






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
原标题:End-to-End Navigation with Vision-Language Models: Transforming Spatial Reasoning into Question-Answering
论文链接:https://jirl-upenn.github.io/VLMnav/static/VLMnav.pdf
项目链接:https://jirl-upenn.github.io/VLMnav/
作者单位:UC Berkeley 宾夕法尼亚大学

出发点&VLMnav的概览
VLMnav是一种将视觉语言模型(VLM)转化为端到端导航策略的具身框架。与以往研究不同,VLMnav不依赖感知、规划和控制的分离,而是通过VLM一步直接选择动作。令人惊讶的是,我们发现VLM可以作为端到端策略进行零样本导航,即无需任何微调或导航数据的训练。这使得方法具有开放性和广泛的下游导航任务的泛化能力。我们进行了广泛的研究,以评估该方法相较于基线提示方法的性能。此外还进行了设计分析,以理解最具影响力的设计决策。
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
VLMnav的设计
在环境中有效导航以实现目标的能力是物理智能的标志。空间记忆以及更高级的空间认知形式,被认为在早期陆生动物和高级脊椎动物的进化历史中开始发展,可能始于4亿至2亿年前。由于这一能力经历了如此漫长的进化历程,因此对于人类而言,这种能力几乎显得本能且理所当然。然而,导航实际上是一个高度复杂的问题。它需要协调低层次的规划以避开障碍,同时还需进行高层次的推理,以理解环境的语义,并探索最有可能让智能体实现其目标的方向。
导航问题的很大一部分似乎涉及与回答长上下文图像和视频问题类似的认知过程,而这是当代视觉语言模型(VLMs)擅长的领域。然而,当这些模型直接应用于导航任务时,却面临明显的局限性。具体而言,当给出任务描述并将其与观察-动作历史拼接后,VLMs 往往难以生成精细的空间输出以避开障碍,且无法有效利用其长上下文推理能力来支持有效的导航。
为了解决这些挑战,先前的研究将VLMs作为模块化系统的组成部分,用于执行高层次的推理和识别任务。此类系统通常包含一个显式的3Dmapping模块和一个规划器,以处理任务中更具具身性的部分,例如运动和探索。尽管模块化设计的优势在于可以将每个组件用于其擅长的子任务,但其缺点在于系统的复杂性增加,并且任务专用性较强。
