






作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
导读
本文揭示了 Mamba 模型与 Linear Attention Transformer 之间有着惊人的相似之处。作者通过探索 Mamba 和 Linear Transformer 之间的相似性和差异,在本文中提供了一个全面的分析来揭示 Mamba 成功的关键因素。
本文目录
1 揭秘视觉 Mamba:一种线性注意力机制视角
(来自清华大学 (黄高团队),阿里巴巴)
1 MLLA 论文解读
1.1 探索 Mamba 和 Linear Attention Transformer 的关联
1.2 线性注意力与选择性状态空间模型简介
1.3 用统一的视角看待选择性状态空间模型与线性注意力
1.4 关于每个差异的分析
1.5 宏观架构设计
1.6 每种差异的影响和 MLLA 最终方案
1.7 实验结果
太长不看版
Mamba 是一种具有线性计算复杂度的状态空间模型。其最近在处理不同视觉任务的高分辨率输入中展示出很不错的效率。本文揭示了 Mamba 模型与 Linear Attention Transformer 之间有着惊人的相似之处。作者通过探索 Mamba 和 Linear Transformer 之间的相似性和差异,在本文中提供了一个全面的分析来揭示 Mamba 成功的关键因素。
具体而言,作者使用统一的公式重新表述了选择性状态空间模型和线性注意力,将 Mamba 重新表述为 Linear Attention Transformer 的变体。它们主要有6个区别:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力归一化、single-head 和修改后的 Block Design。对于每个设计,本文仔细分析了它的优缺点,并实证性地评估了其对视觉模型性能的影响。更有趣的是,遗忘门 (forget gate) 和修改后的 Block Design 是 Mamba 模型成功的核心贡献,而其他的四种设计不太关键。
基于这些发现,作者将这两个比较重要的设计融入 Linear Attention 中,并提出一种类似 Mamba 的线性注意力模型,其在图像分类和高分辨率密集预测任务上都优于视觉 Mamba 模型,同时享受并行化的计算和快速推理。
本文做了哪些具体的工作
揭示了 Mamba 与 Linear Attention Transformer 之间的关系:Mamba 和 Linear Attention Transformer 可以使用一个统一的框架表示。与传统的 Linear Attention 的范式相比,Mamba 有6种不同设计:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力的归一化、single-head 和经过修改的 Block Design。
对上述的每一种特殊的设计进行了详细分析,并实证验证了遗忘门 (forget gate) 和 Block Design 很大程度上是 Mamba 性能优越的关键。此外,证明了遗忘门 (forget gate) 的循环计算可能不是视觉模型的理想选择。相反,适当的位置编码可以作为视觉任务中的遗忘门 (forget gate) ,同时保持并行化的计算和快速的推理。
开发了一系列名为 MLLA 的 Linear Attention Transformer 架构,它继承了 Mamba 的核心优点,并且往往比原始 Mamba 模型更适合视觉任务。
1 揭秘视觉 Mamba:一种线性注意力机制视角
论文名称:Demystify Mamba in Vision: A Linear Attention Perspective (Arxiv 2024.05)
论文地址:
https://arxiv.org/pdf/2405.16605
代码链接:
https://github.com/LeapLabTHU/MLLA
1.1 探索 Mamba 和 Linear Attention Transformer 的关联
最近,以 Mamba 为例的状态空间模型迅速引起了领域的研究兴趣。与主流 Transformer 模型的二次复杂度相比,Mamba 有线性复杂度的有效序列建模。这个关键的属性允许 Mamba 在处理极长的序列时更加占优势,使其称为语言[1]和视觉[2]模型的炙手可热的架构。
然而, Mamba 不是第一个实现具有线性复杂度的全局建模的模型。早期的工作 Linear Attention 提出了 Softmax Attention 的高效替代方案。具体来讲, Linear Attention 用线性归一化代替了注意力操作中的非线性 Softmax 函数。线性注意力机制使得计算顺序从 更改为 , 从而将计算复杂度从 降低到 。尽管它的效率很高, 但之前的工作 [4]证明了线性注意的表达能力不足, 这使得它在实际应用中不切实际。令人惊讶的是, 本文发现 Mamba 和 Linear Attention 的公式之间存在非常接近的联系。因此,一个值得研究的问题出现:
到底是什么因素促使了 Mamba 的成功,及其对 Linear Attention Transformer 的优势?
