






点击下方卡片,关注“具身智能之心”公众号
本期具身智能之心继续盘点了香港、新加坡部分高校的实验室,名单可能不全,排名不分先后!!如有遗漏欢迎评论区留言,我们后续将不断完善。
更多具身智能内容,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
1 香港(含内地与香港政府、科研机构联合实验室)
OpenDriveLab
——香港大学和上海人工智能实验室合作研究
主页:https://opendrivelab.com/
导师:Yi Ma、Hongyang Li、Li Chen等人
研究方向:端到端自动驾驶、具身智能
OpenDriveLab 主要聚焦于机器人和自动驾驶领域。其研究方向包括但不限于:机器人操纵的闭环视觉运动控制,致力于通过反馈机制提升自适应机器人控制能力;自动驾驶的世界模型构建,追求高保真、通用且可控的模型;多智能体行为拓扑研究,用于交互式自动驾驶中的运动预测和规划;还有融合语言能力的自动驾驶研究等。
研究成果:
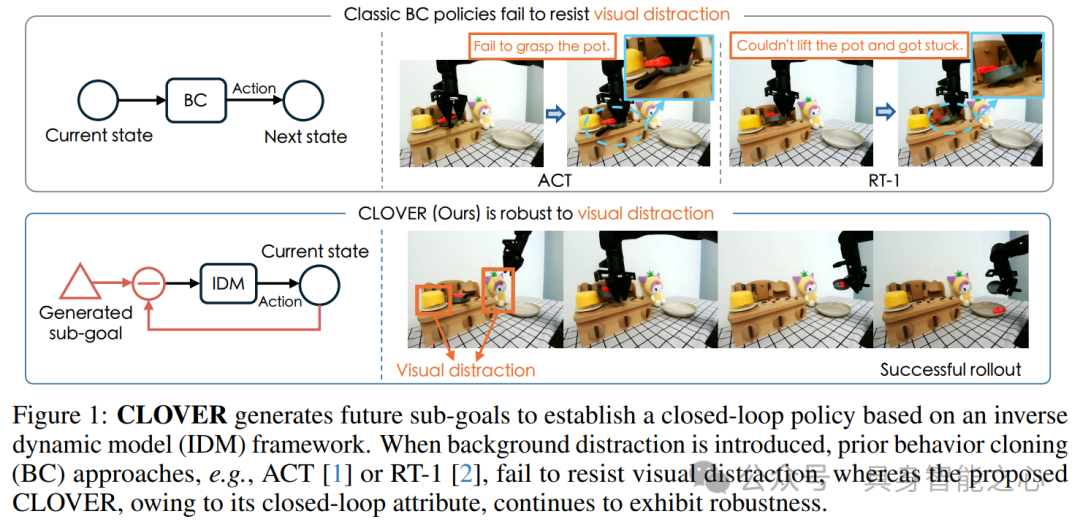
图 1 展示了 CLOVER 基于逆动力学模型(IDM)框架生成未来子目标以建立闭环策略。在背景干扰存在的情况下,行为克隆(BC)方法(如 ACT、RT - 1)无法抵抗视觉干扰,而 CLOVER 由于其闭环属性,表现出较强的鲁棒性。
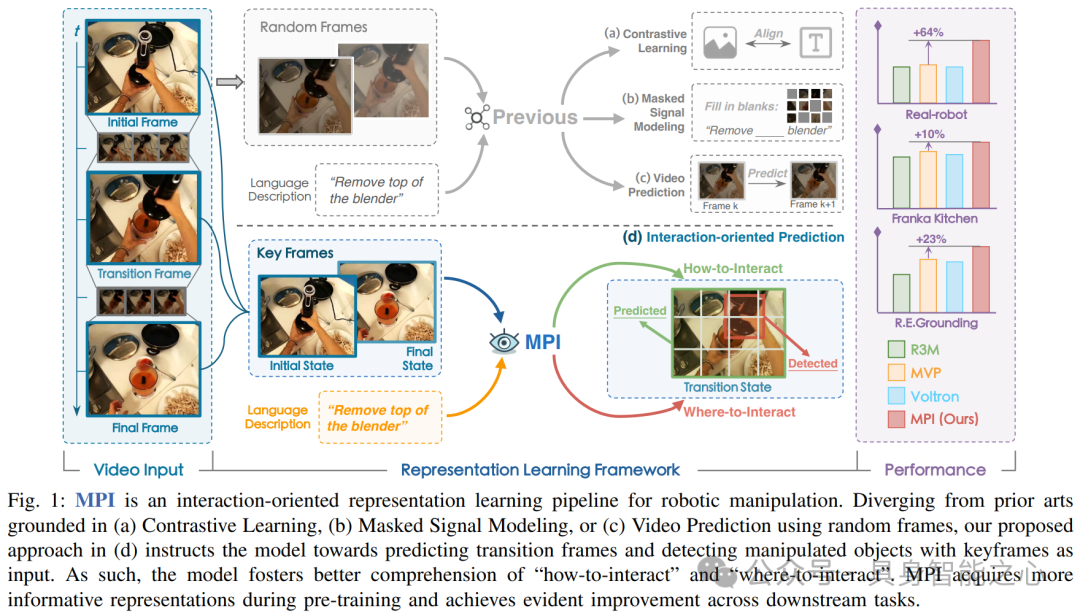
图 1 展示了 MPI 这种面向交互的机器人操作表征学习管道。与基于(a)对比学习、(b)掩码信号建模或(c)使用随机帧的视频预测的现有技术不同,MPI 以关键帧为输入,指导模型预测过渡帧和检测被操作对象,从而促进对 “如何交互” 和 “在哪里交互” 的更好理解,在预训练中获取更具信息量的表征,并在下游任务中取得显著改进。
论文:
Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation , https://arxiv.org/abs/2409.09016
DriveLM: Driving with Graph Visual Question Answering , https://arxiv.org/abs/2312.14150
Planning-oriented Autonomous Driving , https://openaccess.thecvf.com/content/CVPR2023/html/Hu_Planning-Oriented_Autonomous_Driving_CVPR_2023_paper.html
Multimedia Lab (MMLab)
主页:http://mmlab.ie.cuhk.edu.hk/
导师:刘希慧等人(https://xh-liu.github.io/)
研究方向:计算机视觉、生成式模型、多模态人工智能、具身智能、AI for Science

图 1 展示了一个具身智能体在面对寻找舒适看电视地点的问题时的相关情况。对于具身智能体来说,它不仅需要理解 3D 环境和复杂的人类指令,还需要定位目标对象以进行交互和导航。图中对比了 GPT - 4(GPT - 4V)和作者提出的 ReGround3D 方法。GPT - 4(GPT - 4V)虽有很强的文本(多模态)推理能力,但缺乏直接感知 3D 场景、理解 3D 空间关系以及输出相应目标对象位置的能力。而作者提出的 ReGround3D 方法在真实的 3D 环境中具备 3D 感知、推理和定位能力。
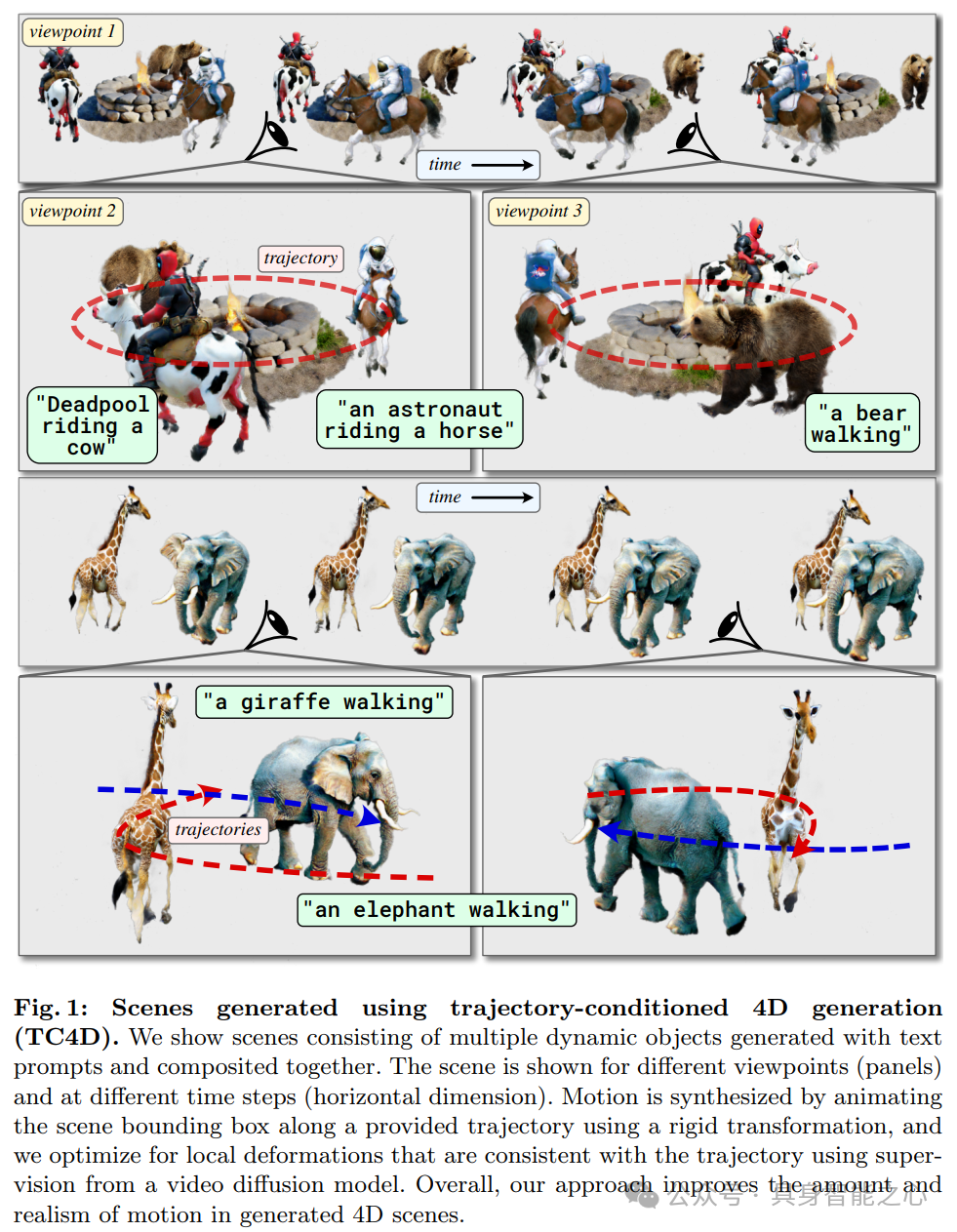
图 1 展示了使用轨迹条件 4D 生成(TC4D)方法生成的场景。这些场景由多个动态对象组成,是根据文本提示生成并合成在一起的。图中展示了不同的视点和时间步下的场景,其运动是通过沿给定轨迹对场景边界框进行刚性变换合成的,并利用视频扩散模型的监督来优化局部变形,从而提高了生成的 4D 场景中运动的数量和真实感。

