差是不可避免的。此外,选择不同的关键点可能会影响配准精度,下采样对可重复性[45]提出了挑战。本文没有寻找关键点,而是直接将所有的LiDAR点投影到一个圆柱面上进行处理。投影 image-like 结构有利于transformer的窗口划分,实现了线性计算成本。这使本文的网络能够高效地处理近120000个点。为了利用3D几何特征,每个投影位置都被原始点坐标所填充,灵感来自于[37]。另一个问题是,由于原始点云的稀疏性,投影的伪图像充满了无效的位置。本文通过设计一个投影mask来处理这个问题。
对于第二个挑战,常用的方法是使用鲁棒估计器(RANSAC)[13,4,1]来过滤异常值。但RANSAC的收敛速度较慢[30],高度依赖后处理选择[44]。从另一个角度,本文观察到全局建模能力对于被遮挡对象的局部化和识别动力学是很有帮助的,因为它们提出全局运动。为此,本文提出了一种全局提取点特征的projection-aware transformer。值得注意的是,近期的一些作品[30,44]也尝试设计RANSAC-free配准网络。然而,CNN和transformer在特征提取模块中的结合,降低了效率。最接近我们的方法是REGTR[44],它直接预测与Transformer的干净对应。然而,二次复杂度限制了其大规模应用的能力。
此外,设计了一个Bijective Association Transformer(BAT)来解决第三个挑战。HRegNet[25]已经意识到,最近邻匹配可能会由于描述符中可能出现的错误而导致大量的不匹配。然而,它们的kNN簇仍然是基于距离的,不能很好地泛化到低重叠输入。为了解决这个问题,在最佳技术中设计了两个有效的部分来减少不匹配。首先利用交叉注意力机制进行初步的位置信息交换。直觉上,更深层次的特征是粗糙的,但可靠的,因为它们用更大的感受野收集更多的信息。因此,每一个点都与另一帧中的所有点(而不是选择k个点)相关,从而在最粗糙的层上获得可靠的运动嵌入((all-to-all)。然后通过对浅层的迭代细化来恢复精确的变换。
