






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
论文作者 | 汽车人
编辑 | 自动驾驶之心
神经辐射场(Neural Radiance Fields)自2020年被提出以来,相关论文数量呈指数增长,不但成为了三维重建的重要分支方向,也逐渐作为自动驾驶重要工具活跃在研究前沿。
NeRF这两年异军突起,主要因为它跳过了传统CV重建pipeline的特征点提取和匹配、对极几何与三角化、PnP加Bundle Adjustment等步骤,甚至跳过mesh的重建、贴图和光追,直接从2D输入图像学习一个辐射场,然后从辐射场输出逼近真实照片的渲染图像。也就是说,让一个基于神经网络的隐式三维模型,去拟合指定视角下的2D图像,并使其兼具新视角合成和能力。NeRF的发展也和自动驾驶息息相关,具体体现在真实的场景重建和自动驾驶仿真器的应用中。NeRF擅长呈现照片级别的图像渲染,因此用NeRF建模的街景能够为自动驾驶提供高真实感的训练数据;NeRF的地图可以编辑,将建筑、车辆、行人组合成各种现实中难以捕捉的corner case,能够用于检验感知、规划、避障等算法的性能。因此,NeRF作为一个三维重建的分支方向和建模工具,掌握NeRF已经成为了研究者们做重建或者自动驾驶方向必不可少的技能。
今天为大家梳理下Nerf与自动驾驶相关的内容,近11篇文章,带着大家探索Nerf与自动驾驶的前世今生;
1.Nerf开山之作
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV2020.
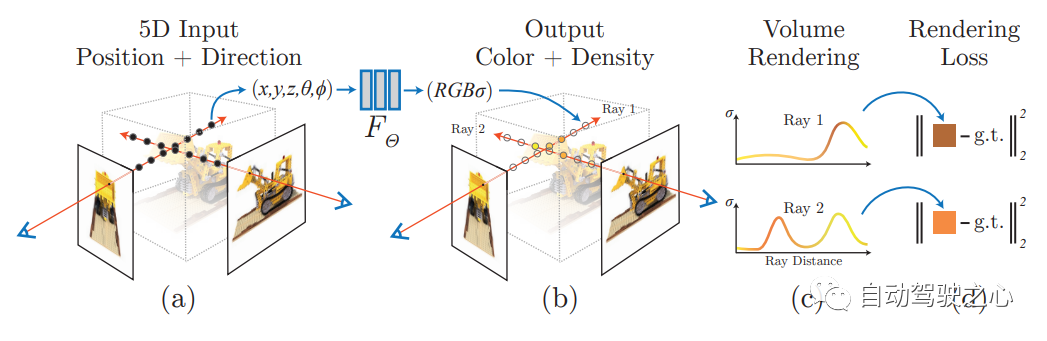
首篇,开山之作,提出了Nerf方法,该方法通过使用稀疏的输入视图集优化底层连续体积场景函数,实现了合成复杂场景的新视图的最新结果。算法使用全连接(非卷积)深度网络来表示场景,其输入是单个连续5D坐标(空间位置(x,y,z)和观看方向(θ,ξ)),其输出是该空间位置的体积密度和与视图相关的发射辐射。