作者在本文中提供了理论和实证分析,站在 Linear Attention Transformer 的角度来揭示 Mamba。具体而言,作者使用统一的公式重写了选择性状态空间模型和 Linear Attention 的公式,指出 Mamba 与 Linear Attention Transformer 的区别主要有6点:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力的归一化、single-head 和经过修改的 Block Design。为了揭示到底是哪种因素导致 Mamba 的有效性,作者进行了实证研究来评估每种设计的影响。结果表明,遗忘门 (forget gate) 和经过修改的 Block Design 是 Mamba 模型优越性的核心贡献。
遗忘门 (forget gate) 需要循环计算,可能不太适合非自回归的视觉模型。因此,作者深入研究了遗忘门 (forget gate) 的本质,验证其可以被位置编码所取代。基于这些发现,作者设计了 Mamba-like Linear Attention (MLLA) 模型。
1.2 线性注意力与选择性状态空间模型简介
令 为长度为 且维度为 的序列, 单头 Softmax attention, 可以写成:
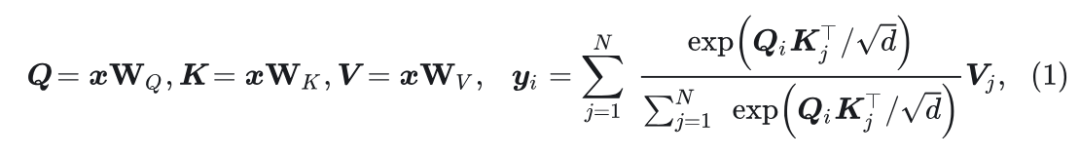
式中, 为投影矩阵。 为 Query, Key 和 Value。Softmax attention 计算每个查询键对之间的相似性, 导致 复杂度。因此, 它在长序列建模场景中会产生难以承受的计算成本。
Linear Attention
另一种注意力范式,通过将计算复杂度降低到 来有效地解决这个问题。线性注意力用线性归一化代替了非线性 Softmax 函数, 并在 和 中采用了一个额外的核函数 :
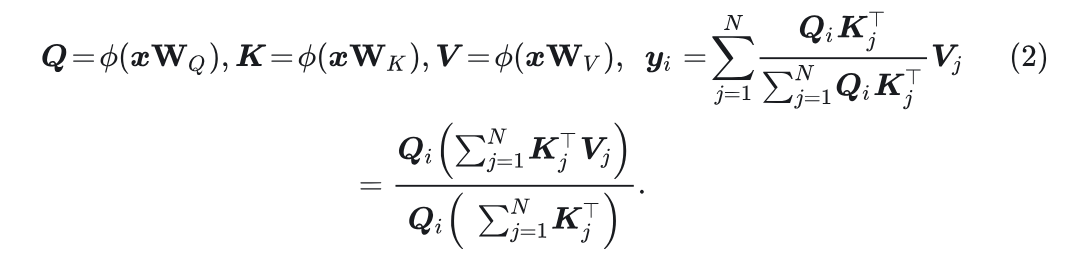
根据矩阵乘法的结合律, 将计算顺序从 重新变为 , 从而将计算复杂度降低到 。
上式2使用全局感受野定义线性注意力, 其中每个 Query 聚合来自所有 Key 和 Value 的信息。在实践中, 线性注意力也可以在自回归模型中实现, 将第 个 token 的感受野限制为之前的所有 tokens 。这种因果线性注意力公式如下:
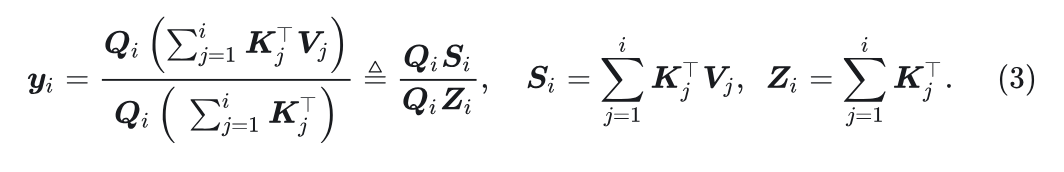
