






作者 | Dcity 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
导读
重点阐述真实的客流统计算法从Nvidia环境往国产海光CPU+DCU进行迁移的部署过程,除去学习成本时间和处理一些项目用的基本软件安装时间外,实际移植时间大约为1天时间。
背景
项目开发全国产方案替代实操记录部署篇来啦!在刚完成本篇不久又看到漂亮国宣布撤销英特尔、高通对华为出口芯片的许可证,对国内的打压继续收紧。现在AI的势头越来越猛,国产AI软硬件也是在不断发力,尽管差距还大,但至少有了,能「遥遥领先」一次,非常再期待来多几次 ~
~
没有看过上篇的建议结合本文一起食用,总体来说使用国产的CPU+GPU效果还是不错的,整个过程也是比较流程的。本篇重点阐述了真实的客流统计算法从Nvidia环境往国产海光CPU+DCU进行迁移的部署过程。
任务介绍
再简单介绍一下项目任务:利用监控摄像头采用AI的技术方法对零售门店、大型商超和公共设施等场景下进行客流信息统计。算法应用具体包含的需求点是:
1)能够根据视频流实时统计门口的进入客流数量和出去客流数量(即同时记录出入两个方向的客流量);
2)能够实现客流去重,即频繁进出门口的客流需要在统计上去除重复;
3)能够实现特殊人员的筛选,比如门店工作人员、外卖人员、清洁人员等;
4)限制条件为不允许使用人脸信息和基于人脸的算法。
技术方案具体可以看上文,在这里不展开介绍了
部署开发流程
部署环境搭建
海光DCU开发的相关文档和资源都可以在社区光合开发者社区(https://developer.hpccube.com/)找到,下载拉取都挺方便。首先,我们物理机的CPU配置为EPYC 8-core Processor, DCU配置为DCU Z100L,预装国产操作系统NFSChina Server release 4.0。根据操作系统选择了相应的安装驱动(https://cancon.hpccube.com:65024/6/main)版本。宿主机上安装容器环境docker,从官方镜像仓库(https://sourcefind.cn/#/image/dcu/migraphx?activeName=overview)选择所需要的包含DCU migraphx部署工具的docker镜像,直接docker pull即可。该项目中我们选择了tag 为4.0.0-centos7.6-dtk23.04.1-py38-latest的镜像。项目部署全部采用c/c++实现,在上述基础镜像条件下,继续在镜像中安装了ffmpeg和OpenCV两个库,这都是我们比较熟悉的,也是CV领域内最常用的图像视频处理库,安装方法相对比较简便。
模型导出
在训练篇中介绍的三个模型,全部都导出为onnx格式的模型,分别是行人目标检测模型,ReID模型和属性分类模型。在AI模型工程化部署方面,我比较推荐将训练后的模型都导出为onnx格式,这样比较方便采用不同的AI硬件进行推理,绝大多数AI硬件的推理引擎工具都支持onnx格式的模型,要么支持直接加载onnx模型,要么支持将onnx模型转换为特定AI硬件所支持的自有模型格式。海光DCU提供的推理引擎migraphx可以直接加载onnx模型,无需手动进行模型格式转换,这一点非常方便,否则还需要一个专门的转换过程,有时候也比较让人抓狂。
算法SDK编写
采用极视角的EV_SDK规范接口(https://gitee.com/cvmart/ev_sdk_demo4.0_evdeploy)来实现整个算法SDK。算法流程大致如下图所示
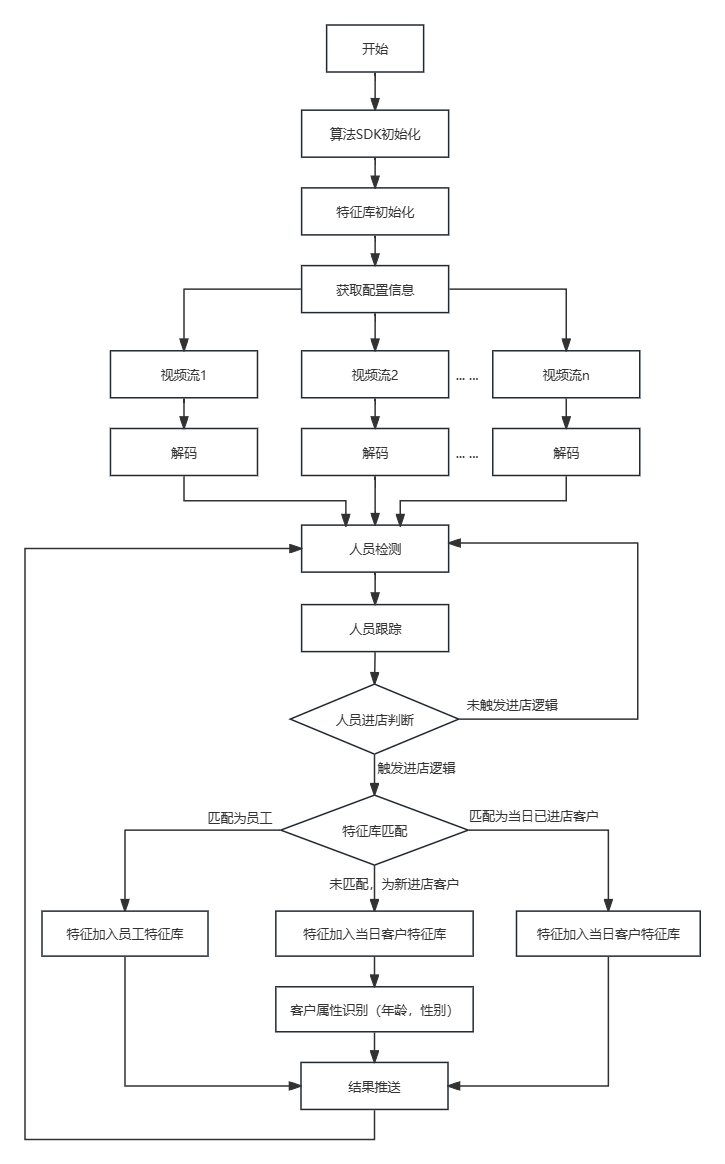
程序开始执行,首先进行算法SDK初始化,主要包括AI模型的初始化加载及预热,本算法主要涉及到三个AI模型,分别用于行人目标检测,行人属性识别和行人重识别;
特征库初始化,主要是初始化录入的门店员工特征信息(全身图像信息,非人脸信息,不依赖于人脸),目的是对客流统计时去除门店员工,使客流统计只针对客户;
获取配置信息,主要是获取监控摄像头的视频流地址信息、以及门店监控区域门线配置等信息;
多路视频流解码,主要是针对监控视频流,解码出图像数据,进行图像的预处理,以合适的格式送入到算法模型分析;
人员检测,主要是利用AI模型对图像帧中的所有行人进行目标检测,获取到图像帧中行人目标位置信息;
人员跟踪,主要是利用多目标跟踪器对连续图像帧的行人进行连续跟踪,以得到行人的运动轨迹;