在本研究中,我们展示了一种现成的VLM可以作为零样本的端到端语言条件导航策略使用。实现这一目标的关键在于将导航问题转化为VLM擅长的任务:回答关于图像的问题。
为此,开发了一种新颖的提示策略,使VLM能够明确考虑探索和避障问题。该提示具有通用性,可用于任何基于视觉的导航任务。
与以往的方法相比,我们不使用特定模态的专家模型,不训练任何特定领域的模型,也不假设可以访问模型生成的概率。
我们在具身导航的既定基准上评估了本文的方法,结果证实,与现有的提示方法相比,本文的方法显著提升了导航性能。最后,本文通过对具身VLM框架的多个组件进行消融实验,得出了设计上的见解。
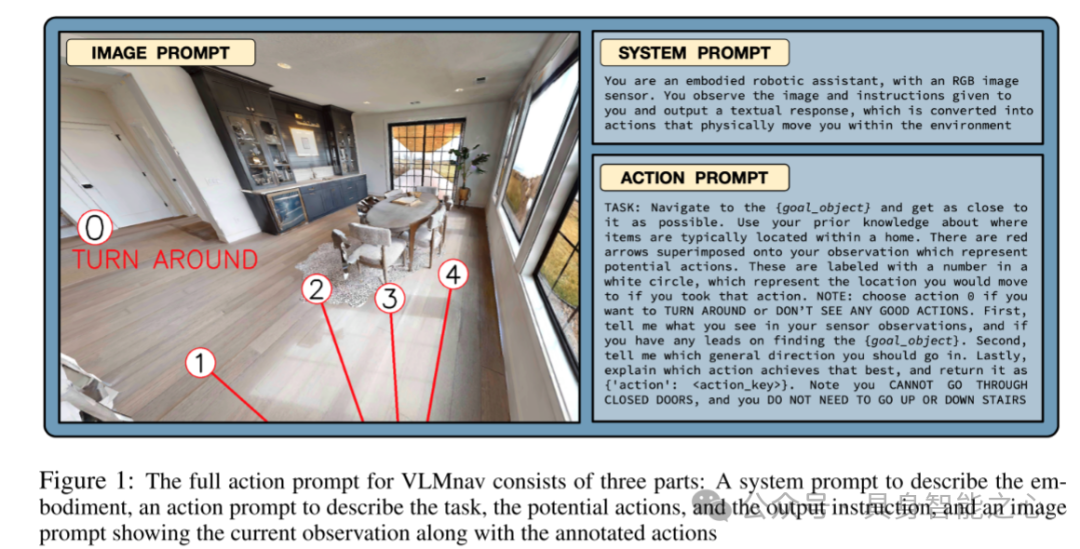
图1:VLMnav的完整动作提示由三部分组成:系统提示用于描述具身性,动作提示用于描述任务、可能的动作和输出指令,以及图像提示显示当前观察到的场景和标注的动作。
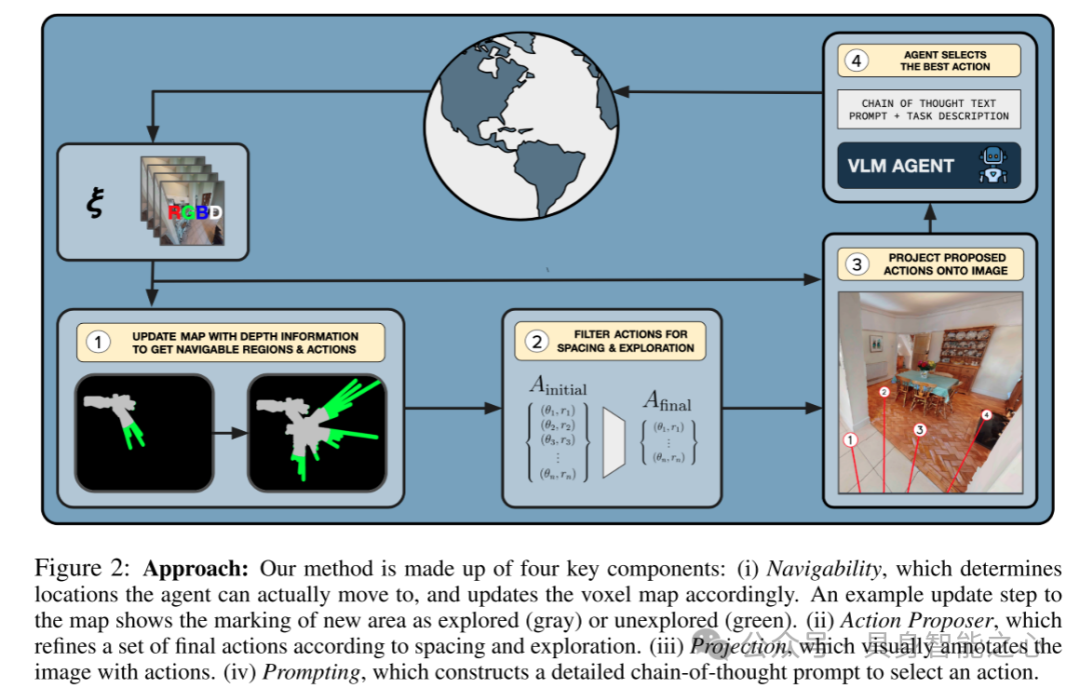
图2:方法:本文的方法由四个关键组件组成:(i) 可导航性,确定智能体可以实际移动的位置,并相应地更新体素地图。地图更新步骤的示例显示新区域标记为已探索(灰色)或未探索(绿色)。(ii) 动作提议器,根据间距和探索情况优化一组最终动作。(iii) 投影,视觉上在图像中标注动作。(iv) 提示,构建详细的思维链提示以选择动作。
VLMnav是一种导航系统,以目标作为输入,目标可以通过语言或图像指定,还包括RGB-D图像、姿态,并输出动作。动作空间由绕偏航轴的旋转和沿机器人框架前轴的位移组成,使得所有动作可以用极坐标表示。由于已知VLM在连续坐标推理上存在困难,本文将导航问题转化为从离散选项集中选择动作。本文的核心思想是选择这些动作选项,以避免碰撞障碍并促进探索。
图2总结了本文的方法。首先,本文通过深度图像估计与障碍物的距离,以确定局部区域的可导航性。本文使用深度图像和位置信息来维护场景的自上而下体素地图,并显著地将体素标记为已探索或未探索。该地图由动作提议器使用,以确定一组避开障碍并促进探索的动作。接着,本文将这一组可能的动作通过投影模块映射到第一人称视角的RGB图像中。最后,VLM将该图像和精心设计的提示作为输入,选择一个动作供智能体执行。为确定回合终止,本文使用一个单独的VLM调用。