NERF用 2D 的 posed images 作为监督,无需对图像进行卷积,而是通过不断学习位置编码,用图像颜色作为监督,来学习一组隐式参数,表示复杂的三维场景。通过隐式表示,可以完成任意视角的渲染。
2.Mip-NeRF 360
CVPR2020的工作,室外无边界场景相关。Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
论文链接:https://arxiv.org/pdf/2111.12077.pdf
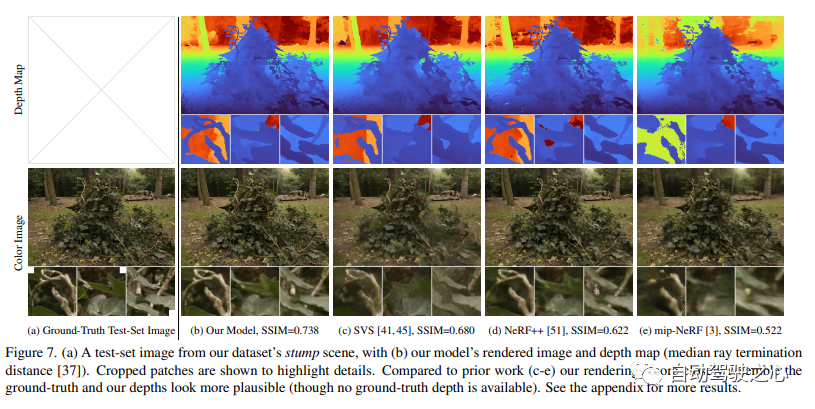
尽管神经辐射场(NeRF)已经在物体和空间的小边界区域上展示了不错的视图合成结果,但它们在“无边界”场景中很难实现,在这些场景中,相机可能指向任何方向,内容可能存在于任何距离。在这种情况下,现有的类NeRF模型通常会产生模糊或低分辨率的渲染(由于附近和远处物体的细节和比例不平衡),训练速度较慢,并且由于从一组小图像重建大场景的任务的固有模糊性,可能会出现伪影。本文提出了mip-NeRF(一种解决采样和混叠问题的NeRF变体)的扩展,它使用非线性场景参数化、在线蒸馏和一种新的基于失真的正则化子来克服无界场景带来的挑战。与mip-NeRF相比,均方误差减少了57%,并且能够为高度复杂、无边界的真实世界场景生成逼真的合成视图和详细的深度图。

3.Instant-NGP
显示体素加隐式特征的混合场景表达(SIGGRAPH 2022)
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
链接:https://nvlabs.github.io/instant-ngp
这里先直接给出Instant-NGP与NeRF的异同:
同样基于体渲染
不同于NeRF的MLP,NGP使用稀疏的参数化的voxel grid作为场景表达;
基于梯度,同时优化场景和MLP(其中一个MLP用作decoder)。
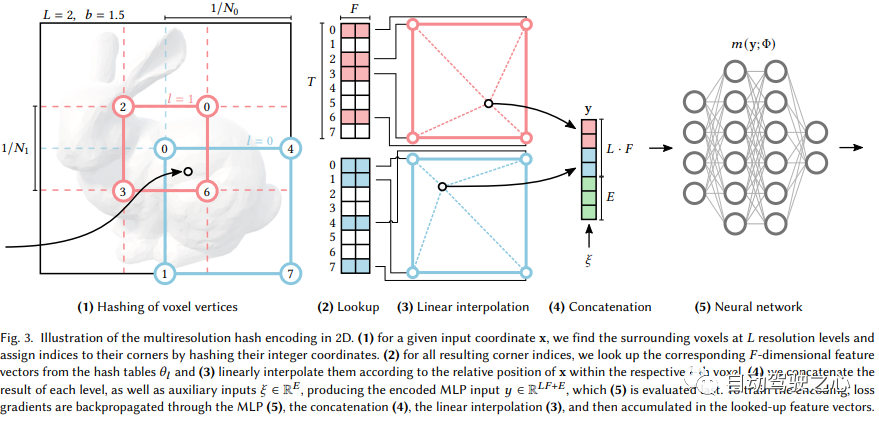
