



作者 | oldpan 编辑 | 自动驾驶之心
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
本文来自The State of vLLM | Ray Summit 2024 && RoadMap的分享,带大家一起回顾下vllm发展历史、过去一年的发展及接下来Q4规划。感兴趣的也可以查看原视频:https://www.youtube.com/watch?v=4HPRf9nDZ6Q[1]
过去一年vLLM的工作内容
记得vLLM在九月初更新了一个版本[2],性能有了明显的提升(支持了multi step,因为减少了CPU overhead,会对吞吐会有提升,但是带来的副作用是TTFT和ITL会变大),某些场景确实带来了收益。
vLLM在2024年更新了很多内容~首先是模型支持,支持几乎所有的llm和vlm模型且效率非常高,这点确实要比TRT-LLM支持更快更方便,涉及到底层改动支持的模型,TRT-LLM因为底层限制只能提个issue等官方支持。而vLLM就很方便,目前vLLM支持的模型有:
包括LLama系列模型/Mixtral系列模型/LLava多模态/State-Space模型/reward模型等

除了GPU也支持很多其他的硬件,如amd GPU/Intel GPU/Google TPU等,当然还有CPU!

当然核心还是依赖的Pytorch,PyTorch 作为核心,为不同的上层模型和底层实现提供了一个统一的接口。
PyTorch as a Narrow Waist,“narrow waist”概念来源于计算机网络结构,通常指的是一个核心层,它连接了上层和下层的各种模块
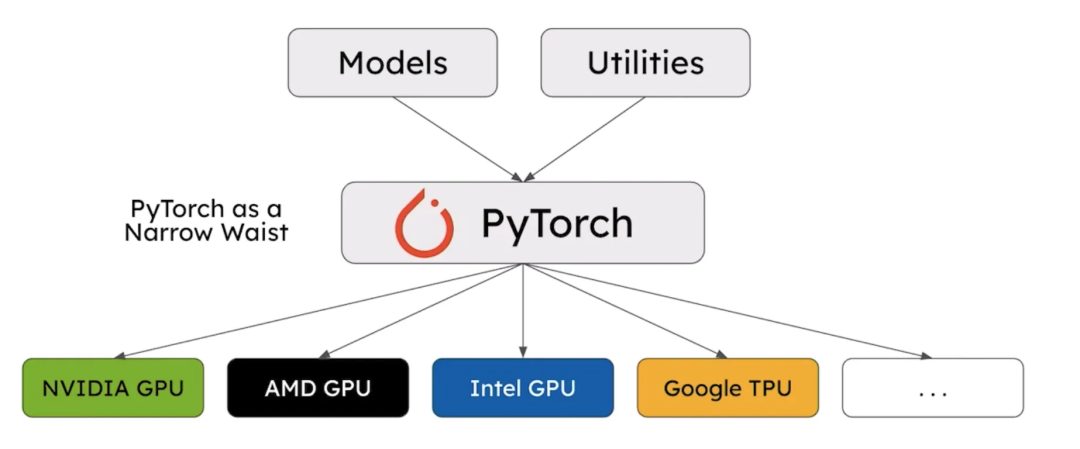
同样对vLLM社区来说,性能优化是第一个目标。
矩阵乘法有专门深层次的cuda kernel[3]优化。此外特定层(如 ffn 层)专门优化了 Triton 内核以提升性能,利用cutlass库优化GEMM,实现kernel fusion等功能,提供专门的flashatention kernel等。
为了优化通信性能,vLLM还开发了一个定制的 all-reduce CUDA 内核(尤其是 all-reduce 操作,计算时异步数据传输/优化内存访问、增加并行度等优化allreduce通信)。还有transformer的核心注意力机制,现在已经采用了许多基于 CUDA 的内核和其他注意力内核,包括 Flash Attention 和 FlashInfer。
还有量化支持变得愈发重要,首先开发一个通用的量化方法抽象层,然后实现这些量化方法,最后优化这些量化操作的性能;目前vLLM支持了几乎所有流行的量化方法,包括 FP8、IN8、GPTQ、AWQ 量化方法。此外,vLLM中还引入了许多高效的量化内核,例如 Marlin[4]。
vLLM还有个 LLM Compressor[5],帮助量化模型的库,支持多种量化方法,高效地将模型量化成vLLM能理解的格式,从而获得更佳性能。这个可以理解为TRT-LLM的ModelOPT。

性能优化
vLLM除了LLM基本的kernel优化、并行优化、量化策略,还有很多其他优化。
CUDA Graph
Cuda Graph对vLLM的性能提升很大,毕竟vLLM是采用pytorch原生的op配合拓展op搭建的,有很多额外的消耗:user-written logic, PyTorch dispatcher logic, memory allocation overhead, and GPU driver/kernel overhead。使用了cuda graph可以避免掉这些开销。
We find that without CUDA graphs, LLaMA-7B inference executes at 30 tokens/sec, but with CUDA graphs enabled it executes at 69 tokens/sec for a 2.3x speedup.