图3:可导航性子程序的示例步骤。可导航性掩码显示为蓝色,构成初始动作集 的极坐标动作显示为绿色。
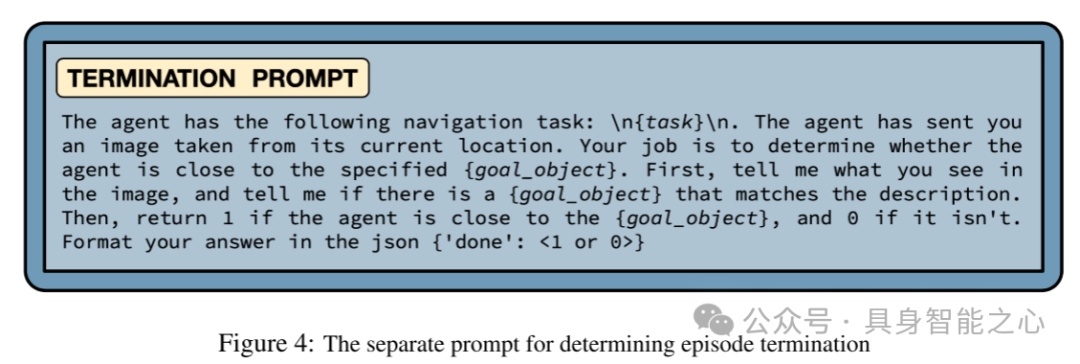
图4:用于确定回合终止的独立提示
VLMnav的实验验证
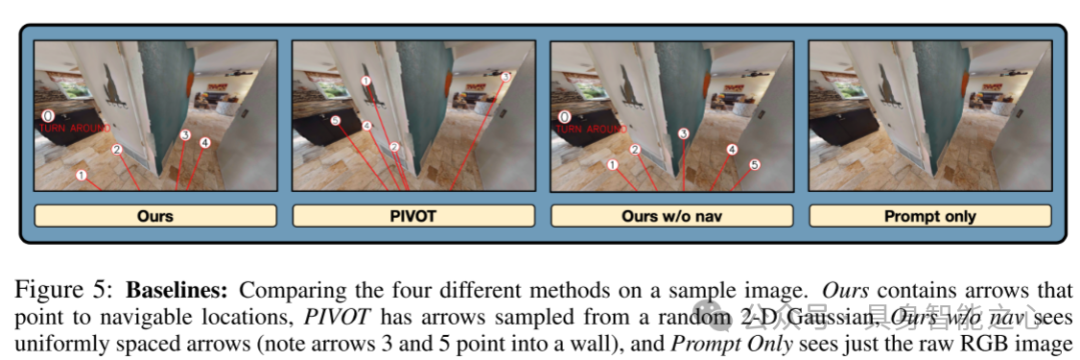
图5:基线方法:在示例图像上比较四种不同方法。本文的方法包含指向可导航位置的箭头,PIVOT方法的箭头从随机二维高斯分布中采样,本文的无导航版本显示均匀分布的箭头(注意箭头3和5指向墙壁),仅提示方法则仅显示原始RGB图像。
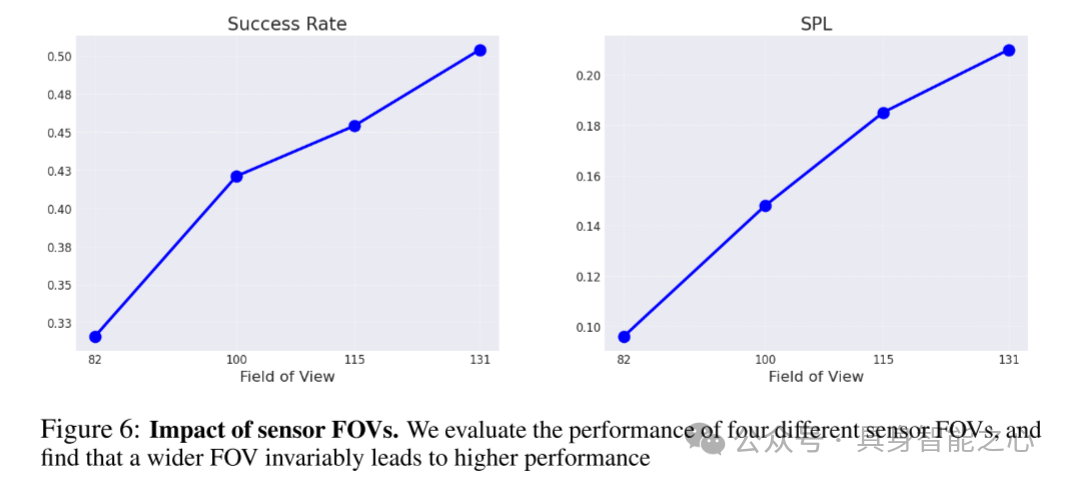
图6:传感器视场角(FOV)的影响。本文评估了四种不同视场角传感器的性能,发现更宽的视场角始终带来更高的性能。

