






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心分享一篇基于神经位姿特征的视觉定位技术,已被ECCV2024收录。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
编辑 | 自动驾驶之心
论文地址:https://arxiv.org/abs/2403.12800
项目主页:https://gujiaqivadin.github.io/posemap/

方法概述:
这篇文章首次提出了一种用于相机定位的神经体位姿特征——PoseMap,利用神经体中编码的视角特征刻画图像的相机位姿信息。该文将PoseMap与神经辐射场(Neural Radiance Fields,NeRF)结合设计了NeRF-P模块,并将它与绝对位姿回归(Absolute Pose Regression,APR)框架进行结合,提出了一种新的相机位姿回归网络结构。这种结构不仅有助于合成新视角图像以丰富训练数据集,而且能够有效学习姿势特征。此外,该方法还拓展了网络结构以达到在线阶段的自监督训练目的,实现在统一框架内使用和微调框架来处理未标记相机位姿的额外图像,进一步提高相机位姿估计精度。实验表明,该方法在室内和室外场景相机位姿估计任务中平均实现了14.28%和20.51%的性能增益,超越了现有APR方法。
1. 问题背景
基于图像的相机定位技术是3D视觉领域中学术界与工业界聚焦的一项关键任务,对于实现三维重建、自动驾驶、环境感知及AR/VR应用的深度交互至关重要。近期,绝对姿态回归(Absolute Pose Regression, APR)作为一种创新方法,日益受到瞩目。该方法与传统基于结构技术(如Structure from Motion, SfM)形成对比,通过单一神经网络推理即可直接估计相机位姿,显著提升了处理速度与效率,同时在处理无纹理或重复纹理图像时展现出更强的鲁棒性。APR通常依托监督学习框架,利用图像与其对应相机姿态对来训练回归模型,进而使模型能够直接为新的查询图像预测相机位置与方向,开辟了相机定位研究的新前景。
然而,APR的一个核心挑战在于其性能依赖于训练集覆盖的场景多样性,即观察场景越丰富,位姿估计越精确。这突显出扩充高质量带标签图像数据集的重要性。神经渲染技术,如NeRF( Neural Radiance Fields)技术的出现为这一挑战提供了新的解法。这些技术使得从任意视角合成逼真场景图像成为可能,为相机定位系统提供了强大的数据扩充手段。例如,DFNet与LENS等研究通过整合NeRF生成的图像到训练流程中,致力于缩减真实与合成图像间的特征差异,有效提升了算法性能。