可以看出,大的框架还是一样的,最重要的不同,是NGP选取了参数化的voxel grid作为场景表达。通过学习,让voxel中保存的参数成为场景密度的形状。MLP最大的问题就是慢。为了能高质量重建场景,往往需要一个比较大的网络,每个采样点过一遍网络就会耗费大量时间。而在grid内插值就快的多。但是grid要表达高精度的场景,就需要高密度的voxel,会造成极高的内存占用。考虑到场景中有很多地方是空白的,所以NVIDIA就提出了一种稀疏的结构来表达场景。


4. F2-NeRF
F2-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories
论文链接:https://totoro97.github.io/projects/f2-nerf/
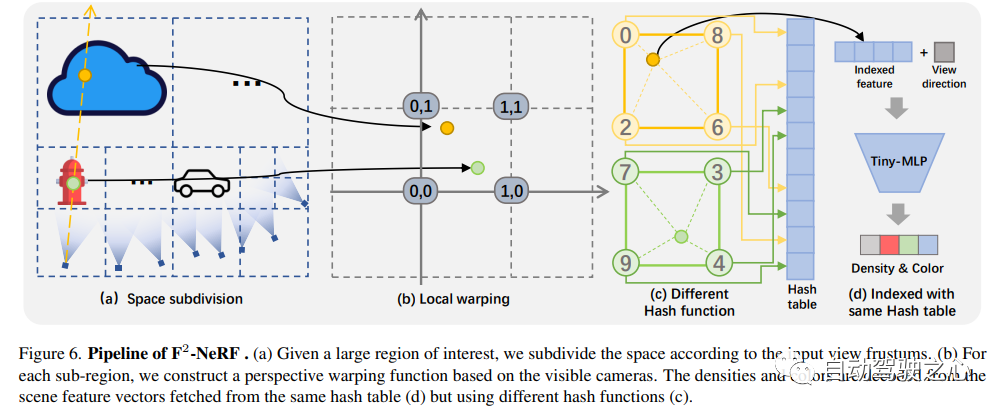
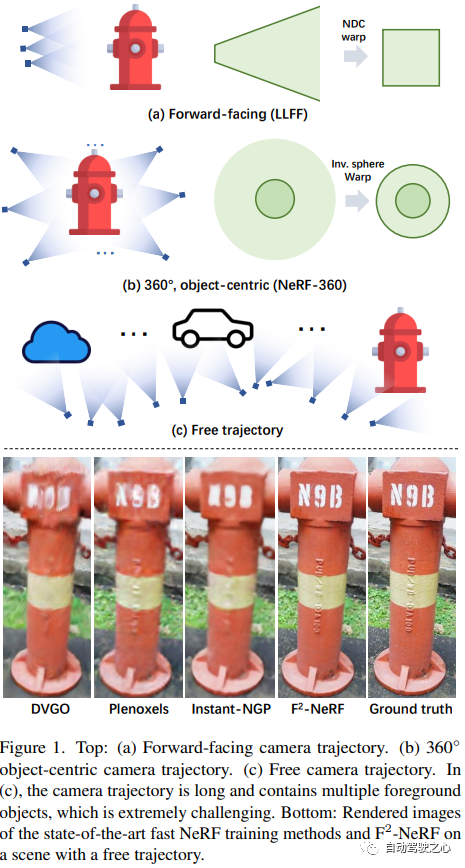
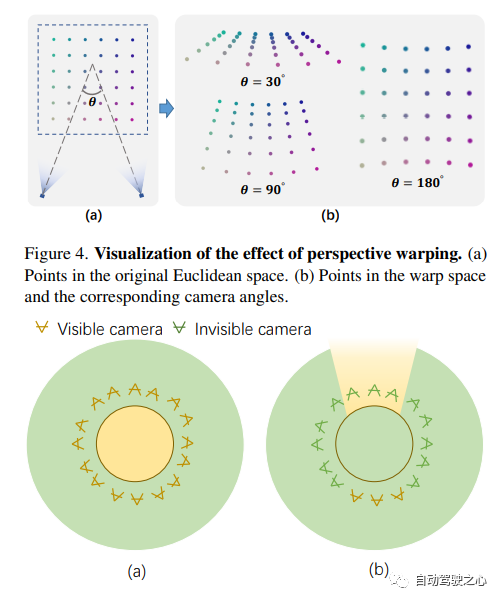
提出了一种新的基于网格的NeRF,称为F2-NeRF(Fast Free NeRF),用于新的视图合成,它可以实现任意输入的相机轨迹,并且只需要几分钟的训练时间。现有的基于快速网格的NeRF训练框架,如Instant NGP、Plenoxels、DVGO或TensoRF,主要针对有界场景设计,并依靠空间warpping来处理无界场景。现有的两种广泛使用的空间warpping方法仅针对面向前方的轨迹或360◦ 以物体为中心的轨迹,但不能处理任意的轨迹。本文深入研究了空间warpping处理无界场景的机制。进一步提出了一种新的空间warpping方法,称为透视warpping,它允许我们在基于网格的NeRF框架中处理任意轨迹。大量实验表明,F2-NeRF能够在收集的两个标准数据集和一个新的自由轨迹数据集上使用相同的视角warpping来渲染高质量图像。
5.MobileNeRF
移动端实时渲染,Nerf导出Mesh,被CVPR2023收录!
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures.