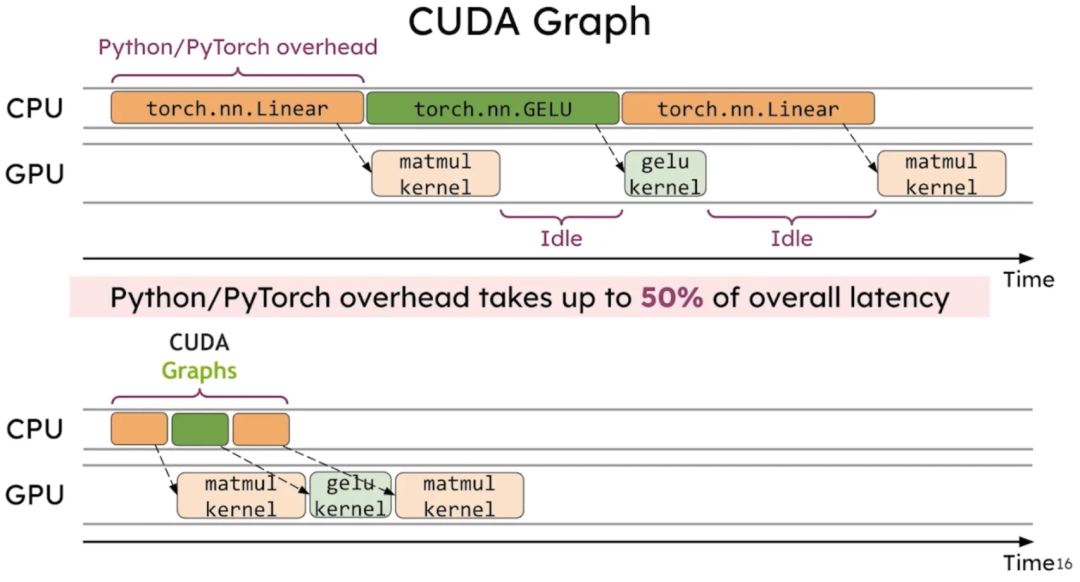
唯一可能的缺点就是因为要适配dynamic shape,占用的显存相比之前大些,同时启动时间也因为要捕获graph慢了些。
Multi-step Scheduling
Multi-step Scheduling提出的原因很简单,之前vllm被诟病python/cpu overhead一直很大,也就是每次decoder时候,CPU与GPU的同步操作导致了较高的性能开销(你可以亲自打下vLLM运行时候的timeline,中间间隙比TRT-LLM要大些)。
具体就是GPU在每次从CPU接收下一步的输入,以及从GPU传输采样后的token,到CPU生成用户响应时,都会产生一定的“GPU bubble”(GPU等待CPU处理的时间,5-13ms of GPU bubble),具体是这四个:
Transfer of the sampled token from GPU to CPU for de-tokenization and response to client
Generation of output for user - Pythonization of tensors into python objects
CPU preparation and generation of next step’s input metadata
vLLM scheduler
多步解码指的是在调用 vLLM 调度器并处理采样的 tokens 之前,执行多次解码。
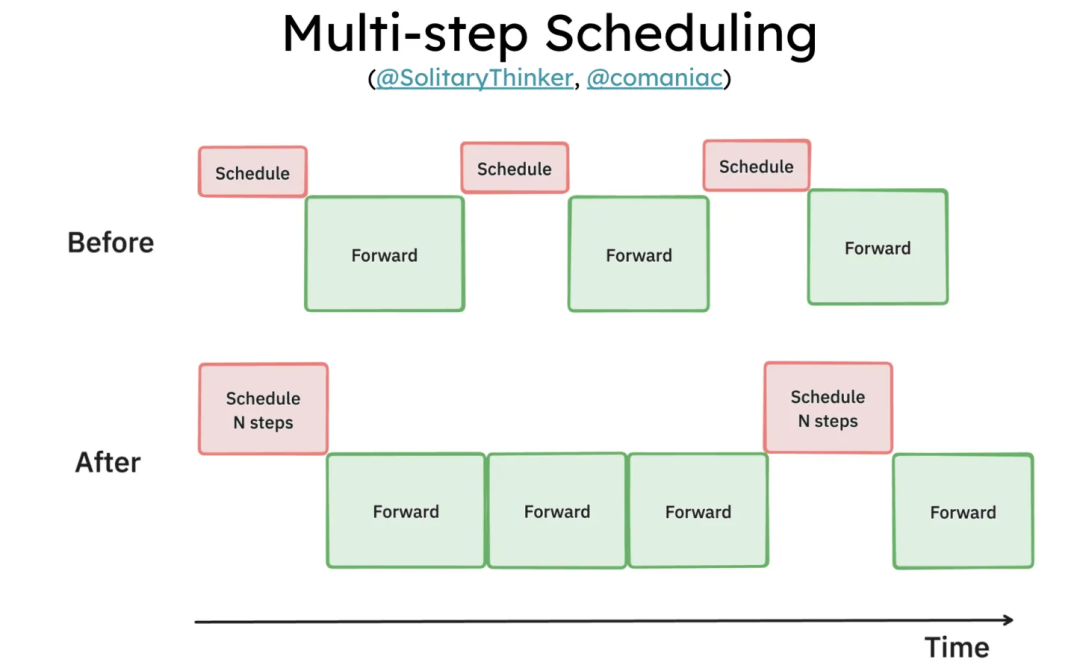
之前每次解码步骤中 GPU->CPU 的内存传输都是同步进行的,导致 GPU 出现空闲时间。多步解码后,这种内存传输可以在一个独立的 CUDA 流中进行,而此时 CPU 已经领先于 GPU,因此几乎没有额外开销。
Multi-step decoding will be able to amortize all these overheads over n-steps at a time.
下方两个图是官方提供的对比图,这两个时长大约为 200ms。第一行是 CUDA 核心操作,底部是 Python 跟踪。每个红框大约代表 4ms 的 GPU 空闲时间,两张图均如此。
首先是baseline,每个decode步骤都会导致4毫秒的GPU空泡(这里使用Pytorch profiler打印):
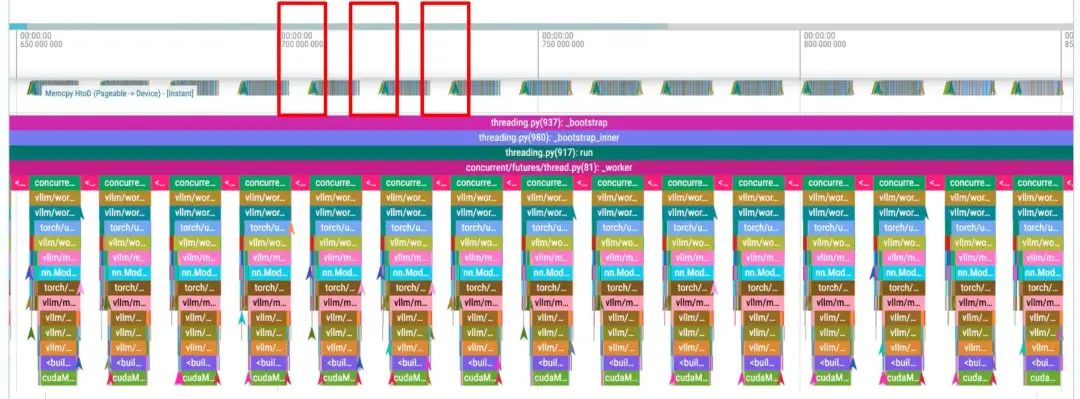
使用Multi-Step-8之后,4毫秒的开销仅在每8次解码中出现一次:
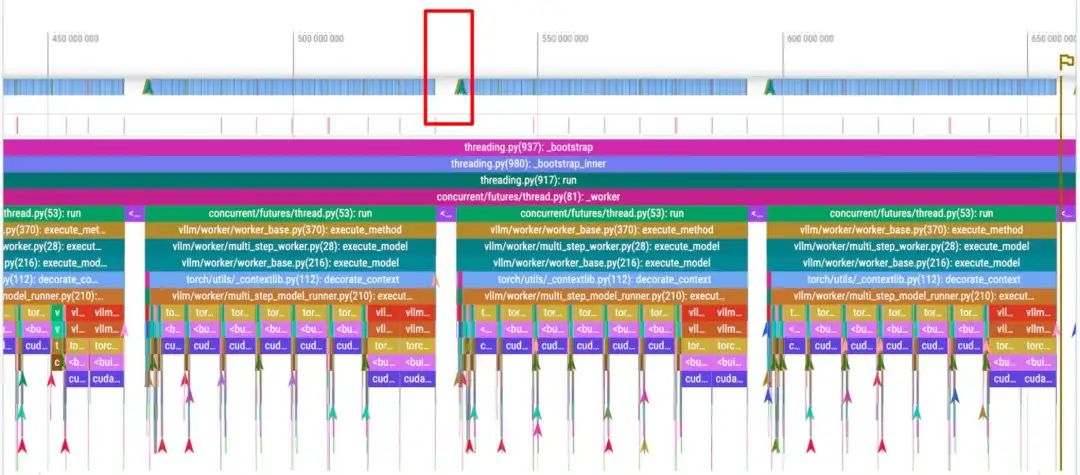
通过使用Multi-Step,基于H100的8B Llama模型的请求吞吐量从20.66请求/秒提升至40.06请求/秒,性能显著提升。
具体提升指标:
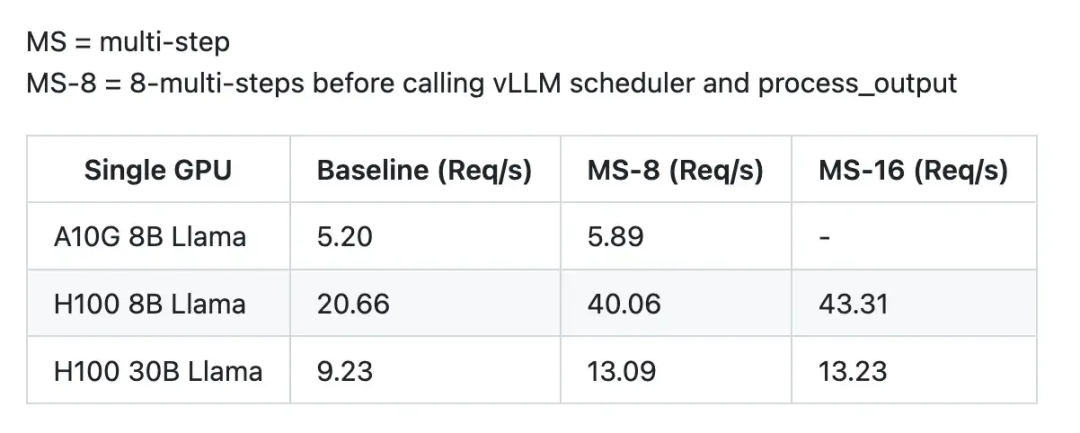
不过需要注意这个只针对decoder阶段,prefill阶段还和之前一样
更多的细节可以看这两个链接:
https://github.com/vllm-project/vllm/issues/6854[6]
https://github.com/vllm-project/vllm/pull/7000[7]
Chunked prefill
Chunked prefill 技术也属于LLM标配了,可以简单聊一聊。
这个功能的作用在于,可以将非常长的输入prompt拆分成更小的块进行处理,以避免长prompt阻塞其他请求,从而减少延迟并提高整体的吞吐。相比不用的情况,用户的性能延迟有了 2 倍的提升,吞吐量更高,延迟更低。
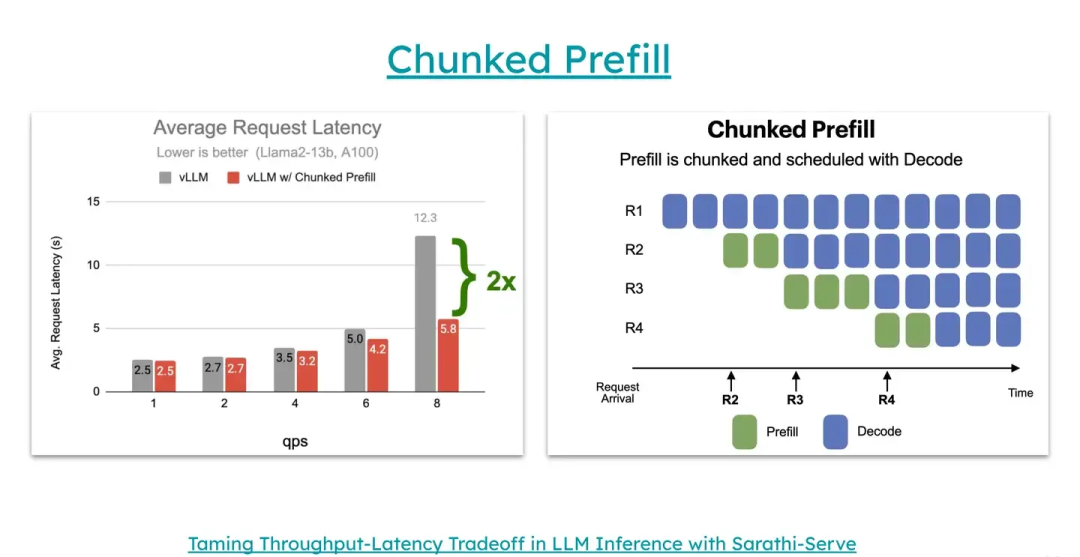
前面提到,vLLM 将请求的处理分为prefill阶段和decode阶段,同一批被调度的请求要么都处于prefill阶段,要么都处于decode阶段。而 Chunked prefill 将填充请求的 prompt[8] 分成多个块,并与解码请求一起处理。Prefill是计算密集型(compute-bound),而decode则是内存密集型(memory-bound),通过重叠这两种请求可以大大提高系统效率,正如上图(右上角 prefill 进行数学上等价的切分;在 prefill 切成的这些 chunks 的气泡处捎带其他 request 的 decode pass,可以看到R2的Prefill和R1的Decode在一起计算)。
不过也需要注意,做了 chunked prefill 后,prefill 的开销会略微增大。因为计算后续 chunk 的 KV 时需要不断地从 GPU memory 中里读出当前 chunk 的 KV 到 kernel 里面;而不做 chunked prefill 时,最开端的那些 KV Cache 可以不用反复从 GPU memory 中反复读取进入 kernel,毕竟他们一直在 kernel 里面。
关于 Chunked prefill 细节可以阅读:
DeepSpeed-FastGen[9]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills[10]
官方RFC:
[RFC] Upstream Chunked Prefill · Issue #3130 · vllm-project/vllm[11]
Speculative Decoding
Speculative Decoding也就是俗称的投机推理或者叫预测推理。
vLLM 这里讲了两个,分别是speculative decoding (draft-verification) && dynamic speculative deccoding(根据系统负载和推测精度动态调整长度)
Speculative Decoding,其目标是利用小模型来预测大型模型的行为,从而加速大型模型的执行。例如,我们可以让小模型生成候选序列,然后将此候选序列提供给大模型,允许大模型并行处理以验证这些候选序列的正确性。如果验证通过,我们可以一次性生成多个token,大大提升生成速度:

再详细些,看下面的例子。下面是一个关于随机采样工作方式的示例。图中每一行表示算法的一次迭代。绿色标记表示近似模型生成的token建议,目标模型则负责判断是否接受这些建议。红色和蓝色标记分别表示被目标模型拒绝的token及其修正。
例如,在第一行中,近似模型生成了5个token,生成的句子是“[START] japan’s benchmark bond”。目标模型将这些token与前缀拼接成一句话进行验证。在这次推理中,目标模型接受了前四个token(“japan”,“’s”,“benchmark”),但拒绝了最后一个token “bond”,并重新采样生成“n”。
通过这种方式,虽然每次都对近似模型的输出进行一次性验证,但目标模型在仅9次推理后就生成了37个token。尽管目标模型的总体计算量没有变化,但一次性验证多个token的延迟与逐个生成token相似(并行总是比一个一个吐字快),从而显著提高了生成速度。

不过还有另一种情况,当系统负载很高时,vLLM已经可以很好地处理批量请求,因此在这种情况下使用预测解码可能并不会提升性能。然而,在系统负载较低时,利用预测解码可以减少延迟。因此,Dynamic Speculative Decoding的核心是如何动态调整预测解码量,以在系统负载不同的情况下获得最佳性能。

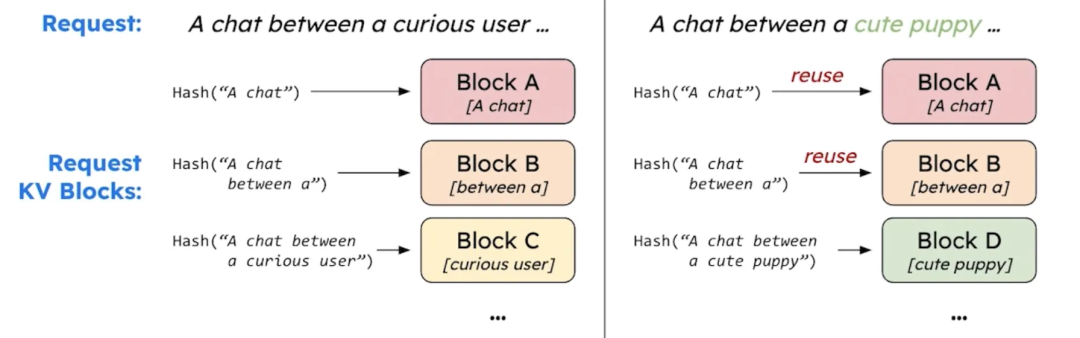
Hash-Based Automatic Prefix Caching
vLLM还实现了基于哈希的自动prefix caching。
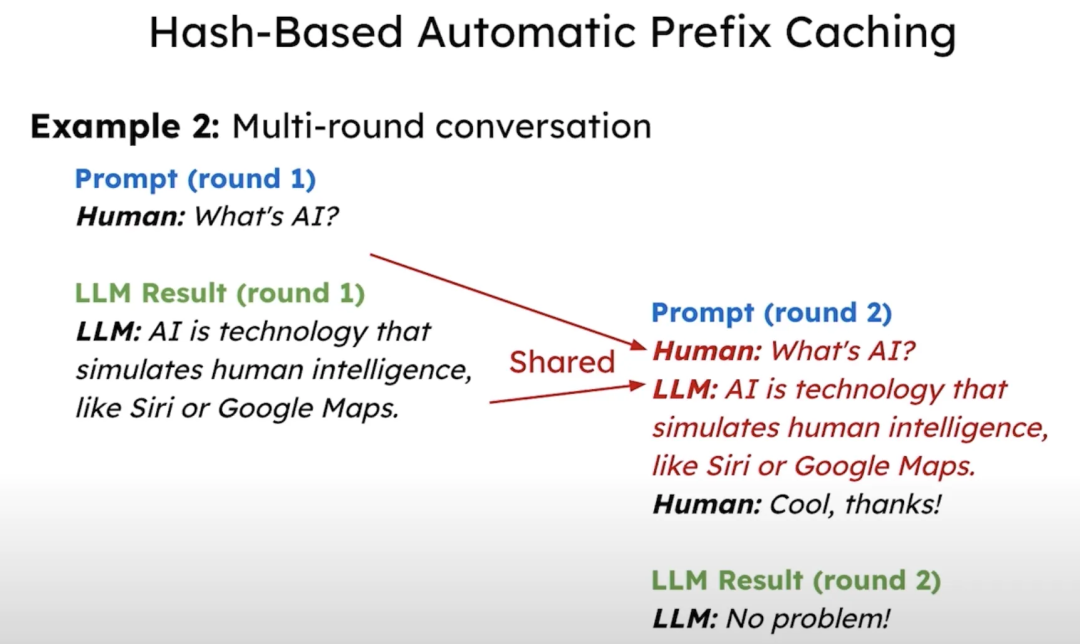
一般我们的LLM服务会有一个较长的系统提示来描述模型的行为。若两个请求共享同样的系统提示,则可以缓存并共享该系统提示的 KV 缓存,从而减少重复计算。此外,多轮对话也可以受益于这种缓存机制。vLLM实现了基于哈希的前缀缓存自动化,通过为每个缓存块分配哈希值,使其在不同请求之间实现共享。

基于hash的自动前缀缓存,缓存system prompt及多轮对话,减少请求数据量,这与sglang中采用的radix树维护kv cache不同,但都提高了缓存重用:
其他功能支持
vLLM也支持多个lora adapter[12]及热加载,同时支持结构化输出等;也支持了基于prometheus/grafana的实时监控,包括gpu内存使用/kvcache重用率/访问延迟吞吐等指标。
在多任务服务方面,vLLM现在支持同时加载多个 LoRA 适配器,并能将不同适配器的请求批处理。
分布式支持
VM 从一开始就支持张量并行(Tensor Parallelism),不过当使用多 GPU 和多节点时,Tensor Parallelism会引入许多潜在的通信问题和故障。vLLM修复了大量通信相关的 Bug,并提供了调试指南来处理分布式系统中的故障和崩溃。

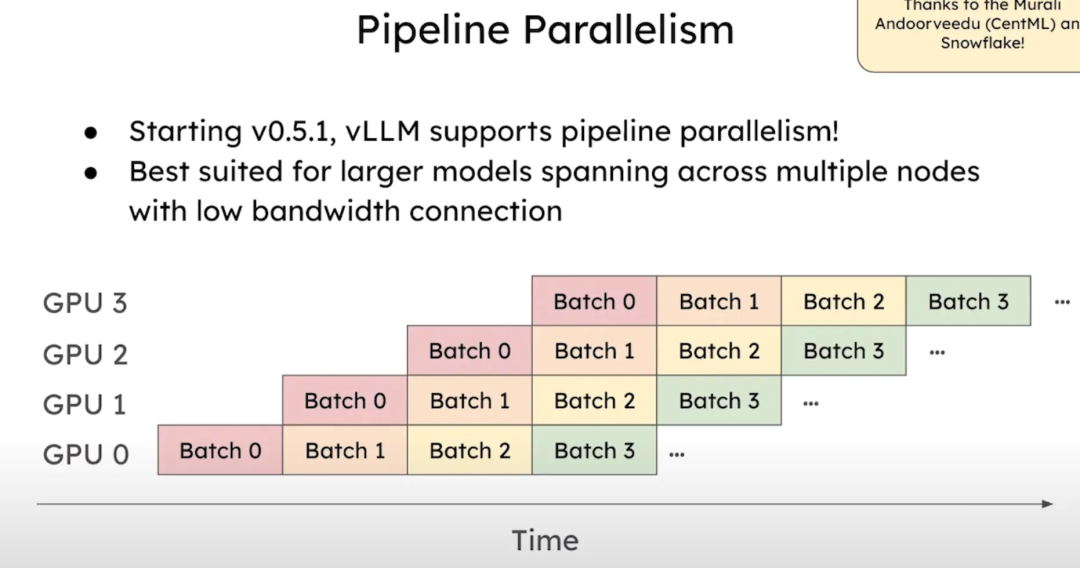
后来vLLM还增加了流水线并行(Pipeline Parallelism)的支持,从vLLM版本 0.5.1 开始支持跨多节点的流水线并行,对于那些跨多个节点的超大模型和低带宽连接,流水线并行是一种更优的选择。