更进一步,这篇文章认识到NeRF与APR之间存在着深刻的内在联系:NeRF通过“位姿到图像”的映射构建场景,而APR则执行相反的“图像到位姿”的逆向操作。这暗示着双方可以实现更深层次的协同——不仅限于将NeRF生成的图像简单作为额外训练数据,而是探索如何在NeRF的渲染机制内嵌入对相机位姿本质的理解,利用NeRF深化APR对场景结构与相机位置的洞察力。通过建立NeRF与APR任务的耦合有望推动相机定位技术实现更精准、高效的位置与姿态估算能力。
由此,该文首次提出了一种用于相机定位的神经体位姿特征——PoseMap,利用神经体中编码的视角特征刻画图像的相机位姿信息。本文将PoseMap与NeRF结合设计了NeRF-P模块,并将它与APRNet结构进行结合,提出了一种新的相机位姿回归网络结构。这种结构不仅有助于合成新视角图像以丰富训练数据集,而且能够有效学习姿势特征。此外,该文还拓展了本文的网络结构以达到在线阶段的自监督训练目的,实现在统一框架内使用和微调框架来处理未标记相机位姿的额外图像,进一步提高相机位姿估计精度。实验表明,该方法在室内和室外场景相机位姿估计任务中平均实现了14.28%和20.51%的性能增益,超越了现有APR方法。
2. 实现方法
给定一组图片和对应的相机位姿,该目标是训练一个神经网络是的对于一张输入图片,可以直接预测它对应的相机位姿。图1展示了整个算法流程。
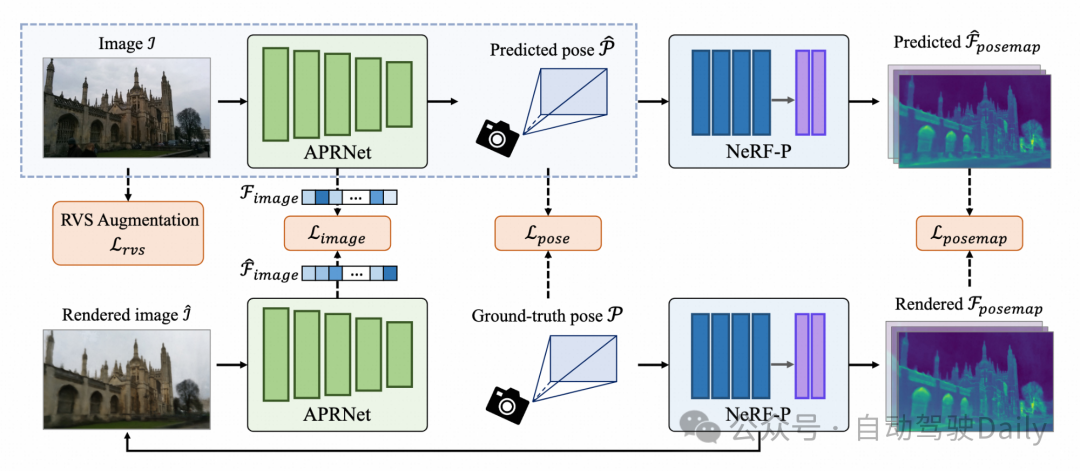
它主要包含2个模块:APRNet和NeRF-P。其中,APRNet利用单独的分支抽取输入图像的图像特征,并且估计相机位姿。对于给定的位姿真值,NeRF-P渲染合成图像,并同样抽取其图像特征。此外,本文提出了一种隐式的位姿特征,成为PoseMap。整体设计主要来源于以下两方面的思考:
现有技术大多聚焦于利用NeRF的正向渲染过程,却忽略了挖掘神经体中编码特征的价值。鉴于NeRF中实质上已经集成了图像和姿态信息,在其内部应该已经蕴含了每个相机姿态的信息,等待进一步发掘。
遮挡、边界以及阴影是相机定位的重要视觉线索,它们通常被编码为神经网络中的深层特征。这从直觉上表明,姿态估计应当与这些富含信息的特征图紧密关联。
整个训练流程分为2个步骤:先完成NeRF-P的训练,随后将之整合进APRNet的训练流程。而在实际应用的推理阶段,仅需APRNet即可迅速完成预测。
NeRF-P作为NeRF的拓展版本,不仅服务于新观察角度图像的合成,而且在其设计中融入了对更精细相机位姿特征PoseMap的学习监督(见下图2)。与CROSSFIRE[1]及NeFeS[2]尝试利用NeRF合成CNN图像特征的想法不同,PoseMap更关注于建立3D场景隐含信息与相机位姿之间的直接联系,通过NeRF的本征特征来指导生成PoseMap特征图。