可以写成循环线性注意力形式:
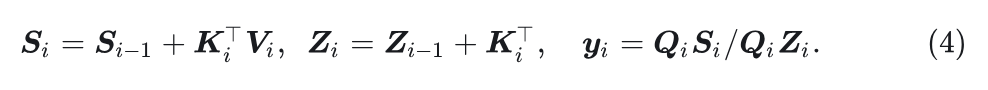
Selective State Space Model
经典状态空间模型 (State space model, SSM): 经典的状态空间模型是一个连续系统,它通过隐藏状态 将输入 映射到输出 ,可以写成:
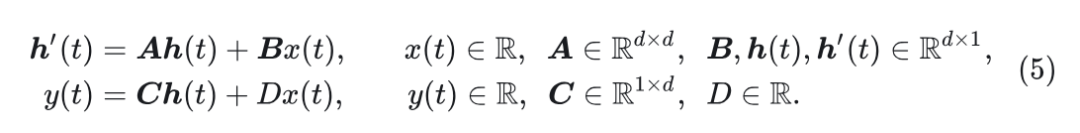
离散状态空间模型: 为了应用于深度神经网络,SSM 首先通过零阶保持离散化转换为其离散版本。具体来说,使用时间尺度参数 将连续参数 转换为其离散化的对应参数
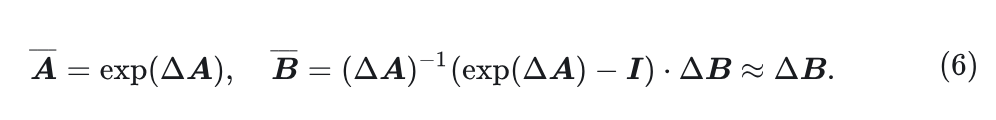
离散状态空间模型将式5重写为:
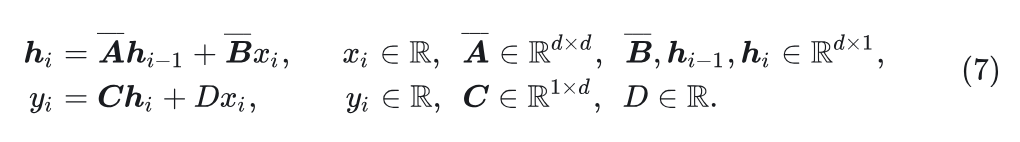
选择性状态空间模型 (Selective State Space Model): Mamba 通过选择改进了 SSM,提出了选择性状态空间模型。参数 被设置为 的函数, 从而成为依赖于输入的参数 。因此, 离散化参数 也是依赖于输入的。选择性状态空间模型可以写成:
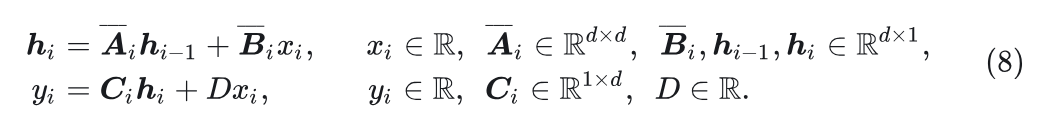
为了便于后续推导,作者对等式进行了3个修改:
Mamba 实际上将 设置为对角矩阵。因此, , 其中 表示 对角元素组成的矩阵。
给定 和 , 有 。
, 其中 表示 Hadamard 积, 即元素乘法。
因此,8式可以重写成:
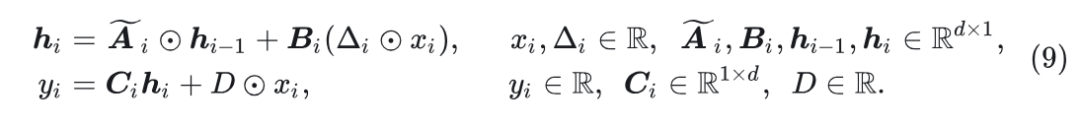
式8和式9的等效关系如下图1所示。
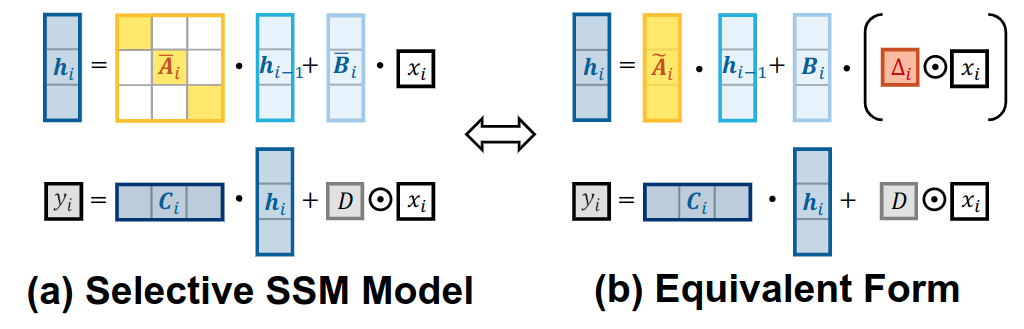
上式 9 提出的选择性状态空间模型只能处理标量输入 。为了对输入序列 进行操作, 使用下式:
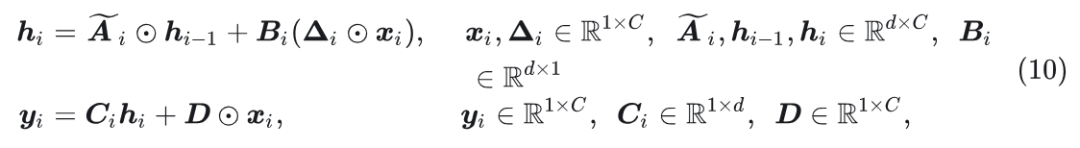
其中 源自输入。
具体来讲, Mamba 采用 生成参数 , 其中 是投影矩阵。值得注意的是, 10式就是 Mamba 中采用的选择性 SSM。
1.3 用统一的视角看待选择性状态空间模型与线性注意力
对于 个 token 的输入序列 , 选择性状态空间模型和线性注意的公式分别如式10和式4所示。这两个操作的公式之间存在许多潜在的相似性。为了便于理解, 作者用统一的公式重写式10和式4:
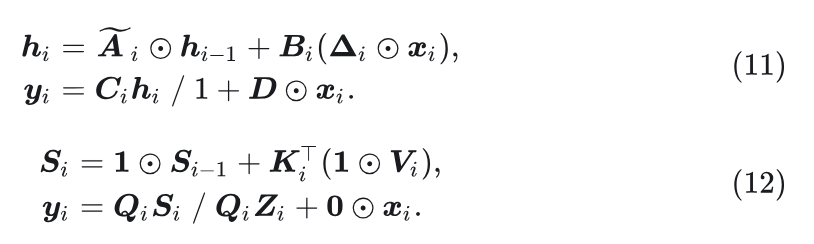
如图1所示, 式11和12之间的关系显而易见。具体来讲, , 。因此, 选择性 SSM 可以看作是 Linear Attention 的特殊变体, 表明这两种机制之间的联系非常密切。此外, 可以观察到4个主要差异:
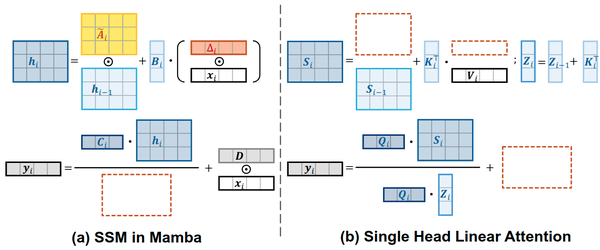
在式11中, 输入 由带有 的 Hadamard 积增强。由于 , 的所有元素都是正数。因此, 可以将 视为输入门, 控制是否让输入 进入隐藏状态。
在式11中, 有一个额外的 。Mamba 将 设置为具有负对角元素的对角矩阵, 从而确保 的所有元素落在 0 和 1 之间。因此, 作者将 解释为遗忘门, 它决定前一个隐藏状态 的衰减程度。
式11使用从输入 到输出 的可学习捷径, 即 。
在式12中, 线性注意力将输出除以了 , 保证注意力权重之和为1, 而式11没有这样的归一化。
除了这4个差异之外,重要的是要注意式12表示单头线性注意力。这表明选择性状态空间模型类似于单头线性注意,不包含多头设计。
总之,选择性 SSM 和线性注意力之间的相似性和差异可以概括为:
选择性状态空间模型类似于具有附加输入门、遗忘门和 Shortcut 的线性注意力,同时省略归一化和多头设计。
1.4 关于每个差异的分析
1)输入门: 实际上充当输入 的输入门, 确定它对隐藏状态的访问。该输入门的值从当前输入 预测为 。因此, 通过学习 的权重, 该模型可以识别 的 "效用", 为 "有用" 的 生成较大的 值, 为 "无用" 的 生成较小的 值。例如, 在视觉任务中, 表示前景对象的 token 可能会产生更大的输入门值, 而背景 token 可能会产生更小的输入门值。
2)遗忘门: 在选择性状态空间模型中充当遗忘门,提供2个基本属性:局部偏差和位置信息。首先, 的所有值的范围都是从 0 到 1的, 表明模型在到达当前 token 时始终衰减先前的隐藏状态 。这就会带来强烈的局部偏差。
其次, 为模型提供位置信息。它确保模型对输入序列的顺序很敏感。如果没有这个遗忘门,重新排列前面序列的顺序不会影响后续输出。例如, 在循环线性注意中, 如果我们改变 和 的顺序, 输出 不会改变。因此, 遗忘门 在选择性 SSM 中起着重要作用。尽管遗忘门的有效性, 但合并遗忘门也带来了重大挑战。首先, 遗忘门迫使模型在训练和推理过程中采用循环公式。