人员进店判断,主要是主要利用跟踪轨迹以及门线信息,自动判断出人员是否进店,以及人员是否是从店前路过;
特征库匹配,主要是利用AI模型,提取某个候选行人的整体特征,并与特征库进行匹配,判断该候选行人是否属于员工;
真实客户/客流信息更新,主要是区分出真实客流后,进一步利用AI模型识别出客流的属性信息,包括性别、职业类型等;
最终将相关结果信息实时推送出去,一般推送到上层管理平台,进行数据的展示和存储
因为不少代码实现是跟项目和业务关联较大,相对略复杂,为了更方便学习如何使用DCU进行模型部署开发,我们提供了 EV_SDK DCU demo(https://gitee.com/cvmart/ev_sdk_demo4.0_dcu) 程序,可以直接查看和学习。
DCU模型推理
重点介绍一下采用DCU实现C++模型推理的过程。随着AI技术的发展,很多异构的AI硬件开发商都提供了一个模型推理加速库或者推理引擎,这些加速库也越来越方便,大大简化了模型推理部署的开发门槛。对于DCU,其采用的是migraphx,实现模型推理主要就几个相关步骤:
导入相关的几个头文件,比如:
#include <migraphx/program.hpp>
#include <migraphx/onnx.hpp>
#include <migraphx/gpu/target.hpp>
#include <migraphx/quantization.hpp>定义一个migraphx::program类型,假设为m_net,然后解析输入的onnx模型:
migraphx::program m_net;
m_net = migraphx::parse_onnx("onnx_model_name");获取模型输入输出节点信息,并进行device设置,量化设置等:
std::unordered_map<std::string, migraphx::shape> inputs = m_net.get_inputs();
std::unordered_map<std::string, migraphx::shape> outputs = m_net.get_outputs();
migraphx::target gpu_target = migraphx::gpu::target{};
migraphx::quantize_fp16(m_net);
migraphx::compile_options options;
options.device_id = 0; // 设置GPU设备,默认为0号设备
options.offload_copy = true;进行模型编译, 模型编译这个过程是对onnx格式的模型,根据设置进行优化,有点类似于其他AI推理引擎会遇到的模型转换过程。一般来说模型转换过程都相对较慢,DCU上面这步模型编译过程也是相对较慢,在本项目测试的机器上,该过程耗时在分钟级别:
m_net.compile(gpu_target, options);前面步骤可以认为是模型初始化过程,初始化完成后即可送入输入图像数据,进行模型推理,非常简单,其中input_data就是经过前处理的后的图像数据:
std::vector<migraphx::argument> inference_results = m_net.eval(input_data);获取到推理结果inference_results后,最后剩下的就是后处理部分。这个就是根据每个模型的输出节点数据去自行解析了。
整个过程相对还是比较简单,完整示例可以参考 EV_SDK DCU demo(https://gitee.com/cvmart/ev_sdk_demo4.0_dcu)
总结
项目的测试效果视频,项目中总共采用了三个模型,同时加入了多目标跟踪,还包含视频流解码处理等过程,在视频流分析上可以轻松做到实时分析。对于真实场景下的零售门店监控摄像头输出的标准1080p视频流,其全过程分析速度可达60+fps。
整个过程除了重点修改了一下模型推理部分代码,其余原有代码完全复用,所以其移植过程还是很快速的,除去学习成本时间和处理一些项目用的基本软件安装时间外,实际移植时间大约为1天时间。在这个被“卡脖子”的时代,相信采用国产AI软硬件也会是一个不错的选择,也期待国产生态越来越好。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