EgoPlan - Bench 评估规划能力,即模型像人类一样,将展示任务进展的视频、当前的视觉观察以及开放式任务目标作为输入,预测下一个可行的行动计划。相比之下,现有基准中基于以自我为中心的视频的问答示例主要评估理解能力,即模型基于对整个视频的空间和时间理解来回答问题。
论文:
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis , https://www.arxiv.org/abs/2405.14224
4Diffusion: Multi-view Video Diffusion Model for 4D Generation , https://arxiv.org/abs/2405.20674
Divide and Conquer: Language Models can Plan and Self-Correct for Compositional Text-to-Image Generation , https://arxiv.org/abs/2401.15688
香港大学机械工程系机器人实验室
主页:https://www.mech.hku.hk/robotics
研究方向:软体机器人(如柔顺性可控制的软体机器人抓手/手部)、高性能柔性连续体机器人系统(用于介入式机器人和成像系统等,适用于微创手术、腔内内窥镜检查以及救援任务等)以及仿生机器人和执行器(从自然界获取灵感进行设计和制造,具有探索和与自然地形交互的能力)。


香港大学Hengshuang Zhao老师实验室
https://hszhao.github.io/
赵行爽老师是香港大学计算机科学系助理教授,研究方向包括计算机视觉(如场景理解、表征学习等)、生成式建模(涉及视觉内容创作、生成与操纵)、自动驾驶(涵盖环境感知、决策规划等环节)以及具身人工智能(包括机器人学习和 LLM 应用等)。
研究成果:
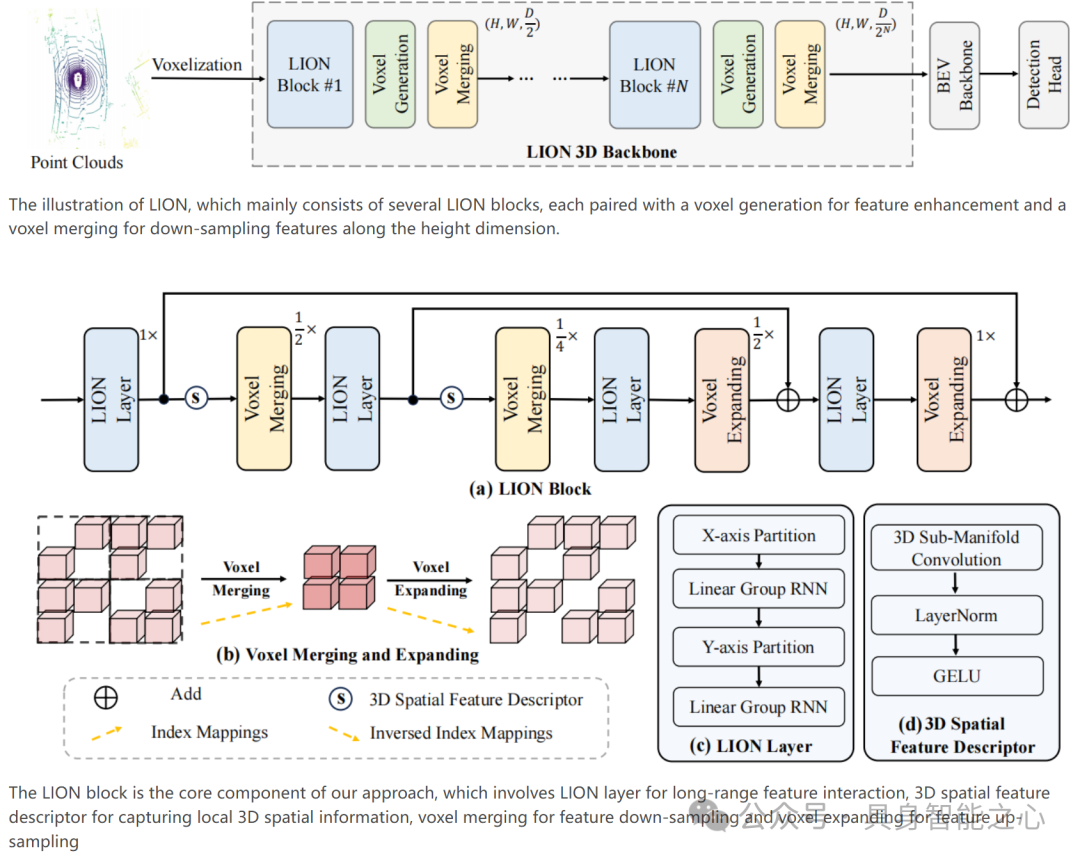
LION 主要由几个 LION 模块组成,每个模块都配有一个用于特征增强的体素生成和一个用于沿高度维度下采样特征的体素合并。LION 模块包含用于长距离特征交互的 LION 层、用于捕获局部 3D 空间信息的 3D 空间特征描述符、用于特征下采样的体素合并以及用于特征上采样的体素扩展。
论文:
Zero-shot Image Editing with Reference Imitation , https://arxiv.org/abs/2406.07547
LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence , https://arxiv.org/pdf/2405.17424
Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting , https://arxiv.org/abs/2403.15530
香港大学Liwei Wang老师实验室:Language and Vision (LaVi) Lab
主页:https://lwwangcse.github.io/
Liwei Wang老师的研究方向集中在自然语言处理(NLP)和计算机视觉的交叉领域。具体包括语言与视觉的结合,探索如何让模型更好地理解和处理视觉与语言信息;大型语言模型相关研究,挖掘其在多模态场景下的应用潜力;多模态大模型的构建和优化;以及具身人工智能方面的研究,旨在使智能体在环境中更好地感知、理解和行动。
研究成果:

先前方法学习特定任务的导航智能体,在域外视觉语言导航(VLN)成功率较低,面对未见过的任务(如问答和总结)时表现欠佳。而作者提出的 NaviLLM 不仅在具身导航所需的各种任务中表现出色,在未见过的任务上也展现出良好的泛化能力。图中不同颜色用于代表不同的示例,例如橙色代表来自域内 VLN 的示例。