以前的 SSM 通常使用全局卷积进行有效的并行训练, 但由于 的输入依赖性, 导致与选择性 SSM 不兼容 (选择性 SSM 的 与输入不相关)。作为补救措施, Mamba 提出了一种硬件感知算法, 通过在循环模式下执行并行扫描来加速计算。虽然有效, 但这种循环计算不可避免地会降低模型吞吐量, 但仍然比并行线性注意力慢。
其次,遗忘门本质上属于是 causal mode,可能不太适合非自回归视觉模型。在视觉任务中使用遗忘门 需要将图像转换为一维序列并进行循环计算,这限制了每个图像 token 的感受野并导致额外的延迟。因此,作者认为遗忘门非常适合对因果数据进行建模,这些数据自然需要自回归训练和循环计算。然而,它可能不适合像图像这样的非因果数据。作者进一步推测,合适的位置编码可以替代遗忘门,因为某些位置编码,如 LePE 和 RoPE,也可以提供局部偏差和位置信息。
3) Shortcut: 选择性 SSM 采用可学习的 Shortcut 连接 ,使其类似于残差块。这种 Shortcut 可能有助于优化模型和稳定训练。
4) 归一化: 线性注意力的输出除以 , 以确保注意权重总和为1。作者认为这种归一化对于稳定训练和提高模型容量至关重要。比如说现在有一个输入 , 那它就会对应到 。如果没有归一化, 则 的值的范围也会更大。这可能会导致训练不稳定, 并可能降低模型的表达能力。规范化注意力权重可以显着缓解这个问题。因为 的值也会同步增加。
5) Multi-head: 线性注意力机制通常使用多头设计来获得更好的结果。多头注意力允许模型同时关注不同位置的各种表示子空间的信息,从而增强其表达能力。
1.5 宏观架构设计
线性注意 Transformer 模型通常采用图 3(a) 中的设计,它由线性注意力模块和 MLP 模块组成。相比之下,Mamba 通过结合 H3[5]和 Gated Attention[6]这两个设计来改进,得到如图 3(b) 所示的架构。改进的 Mamba Block 集成了多种操作,例如选择性 SSM、深度卷积、线性映射、激活函数、门控机制等,并且往往比传统的 Transformer 设计更有效。
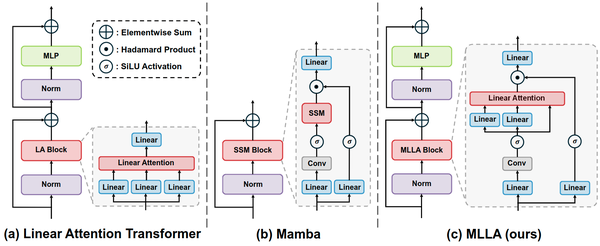
Mamba 和线性注意力 Transformer 的关系
Mamba 可以看作是具有特殊线性注意力和改进的 Block 设计的线性注意力 Transformer 变体。 线性注意力的变体,即选择性状态空间模型,与常见的线性注意力范式相比有5大区别。