CPU Offloading
vLLM还可以将部分模型权重卸载到 CPU 上,从而在小 GPU 上运行更大模型。
尽管这种方法比直接在 GPU 上运行速度要慢,但对于资源有限的用户来说,可以更高效地利用现有资源来运行模型(有时候能跑起来更重要)。

Q4计划
vLLM之后TODO:
为了性能,默认启用Chunked Prefill和Prefill Cache。此外,我们将加快结构化解码的速度,并通过通信融合来减少开销。会继续提升batch推理的性能,并进行更多内核优化
将支持将 KV 缓存offload到 CPU上从而增加cache空间(已经有很多民间实现)。此外还将支持 KV cache的传输,这对于disaggregated prefill场景十分有用。我们还会调整缓存策略和调度器,以提高缓存命中率,并在 Q4 推出一系列调度和预测解码(Speculative Decoding)优化。
vLLM正在进行一次重大的架构重构,但我们保证这一过程将会很快完成。我们正在开发新的 vLLM Engine V2,这将包括异步调度和基于Prefill Cache的设计。已经实现了对 Torch Compile 的全面支持,以便用户可以优化他们的模型。此外还新增了一个内存管理器,以便更好地支持多模态模型。
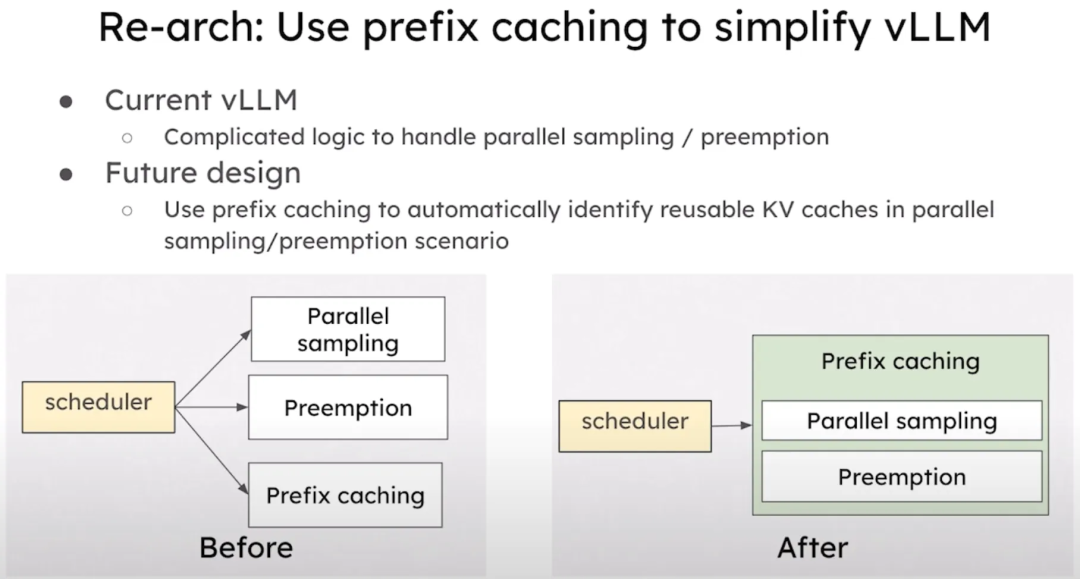
异步调度是重构的一个重点。通过在当前步骤执行的同时调度下一个步骤,会大幅减少了 GPU 的空闲时间。这样可以让 GPU 在完成当前步骤后立即开始执行下一个步骤。与之前相比,这种新的异步架构让调度和执行可以并行进行,显著降低了 GPU 的空闲时间。
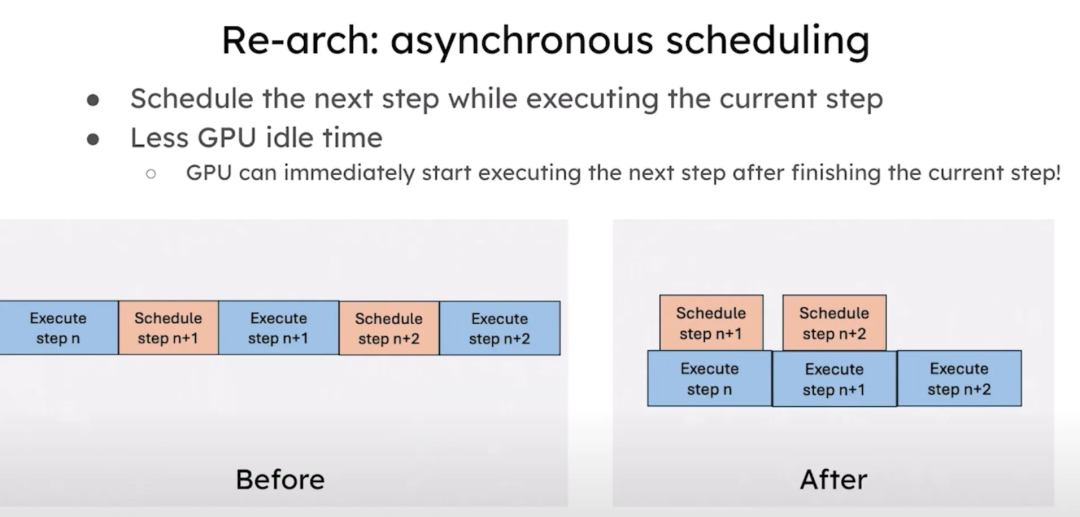
通过Prefill Cache简化了设计。在当前的架构中需要复杂的逻辑来处理并行采样或抢占的情况。在未来,vLLM将使用Prefill Cache来自动识别并行采样和抢占场景中的可重用 KV 缓存,从而减少对手动处理的需求。之前,调度器直接与并行采样和前缀缓存模块进行通信。未来,调度器将只需与前缀缓存模块通信,自动识别重用机会。
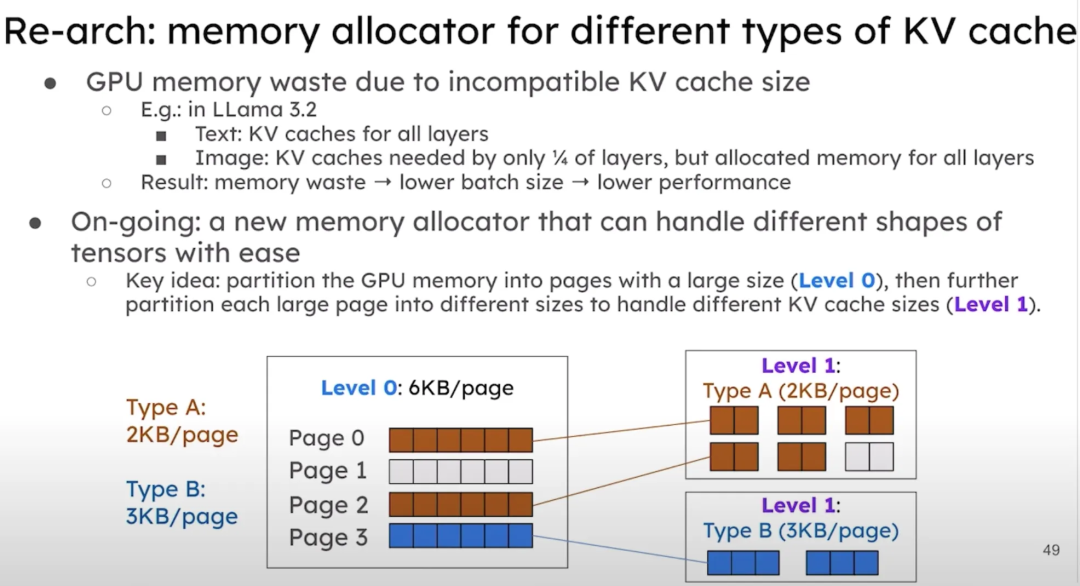
重构内存分配器,以更好地适应不同类型的 KV 缓存。由于 KV 缓存大小不兼容,导致 GPU 内存浪费严重。以新的 LLaMA 模型为例,文本部分有全层的 KV 缓存,而图像部分只有 1/4 层的 KV 缓存,我们实际上为所有层分配了内存,导致浪费。我们计划通过新的内存分配器来优化这种情况。我们的方案是将 GPU 内存首先分区成较大的页面,然后进一步将每个大页面划分为不同的大小,以适应不同的 KV 缓存大小。
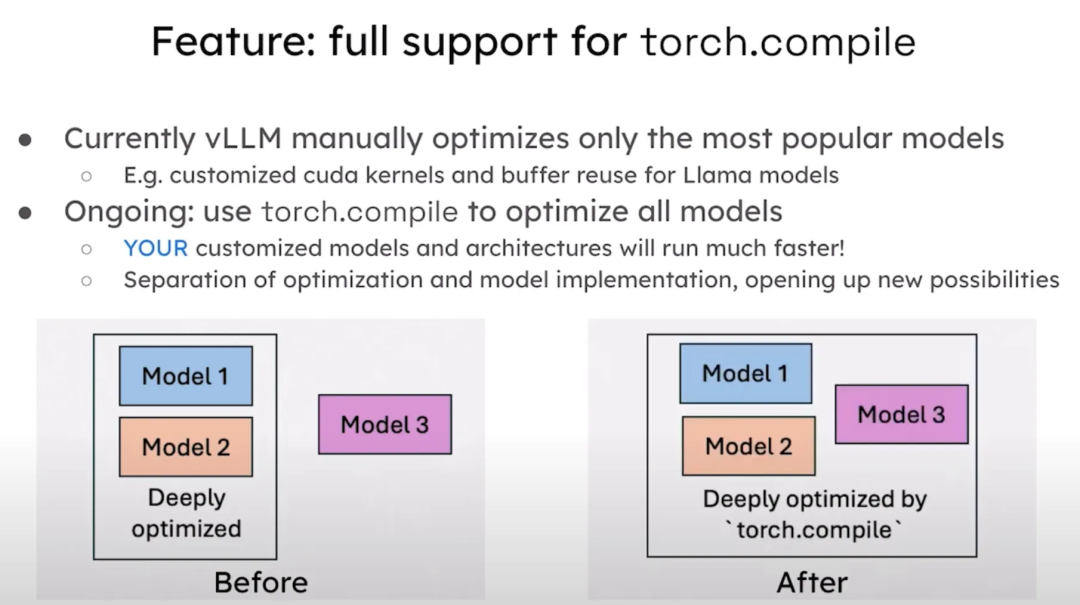
开启对 Torch Compile 的全面支持。目前,vLLM已经手动优化了最流行的模型,例如 LLaMA 模型的 CUDA 内核和缓存重用优化。我们的工作正在进行中,我们将利用 Torch Compile 来优化所有模型,从而使用户的自定义模型和架构也能高效运行。
