






点击下方卡片,关注“具身智能之心”公众号
具身智能训练要求智能体通过与环境的物理交互来学习智能行为,数据集对于具身智能的训练效果有着至关重要的影响,提高训练效果的根源在于使用丰富多样的数据集,让具身智能体接触到各种不同的情况,从而学习到更广泛的技能和应对策略。然而,数据集的数据采集过程复杂且成本高昂,数据标注工作往往需要专业知识和大量的人工劳动。
大家总在吐槽具身智能训练数据集太贵,本期具身智能之心就为大家汇总了一些具身智能训练数据集,方便大家选取适合的开展研究!
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
ARIO数据集 - 机器人控制
数据集链接:https://openi.pcl.ac.cn/ARIO/ARIO_Dataset
项目链接:https://imaei.github.io/project_pages/ario/
论文链接:https://arxiv.org/pdf/2408.10899
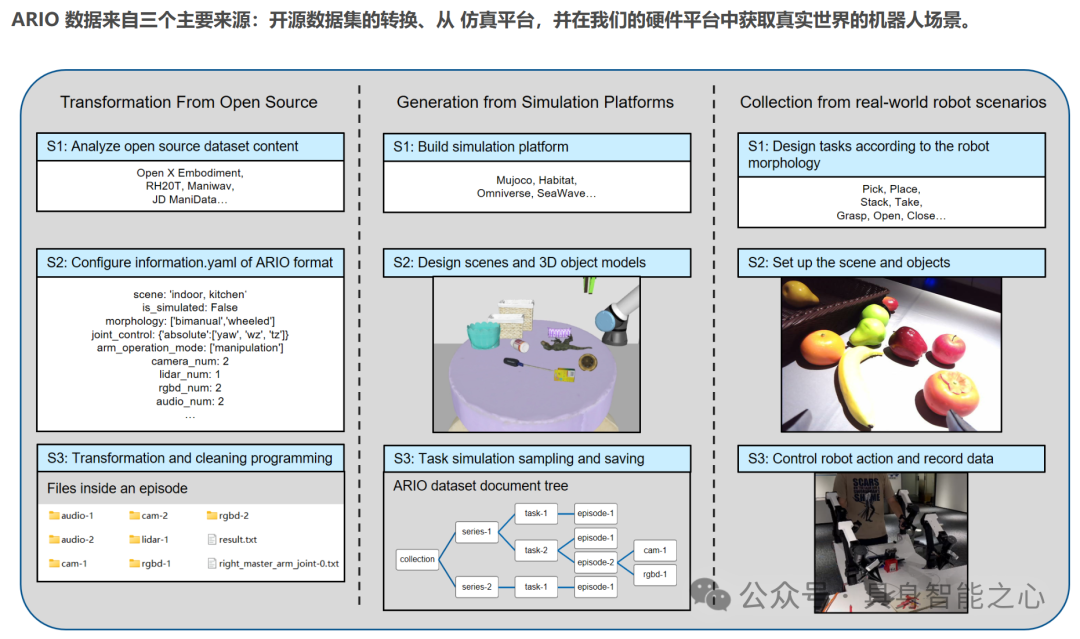
ARIO(All Robots In One)是鹏城实验室建立的大规模统一数据集,旨在解决现有数据集在开发多功能通用实体智能体方面的不足。ARIO支持 5 种感官模态,基于时间戳对齐多模态数据,采用统一数据架构,有统一配置,增强数据多样性,涵盖多种数据来源:(1)从真实场景收集:使用 Cobot Magic 平台(双手机器人移动操作平台)、Cloud Ginger XR - 1 平台(5G 轮式人形云机器人)。(2)从模拟平台生成,包括Habitat 的对象导航任务、MuJoCo 的操作任务、SeaWave 的操作任务。(3)从开源数据集转换,基于 Open X - Embodiment 数据集、基于 RH20T 数据集、基于 ManiWAV 数据集。
ARIO 数据集可用于训练具身智能体,以提高它们在各种任务和环境中的性能和适应性。ARIO拥有多模态特性,包含 2D 和 3D 视觉数据、触觉、声音和文本形式的数据,使得开发者可以在多种任务上进行模型训练;解决了多个现有数据集之间数据结构不一致的问题,显著减少前期数据清洗和预处理的时间。
G1数据集 - 人形机器人操作
开源数据采集的链接:https://github.com/unitreerobotics/avp_teleoperate
开源学习算法的链接:https://github.com/unitreerobotics/unitree_IL_lerobot
开源数据集和模型的链接:https://huggingface.co/UnitreeRobotics
宇树科技公布了开源 G1 人形机器人操作数据集,用以训练人形机器人,适配多种开源方案。宇树 G1 人形机器人操作数据集具有以下特点:(1)多样化的操作能力展示:通过演示视频可以看到,G1 人形机器人能够完成拧瓶盖倒水、叠三色积木、将摄像头放入包装盒、收集物品并存储、双臂抓取红色木块并将其放入黑色长方形容器中等复杂操作,显示出高度的灵活性和实用性。(2)数据采集方式创新:使用苹果的 Vision Pro 对 G1 进行遥操作控制。(3)丰富的数据维度:数据集中的图像分辨率为 640×480,每个手臂和灵巧手的状态及动作维度为 7。目前包含拧瓶盖倒水、叠三色积木、包装摄像头、存储物品、双臂抓取和放置等五大类操作的数据集。