下面作者通过实验来评估每个区别的影响,揭示了 Mamba 成功背后的核心贡献到底是什么。
作者采用了 Swin Transformer[7]架构来验证六个差异的影响。首先将 Swin Transformer 中的 Softmax attention 替换为线性注意力来创建基线模型。然后分别对基线模型引入每个区别来评估其影响。作者进一步将有用的设计集成到线性注意力 Transformer 中以创建本文的 Mamba-like Linear Attention (MLLA) 架构,并将其与各种视觉 Mamba 进行比较来评估其有效性,包括 ImageNet-1K 分类 、COCO 目标检测和 ADE20K 语义分割。
1.6 每种差异的影响和 MLLA 最终方案
作者分别将每个区别应用于线性注意力模型并评估其在 ImageNet-1K 上的性能,结果如下图4所示。
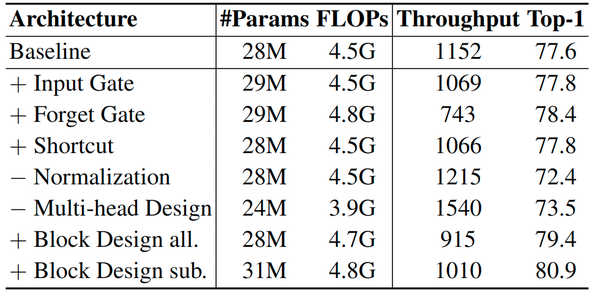
1) 输入门: 使用输入门可以略微提升模型的精度 0.2%。图5中的可视化有助于理解输入门的影响。可以看出,该模型倾向于为前景物体等信息丰富的区域生成更高的输入门值,同时抑制不太有用的 tokens。此外,使用输入门会导致模型吞吐量降低 7%。

2) 遗忘门: 在线性注意中使用遗忘门可以显着提高性能,从 77.6% 提高到 78.4%。然而,这种精度增益是有代价的:模型吞吐量从 1152 严重下降到 743。这是因为遗忘门必须使用循环计算,比线性注意力中的并行化矩阵乘法慢。值得注意的是,作者利用 Mamba 中提出的硬件感知算法来加速循环计算。作者认为遗忘门可能不太适合对非因果数据进行建模,例如图像,其本质上不需要递归。作为替代方案,作者分析了遗忘门的基本属性,并尝试将其替换为其他并行化的操作。
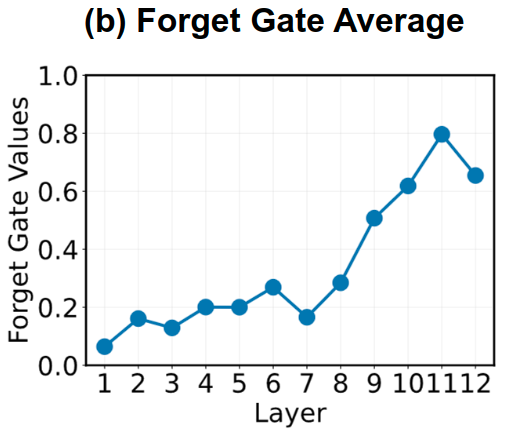
在图5中,作者计算了每一层的遗忘门值的平均值,并说明不同遗忘门值的衰减效应。在浅层,遗忘门值 ,表明每个 token 主要关注自身和前两个 tokens,表现出强烈的局部偏差。在更深的层中,平均值约为 0.6-0.8,这表明每个标记的感受野很广。这证实了作者的分析,即遗忘门为模型提供了两个关键属性,即局部偏差和位置信息。