https://arxiv.org/pdf/2208.00277.pdf
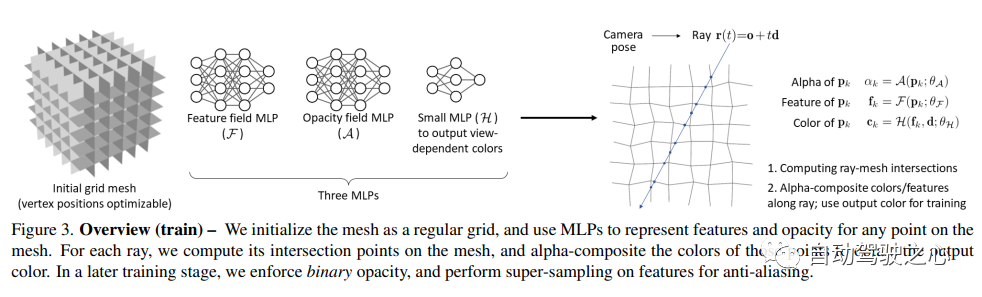
神经辐射场(NeRF)已经证明了从新颖的视图合成3D场景图像的惊人能力。然而,它们依赖于基于光线行进的专用volumetric 渲染算法,这些算法与广泛部署的图形硬件的功能不匹配。本文介绍了一种新的基于纹理多边形的NeRF表示,该表示可以通过标准渲染pipeline有效地合成新图像。NeRF表示为一组多边形,其纹理表示二元不透明性和特征向量。使用z缓冲区对多边形进行传统渲染会生成每个像素都具有特征的图像,这些特征由片段着色器中运行的小型视图相关MLP进行解释,以生成最终的像素颜色。这种方法使NeRF能够使用传统的多边形光栅化pipeline进行渲染,该pipeline提供了巨大的像素级并行性,在包括手机在内的各种计算平台上实现交互式帧率。



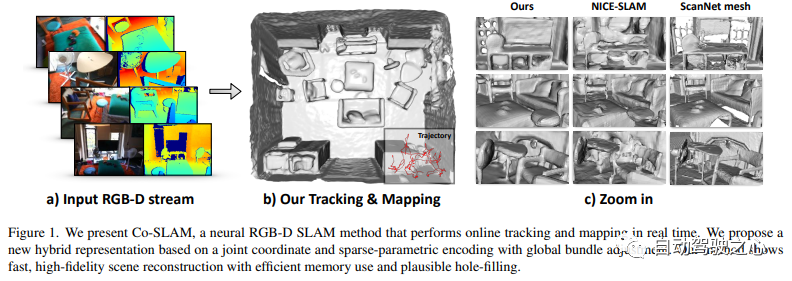
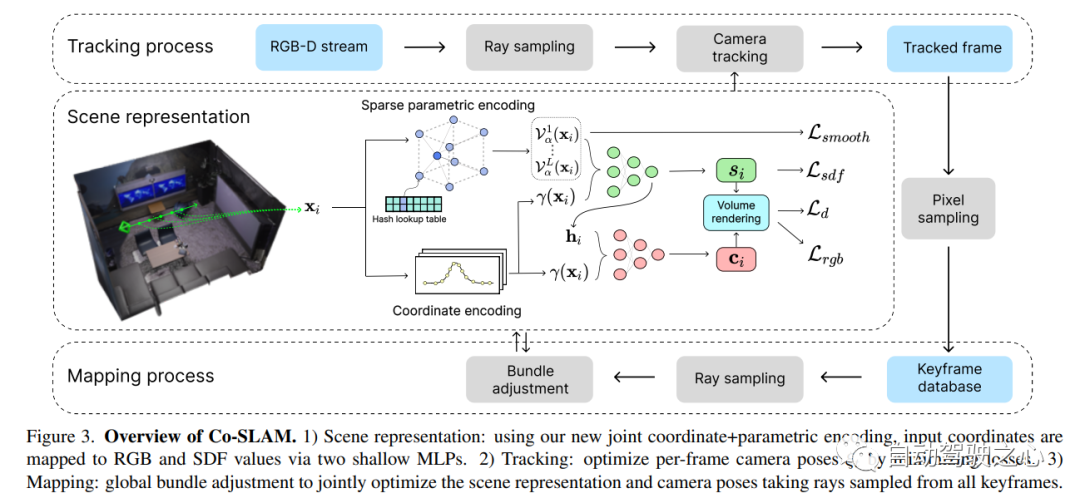
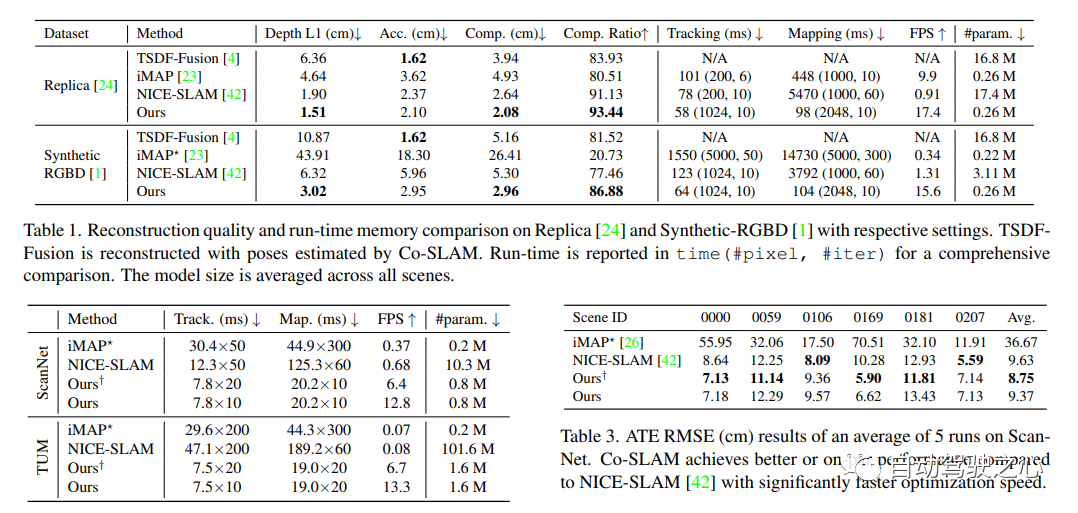
6.Co-SLAM
实时视觉定位和NeRF建图工作,被CVPR2023收录;
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
论文链接:https://arxiv.org/pdf/2304.14377.pdf
Co-SLAM是一个基于神经隐式表示的实时RGB-D SLAM系统,能够进行相机跟踪和高保真度的表面重建。Co-SLAM将场景表示为多分辨率哈希网格,以利用其极高的收敛速度和表示高频局部特征的能力。此外,为了融合表面一致性先验,Co-SLAM添加了一种块状编码方法,证明它使得在未观测区域能够进行强大的场景补全。我们的联合编码将两种优点结合到了Co-SLAM中:速度、高保真度重建以及表面一致性先验,射线采样策略使得Co-SLAM能够对所有关键帧进行全局捆绑调整!