RT-1数据集 - 机器人操作
论文链接:https://robotics-transformer.github.io/assets/rt1.pdf
开源链接:https://github.com/google-research/robotics_transformer
项目主页:https://robotics-transformer2.github.io/
RT-1 数据集是用于训练和评估机器人学习模型 RT-1 的数据集,旨在构建一个能够处理多种任务、对新任务和环境具有良好泛化能力的机器人系统。数据收集使用 13 个来自 Everyday Robots 的移动机械臂,在三个厨房环境(两个真实办公室厨房和一个训练环境)中收集数据。数据由人类提供演示,并为每个情节标注执行任务的文本描述,指令通常包含动词和描述目标对象的名词。
RT-1 能够执行超过 700 个语言指令,根据指令中的动词将其分组为不同技能,如拾取、放置、打开和关闭抽屉、取放抽屉中的物品、直立放置细长物品、推倒物品、拉餐巾和打开罐子等。涵盖多种行为和对象,通过增加 “pick” 技能的对象多样性来提升技能的泛化能力,并在实验中扩展了技能,包括一些现实的长指令任务,如在办公室厨房场景中的复杂操作。
RT-1 包含超过 130k 个机器人演示,这些演示构成了 744 个不同的任务指令,涉及多种技能和大量不同的对象。数据集中的技能和指令涵盖了多个领域,如物体操作、环境交互等,以支持机器人在不同场景下的任务执行和学习。

QT-Opt - 抓取
论文链接:https://arxiv.org/pdf/1806.10293
开源链接:https://github.com/quantumiracle/QT_Opt
QT-Opt 数据集是为训练机器人的视觉抓取策略而收集的大规模数据集,通过 7 个机器人在四个月内收集了超过 580k 次真实世界的抓取尝试,旨在让机器人学习通用的抓取技能,能够在未见过的物体上实现高成功率的抓取。
在收集数据集时,使用 7 个 KUKA LBR IIWA 机械臂,每个机械臂配备一个两指夹爪和一个位于肩部上方的 RGB 相机来收集数据。数据收集过程中,为了使模型能够学习到通用的抓取策略,使用了多样化的物体,这些物体在训练过程中定期更换,每 4 小时更换一次(在工作时间内),夜间和周末则保持不变。收集的数据包括机器人的相机观察(RGB 图像,分辨率为 472x472)、夹爪状态(开或关的二进制指示)以及夹爪相对于地面的垂直位置等信息。数据收集总共耗时约 800 机器人小时,数据量达到 4TB,足以训练出具有高成功率的抓取策略模型。