作者进行实验以验证遗忘门是否可以替换为适当的位置编码,因为其也可以提供局部偏差和位置信息。图7的结果表明 APE、LePE、CPE 和 RoPE 都可以帮助模型比遗忘门产生更好的结果,同时保持高吞吐量。作者将改进的结果归因于更广泛的感受野。具体而言,当使用遗忘门时,就必须采用循环线性注意格式,将每个 token 的感受野限制为前面的序列。相比之下,如果没有遗忘门,很自然地利用并行线性注意力来实现全局感受野。
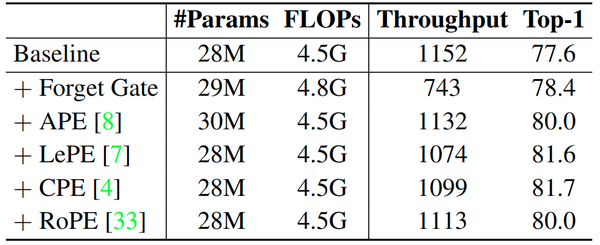
3) Shortcut: 在线性注意力中使用可学习 Shortcut 提供了 0.2% 的精度增益,同时将吞吐量从 1152 降低到 1066。
4) 归一化: 在没有归一化的情况下,模型严重的性能下降从 77.6% 下降到 72.4%。
5) Multi-head: 现代 Transformer 通常采用多头设计来增强其表达能力。移除这种设计降低了计算成本并加速了模型,但显着降低了性能。因此作者不使用这个做法。
6) Block Design: 作者采用两种方法来评估 Mamba 的 Block Design 的影响:
1. 用 Mamba 的 Block Design 替换整个 Transformer Block。
2. 用 Mamba Block 设计替换注意力 Block,同时保留 MLP Block。在这两种情况下,Mamba BLock 中的选择性 SSM 都被替换为线性注意力。为了维护类似的 FLOP,作者对两种设置分别使用 Mamba 扩展因子 E = 2.0 和 E = 1.0。结果如图4所示。这两种情况分别用 Block Design all 和 Block Design sub 表示。两种替换方法都可以提高性能,证明了 Mamba 宏观设计的有效性。替换注意力 Block 可以产生更好的结果,得到如图 3(c) 所示的 MLLA 架构。MLLA 架构的计算复杂度可以表示为:

基于这些发现,作者将遗忘门和 Block Design 集成到线性注意力中, 得到本文的 MLLA 模型。值得注意的是,MLLA 实际上使用 LePE、CPE 和 RoPE 分别替换遗忘门的局部偏差、依赖于输入的位置信息和全局位置信息。
1.7 实验结果
图像分类实验结果
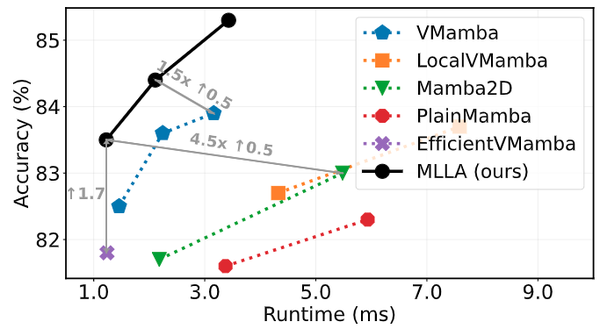