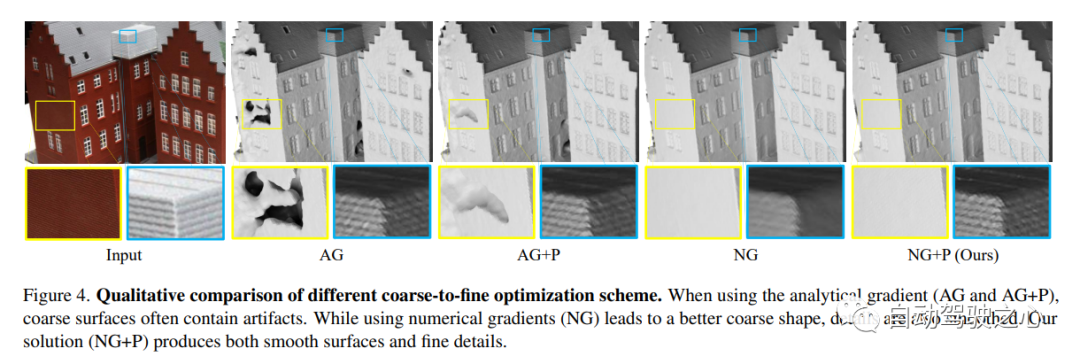
7.Neuralangelo
当前最好的NeRF表面重建方法(CVPR2023)

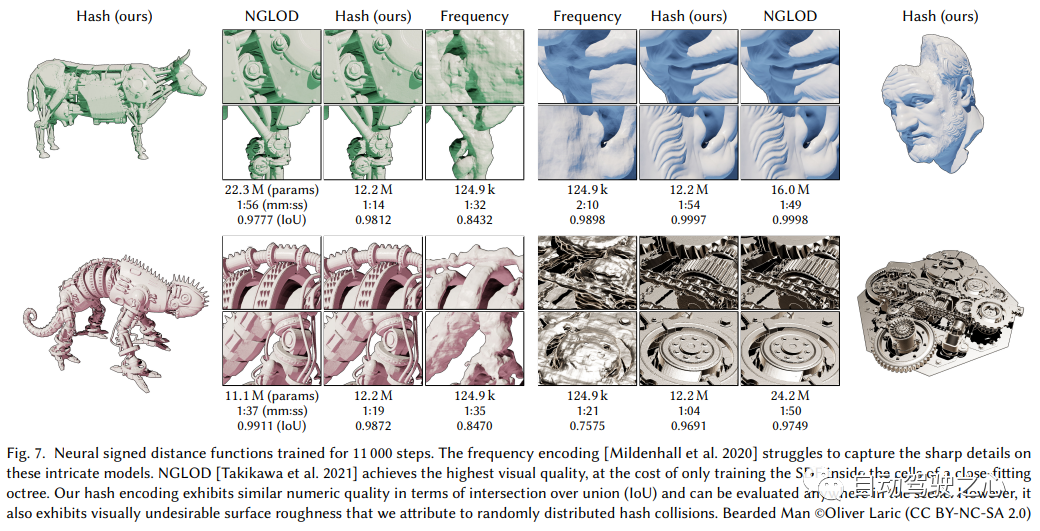
神经表面重建已被证明可以通过基于图像的神经渲染来恢复密集的3D表面。然而,目前的方法很难恢复真实世界场景的详细结构。为了解决这个问题,本文提出了Neuralangelo,它将多分辨率3D哈希网格的表示能力与神经表面渲染相结合。两个关键因素:
(1) 用于计算作为平滑操作的高阶导数的数值梯度,以及(2)控制不同细节级别的哈希网格上的从粗到细优化。
即使没有深度等辅助输入,Neuralangelo也可以有效地从多视图图像中恢复密集的3D表面结构,其保真度大大超过了以前的方法,从而能够从RGB视频捕获中进行详细的大规模场景重建!