BridgeData - 机器人学习与泛化
论文链接:https://arxiv.org/pdf/2308.12952
项目主页:https://rail-berkeley.github.io/bridgedata/
BridgeData V2 是一个用于大规模机器人学习研究的数据集,旨在促进机器人学习方法的发展,包含丰富的机械臂操作行为数据,以支持多种任务和环境下的技能学习与泛化研究。数据集包含 60,096 条轨迹,其中 50,365 条专家演示轨迹和 9,731 条脚本策略收集的轨迹。涵盖 13 种技能,包括基础操作如拾取和放置、推动、重新定向物体,以及更复杂的操作如开门、关门、抽屉操作、擦拭表面、折叠布料、堆叠积木、扭转旋钮、翻转开关、转动水龙头、拉链操作和使用工具清扫颗粒状介质等。这些技能适用于多种环境和物体,确保学习到的技能具有通用性。包含 24 种环境,如厨房、水槽、桌面等,以及 100 多种物体。环境和任务的多样性使数据集能够支持多种学习方法的评估和研究,有助于机器人学习在不同场景下的任务执行和技能泛化。

TACO - RL - 长时域操作
论文链接:http://tacorl.cs.uni-freiburg.de/paper/taco-rl.pdf
项目链接:http://tacorl.cs.uni-freiburg.de/
数据集链接:https://www.kaggle.com/datasets/oiermees/taco-robot
TACO - RL 使用的数据集是通过在模拟和真实环境中对机器人进行远程操作收集的,包含机器人与环境交互的状态 - 动作序列,用于训练分层策略以解决长时域机器人控制任务,支持机器人从无结构的游戏数据中学习通用技能并实现复杂任务的执行。
收集的数据为无结构的游戏数据,未针对特定任务进行标记,包含多种机器人操作行为,如推动、抓取、放置物体,操作抽屉、滑动门和与 LED 按钮交互等,具有丰富的多样性和复杂性。数据集用于训练低层级策略,通过对无结构数据进行自动编码,学习从潜在计划到动作的映射,提取一系列基本行为原语。高层级策略通过离线强化学习(RL)利用后见之明重标记技术进行训练。

CLVR - 遥控
数据集链接:https://github.com/clvrai/clvr_jaco_play_dataset
CLVR Jaco Play Dataset 是一个专注于遥控机器人领域的数据集,共 14.87 GB,由南加州大学和 KAIST 的研究团队发布,它提供了 1,085 个遥控机器人 Jaco2的片段,并配有相应的语言注释。

FurnitureBench - 长时域操作
论文链接:https://arxiv.org/pdf/2305.12821
项目链接:https://clvrai.github.io/furniture-bench/
数据集链接:https://clvrai.github.io/furniture-bench/docs/tutorials/dataset.html
FurnitureBench是一个用于测试真实机器人复杂长时域操作任务的数据集。数据集聚焦于家具组装这一复杂长时域操作任务,其任务层次结构长,涉及家具部件的选择、抓取、移动、对齐和连接等步骤,平均任务时长在 60 - 230 秒(600 - 2300 低层级步骤)。任务要求机器人具备多种复杂技能,如精确抓取(不同家具部件抓取姿态各异)、部件重定向(通过拾取放置或推动实现)、路径规划(避免碰撞已组装部件)、插入和拧紧(精确对齐并重复操作)等。
通过使用 Oculus Quest 2 控制器和键盘对机器人进行远程操作来收集数据,历时 219 小时,涵盖八个家具模型。针对不同家具模型和初始化水平(低、中、高)收集了不同数量的演示数据。每个演示的时间步长因任务长时域性质而在 300 - 3000 步左右。数据收集过程中,通过使用不同颜色温度的单光面板并改变其位置和方向,以及每集随机化前视图相机姿势来增加数据多样性。