优化预测解码。当前的预测解码功能已经不错,但在QPS很高时可能会影响性能。我们即将引入动态预测解码机制,以确保预测解码始终让vLLM运行得更快。与之前的机制不同,新的解码机制将无论在何种负载下都能带来更好的性能。
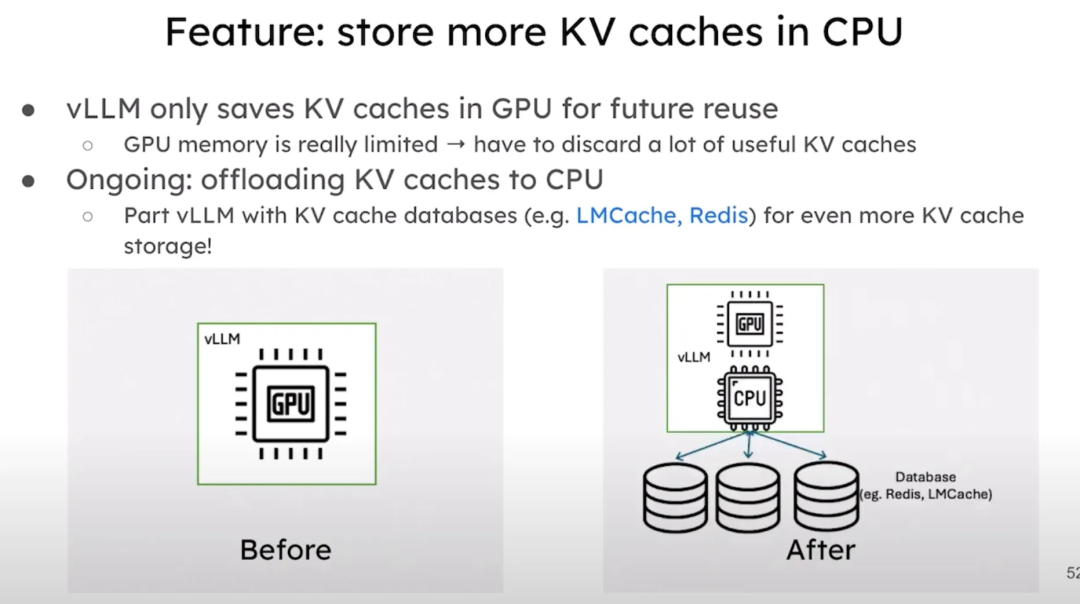
还将支持将更多的 KV 缓存存储到 CPU 上,从而增加多轮对话和系统提示的缓存空间。目前的vLLM只在 GPU 中存储 KV 缓存,未来将支持自动将缓存转移到 CPU,甚至可以与远程缓存数据库(如 LM Cache 和 Redis)配合使用,进一步扩展 KV 缓存存储。之前的vLLM只能在 GPU 中存储 KV 缓存供未来重用,而未来版本的vLLM可以将 KV 缓存存储在 GPU、CPU 甚至远程数据库中。
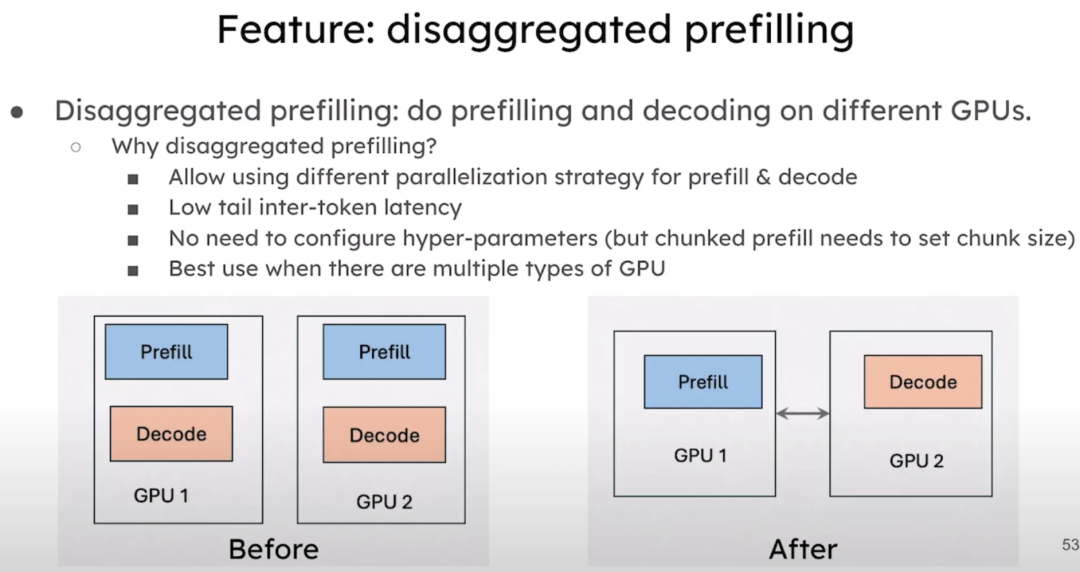
还计划支持disaggregated prefill,在不同的 GPU 上分别进行预填充和解码。这样可以单独配置预填充和解码的并行策略,从而显著降低尾部延迟,并且无需调整任何超参数。这种方法对于拥有多种类型 GPU 的场景尤其适用。
当然还有oss社区,提高perf benchmark及文档优化等。
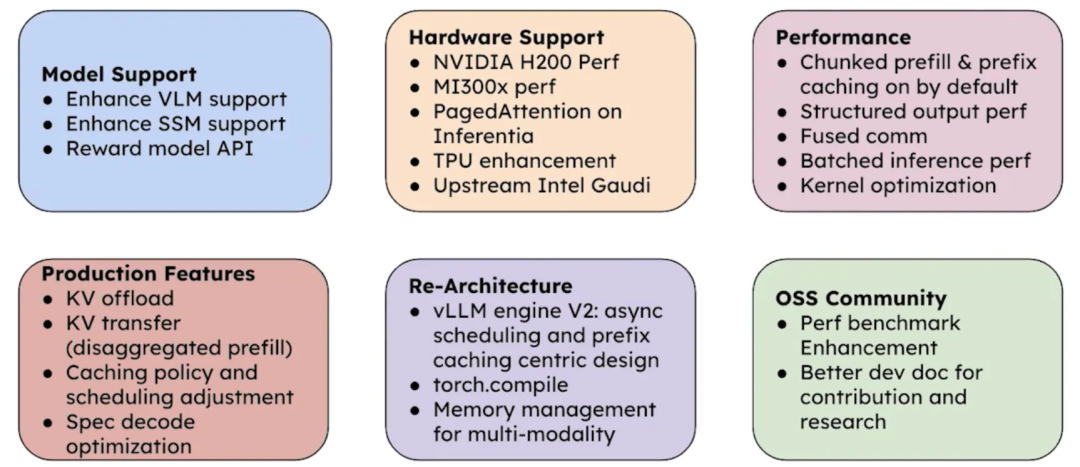
模型支持
持续支持以下模型:
VLM(多模态模型)
SSM(状态空间模型)- Mamba
Reward模型
Whisper等
硬件支持,持续优化对以下硬件的支持:
NVIDIA H200
AMD MI300X
Intel Gaudi
Google TPU等
性能提升,默认启用以下优化项:
Chunked Prefill
前缀树
Speculative Decoding
结构化输出优化
Kernel融合,提供更高性能的Kernel,例如:FlashAttention3、FlashInfer、FlexAttention、Triton
稀疏KV框架及长上下文优化
新特性
KV Offloading到CPU或磁盘,支持KV迁移
Prefill与Decoding解耦
前缀树缓存策略与调度策略优化
动态Speculative Decoding
让我们期待vLLM变得越(xing)来(neng)越(geng)好(qiang)吧~
参考
https://www.zhihu.com/question/666943660/answer/3631053740[13]
https://docs.google.com/presentation/d/1wrLGwytQfaOTd5wCGSPNhoaW3nq0E-9wqyP7ny93xRs/edit#slide=id.g2fbe9f464f9_0_25[14]
https://docs.google.com/presentation/d/1iJ8o7V2bQEi0BFEljLTwc5G1S10_Rhv3beed5oB0NJ4/edit#slide=id.g2c846bb207d_4_46[15]