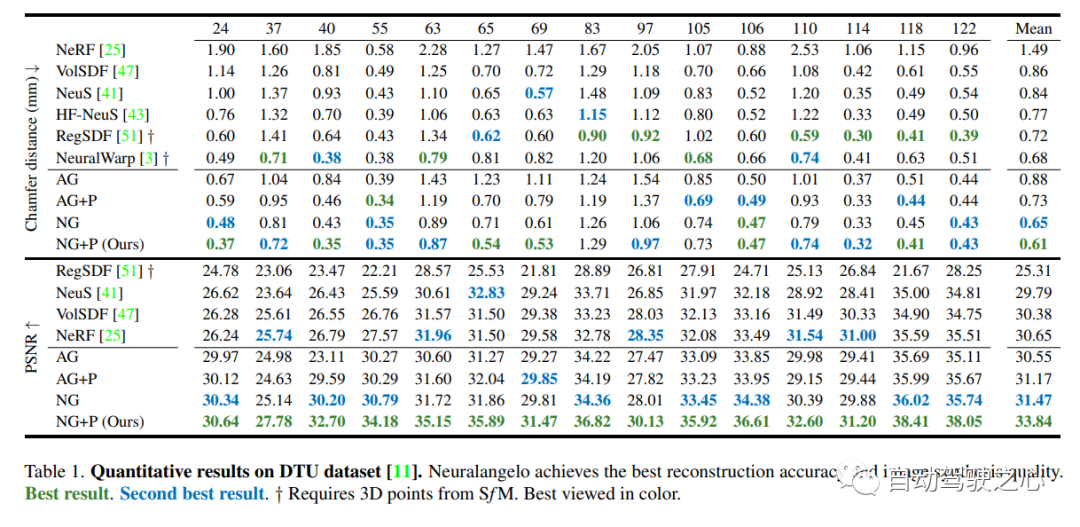


8.MARS
首个开源自动驾驶NeRF仿真工具。
https://arxiv.org/pdf/2307.15058.pdf
自动驾驶汽车在普通情况下可以平稳行驶,人们普遍认为,逼真的传感器模拟将在解决剩余拐角情况方面发挥关键作用。为此,MARS提出了一种基于神经辐射场的自动驾驶模拟器。与现有作品相比,MARS有三个显著特点:(1)实例意识。模拟器使用独立的网络分别对前景实例和背景环境进行建模,以便可以分别控制实例的静态(例如大小和外观)和动态(例如轨迹)特性。(2) 模块化。模拟器允许在不同的现代NeRF相关主干、采样策略、输入模式等之间灵活切换。希望这种模块化设计能够推动基于NeRF的自动驾驶模拟的学术进步和工业部署。(3) 真实。模拟器在最佳模块选择的情况下,设置了最先进的真实感结果。
最重要的一点是:开源!
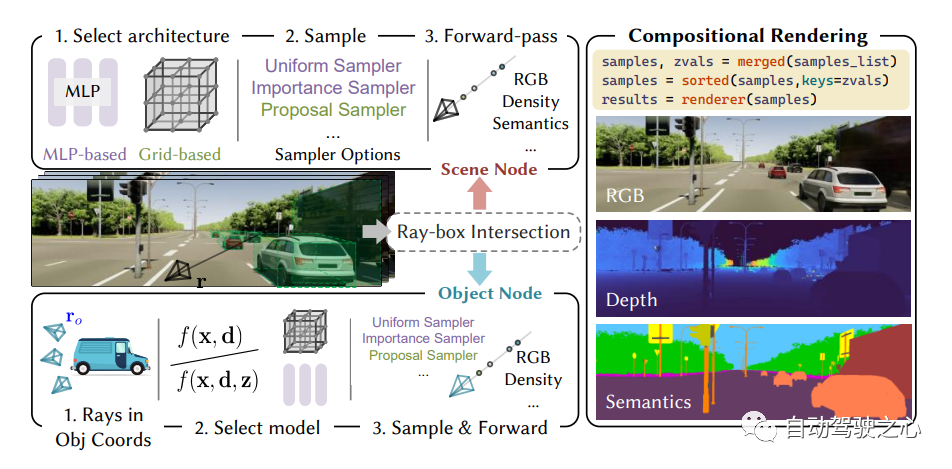

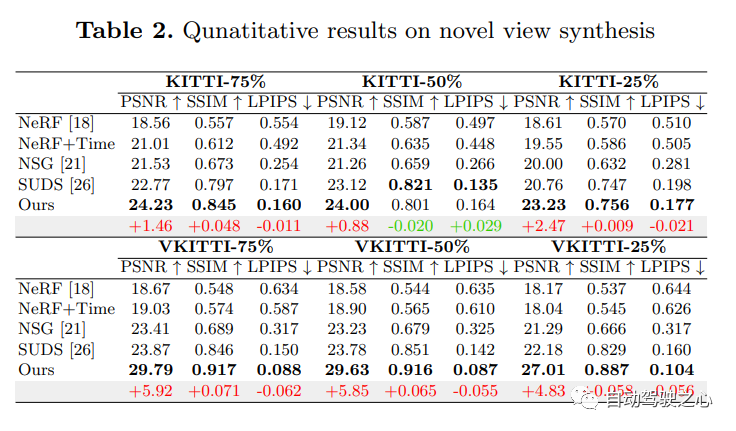
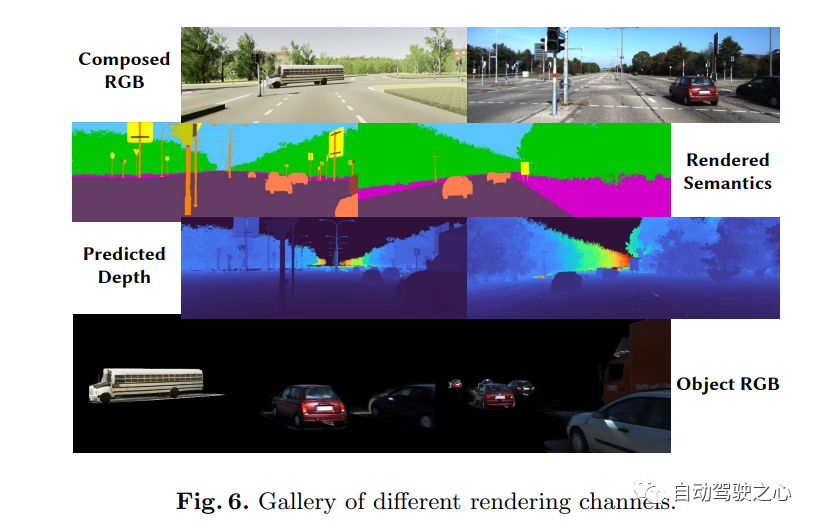