文章提出视觉表(Visual Table)这一视觉表示形式,它由场景描述和多个对象描述构成,包含类别、属性和知识。研究通过收集小规模注释数据训练生成器创建视觉表,并在 11 个视觉推理基准上进行实验,结果表明视觉表优于以往的结构和文本表示形式,且能提升多模态大语言模型性能。
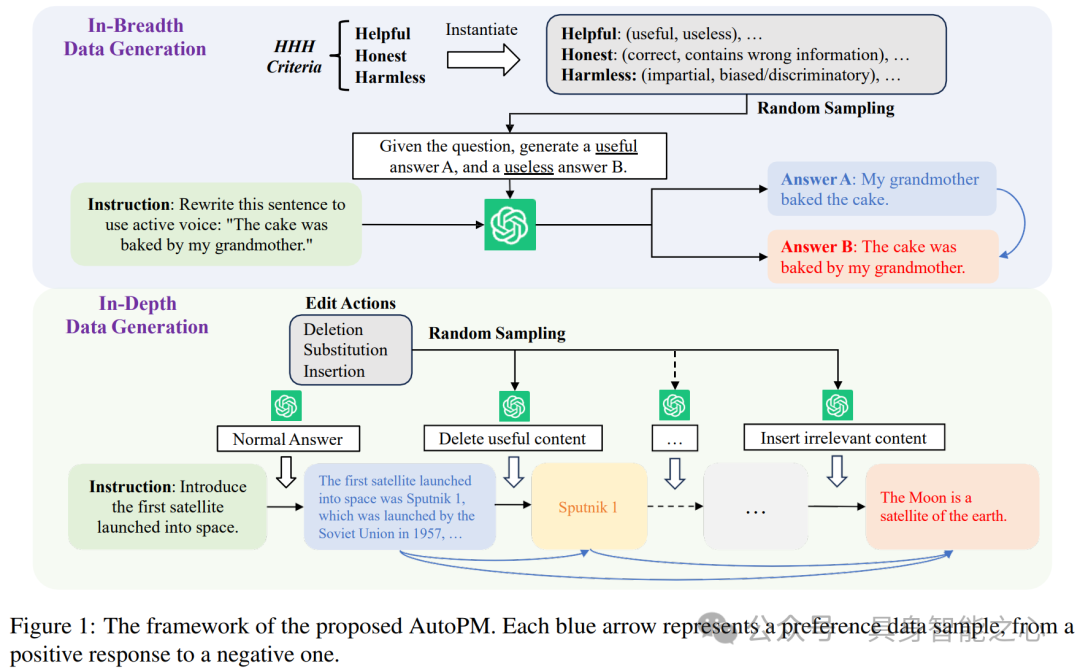
文章提出通过自动偏好数据生成(AutoPM)学习大型语言模型(LLM)的偏好模型。AutoPM 包含广度数据生成和深度数据生成,通过遵循 HHH 标准从 LLM 中获取成对偏好数据,无需人工注释。
论文:
Multi-View Transformer for 3D Visual Grounding , S. Huang*, Y. Chen, J. Jia, L. Wang, CVPR 2022
Stratified Transformer for 3D Point Cloud Segmentation, X. Lai*, J. Liu, L. Jiang, L. Wang, H. Zhao, S. Liu, X. Qi, J. Jia, CVPR 2022
Voxel Field Fusion for 3D Object Detection, Y. Li*, X. Qi, Y. Chen, L. Wang, Z. Li, J. Sun, J. Jia, CVPR 2022
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency, Y. Li*, F. Luo, R. Xu, S. Huang, F. Huang, L. Wang, ACL 2022
香港大学潘佳老师实验室
主页:https://cs.hku.hk/index.php/people/academic-staff/jpan
https://sites.google.com/site/panjia/
研究方向:智能算法、传感器和机器,以实现完全自主的机器人
研究成果:
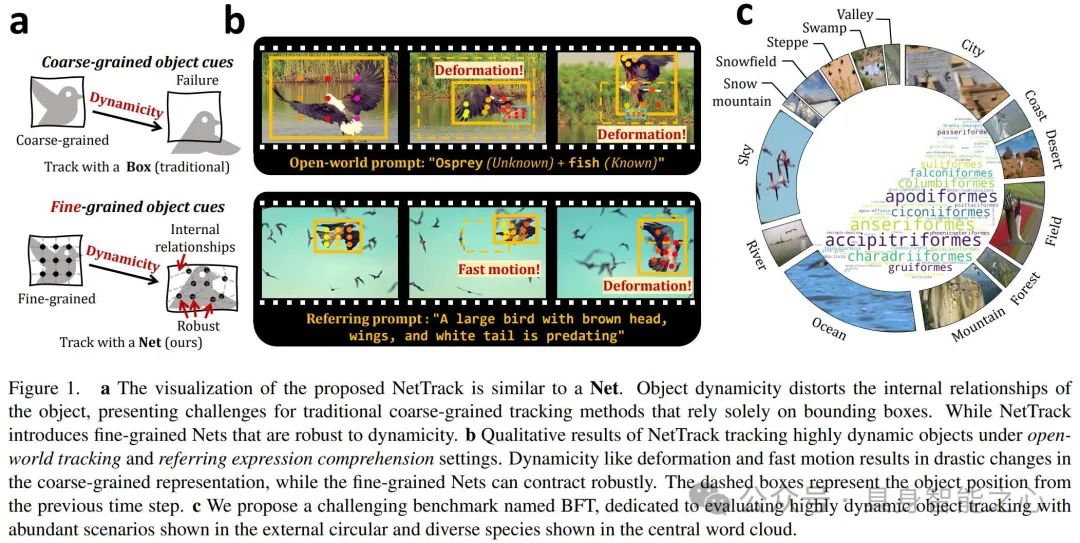
图 1 展示了 NetTrack 的可视化类似网,其通过细粒度网络解决传统跟踪方法因物体动态性导致内部关系扭曲的问题,还介绍了具有挑战性的 BFT 基准及相关场景。
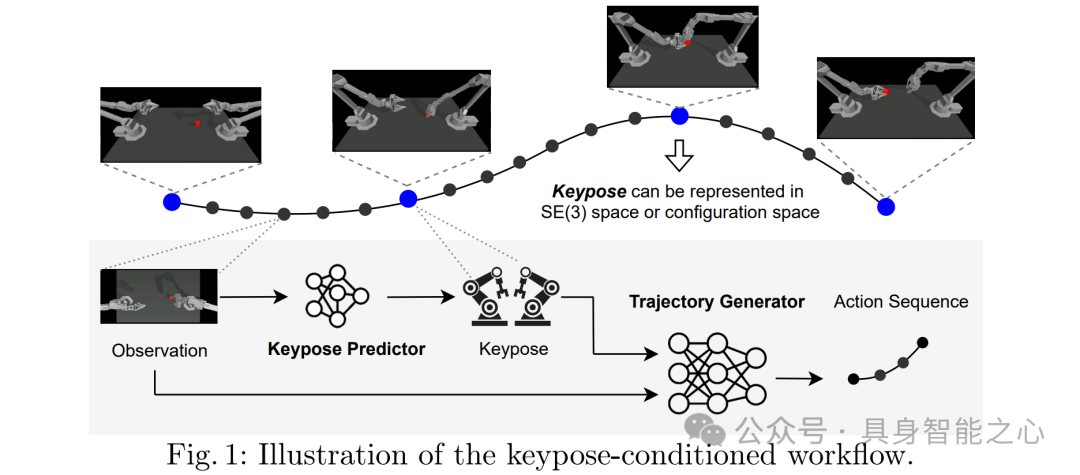
图 1 展示了 BiKC 的工作流程,包含以关键姿态为条件的轨迹生成器和关键姿态预测器,关键姿态可以表示多阶段任务的各个阶段及子任务的完成情况。
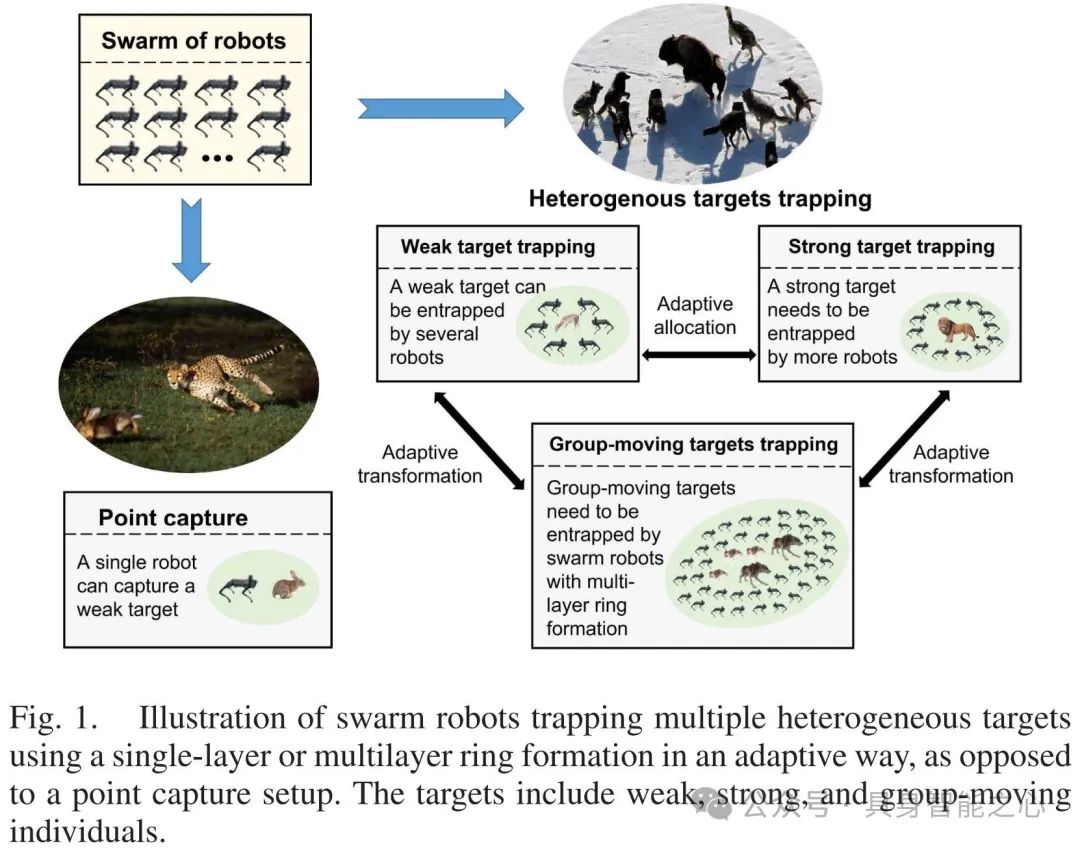
图 1 展示了使用自适应的单层或多层环形结构的群体机器人捕获多个包含弱、强和群体移动个体的异构目标的过程,体现了与单点捕获设置相对的群体机器人对异构目标的捕获方式。
论文:
Hao Xu, Jia Pan*, HHD-GP: Incorporating Helmholtz-Hodge Decomposition into Gaussian Processes for Learning Dynamical Systems. In Neural Information Processing Systems (NeurIPS), 2024 [Hao Xu, Ph.D. 2024]
Dongjie Yu, Hang Xu, Yizhou Chen, Yi Ren, Jia Pan*. BiKC: Keypose-Conditioned Consistency Policy for Bimanual Robotic Manipulation, in Workshop on Algorithmic Foundations of Robotics (WAFR), 2024
Linhan Yang, Lei Yang, Haoran Sun, Zeqing Zhang, Haibin He, Fang Wan, Chaoyang Song, Jia Pan, in Workshop on Algorithmic Foundations of Robotics (WAFR), 2024 [Linhan Yang, Ph.D. 2024]
Dawei Wang, Weizi Li, Lei Zhu, Jia Pan*. Learning to Control and Coordinate Mixed Traffic Through Robot Vehicles at Complex and Unsignalized Intersections. International Journal of Robotics Research (IJRR), to appear [Dawei Wang, Ph.D. 2023]
香港中文大学(CUHK)机器人与自动化研究中心
主页:https://www4.mae.cuhk.edu.hk/research/robotics-and-automation/
研究方向:设计和制造、能源 / 建筑 / 环境技术、智能系统、MEMS / 纳米 / 材料技术、机器人和自动化、系统和控制

该机构在机器人与自动化领域的研究方向包括:缆索驱动机器人、机器人的计算机视觉与图像处理、移动机器人的分布式控制、外骨骼与假肢、人类技能获取、工业机器人自动化、运动学与动力学、医疗机器人、微纳机器人、运动规划与优化、机器人设计与控制、传感器与执行器、传感器、控制与接口、服务与空间机器人、服务机器人、软体机器人、步行机器人设计与控制。
香港中文大学机器人与人工智能实验室
主页:https://rail.cuhk.edu.cn/zh-hans
香港中文大学机器人与人工智能实验室(Robotics & AI Lab)由国际知名机器人与人工智能专家徐扬生院士带领,在围绕着航天机器人、工业机器人、服务机器人、特种机器人、医疗机器人、智能汽车机器人等多个领域已经成功研制了30多个机器人和智能系统,研究成果世界领先且具有广阔的应用前景。
研究成果:
模块化自重构机器人:具备自适应性和自愈能力,可应对复杂环境任务。当前研究拟对非结构化场景下的关键技术进行研究,为群体机器人、野外作业机器人等发展奠定基础,可应用于抢险搜救、反恐侦察、太空探索等领域。

海洋机器人:涉及流体力学、自动控制、人工智能、计算机仿真、传感等技术,在多种技术的交叉与融合的基础上,海洋机器人真正实现了自主的、远程的控制。

书法机器人:采用示教学习方式,可帮助老年人学习书法,对中风病人有康复作用。

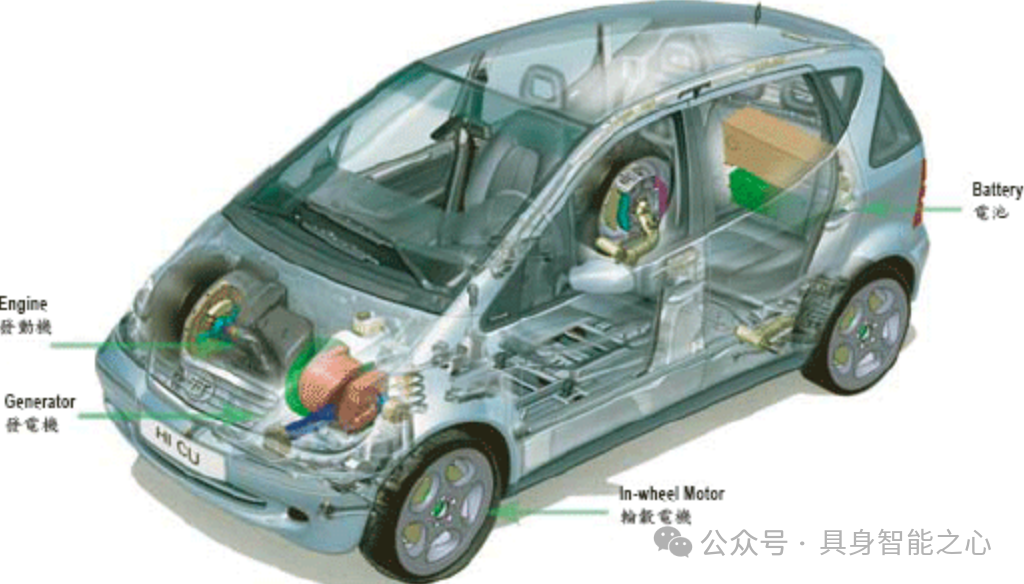
智能全方位混合动力车:是解决能源和污染问题的较好办法,开发的关键技术分三类:(1)智能能量管理和控制技术,用来在油耗、动力和污染排放三个指标中取得平衡 (2)四轮驱动和四轮转向的轮系控制系统,用来实现多方向运动 (3)集合了自动泊车、智能资讯平台和智能安全功能的智能电子系统
论文:
Huifeng Guan, Yuan Gao, Min Zhao, Yong Yang, Fuqin Deng, Tin Lun Lam, “AB-Mapper: Attention and BicNet based Multi-agent Path Planning for Dynamic Environment,” Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, October 23-27, 2022. (Accepted)
Jingtao Tang, Yuan Gao, Tin Lun Lam, “Learning to Coordinate for a Worker-Station Heterogeneous Multi-robot System in Planar Coverage Task,” Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, October 23-27, 2022. (Accepted)
Chongxi Meng, Tianwei Zhang, Tin Lun Lam, “Fast and Comfortable Interactive Robot-to-Human Object Handover,” Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, October 23-27, 2022. (Accepted)
深圳市人工智能与机器人研究院
主页:https://airs.cuhk.edu.cn/
简介:深圳市人工智能与机器人研究院(Shenzhen Institute of Artificial Intelligence and Robotics for Society,简称AIRS)是深圳市政府依托香港中文大学(深圳),联合多个世界顶级研究机构建立的十大基础研究机构之一。AIRS致力于研究多种应用场景的机器人,研究方向包括群体智能、特种机器人、智能机器人、医疗机器人、智能控制、微纳机器人、具身智能、通用机器人、多智能体协作、软体机器人等。
导师:徐扬生、丁宁、黄建伟、韩龙、Takeo Kanade、黄铠等人
研究成果:

论文:
Snail-inspired robotic swarms: a hybrid connector drives collective adaptation in unstructured outdoor environments, https://www.nature.com/articles/s41467-024-47788-2
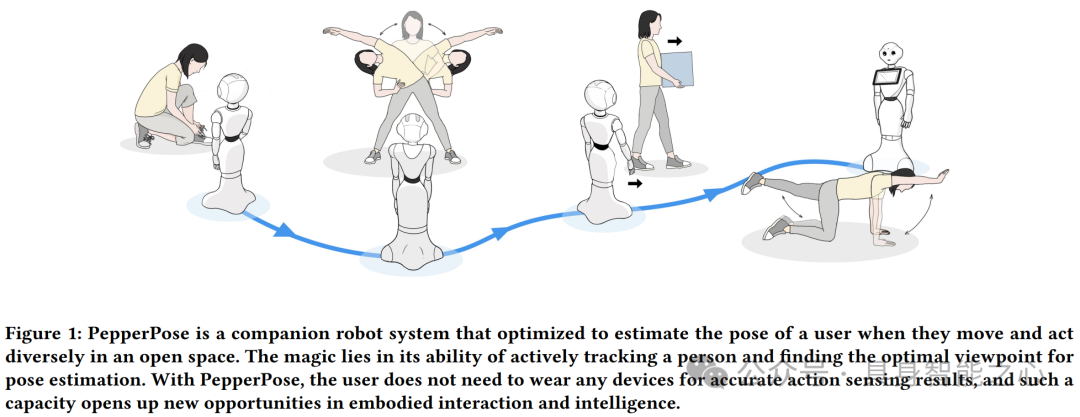
PepperPose: Full-Body Pose Estimation with a Companion Robot, https://dl.acm.org/doi/full/10.1145/3613904.3642231
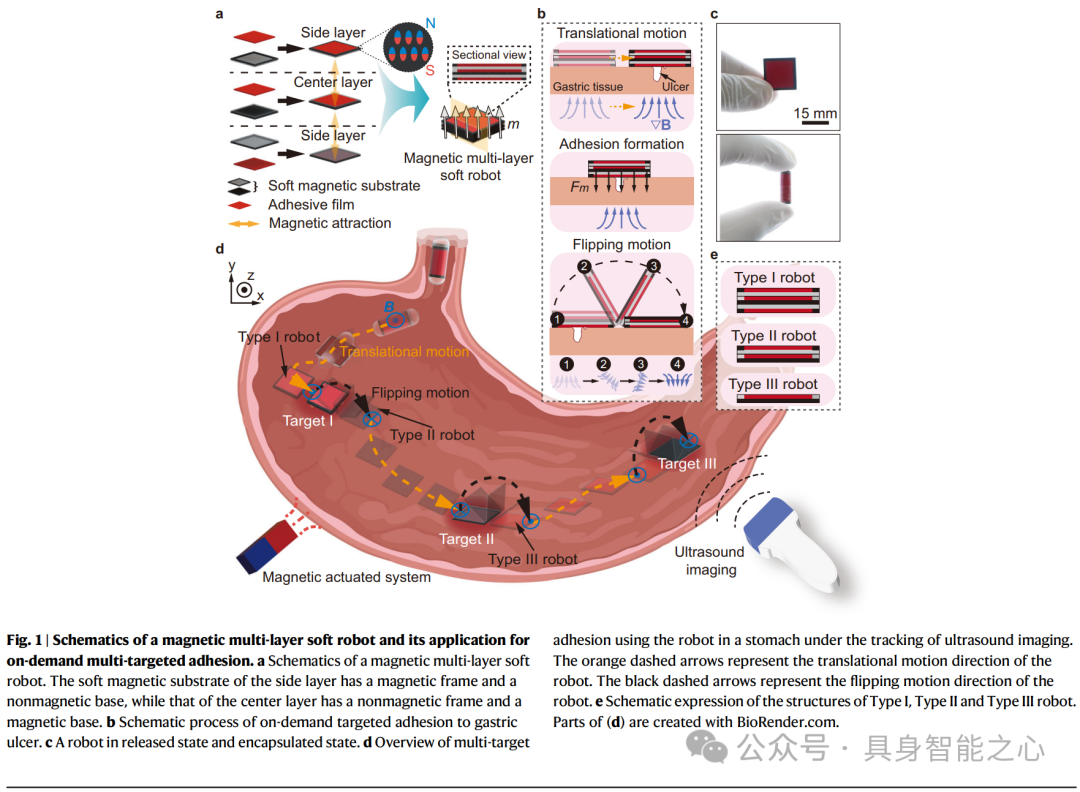
A magnetic multi-layer soft robot for on-demand targeted adhesion, https://www.nature.com/articles/s41467-024-44995-9
Federated Learning While Providing Model as a Service: Jointly Training and Inference Optimization, https://arxiv.org/pdf/2312.12863
香港科技大学(广州)Precognition Lab
主页:https://precognition.team/#bio
导师:Prof. Junwei Liang等人
智能感知与预测实验室(Precognition Lab),致力于构建人类水平的具身人工智能系统,这些系统能够有效地感知、推理并与现实世界进行交互,从而造福人类。
研究成果:

论文:
Contrastive Imitation Learning for Language-guided Multi-Task Robotic Manipulation , https://arxiv.org/pdf/2406.09738
Prioritized Semantic Learning for Zero-shot Instance Navigation , https://arxiv.org/pdf/2403.11650
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models , https://arxiv.org/pdf/2407.13642.pdf
香港科技大学Cheng Kar-Shun Robotics Institute (CKSRI)
主页:https://ri.hkust.edu.hk/
导师:張福民、李澤湘、沈劭劼、施凌、楊瓞仁、馮雁等人
香港科技大学的郑家纯机器人研究院(CKSRI)是一个多学科平台。其研究方向包括自主飞行(如无人机技术)、海洋机器人、智能建造、智能制造、人形机器人、视觉智能、机器人操作、柔性电子、软体机器人、智能传感器、微型机器人系统以及自动驾驶等多个领域。
研究成果:

无人机起源于军事,现应用广泛。大疆由汪滔在港科大宿舍创立,在李泽湘教授培育下发展,其研究成果使无人机可应对复杂地形,公司发展良好且支持港科大研究。

施柏荣教授与德国法兰克福高等研究院的特里施教授团队合作开发了主动高效编码(AEC)框架。该框架结合多学科知识,解释了动物和人类在婴儿期共同发展的感知和行为机制,其受神经启发的设计可使机器人更具适应性和自主性,在医学和工业等领域有广泛应用。

香港科技大学在无人机技术方面处于全球领先。电子与计算机工程系的沈劭劼教授是推动者之一。他因港科大与行业联系紧密而回校,他致力于让无人机摆脱 GPS 控制,使其能感知环境并智能应对飞行任务中的情况,而市场上的无人机仍需人保障空中安全。
论文:
An Efficient Spatial-Temporal Trajectory Planner for Autonomous Vehicles in Unstructured Environments , IEEE Transactions on Intelligent Transportation Systems, v. 25, (2), February 2024, article number 10285583, p. 1797-1814. Han, Zhichao; Wu, Yuwei; Li, Tong; Zhang, Lu; Pei, Liuao; Xu, Long; Li, Chengyang; Ma, Changjia; Xu, Chao; Shen, Shaojie; Gao, Fei
D(2)SLAM: decentralized and distributed collaborative visual-inertial SLAM system for aerial swarm , IEEE Transactions on Robotics, v. 40, July 2024, article number 10582478, p. 1-20
Xu, Hao; Liu, Peize; Chen, Xinyi; Shen, Shaojie.FM-Fusion: Instance-Aware Semantic Mapping Boosted by Vision-Language Foundation Models , IEEE Robotics and Automation Letters, v. 9, (3), March 2024, article number 10403989, p. 2232-2239. Liu, Chuhao; Wang, Ke; Shi, Jieqi; Qiao, Zhijian; Shen, Shaojie
香港科技大学机器人研究所
主页:https://seng.hkust.edu.hk/zh-hans/node/7013
研究方向:移动机器人、无人机、智能制造、机器人感知与控制、医疗机器人等



下分实验室:
郑家纯机械人研究所 (CKSRI)
香港科技大学-Bright Dream Robotics 联合研究院
香港科技大学协同创新中心
香港科技大学-DJI 联合创新实验室
香港科技大学-生产力局工业人工智能及机械人技术联合实验室
香港科技大学-华为联合实验室
香港科技大学-小一机器学习与认知推理联合实验室
香港建筑机械人研究中心
智能自动驾驶中心 (IADC)
香港科技大学Jun MA老师实验室
主页:https://facultyprofiles.hkust-gz.edu.cn/faculty-personal-page/MA-Jun/eejma
研究方向:机器人学,自动驾驶,运动规划与控制,优化,强化学习
研究成果:

论文:
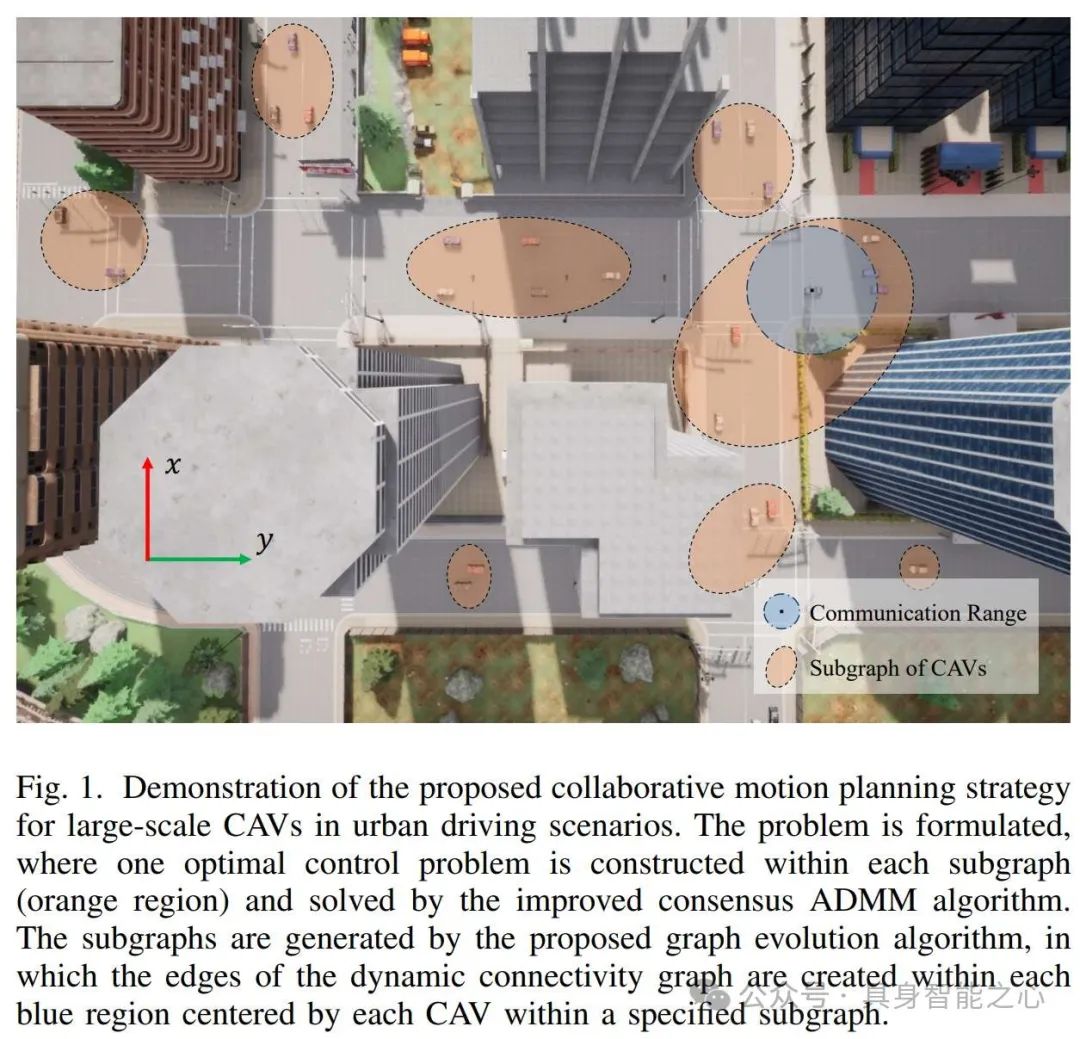
Cooperative autonomous driving in urban traffic scenarios by parallel optimization enforcing hard safety constraints, 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13-17 May 2024
Alternating Direction Method of Multipliers-Based Parallel Optimization for Multi-Agent Collision-Free Model Predictive Control , https://ieeexplore.ieee.org/document/10431550
Learning-Based High-Precision Tracking Control: Development, Synthesis, and Verification on Spiral Scanning With a Flexure-Based Nanopositioner , https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10443724
香港科技大学范明明老师实验室
主页:https://www.mingmingfan.com/
范明明,香港科技大学(广州)信息枢纽计算媒体与艺术学域与物联网学域助理教授、博士生导师、无障碍人机交互(APEX)课题组创始人。研究领域为人机交互,方向包括:1)智能无障碍与“适老化”交互技术设计;2)人智协同;3)虚拟与增强现实的交互技术与应用。
研究成果:

论文:
Toward Facilitating Search in VR With the Assistance of Vision Large Language Models , Chao Liu, Clarence Chi San Cheung, Mingqing Xu, Zhongyue Zhang, Mingyang Su, Mingming Fan*. https://www.mingmingfan.com/papers/VRST24_VR_Search_Framework.pdf
Investigating Size Congruency Between the Visual Perception of a VR Object and the Haptic Perception of Its Physical World Agent , Wenqi Zheng, Dawei Xiong, Cekai Weng, Jiajun Jiang, Junwei Li, Jinni Zhou, Mingming Fan*. https://www.mingmingfan.com/papers/VINCI24_VR_Size_Congruency.pdf
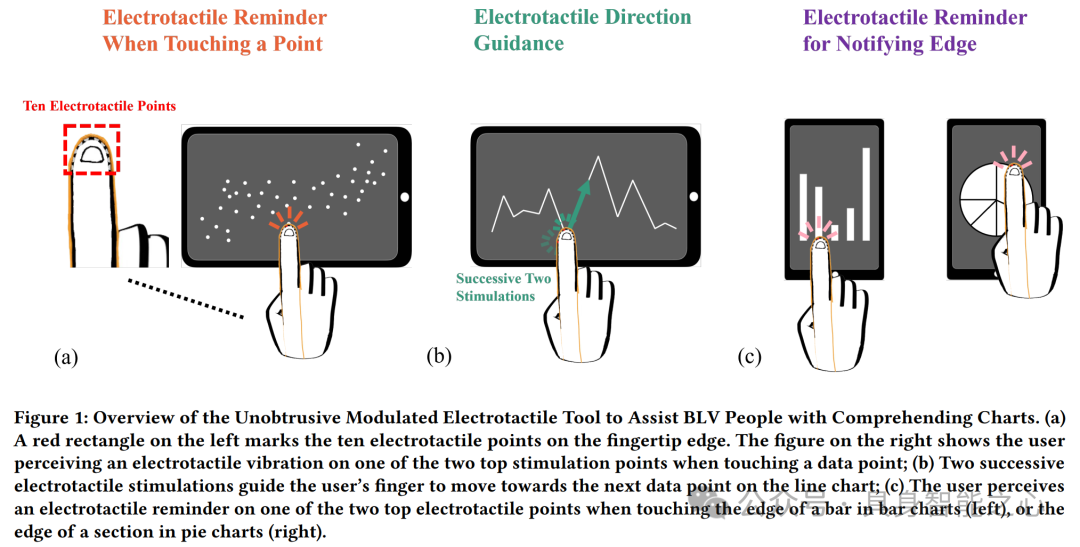
Designing Unobtrusive Modulated Electrotactile Feedback on Fingertip Edge to Assist Blind and Low Vision (BLV) People in Comprehending Charts. Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI '24), May 11--16, 2024, Honolulu, HI, USA.
香港城市大学机器人与自动化研究中心
主页:https://www.cityu.edu.hk/cra/
研究方向:医疗机器人(如手术机器人、机器人视觉、细胞手术机器人、电磁机器人系统)、人机交互(如抓取新物体的众包、社交机器人、基于云的个人机器人系统、基于视觉的传感技术、服务机器人)、微 / 纳 / 生物机器人(如机器人辅助的微 / 纳操作、光致电动力学、纳米医学、微飞行机器人)以及智能自动化(如多机器人系统、机器学习、人工智能机器人)。
研究项目:

香港理工大学机器人与机械智能实验室-The Robotics and Machine Intelligence (ROMI) Laboratory
主页:https://www.romi-lab.org
导师:Dr David Navarro-Alarcon
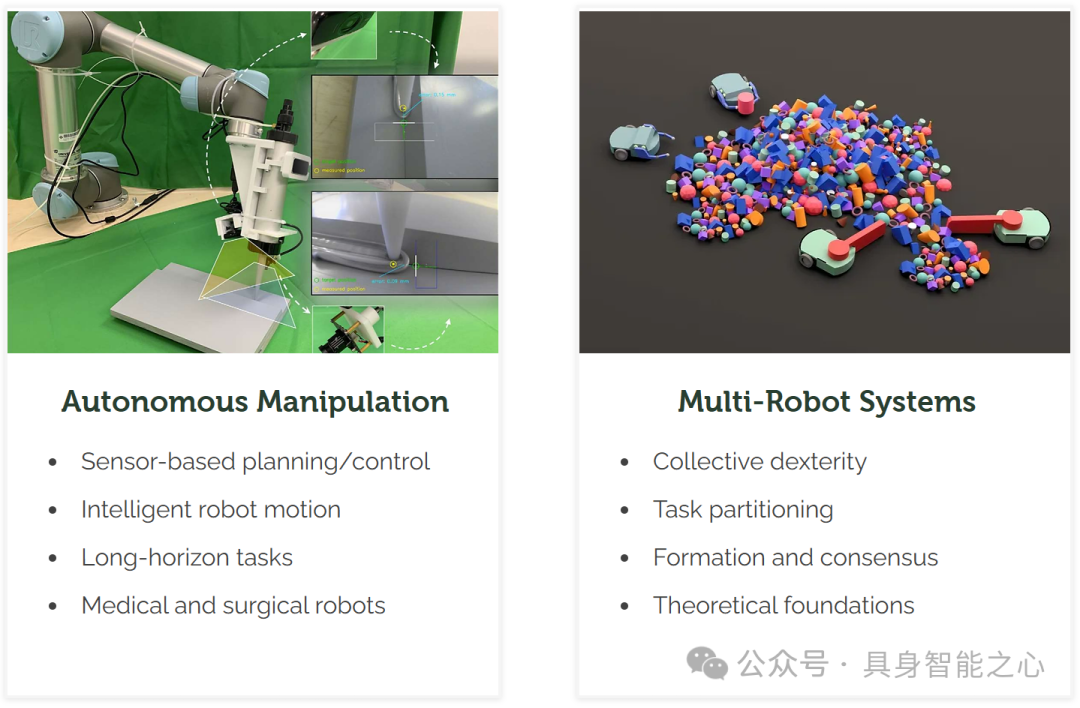
研究方向:基于传感器的规划 / 控制、智能机器人运动、长期任务、医疗和手术机器人、自主操作、集体灵巧性、任务划分、编队与共识、理论基础、多机器人系统、软物体操作、视觉形状伺服、形态模型、潜在形状表示、反馈形状控制、多模态传感器融合、人机接口、医疗机器人感知、计算传感器模型、机器人感知。

2 新加坡
NUS AI LAB
主页:https://nusail.comp.nus.edu.sg/
NUS AI Lab 隶属于新加坡国立大学,研究方向几乎涵盖 AI 的所有领域,包括建模与表示、推理与规划、机器学习与数据科学、计算机视觉和自然语言处理以及学习理论。具体涉及具身 AI(如移动机器人、自动驾驶车辆等领域)、交互式 AI(开发用于改善人机交互的方法和系统)以及可信 AI(考虑 AI 系统部署的伦理、法律和社会影响)。
研究成果:

图注:交互式人工智能:从粗到精的动物姿态和形状估计:大多数现有的动物姿态和形状估计方法使用参数化的 SMAL 模型重建动物网格。然而,SMAL 模型是从姿态和形状变化有限的玩具动物扫描中学习得到的,因此可能无法很好地表示变化很大的真实动物。为了缓解这个问题,我们提出了一种从粗到精的方法,从单张图像中重建 3D 动物网格。
图注:多模态鲁棒强化学习:此工作专注于使用多个可能不可靠的传感器学习有用且鲁棒的深度世界模型。发现当前方法不能充分鼓励模态间的共享表示,会导致下游任务表现不佳以及对特定传感器过度依赖。提出了一种新的多模态深度潜在状态空间模型,使用互信息下限进行训练,关键创新是一种专门设计的密度比估计器,鼓励每种模态的潜在代码之间的一致性。该方法在多模态 Natural MuJoCo 基准和具有挑战性的擦桌子任务中以自我监督的方式学习策略,实验表明该方法显著优于现有的深度强化学习方法,特别是在存在缺失观测的情况下。
论文:
Coarse-to-fine Animal Pose and Shape Estimation , https://arxiv.org/pdf/2111.08176
Self-supervised 3D hand pose estimation through training by fitting, https://openaccess.thecvf.com/content_CVPR_2019/papers/Wan_Self-Supervised_3D_Hand_Pose_Estimation_Through_Training_by_Fitting_CVPR_2019_paper.pdf#:~:text=Abstract.%20We%20present%20a%20self-supervision%20method%20for%203D%20hand%20pose
Towards Effective Tactile Identification of Textures using a Hybrid Touch Approach, Tasbolat Taunyazov, Hui Fang Koh, Yan Wu, Caixia Cai and Harold Soh, IEEE International Conference on Robotics and Automation (ICRA), 2019
Advanced Robotics Centre - NUS
主页:https://arc.nus.edu.sg/
Advanced Robotics Centre 是新加坡国立大学下属的一个机构,研究方向涵盖多个方面,包括:(1)智能抓取技术相关:有关于软机器人智能抓取器(Smart Grippers for Soft Robotics - SGSR)的项目研究。例如举办相关的研讨会,探讨液体堵塞抓取器(Liquid Jamming Gripper)的设计、建模和模拟等内容。(2)机器人技术的发展历程及应用场景研究:有相关研讨会阐述机器人如何从工业制造技术发展到当前的服务机器人,以及从仿生组件和仿生系统的基础研究到当前机器人伴侣和工业 5.0 的场景。
研究成果:




论文:
Model-based reinforcement learning for closed-loop dynamic control of soft robotic manipulators , TG Thuruthel, E Falotico, F Renda, C Laschi. IEEE Transactions on Robotics 35 (1), 124-134.
Synteraction Lab
主页:https://synteraction.org/
导师:Shengdong Zhao
交互实验室由Shengdong Zhao博士于 2009 年成立,现已发展成为亚洲及世界上最活跃的人机交互研究中心之一。它在开发新的界面工具和应用方面有经验,并定期在顶级人机交互会议和期刊上发表文章。该实验室的愿景是抬头计算,旨在通过可穿戴平台和多模式交互方法改变我们与技术交互的方式。
研究成果:
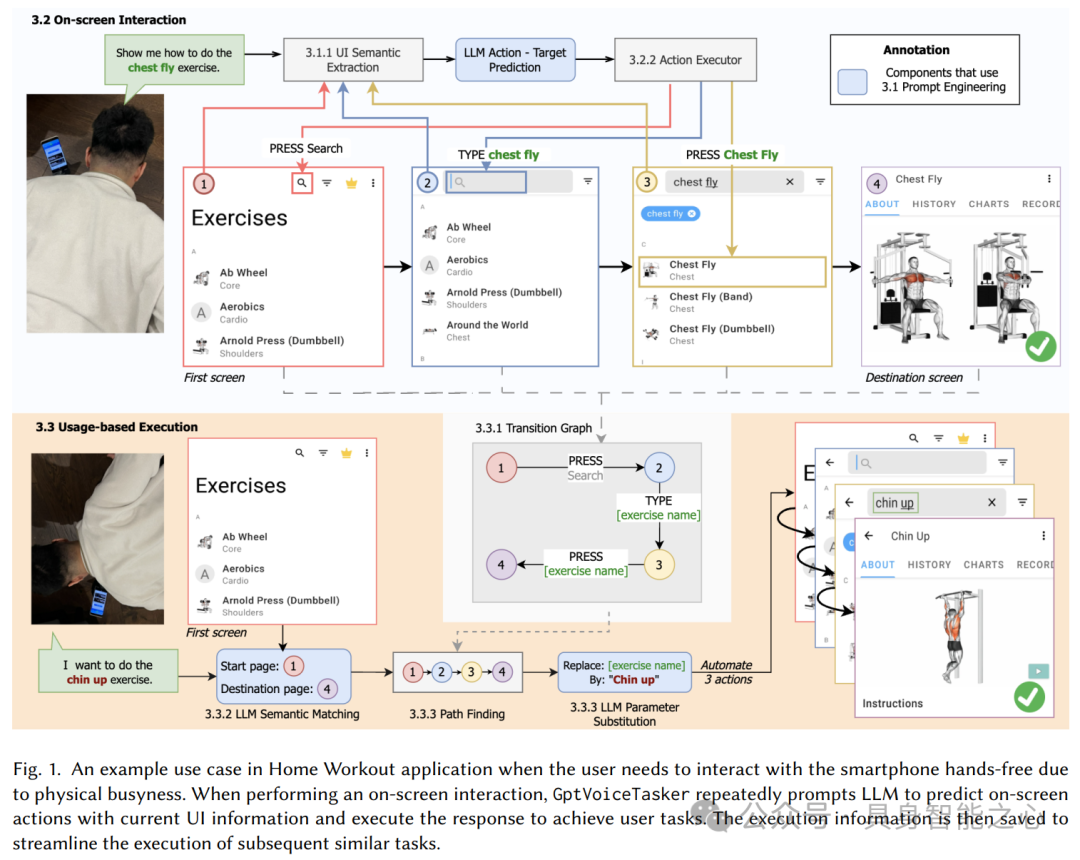
论文:
What's this? Understanding User Interaction Behaviour with Multimodal Input Information Retrieval System. Silang Wang, Hyeongcheol Kim, Nuwan Janaka, Kun Yue, Hoang-Long Nguyen, Shengdong Zhao, Haiming Liu, Khanh-Duy Le. Keywords: Information Retrieval, Multimodal Interaction, User Search Behaviour, Heads-up Computing
Navigating Real-World Challenges: A Quadruped Robot Guiding System for Visually Impaired People in Diverse Environments. Shaojun Cai, Ashwin Ram, Zhengtai Gou, Mohd Alqama Wasim Shaikh, Yu-An Chen, Yingjia Wan, Kotaro Hara, Shengdong Zhao, David Hsu. Keywords: visual impairment, orientation and mobility, assistive technology, navigation, robot guide dog
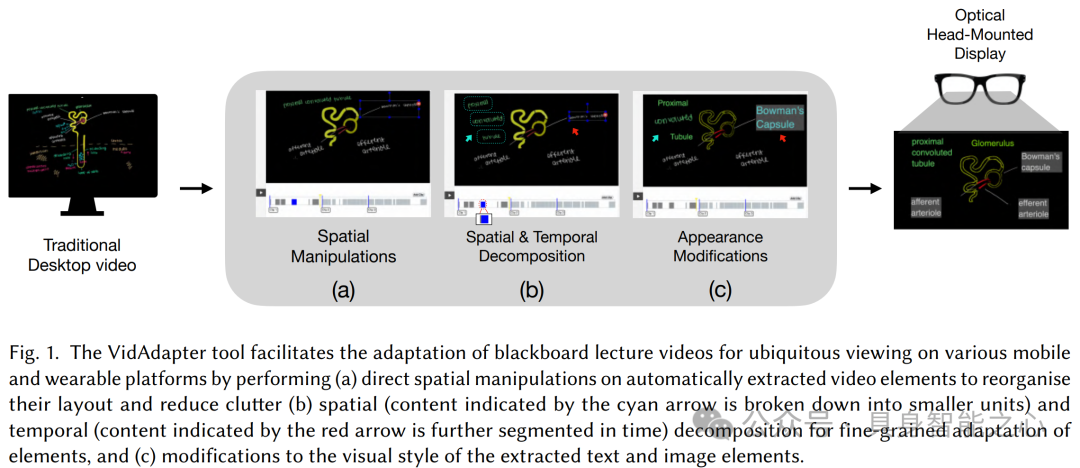
Heads-Up Multitasker: Simulating Attention Switching On Optical Head-Mounted Displays. Yunpeng Bai, Aleksi Ikkala, Antti Oulasvirta, Shengdong Zhao, Lucia J. Wang, Pengzhi Yang, Peisen Xu. Keywords: multitasking, heads-up computing, computational rationality, deep reinforcement learning, bounded optimal control
Microsystem Engineering and Robotics
主页:https://guppy.mpe.nus.edu.sg/peter_chen/
导师:**Peter C. Y. Chen**
Peter C.Y.Chen的实验室,从事微系统和机器人技术的研究与开发。研究重点是对从微观到宏观尺度的物理和生物系统进行机械操作,以产生实用的工程解决方案。他们积极寻求合作,并欢迎对微系统工程和机器人技术感兴趣的学生。
研究成果:

论文:
Du, Herath, Wang, Wang, Asada, and Chen, Three-dimensional characterization of mechanical interactions between endothelial cells and extracellular matrix during angiogenic sprouting. Scientific Reports, 2016.
Herath, Du, Shi, Kim, Wang, Wang, Van Vliet, Asada, and Chen, Quantification of magnetically induced changes in ECM local apparent stiffness. Biophysical Journal, 2014.
Zhou, Chen, and Ong, Force control of a cellular tensegrity structure with model uncertainties and partial state measurability. Asian Journal of Control, 2014.
Herath, Du, Wang, Wang, Liao, Asada, and Chen, Characterization of uniaxial stiffness of extracellular matrix embedded with magnetic beads via bio-conjugation and under the influence of an external magnetic field. Journal of the Mechanical Behavior of Biomedical Materials, 2014.
Multimodal AI and Robotic Systems (MARS) Lab
主页:https://marsyang.site/
导师:Dr. Jianfei Yang
南洋理工大学的多模态人工智能与机器人系统(MARS)实验室研究物理人工智能,重点关注人工智能如何使机器人、物联网和工业系统等物理系统感知、理解并与物理世界交互,涉及多模态感知、具身人工智能、AIoT 系统等多个方面。
研究成果:
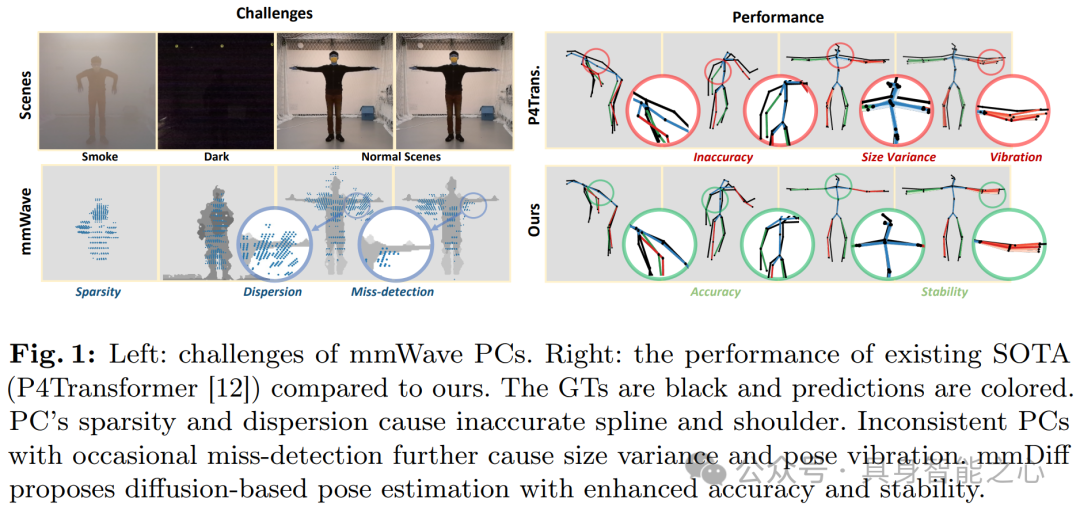
图 1 主要展示了毫米波雷达点云(mmWave PCs)在人体姿态估计(HPE)中的相关情况。左侧毫米波雷达点云稀疏且分散,导致生成的样条和肩部不准确。右侧对比了现有 SOTA 方法(P4Transformer)和本文提出方法(mmDiff)的性能:现有 SOTA 方法的预测结果存在姿态振动和严重漂移,性能不理想。本文提出的 mmDiff 方法基于扩散模型进行姿态估计,具有更高的准确性和稳定性,图中以黑色表示真实值(GTs),彩色表示预测值。
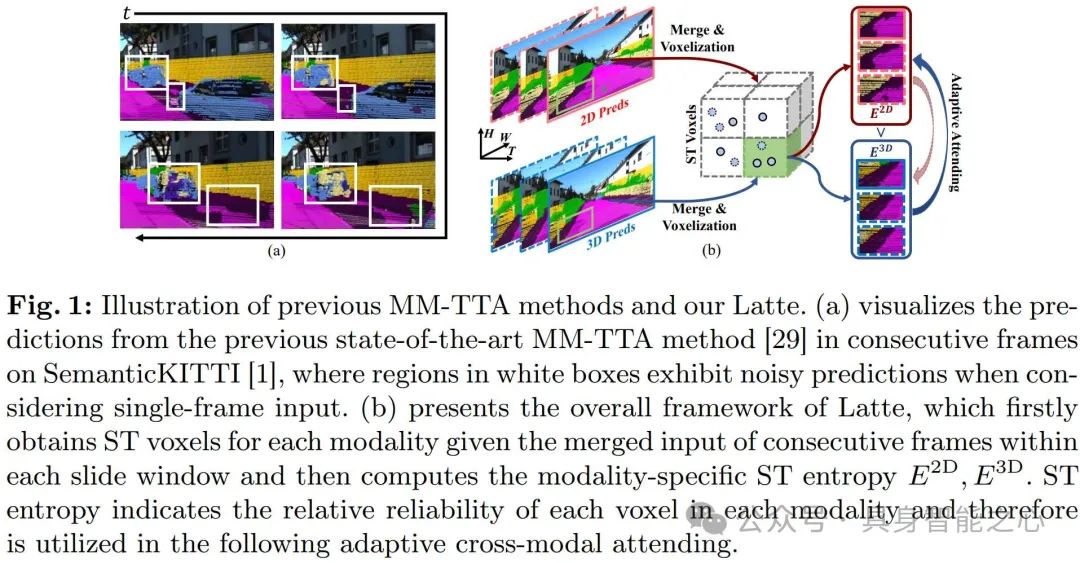
多模态测试时间适应(MM - TTA)旨在通过利用多模态输入来使模型适应无标签目标域。现有方法在进行 3D 分割的 MM - TTA 时,依赖于每个输入帧中跨模态信息的预测,忽略了连续帧内几何邻域的预测是高度相关的这一事实,导致跨时间的预测不稳定。本文提出了 Latte 方法来解决这些问题:首先,给定连续帧的合并输入(例如点云帧和其估计的姿态),通过一种滑动窗口的方式聚合连续帧,并将同一体素内的点视为时空对应关系。然后构建空间 - 时间(ST)体素,通过这种方式来捕获每个模态在时间上局部的预测一致性。
论文:
Diffusion Model is a Good Pose Estimator from 3D RF-Vision, https://arxiv.org/pdf/2403.16198
Reliable Spatial-Temporal Voxels For Multi-Modal Test-Time Adaptation , https://arxiv.org/abs/2403.06461
MoPA: Multi-Modal Prior Aided Domain Adaptation for 3D Semantic Segmentation , https://arxiv.org/pdf/2309.11839
Perception and Embodied Intelligence (PINE) Lab
主页:https://pine-lab-ntu.github.io/team.html
导师:Ziwei Wang
Pine Lab位于南洋理工大学。其主要研究方向包括:1. 具身指令跟随,旨在使智能系统在未知环境中理解并执行人类指令,通过多模态感官融合等方法,其系统能在大型房屋级场景完成204项复杂人类指令;2. 通用机器人操作的生成式模型,目标是为日常机器人操作任务构建生成式基础模型,借鉴相关经验,其机器人可完成多种操作任务且泛化能力高;3. 通用机器人包装系统,为解决包装系统面临的挑战,开发了相关框架和管道,其系统能包装12类日常物品,成功率86.7%;4. 基础模型压缩,解决在机器人上部署大型基础模型受计算资源限制的问题,提出相关技术、框架和引擎,可在特定硬件中部署用于多种任务;5. 实时在线3D场景感知,建立通用框架实现实时高效场景感知,将离线模型转换为在线模型,构建的相关模型能处理视频并输出实时3D重建和分割结果,在一些数据集上性能领先。
研究成果:
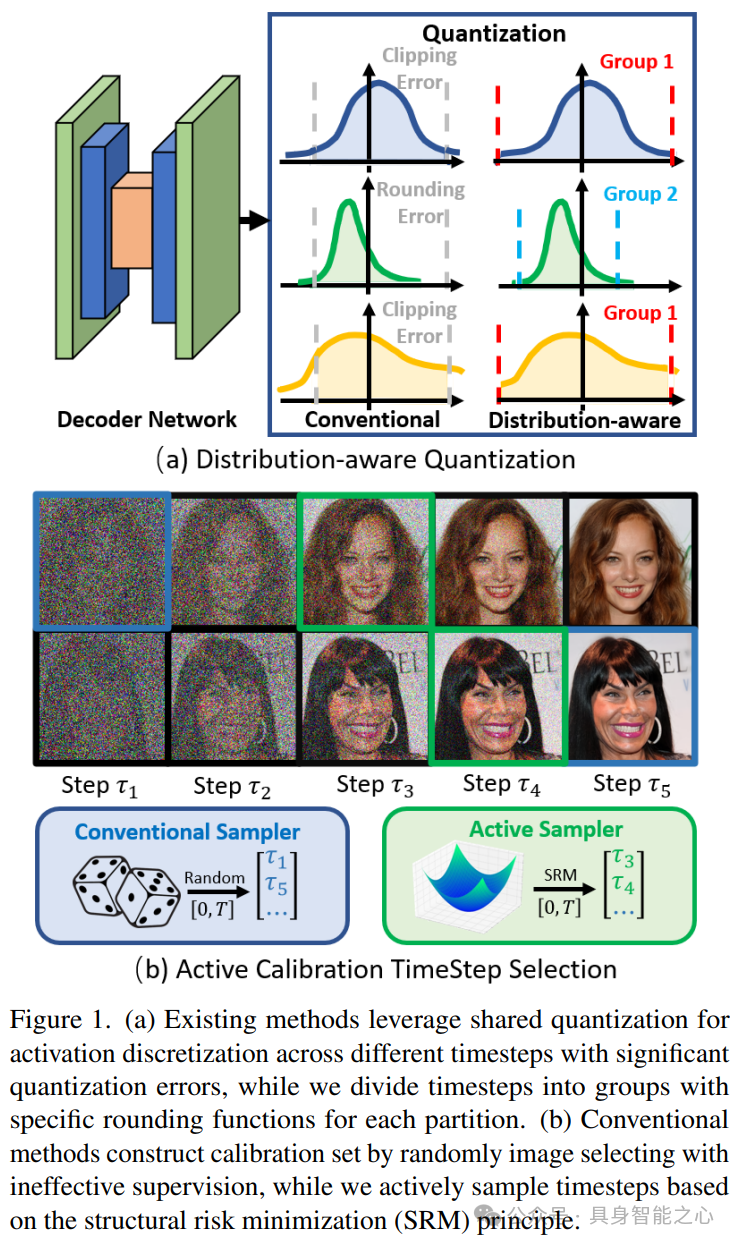
文章提出了一种用于扩散模型的准确的训练后量化框架(APQ - DM)以实现高效的图像生成。

文章提出一种用于在线 3D 场景感知的新框架,通过基于记忆的适配器赋予现有离线模型在线感知能力。图1展示了所提出的在线 3D 场景感知的通用框架,体现了该框架在不同 3D 场景感知任务(如语义分割、目标检测和实例分割)中的应用价值,这些任务对于机器人应用很重要。
论文:
3D Small Object Detection with Dynamic Spatial Pruning , Xiuwei Xu*, Zhihao Sun*, Ziwei Wang, Hongmin Liu, Jie Zhou, Jiwen Lu , European Conference on Computer Vision (ECCV), 2024.
ManiGaussian: Dynamic Gaussian Splatting for Multi-task Robotic Manipulation , Guanxing Lu, Shiyi Zhang, Ziwei Wang, Changliu Liu, Jiwen Lu, Yansong Tang , European Conference on Computer Vision (ECCV), 2024.
StableLego: Stability Analysis of Block Stacking Assembly , Liu, Kangle Deng, Ziwei Wang, Changliu Liu , IEEE Robotics and Automation Letters (RAL), 2024.
S-Lab for Advanced Intelligence
主页:https://www.ntu.edu.sg/s-lab
S-Lab for Advanced Intelligence 是南洋理工大学 2020 年成立的实验室。其研究方向包括计算机视觉、自然语言处理、强化学习、深度学习和分布式计算等前沿 AI 技术。具体涉及深度学习中的内容编辑和生成、分布式学习、超分辨率、图像和视频理解、媒体取证、自然语言处理以及 3D 场景理解等。
研究成果:
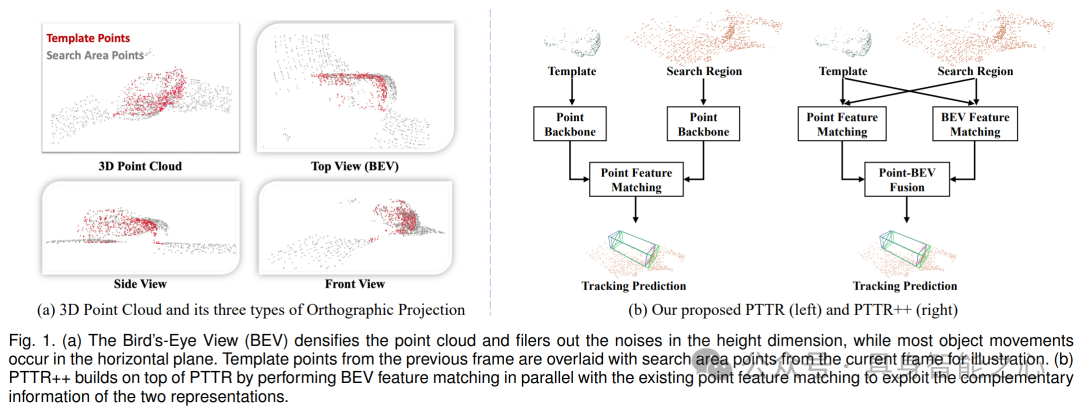
本文提出了用于 3D 点云目标跟踪的方法,包括 PTTR 和 PTTR++。图 1(a)展示了 3D 点云的鸟瞰图(BEV)的优势,以及模板点和搜索区域点的关系。图 1(b)呈现了 PTTR 和 PTTR++ 的结构,PTTR++ 在 PTTR 基础上增加了 BEV 特征匹配,以利用两种表示的互补信息提高跟踪性能。
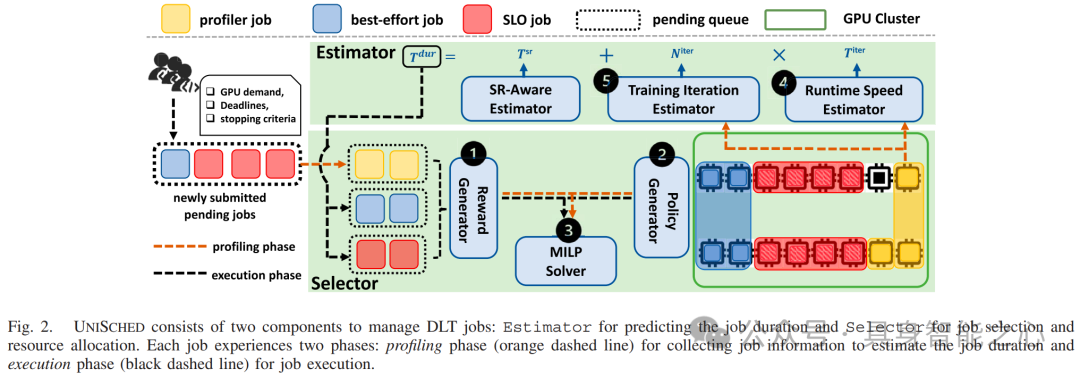
图 2 展示了 UniSched 的工作流程,它由 Estimator 和 Selector 两个组件构成。Estimator 用于预测作业时长,Selector 用于作业选择和资源分配,每个作业都经历 profiling 和 execution 两个阶段。
论文:
Unified 3D and 4D Panoptic Segmentation via Dynamic Shifting Network
F. Hong, L. Kong, H. Zhou, X. Zhu, H. Li, Z. Liu
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI)Flare7K++: Mixing Synthetic and Real Datasets for Nighttime Flare Removal and Beyond
Y. Dai, C. Li, S. Zhou, R. Feng, Y. Luo, C. C. Loy
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI)TOPIQ: A Top-down Approach from Semantics to Distortions for Image Quality Assessment
C. Chen, J. Mo, J. Hou, H. Wu, L. Liao, W. Sun, Q. Yan, W. Lin
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI)
MMLab@NTU
主页:https://www.mmlab-ntu.com/
MMLab@NTU 主要研究方向包括低级别视觉、图像和视频理解、创意内容创作、3D 场景理解与重建等。涉及超分辨率、内容编辑与创作、图像和视频理解、3D 生成式 AI、深度学习、媒体取证等多个领域。
研究成果:
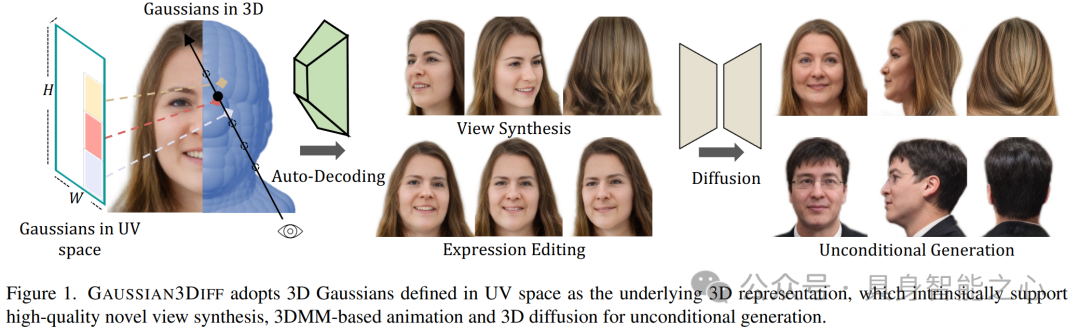
图1展示了GAUSSIAN3DIFF的核心特点,它采用3D Gaussians(定义在UV空间)作为3D表示基础,这种表示支持高质量的新视角合成、基于3DMM的动画以及用于无条件生成的3D扩散。