Cable Routing - 多阶段电缆布线
论文链接:https://arxiv.org/abs/2307.08927
项目链接:https://sites.google.com/view/cablerouting/home
数据集链接:https://sites.google.com/view/cablerouting/data
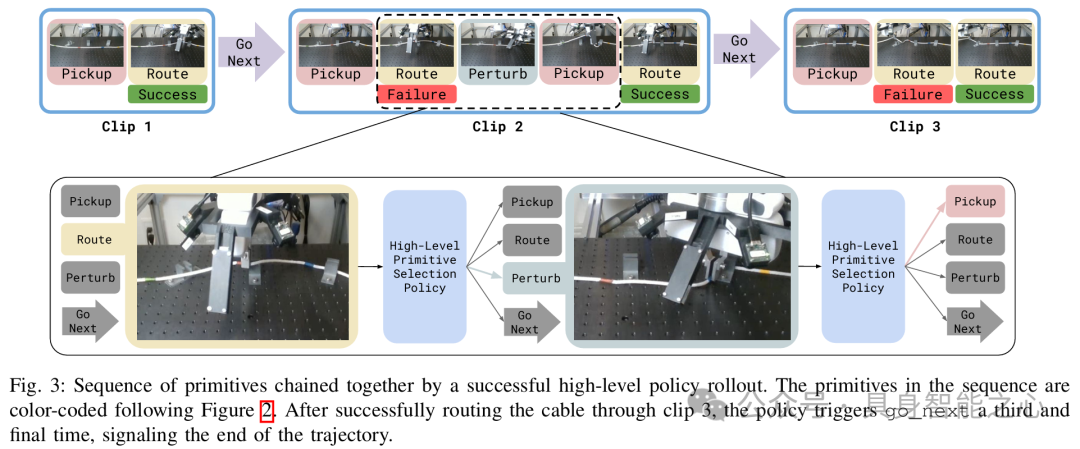
该数据集是为训练机器人的电缆布线策略而收集的,用于支持分层模仿学习系统,使机器人能够学习执行多阶段电缆布线任务,应对复杂的电缆操作挑战。数据集中包含了多种电缆形状、夹取位置和方向的变化,以及不同数量夹子(一夹、两夹、三夹)的布线任务数据,有助于训练出具有泛化能力的策略。
针对单夹电缆布线任务,通过人类专家远程操作机器人在不同位置和夹取方向上执行任务来收集数据。共收集 1442 条夹取轨迹,每条轨迹时长约 3 - 5 秒,包含约 20 个时间步,每个时间步包含机器人相机图像(四个)、机器人配置状态向量和人类远程操作员的指令动作。在训练单夹布线策略和其他原语后,通过人类专家按顺序触发原语以执行完整的多阶段电缆布线任务来收集数据。在一夹、两夹或三夹的场景下,电缆初始状态为平放在桌子上的任意形状,专家输入原语,机器人执行,同时记录整个轨迹的感官信息。