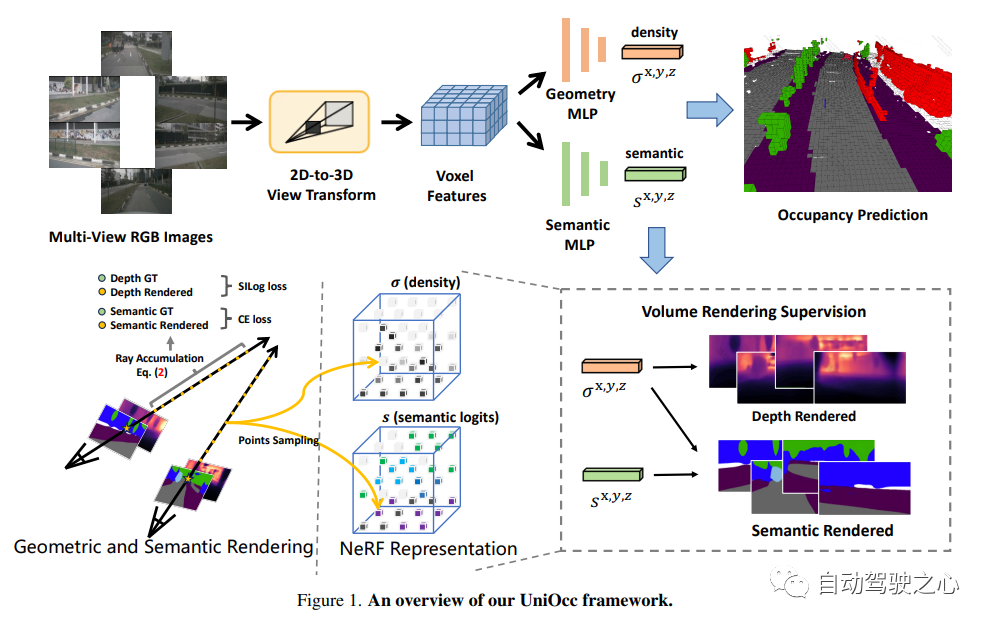
9.UniOcc
NeRF和3D占用网络, AD2023 Challenge
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering.
论文链接:https://arxiv.org/abs/2306.09117
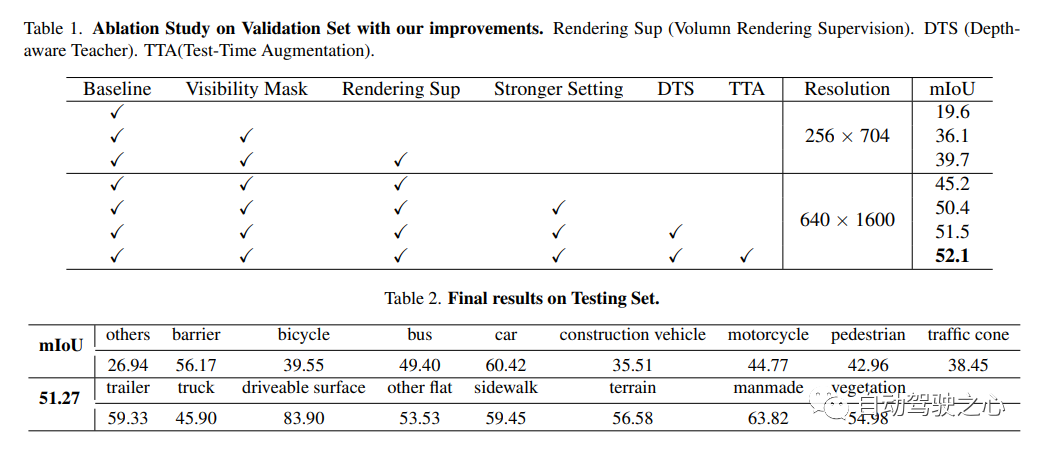
UniOCC是以视觉为中心的3D占用预测,用于占用预测的现有方法主要集中于使用3D占用标签来优化3D volume 空间上的投影特征。然而,这些标签的生成过程复杂且昂贵(依赖于3D语义注释),并且受体素分辨率的限制,它们无法提供细粒度的空间语义。为了解决这一限制,本文提出了一种新的统一占用(UniOcc)预测方法,明确施加空间几何约束,并通过体射线渲染补充细粒度语义监督。方法显著提高了模型性能,并证明了在降低人工标注成本方面的潜力。考虑到标注3D占用的费力性质,进一步引入了深度感知师生(DTS)框架,以使用未标记数据提高预测精度。解决方案在单机型的官方排行榜上获得了51.27%mIoU的成绩,在本次挑战中排名第三。
10.Unisim
waabi出品,必是精品啊!