图 1 展示了 StyleGANEX 在多种人脸操作任务上的应用,包括风格转换、面部属性编辑、超分辨率、从草图或遮罩生成人脸以及视频人脸卡通化等,体现了其突破 StyleGAN 对裁剪对齐人脸限制的能力。
论文:
Efficient Diffusion Model for Image Restoration by Residual Shifting
Z. Yue, J. Wang, C. C. Loy
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI)Talk-to-Edit: Fine-Grained 2D and 3D Facial Editing via Dialog
Y. Jiang, Z. Huang, T. Wu, X. Pan, C. C. Loy, Z. Liu
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI)4D Panoptic Scene Graph Generation
J. Yang, J. Cen, W. Peng, S. Liu, F. Hong, X. Li, K. Zhou, Q. Chen, Z. Liu
in Proceedings of Neural Information Processing Systems, 2023 (NeurIPS, Spotlight)L4GM: Large 4D Gaussian Reconstruction Model
J. Ren, K. Xie, A. Mirzaei, H. Liang, X. Zeng, K. Kreis, Z. Liu, A. Torralba, S. Fidler, S. W. Kim, H. Ling
in Proceedings of Neural Information Processing Systems, 2024 (NeurIPS)
MReaL
主页:https://mreallab.github.io/index.html
MReaL Lab 致力于研究结合现代深度神经网络和传统符号操作的推理算法,研究方向包括多模态编辑、零样本模型优化、3D 内容生成、场景图生成等多个领域。
研究成果:
论文:
Towards Unified Multimodal Editing with Enhanced Knowledge Collaboration
Enhancing Zero-Shot Vision Models by Label-Free Prompt Distribution Learning and Bias Correcting
Robust Fine-tuning of Zero-shot Models via Variance Reduction
Unified Generative and Discriminative Training for Multi-modal Large Language Models
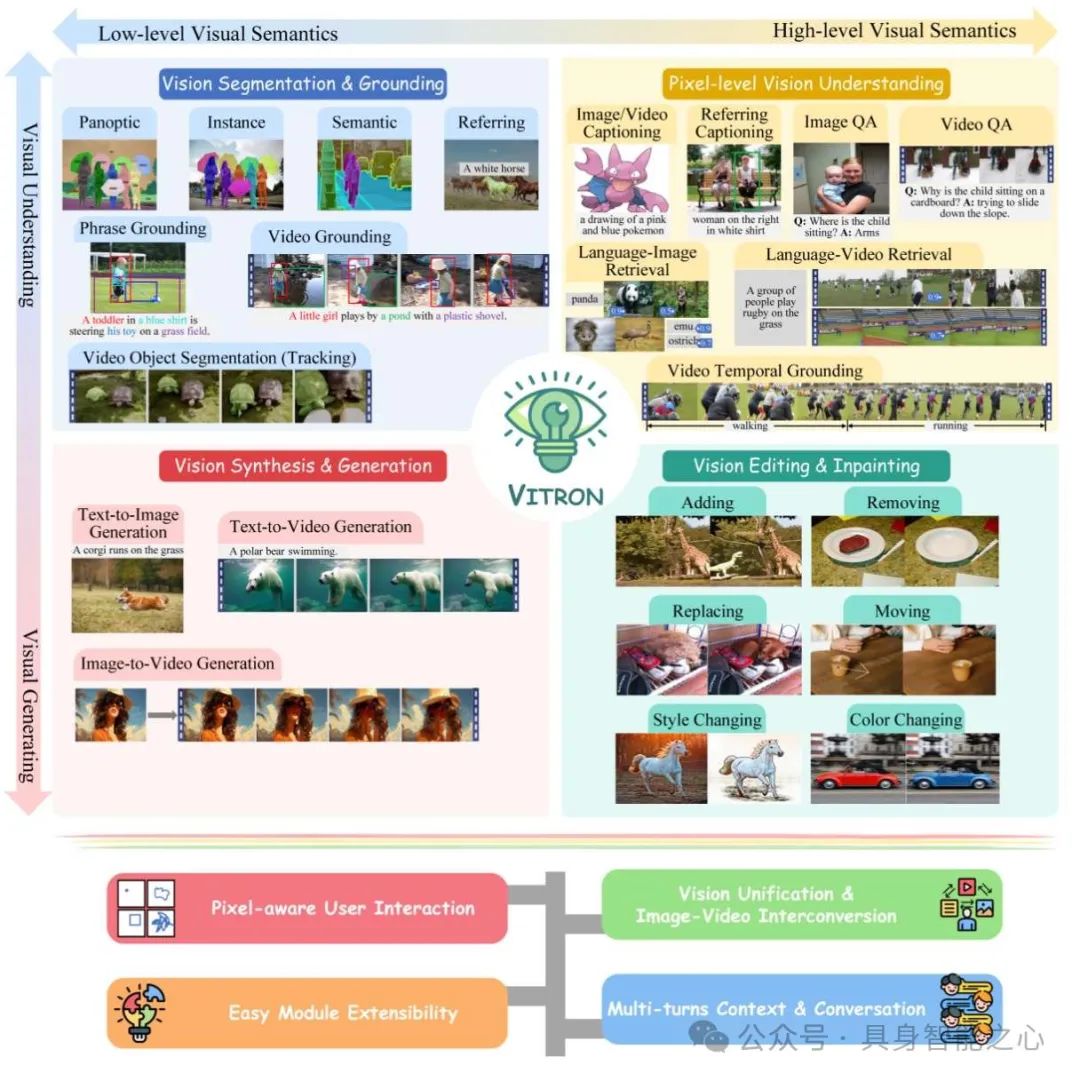
Vitron: A Unified Pixel-level Vision LLM for Understanding, Generating, Segmenting, Editing
MVGamba: Unify 3D Content Generation as State Space Sequence Modeling
Rapid-Rich Object Search Lab (ROSE)
主页:https://www.ntu.edu.sg/rose
该实验室的研究方向包括:利用深度学习等技术进行对象识别与检索,开发适用于移动设备的紧凑且创新的特征编码、可扩展索引和视觉搜索算法;利用传统及机器学习方法进行视频分析;以及针对图像和视频取证应用的生物识别技术,包括生物特征及软生物特征、人脸伪造与活体检测、反射去除等。
研究成果:

论文:
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Xun Lin, Shuai Wang, Rizhao Cai, Yizhong Liu, Ying Fu, Zitong Yu, Wenzhong Tang, Alex Kot, The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024)Flexible-Modal Deception Detection with Audio-Visual Adapter
Zhaoxu Li, Zitong Yu, Xun Lin, Nithish Muthuchamy Selvaraj, Xiaobao Guo, Bingquan Shen, Adams Wai-Kin Kong, Alex Kot, 2024 IEEE International Joint Conference on Biometrics (IJCB)Semantic Deep Hiding for Robust Unlearnable Examples
Ruohan Meng, Chenyu Yi, Yi Yu, Siyuan Yang, Bingquan Shen, Alex C Kot, IEEE Transactions on Information Forensics and Security (TIFS)
“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
(1)具身多模态基础模型
NVIDIA最新!NVLM:开放级别的多模态大语言模型(视觉语言任务SOTA)
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
CLIP怎么“魔改”?盘点CLIP系列模型泛化能力提升方面的研究
揭秘CNN与Transformer决策机制:设计原则是关键?
VILA:视觉推理能力如何up up?多模态预训练设计有妙招
(2)3D场景理解、分割与交互
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
大模型继续发力!SAM2Point联合SAM2,首次实现任意3D场景,任意Prompt的分割
更丝滑更逼真!模型自主发现与模式自动识别新升级助力三维场景构建与形状合成
进一步向开放识别迈进!3D场景理解与视觉语言模型的融合创新可以这样玩
(3)具身机器人与环境交互
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
(4)具身仿真×自动驾驶
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集
ECCV 2024 Oral | DVLO:具有双向结构对齐功能的融合网络,助力视觉/激光雷达里程计新突破
(5)权威赛事结果速递
模型与场景的交互性再升级!感知、行为预测以及运动规划在Waymo2024挑战赛中有哪些亮点
效率和精度齐飞!CVPR2024 AIS workshop亮点大盘点
(6)具身智能工具深度测评
巨好用的工具安利!胜过WPS?MinerU 帮你扫清PDF提取
UCLA出品!用于城市空间的具身人工智能模拟平台:MetaUrban
(7)具身智能时事速递
端到端、多模态、LLM如何与具身智能融合?看完这50家公司就明白了
见证历史?高通准备收购英特尔!
万张A100“堆”出来的勇气:一个更极致的中国技术理想主义故事
即将截止!ECCV'24自动驾驶难例场景多模态理解与视频生成挑战赛


















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