RoboTurk - 模仿学习
论文链接:https://arxiv.org/abs/1811.02790
项目链接:https://github.com/RoboTurk-Platform/roboturk_real_dataset
数据集链接:https://roboturk.stanford.edu/dataset_real.html
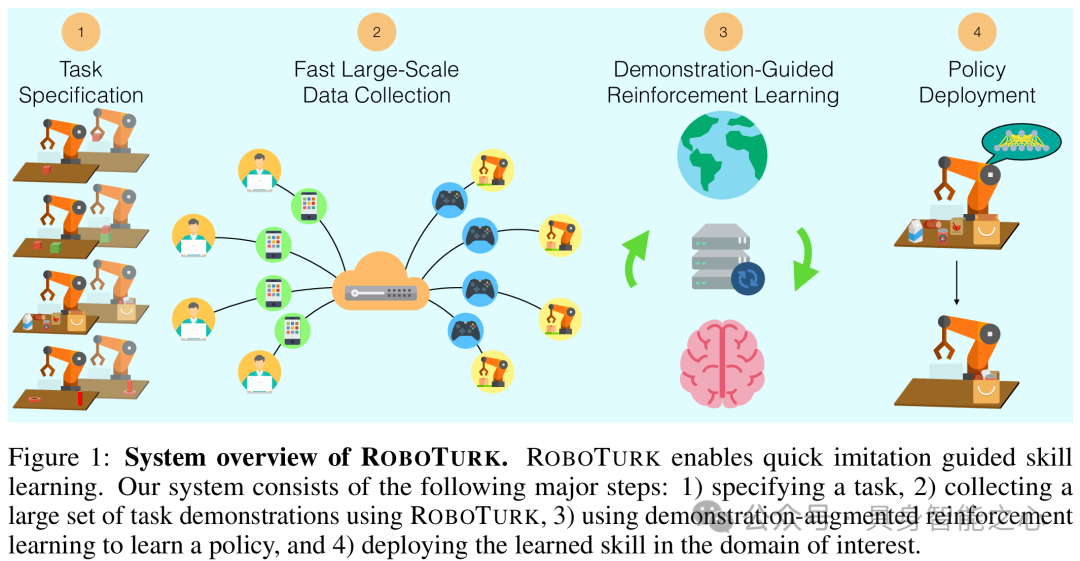
ROBOTURK 数据集是通过众包平台收集的用于机器人学习任务的大规模数据集,旨在解决机器人模仿学习中数据收集困难的问题,使机器人能够从大量的人类演示中学习操作技能,应对复杂的操作任务。数据涵盖了不同用户在多种任务和操作条件下的演示,包括不同物体的操作(如 lifting 任务中的立方体、picking 任务中的各种物品、assembly 任务中的螺母等)以及不同的操作场景,有助于训练出具有泛化能力的机器人策略。
本期推送暂且汇总十个数据集,未完待续!
“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
(1)具身多模态基础模型
NVIDIA最新!NVLM:开放级别的多模态大语言模型(视觉语言任务SOTA)
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
CLIP怎么“魔改”?盘点CLIP系列模型泛化能力提升方面的研究
揭秘CNN与Transformer决策机制:设计原则是关键?
VILA:视觉推理能力如何up up?多模态预训练设计有妙招
(2)3D场景理解、分割与交互
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
大模型继续发力!SAM2Point联合SAM2,首次实现任意3D场景,任意Prompt的分割
更丝滑更逼真!模型自主发现与模式自动识别新升级助力三维场景构建与形状合成
进一步向开放识别迈进!3D场景理解与视觉语言模型的融合创新可以这样玩
(3)具身机器人与环境交互
TPAMI 2024 | OoD-Control:泛化未见环境中的鲁棒控制(一览无人机上的效果)
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
(4)具身仿真×自动驾驶
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集
ECCV 2024 Oral | DVLO:具有双向结构对齐功能的融合网络,助力视觉/激光雷达里程计新突破
(5)权威赛事结果速递
模型与场景的交互性再升级!感知、行为预测以及运动规划在Waymo2024挑战赛中有哪些亮点
效率和精度齐飞!CVPR2024 AIS workshop亮点大盘点
(6)具身智能工具深度测评
巨好用的工具安利!胜过WPS?MinerU 帮你扫清PDF提取
UCLA出品!用于城市空间的具身人工智能模拟平台:MetaUrban
(7)具身智能时事速递
端到端、多模态、LLM如何与具身智能融合?看完这50家公司就明白了
见证历史?高通准备收购英特尔!
万张A100“堆”出来的勇气:一个更极致的中国技术理想主义故事
即将截止!ECCV'24自动驾驶难例场景多模态理解与视频生成挑战赛


















 5614
5614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