表1:ObjectNav结果。本文在ObjectNav基准上评估了四种不同的提示策略,结果显示本文的方法在准确性(SR)和效率(SPL)方面均达到了最高性能。消融“允许滑动”参数表明本文的方法依赖于滑过障碍物的能力。
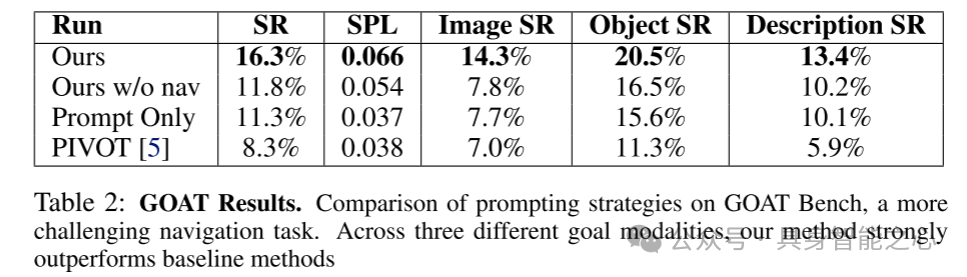
表2:GOAT结果。在更具挑战性的导航任务GOAT基准上对提示策略进行比较。在三种不同的目标模态下,本文的方法均显著优于基线方法。

表3:直接与其他方法对比,本文发现专用系统仍然具有更高的性能。本文还注意到,这些其他方法使用了更窄的视场角(FOV)、更低的图像分辨率以及不同的动作空间,这可能解释了部分性能差异。

表4:添加上下文历史的影响。本文将保持过去0、5、10和15个观测和动作的不同方案与本文的方法进行比较。结果显示,添加上下文历史并未提升本文方法的性能。

表5:深度消融实验。本文评估了仅需RGB的两种替代方法。结果显示,语义分割的性能接近于使用真实深度数据,而估计深度值会导致性能显著下降。
总结
在本研究中,我们提出了VLMnav,这是一种新颖的视觉提示工程方法,使现成的VLM能够作为端到端导航策略工作。该方法的核心思想是精心选择动作提议并将其投影到图像上,从而有效地将导航问题转化为问答问题。通过在ObjectNav和GOAT基准上的评估,本文观察到相较于迭代基线PIVOT(之前在视觉导航提示工程中的最新方法)有显著的性能提升。我们的设计研究进一步突出了宽视场的重要性,并展示了使用最小传感的可能性,即仅依赖RGB图像来实现该方法的部署。
本文的方法也存在一些局限性。禁用“允许滑动”参数后性能急剧下降,表明存在多次与障碍物碰撞的情况,这在实际部署中可能会带来问题。此外,本文发现一些专用系统的性能优于本文的方法。然而,随着VLM能力的不断提升,本文推测该方法可以帮助未来的VLM在具身任务上达到或超越专用系统的表现。
引用:
@inproceedings{
goetting2024endtoend,
title={End-to-End Navigation with VLMs: Transforming Spatial Reasoning into Question-Answering},
author={Dylan Goetting and Himanshu Gaurav Singh and Antonio Loquercio},
booktitle={Workshop on Language and Robot Learning: Language as an Interface},
year={2024},
}① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