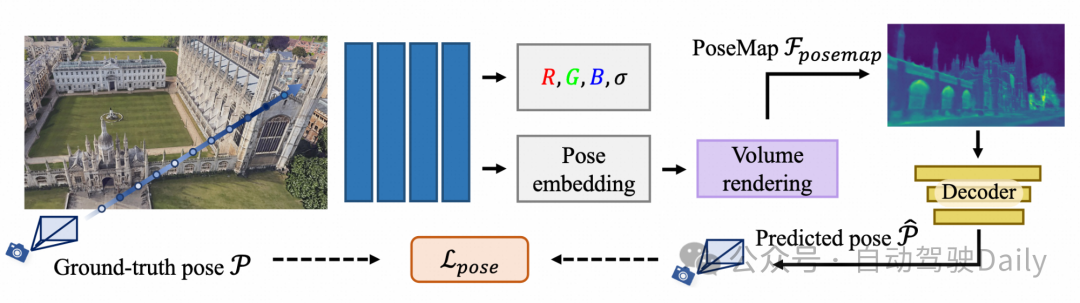
APRNet的训练结构如图1所示,该过程使用带相机位姿真值的标注图片,并利用NeRF-P来训练APRNet。该方法在损失函数设计不仅使用了预测位姿与实际位姿之间的均方误差(MSE),还引入了基于NeRF-P生成的PoseMap的余弦相似度误差。此外,该方法借鉴了DFNet[3]的随机视图合成(RVS)策略,通过使用相同的图像特征三元组误差项,有效缓解图像域差异,同时防止了特征空间的坍塌现象,从而提升了模型的整体泛化性能和稳定性。
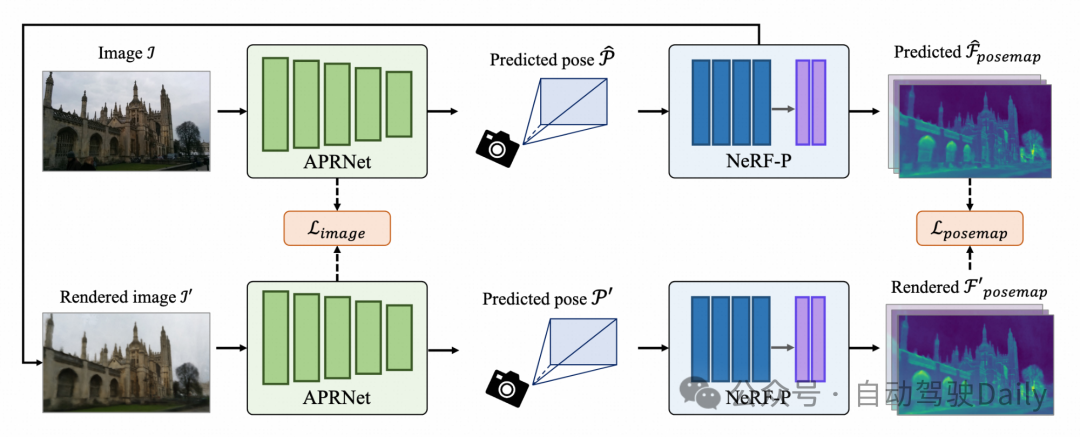
由于APR算法的效果受限于训练数据,而大量无相机位姿信息的场景图像(如互联网图像)易于获取,专门设计了利用这些无标签数据的训练策略,进一步提升APR的效果。一方面以预训练的APRNet的低层特征作为图像特征;另一方面以NeRF-P得到的PoseMap作为位姿特征。通过计算输入图像经过APRNet预测的位姿后,由NeRF-P渲染出的图像与原输入图像之间的特征匹配误差,以及输入图像预测位姿与基于同一渲染图预测的位姿之间的位姿特征差异,该方法构建了一个闭环的自我监督训练过程。该流程图3所示,有效融合无相机姿态信息的图像数据,以增强模型的泛化能力和预测精度。
更详细的算法描述,请参考论文原文。
3. 实验效果
该算法分别在两个相机定位评测数据集(7-Scenes室内场景数据集和Cambridge Landmarks室外场景数据集)上进行了测试和对比。与同类方法对比,该方法在相机位姿估计的平移和旋转误差方面都有明显优势。
表1展示了算法在7-scenes数据集上的评测结果。
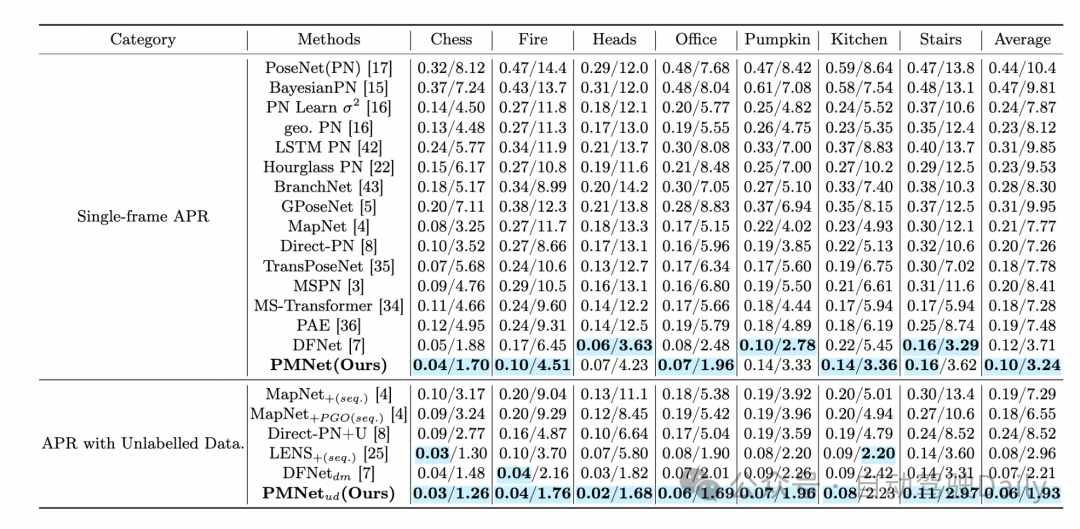
表2展示了算法在Cambridge Landmarks数据集上的评测结果。
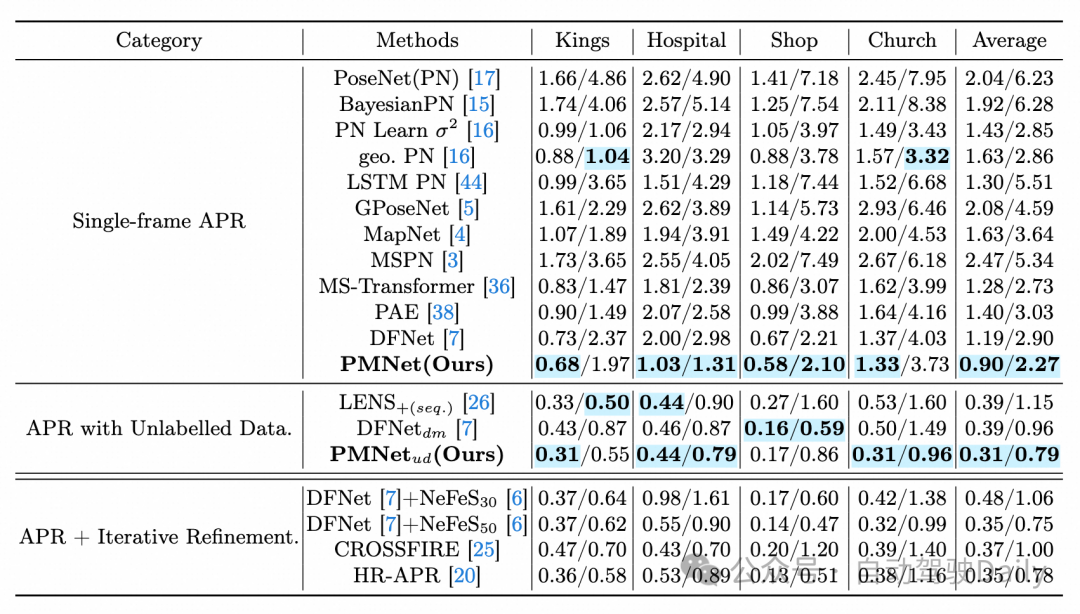
同时,本文也从相机位姿可视化图上(图4)评估了算法的先进性。其中三维坐标系中红色表示预测相机位置,绿色表示真实位置;colorbar中颜色从蓝到黄表示旋转角度误差从小到大。由图可见,该方法预测的相机位姿序列整体上更接近真实相机位姿序列。
此外,该方法还通过PCA 降维的方式直观可视化了PoseMap的具体图像(图5)。从左到右包括:显示输入的真实图像(左)、估计的姿势的渲染图像(第二列)、APR 特征图(第三列)和PoseMap(右)。可以看到,与 APR 图像特征相比,该方法提出的 PoseMap 特征通过聚合光线样本的全局属性来捕获相机姿态的隐式特征,从而产生比 2D-CNN 主干网络具有更清晰几何信息的局部特征,这对于相机定位任务具有更大的意义。
4. 局限性