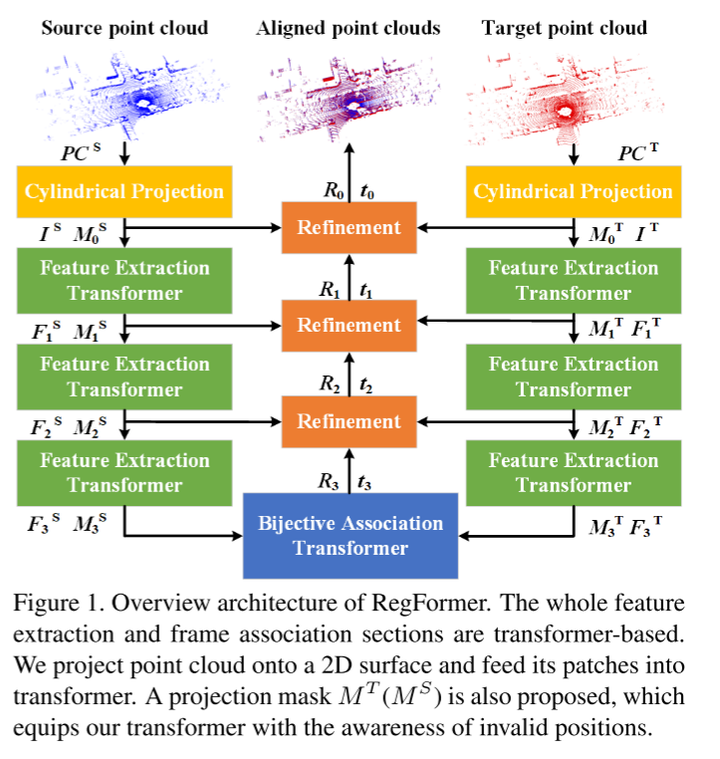
图1。概述RegFormer的架构。整个特征提取和帧关联部分都是基于transformer的。本文将点云投影到2D表面上,并将其patches输入transformer。提出的一种投影mask ,它使本文的transformer具有对无效位置的感知。
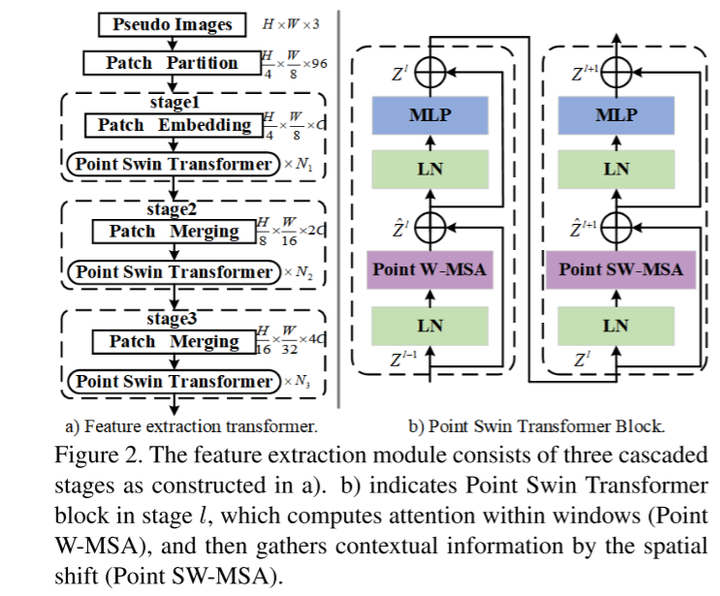
图2。特征提取模块由三个级联的stages组成,如a)所构造的。b)指示stage l 中的Point Swin Transformer block,其计算窗口内的注意力((Point W-MSA),然后通过空间移位(Point SW-MSA)收集上下文信息。
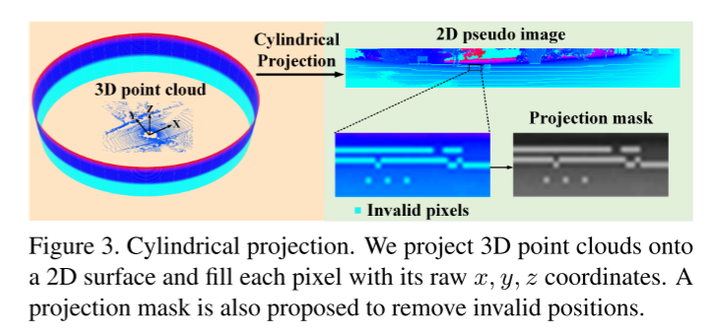
图3。圆柱投影。本文将3D点云投影到2D表面上,并使用其原始的x、y、z坐标填充每个像素。投影mask被提出用来删除无效的位置。
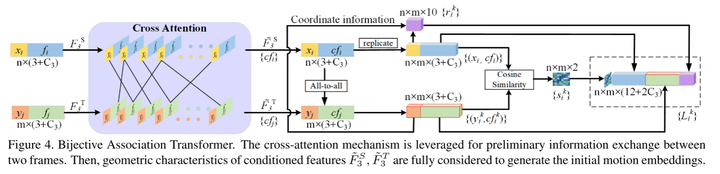
图4。Bijective Association Transformer。交叉注意机制用于两帧之间的初步信息交换。然后充分考虑条件特征 的几何特征,生成初始运动嵌入。
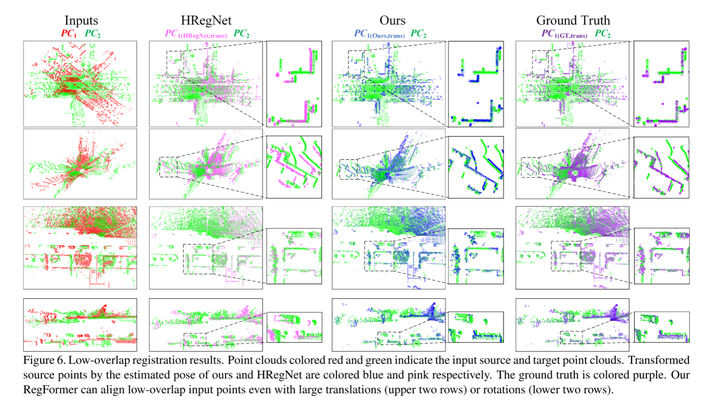
实验结果:

① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