如图8所示,由于集成了 Mamba 和 Linear Attention 的有用设计,本文的 MLLA 模型在所有模型大小上始终优于各种视觉 Mamba 模型。这些结果也说明了凭借 Mamba 的这两点设计,线性注意力机制模型的性能也可以超越 Mamba 架构。作者也实证性地观察到,与视觉 Mamba 模型相比,MLLA 表现出更高的可扩展性,因为 MLLA-B 达到了 85.3 的精度,大大超过了其他模型。

作者在图9中提供了速度测量结果。用位置编码替换遗忘门,本文的 MLLA 模型受益于并行化的计算,与视觉 Mamba 模型相比推理速度明显更快。
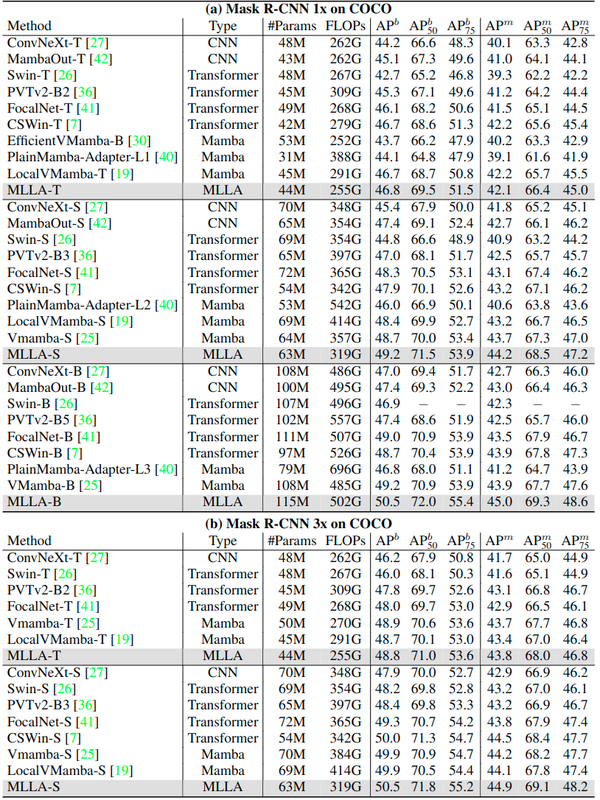
COCO 目标检测实验结果
如图10所示,在 COCO 数据集上,MLLA 模型结果也优于视觉 Mamba 模型,这意味着 MLLA 对于高分辨率密集预测任务的有效性。MLLA 提供了具有线性复杂度 \mathcal{O}(N)\mathcal{O}(N) 的全局建模和并行化的计算,使其非常适合高分辨率图像建模。值得注意的是,MLLA 大大优于 MambaOut,这也与 MambaOut 中的结论 (即 SSM 对于高分辨率密集预测任务很重要) 是一致的。
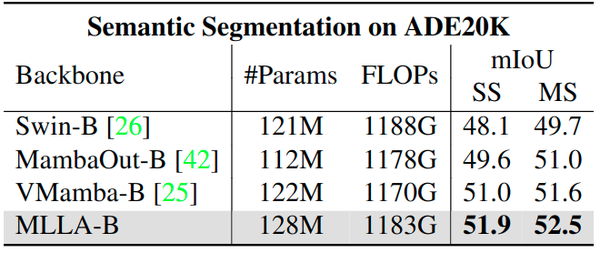
ADE-20K 语义分割
如图11所示为 ADE-20K 数据集的结果。与目标检测任务类似,MLLA 在语义分割也得到了更好的结果,进一步验证了本文分析和 MLLA 模型的有效性。
参考
^abMamba: Linear-Time Sequence Modeling with Selective State Spaces
^Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
^Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
^FLatten Transformer: Vision Transformer using Focused Linear Attention
^Hungry Hungry Hippos: Towards Language Modeling with State Space Models
^Transformer Quality in Linear Time
^Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