与其它基于学习的方法类似,PMNet 也与 NeRF 和 APRNet 有相同的局限性。首要,姿态估计的精确性深受合成图像质量的影响,这突显出对鲁棒性更强的 NeRF 模型的需求,以强化输出结果的可靠性。其次,当前依赖于APR的相机定位技术没有充分利用场景中固有的几何结构信息,未来研究可考虑融入更为明确的结构性信息元素,如2D轮廓线与3D深度信息。最后,采用层次化优化策略,可以在测试环节进一步提升估计结果。
5. 总结与展望
本文介绍了一种新颖的神经体位姿特征 PoseMap,旨在提升相机定位效果。该特征通过神经体刻画了相机位姿的隐式信息,并且可以通过在NeRF基础上加入位姿分支进行渲染。基于位姿特征提取模块,这篇文章开发了一种新的 APR 框架。该框架允许通过自监督的方式使用未标记的图像进行在线优化。实验表明,该方法在室内外数据集上,与基于深度学习的相机定位技术相比,平均性能提升了14.28%和20.51%,超越了现有的APR方法。
该方法与基于几何结构的方法相比,在估计效率方面有明显优势,但是在估计精度方面仍有差距。但基于APR的相机定位技术在定位精度方面拥有巨大的提升空间,一种可能的方式是将更多的几何结构特征融入到APR框架中,通过几何结构提供更精确的定位信息。
6. 参考文献
[1] Moreau, A., Piasco, N., Bennehar, M., Tsishkou, D.V., Stanciulescu, B., de La Fortelle, A.: Crossfire: Camera relocalization on self-supervised features from an implicit representation. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 252–262 (2023).
[2] Chen, S., Bhalgat, Y., Li, X., Bian, J., Li, K., Wang, Z., Prisacariu, V.A.: Refinement for absolute pose regression with neural feature synthesis. ArXiv abs/2303.10087 (2023).
[3] Chen, S., Li, X., Wang, Z., Prisacariu, V.A.: Dfnet: Enhance absolute pose regression with direct feature matching. In: ECCV. pp. 1–17. Springer (2022)
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