https://zhuanlan.zhihu.com/p/718504437[16]
https://docs.google.com/present[17]
https://docs.google.com/document/d/1fEaaIQoRQLbevRu3pj1_ReOklHkoeE7ELqZJ3pnW-K4/edit#heading=h.ntrtei46qfj8[18]
参考资料
[1]
https://www.youtube.com/watch?v=4HPRf9nDZ6Q: https://www.youtube.com/watch?v=4HPRf9nDZ6Q
[2]更新了一个版本: https://blog.vllm.ai/2024/09/05/perf-update.html
[3]cuda kernel: https://zhida.zhihu.com/search?content_id=695585364&content_type=Answer&match_order=1&q=cuda+kernel&zhida_source=entity
[4]Marlin: https://neuralmagic.com/blog/pushing-the-boundaries-of-mixed-precision-llm-inference-with-marlin/
[5]LLM Compressor: https://github.com/vllm-project/llm-compressor
[6]https://github.com/vllm-project/vllm/issues/6854: https://github.com/vllm-project/vllm/issues/6854
[7]https://github.com/vllm-project/vllm/pull/7000: https://link.zhihu.com/?target=https%3A//github.com/vllm-project/vllm/pull/7000
[8]prompt: https://zhida.zhihu.com/search?q=prompt&zhida_source=entity&is_preview=1
[9]DeepSpeed-FastGen: https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2401.08671
[10]SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills: https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2308.16369
[11][RFC] Upstream Chunked Prefill · Issue #3130 · vllm-project/vllm: https://link.zhihu.com/?target=https%3A//github.com/vllm-project/vllm/issues/3130