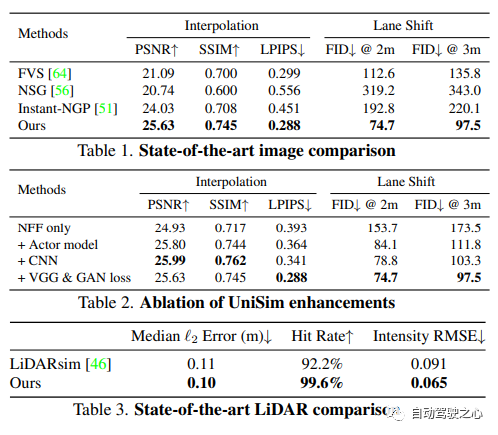
UniSim: A Neural Closed-Loop Sensor Simulator
论文链接:https://arxiv.org/pdf/2308.01898.pdf
阻碍自动驾驶普及的一个重要原因是安全性仍然不够。真实世界过于复杂,尤其是存在长尾效应(long tail)。边界场景对安全驾驶至关重要,很多样,但又很难遇到。测试自动驾驶系统在这些场景的表现非常困难,因为这些场景很难遇到,而且在真实世界中测试非常昂贵和危险。
为了解决这个挑战,工业界和学术界都开始重视仿真系统的开发。一开始,仿真系统主要专注于模拟其他车辆/行人的运动行为,测试自动驾驶规划模块的准确性。而最近几年,研究重心逐渐转向传感器层面的仿真,即仿真生成激光雷达、相机图片等原始数据,实现端到端测试自动驾驶系统从感知、预测一直到规划。
不同于以往工作, UniSim首次同时做到了:
高度逼真(high realism): 可以准确地模拟真实世界(图片和LiDAR), 减小鸿沟(domain gap )
闭环测试(closed-loop simulation): 可以生成罕见的危险场景测试无人车, 并允许无人车和环境自由交互
可扩展 (scalable): 可以很容易的扩展到更多的场景, 只需要采集一次数据, 就能重建并仿真测

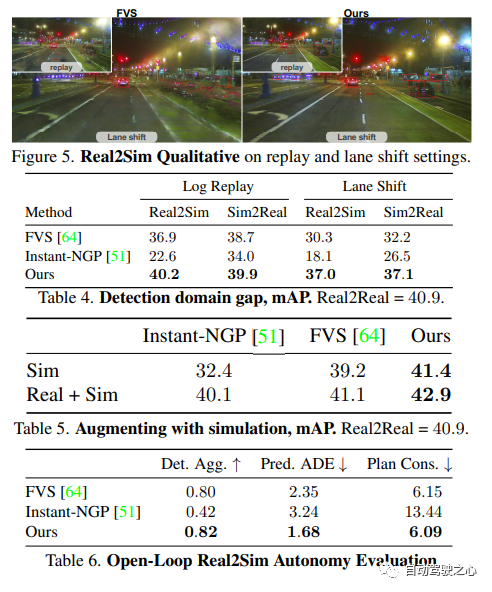
仿真系统的搭建
UniSim 首先从采集的数据中,在数字世界中重建自动驾驶场景,包括汽车、行人、道路、建筑和交通标志。然后,控制重建的场景进行仿真,生成一些罕见的关键场景。
闭环仿真(closed-loop simulation)
UniSim可以进行闭环的仿真测试,首先, 通过控制汽车的行为, UniSim可以创建一个危险的罕见场景, 比如有一辆汽车在当前车道突然迎面驶来;然后, UniSim仿真生成对应的数据;接着, 运行自动驾驶系统, 输出路径规划的结果;根据路径规划的结果, 无人车移动到下一个指定位置, 并更新场景(无人车和其他车辆的位置);然后我们继续进行仿真, 运行自动驾驶系统, 更新虚拟世界状态 ……通过这种闭环测试, 自动驾驶系统和仿真环境可以进行交互, 创造出与原始数据完全不一样的场景

① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