[12]lora adapter: https://zhida.zhihu.com/search?content_id=695585364&content_type=Answer&match_order=1&q=lora+adapter&zhida_source=entity
[13]https://www.zhihu.com/question/666943660/answer/3631053740: https://www.zhihu.com/question/666943660/answer/3631053740
[14]https://docs.google.com/presentation/d/1wrLGwytQfaOTd5wCGSPNhoaW3nq0E-9wqyP7ny93xRs/edit#slide=id.g2fbe9f464f9_0_25: https://docs.google.com/presentation/d/1wrLGwytQfaOTd5wCGSPNhoaW3nq0E-9wqyP7ny93xRs/edit#slide=id.g2fbe9f464f9_0_25
[15]https://docs.google.com/presentation/d/1iJ8o7V2bQEi0BFEljLTwc5G1S10_Rhv3beed5oB0NJ4/edit#slide=id.g2c846bb207d_4_46: https://link.zhihu.com/?target=https%3A//docs.google.com/presentation/d/1iJ8o7V2bQEi0BFEljLTwc5G1S10_Rhv3beed5oB0NJ4/edit%23slide%3Did.g2c846bb207d_4_46
[16]https://zhuanlan.zhihu.com/p/718504437: https://zhuanlan.zhihu.com/p/718504437
[17]https://docs.google.com/present: https://link.zhihu.com/?target=https%3A//docs.google.com/presentation/d/1wrLGwytQfaOTd5wCGSPNhoaW3nq0E-9wqyP7ny93xRs/edit%23slide%3Did.g2fccd0cb111_0_76
[18]https://docs.google.com/document/d/1fEaaIQoRQLbevRu3pj1_ReOklHkoeE7ELqZJ3pnW-K4/edit#heading=h.ntrtei46qfj8: https://docs.google.com/document/d/1fEaaIQoRQLbevRu3pj1_ReOklHkoeE7ELqZJ3pnW-K4/edit#heading=h.ntrtei46qfj8
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









